Category:Scraping Basics
Advanced Web Scraping Techniques in PHP: A Comprehensive Guide

Senior Technical Writer



Web scraping, the art of extracting data directly from websites, has become an indispensable tool for businesses and developers. While numerous programming languages can be used to scrape data, PHP stands out due to its robust server-side capabilities.
PHP’s ability to integrate with web servers, extensive libraries, and ease of handling HTTP requests and responses makes it an essential tool for developers looking to build efficient and scalable web scraping solutions.
In the following sections, we will explore the techniques, best practices, and real-world applications of web scraping with PHP. Without further ado, let’s dive right in.
Setting Up The Environment
To embark on your web scraping journey with PHP, you'll need a solid foundation. This involves setting up your PHP environment and installing essential tools.
Prerequisites
- PHP installation: Ensure PHP is installed on your system. You can verify this by running php -v in your terminal. If it’s not, you can install it by running your CMD as administrator and inputing the folloowing:
choco install PHP #windows
brew install php #macOS
sudo apt-get install php #linuxComposer: Next you’ll need to install composer, a dependency manager for that makes it easy to install and manage the libraries you need for web scraping. While your CMD is still in administrator, run the following code:
choco install composer- Guzzle: Guzzle is a popular HTTP client for PHP that simplifies making HTTP requests. You can install it using Composer:
composer require guzzlehttp/guzzlecURL: cURL is a library that allows PHP to transfer data using various protocols, including HTTP, HTTPS, and FTP. cURL is typically included in the default PHP installation, but if it’s not installed in your system, you can install it like this:
choco install curl #windows
sudo apt install curl #linuxA text editor or IDE: Choose a suitable code editor or Integrated Development Environment (IDE) for writing PHP scripts. Popular options include Sublime Text, Visual Studio Code, and PhpStorm.
By following these steps, you'll have a fully-equipped PHP development environment that's ready to tackle your web scraping projects. Next, let’s dive into the core concepts and techniques of web scraping using PHP.
HTTP Requests in PHP
Before diving into code, let's briefly recap HTTP requests. These are the fundamental way clients (like your PHP script) communicate with servers. There are several methods, but we'll focus on the most common:
- GET: Retrieves data from a specified resource.
- POST: Submits data to be processed by the specified resource.
- PUT: Updates a specified resource.
- DELETE: Deletes a specified resource.
At the core of web scraping is the ability to send HTTP requests and process the responses. PHP offers multiple ways to accomplish this, with cURL and Guzzle being two popular options.
Making HTTP Requests with cURL and Guzzle
