Category:Scraping Use Cases
How to Scrape Amazon Reviews (Behind Login Too)

Software Engineer


If you are running market research, training an AI model on customer sentiment, or just looking for well-performing products to resell, Amazon’s review data is invaluable.
But it isn’t all in one place.
Featured reviews are embedded directly into the product page, while the full review history sits behind pagination and a login wall.
In this guide, we’ll cover both.
Find full working code for scraping Amazon product data, reviews, and search results here ⚙ and here's more on how to scrape Amazon.
Scrape Featured Reviews
Update (May 2026): Amazon hardened how it serves reviews, so parsing them out of the raw product page HTML is no longer reliable. The clean way to pull review content now is the Amazon Scraper API PDP endpoint, which returns each featured review fully parsed, including the title, star rating, and full review text, with no HTML scraping on your end.
Amazon product pages display a handful of “Featured Reviews” that sum up how a product is landing with buyers.
These reviews usually represent a mix of positive, negative, and most helpful feedback, making them valuable for sentiment analysis, quality checks, or customer research.
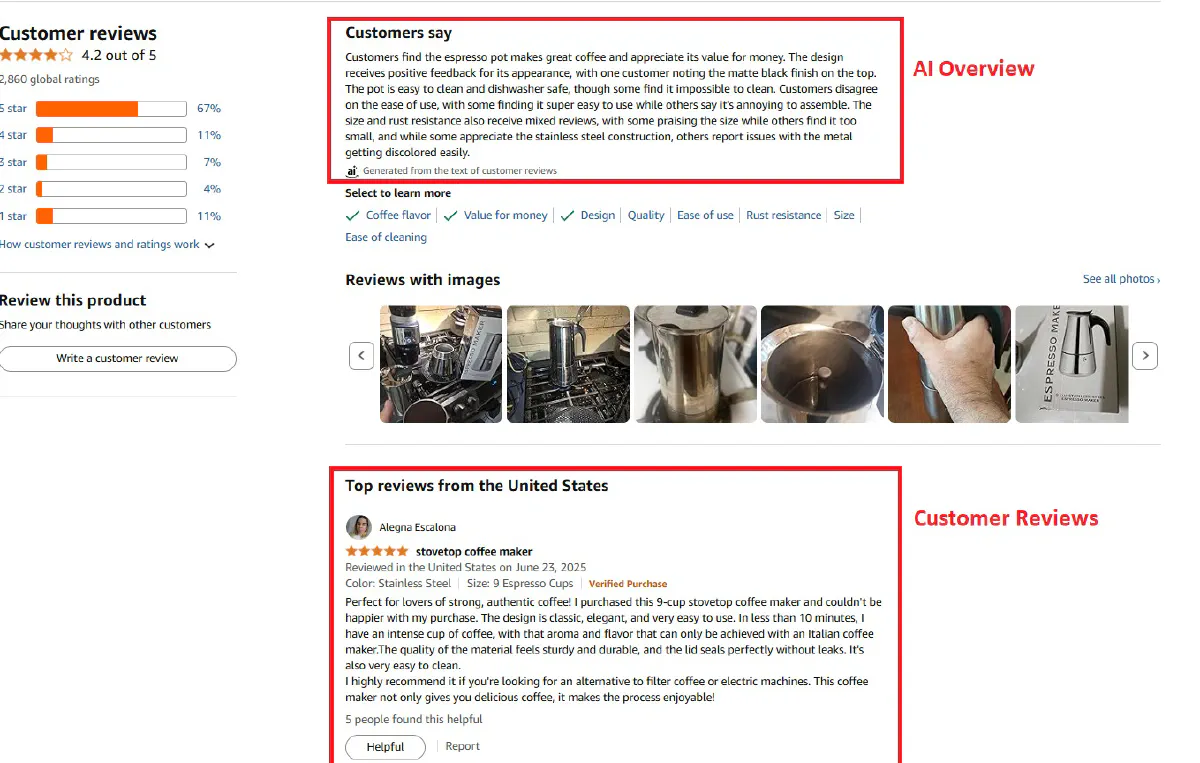
These can be enough for a quick read on a product, so let's pull them with the Amazon Scraper API:
Prerequisites
We'll first need to install our one library, get our Scrape.do token, and build the request that hits the Amazon Scraper API.
1. Install Required Libraries
We’ll be using Python’s requests library for HTTP requests and the built-in csv module for saving results. The Amazon Scraper API returns parsed JSON, so there’s no HTML parsing library to set up.
Install requests with:
pip install requests2. Get Your Scrape.do Token
- Create a Scrape.do account for FREE.
- Open the Dashboard and copy your API Token from the top of the screen.
3. Build the Request
We’ll send the product’s ASIN to the Amazon Scraper API PDP endpoint, along with our token, geocode=us for the US version of the page, and a zipcode so pricing and availability resolve to a real location.
The ASIN is the 10-character ID in any product URL. For https://www.amazon.com/dp/B06X3SSTD8, the ASIN is B06X3SSTD8.
import requests
token = "<SDO-token>"
asin = "B06X3SSTD8"
# The Amazon Scraper API returns the product's featured reviews, pre-parsed.
response = requests.get(
"https://api.scrape.do/plugin/amazon/pdp",
params={"token": token, "asin": asin, "geocode": "us", "zipcode": "10001"},
)
data = response.json()Each item in the reviews array comes back fully parsed, text and all:
{
"review_id": "R3KL8XPQZ2WN1A",
"author": "Marcus T.",
"title": "Sturdy and brews a great cup",
"rating": 5,
"date": "Reviewed in the United States on May 28, 2026",
"verified_purchase": true,
"helpful_votes": 42,
"body": "I've used this percolator every morning for two months. The stainless steel feels solid, it heats evenly on my gas stove, and cleanup takes seconds. Coffee comes out rich without any metallic taste. Worth every penny."
}Extract Review Data
The endpoint hands back structured JSON, so there’s no HTML to parse. The featured reviews live in the reviews array, and each entry carries these fields:
review_id→ Amazon’s unique ID for the reviewauthor→ the reviewer’s display nametitle→ the review headlinerating→ the star rating the reviewer gave, from 1 to 5date→ the full “Reviewed in … on …” stringverified_purchase→truewhen Amazon confirmed the buyer purchased the itemhelpful_votes→ how many shoppers marked the review helpfulbody→ the full review text
Loop over the array and pull out what you need:
reviews = []
for r in data.get("reviews", []):
reviews.append([
r.get("review_id", ""),
r.get("author", "N/A"),
r.get("title", ""),
r.get("rating", ""),
r.get("date", "N/A"),
r.get("verified_purchase", False),
r.get("helpful_votes", 0),
r.get("body", ""),
])
print(f"Found {len(reviews)} featured reviews")
for r in reviews:
print(f"{r[3]}★ {r[1]}: {r[2]}")Our data is now ready to export, so let's do that:
Export Reviews to CSV
We can export reviews stored in our reviews list to a CSV for easier storage. Python’s built-in csv module makes this straightforward:
import csv
with open("amazon_reviews.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["review_id", "author", "title", "rating", "date", "verified_purchase", "helpful_votes", "body"])
writer.writerows(reviews)
print("Reviews saved to amazon_reviews.csv")This will create a file named amazon_reviews.csv in your working directory with columns for review ID, author, title, rating, date, verified purchase, helpful votes, and the full review body:
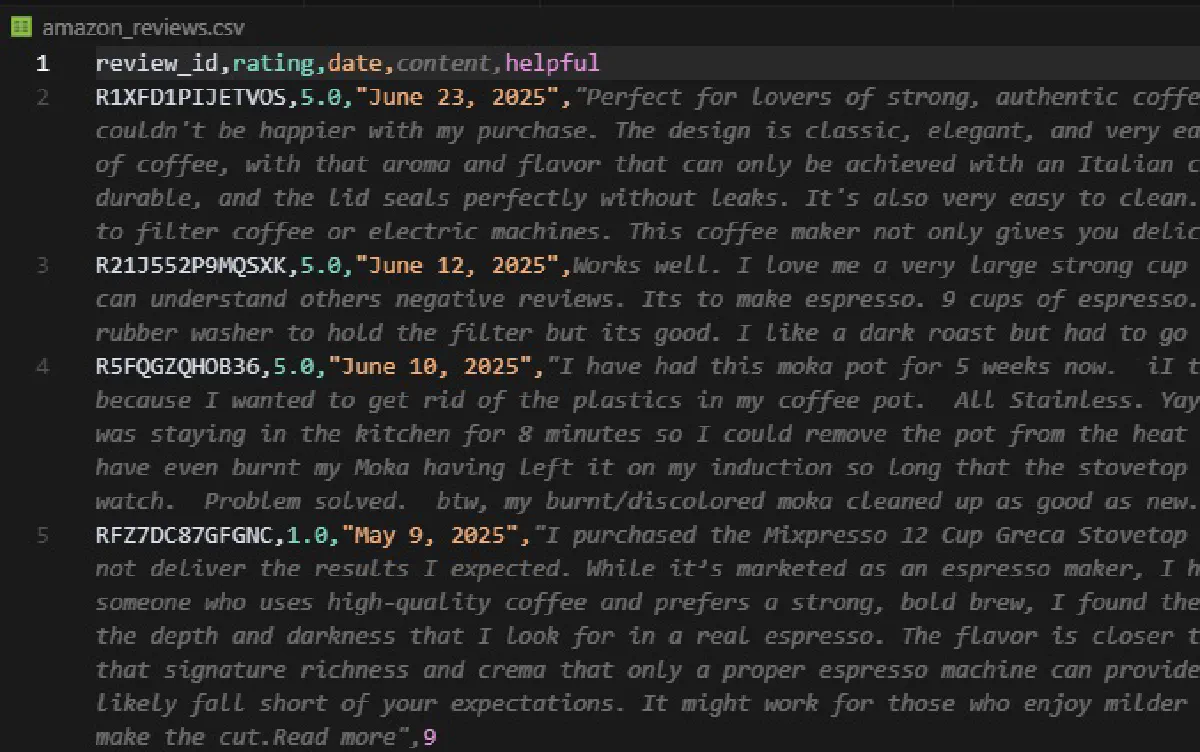
Keep in mind the featured set is a curated sample of roughly 8 to 13 reviews that Amazon picks, not the product’s full review history.
This should give you a decent level of insight of how a product is performing with consumers.
But if you insist on more...
Scrape All Reviews Behind Login
🛑 ⚠ Before we dive into the code, there’s an important warning you need to read carefully.
Scraping Amazon while logged in is not the same as scraping public product pages.
If you log into your Amazon account and then scrape data:
- You are bound by Amazon’s Terms of Service: these explicitly prohibit the use of data mining tools, robots, or data gathering and extraction tools.
- Data behind a login wall may not be considered public data, which means scraping and re-using it can be illegal in many countries.
Doing this at scale can lead to:
- Permanent account bans (losing access to your purchases, history, and Prime membership)
- Legal action from Amazon
We do not endorse or recommend scraping logged-in data at scale.
What changed in May 2026: Run logged out, the
/product-reviews/<ASIN>/URL now returns Amazon's own "Page Not Found" response, so thepageNumberloop below yields nothing without valid session cookies. Logged in, you can still page through more reviews than the public sample exposes, but Amazon now caps how much of the full history it will serve. For most use cases the featured reviews from the first method are enough. Reach for the logged-in method only when you specifically need more depth for a product you own or purchased.
That said, if you want to scrape review data for personal use without reutilizing it, for example, researching a product you purchased or tracking reviews of your own listings, we’ll walk you through how to do it safely:
Collecting Necessary Cookies
To fetch Amazon’s full review history, you’ll need a handful of your own session cookies from Chrome DevTools.
These prove you’re logged in and let Amazon serve you the complete reviews data.
Open the reviews page for your target product while signed in, then right-click and choose Inspect. In the DevTools panel, switch to the Application tab and look under Storage → Cookies for https://us.amazon.com (or whichever Amazon domain matches your geoCode).
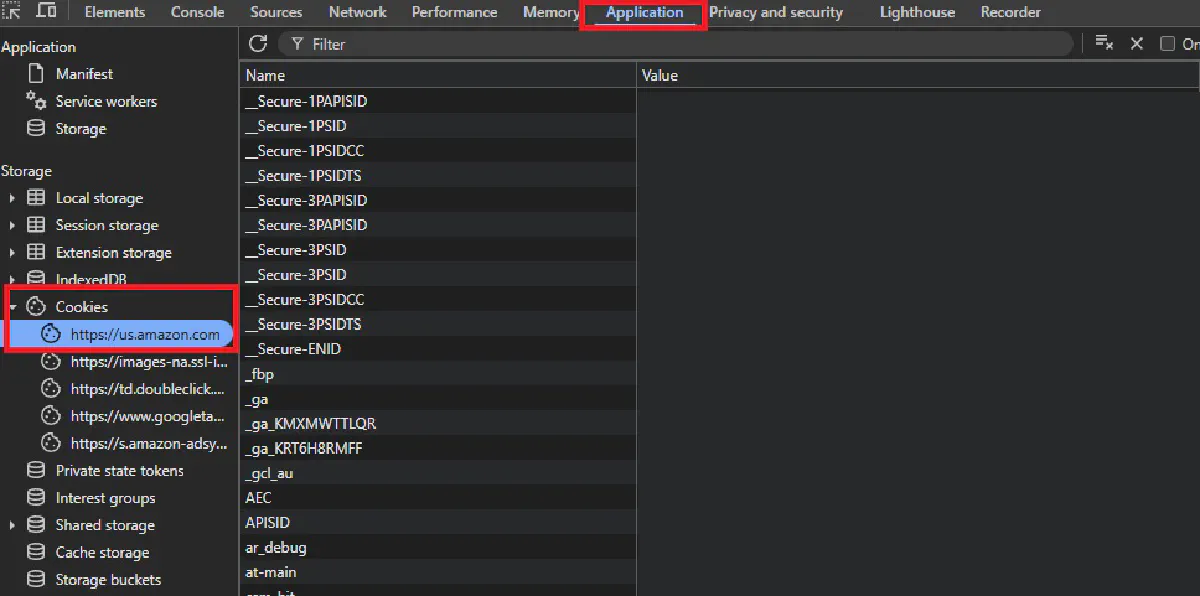
Here, locate the cookies named at-main, sess-at-main, session-id, session-id-time, session-token, ubid-main, and x-main.
Copy their Value fields exactly, without quotes or spaces, and join them into a single string separated by semicolons and a space. The final string should look like:
at-main=...; sess-at-main=...; session-id=...; session-id-time=...; session-token=...; ubid-main=...; x-main=...Make sure the region in the cookie domain matches the one you’ll scrape; a mismatch will return a login page instead of reviews, and expired cookies will need to be refreshed before they work again.
Injecting Cookies into Your Request
Once you have your cookie string, you can pass it to Scrape.do using the setCookies parameter.
This tells Amazon’s servers that your scraper is already logged in with your account, so they return the full reviews page instead of a limited public version.
Before sending, URL-encode the cookie string so it can safely travel inside the request URL. Python’s urllib.parse.quote handles this for us.
Then, build the Scrape.do API request with your token, the target reviews page URL, your geoCode, and the encoded cookies.
import requests
import urllib.parse
token = "<SDO-token>"
encodedCookies = urllib.parse.quote(
"at-main=YOUR_AT_MAIN_VALUE; "
"sess-at-main=YOUR_SESS_AT_MAIN_VALUE; "
"session-id=YOUR_SESSION_ID; "
"session-id-time=YOUR_SESSION_ID_TIME; "
"session-token=YOUR_SESSION_TOKEN; "
"ubid-main=YOUR_UBID_MAIN; "
"x-main=YOUR_X_MAIN_VALUE; "
)
target_url = "https://us.amazon.com/product-reviews/B06X3SSTD8/"
targetUrl = urllib.parse.quote(target_url, safe="")
api_url = (
f"https://api.scrape.do/?token={token}"
f"&url={targetUrl}"
f"&geoCode=US"
f"&setCookies={encodedCookies}"
)api_url contains everything needed to make an authenticated request and pull reviews that are normally hidden behind the login wall.
Taking a Full Page Screenshot & More
Let's now add a few extra parameters, so we can have Scrape.do render the page in a headless browser, capture a full-page screenshot, and send back the results as JSON.
This will be useful for confirming that the cookies worked and that we’re seeing the complete logged-in review list before parsing.
We enable rendering with render=true, request a full screenshot with fullScreenShot=true, and choose returnJSON=true so the HTML, screenshots, and other data come in a structured JSON response.
The screenshot is returned as a Base64-encoded string, which we can decode and save locally, the full code looks like this with these added:
import requests
import urllib.parse
import base64
import json
token = "<SDO-token>"
encodedCookies = urllib.parse.quote(
"at-main=YOUR_AT_MAIN_VALUE; "
"sess-at-main=YOUR_SESS_AT_MAIN_VALUE; "
"session-id=YOUR_SESSION_ID; "
"session-id-time=YOUR_SESSION_ID_TIME; "
"session-token=YOUR_SESSION_TOKEN; "
"ubid-main=YOUR_UBID_MAIN; "
"x-main=YOUR_X_MAIN_VALUE; "
)
# Target an authenticated page to verify login
target_url = "https://us.amazon.com/product-reviews/B06X3SSTD8/"
targetUrl = urllib.parse.quote(target_url, safe="")
url = f"https://api.scrape.do/?token={token}&url={targetUrl}&geoCode=US&setCookies={encodedCookies}&fullScreenShot=true&render=true&returnJSON=true"
resp = requests.get(url, timeout=60)
json_map = json.loads(resp.text)
image_b64 = json_map["screenShots"][0]["image"]
image_bytes = base64.b64decode(image_b64)
file_path = "amazon_screenshot.png"
with open(file_path, "wb") as file:
file.write(image_bytes)
print(f"Full screenshot saved as {file_path}")If all works, you should have a clear view of the reviews page with your own account logged in.
To extract all reviews while logged in, you can disable render, returnJson, and fullScreenshot parameters use **the exact parsing logic we used in the previous section.
**To loop through all pages, make the code add&pageNumber=2to the end of the target URL and increase page number until there are no more reviews left.One parsing note: helpful-vote counts are shown on only some reviews, so a value of 0 means "not shown" rather than "zero votes."
Next Steps
Featured reviews are easy to scrape for a quick snapshot, while logged-in scraping unlocks more of the review history but comes with higher risk and strict legal limits. We only suggest this for personal use.
But you can't just pick random products to scrape reviews from. You need a source of product ASINs first.
To build your product list, you can either scrape Amazon search results for a specific keyword or category, or scrape Amazon best sellers to get the top-performing products in any category. Both methods give you ASINs you can then feed into your review scraper.
If you're evaluating different tools for Amazon scraping, check out our comparison of the best Amazon scraper APIs to find the right solution for your needs.
Scrape.do handles the heavy lifting by providing proxies, geo-targeting, rendering, and session management. You can focus on extracting the data you need.
Get 1000 free credits and start scraping →
FAQ
Can you view Amazon reviews without logging in?
No, you can't view all reviews of an Amazon product without logging in. Amazon limits the number of reviews visible to logged-out users.
What the public product page does expose is a curated sample of roughly 8 to 13 featured reviews, which is exactly what our first method extracts via the Amazon Scraper API. You can use that sample to form an opinion about a product without any logins, but the full review set is not available unless you log in.
Is scraping Amazon reviews allowed by terms of service?
No. Amazon's Terms of Service explicitly prohibit "the use of data mining, robots, or similar data gathering and extraction tools."
That said, scraping public data like product pages and search results sits in a legal gray area. Since you never agreed to the ToS (you didn't log in), the enforceability of those terms is questionable in many jurisdictions.
But scraping reviews behind a login is different. You've actively agreed to the ToS by creating an account, and the data isn't publicly accessible. Doing this commercially or at scale can result in serious backlash, including account bans, legal threats, or worse.
Our recommendation: stick to featured reviews on public product pages for any commercial use.
Software Engineer








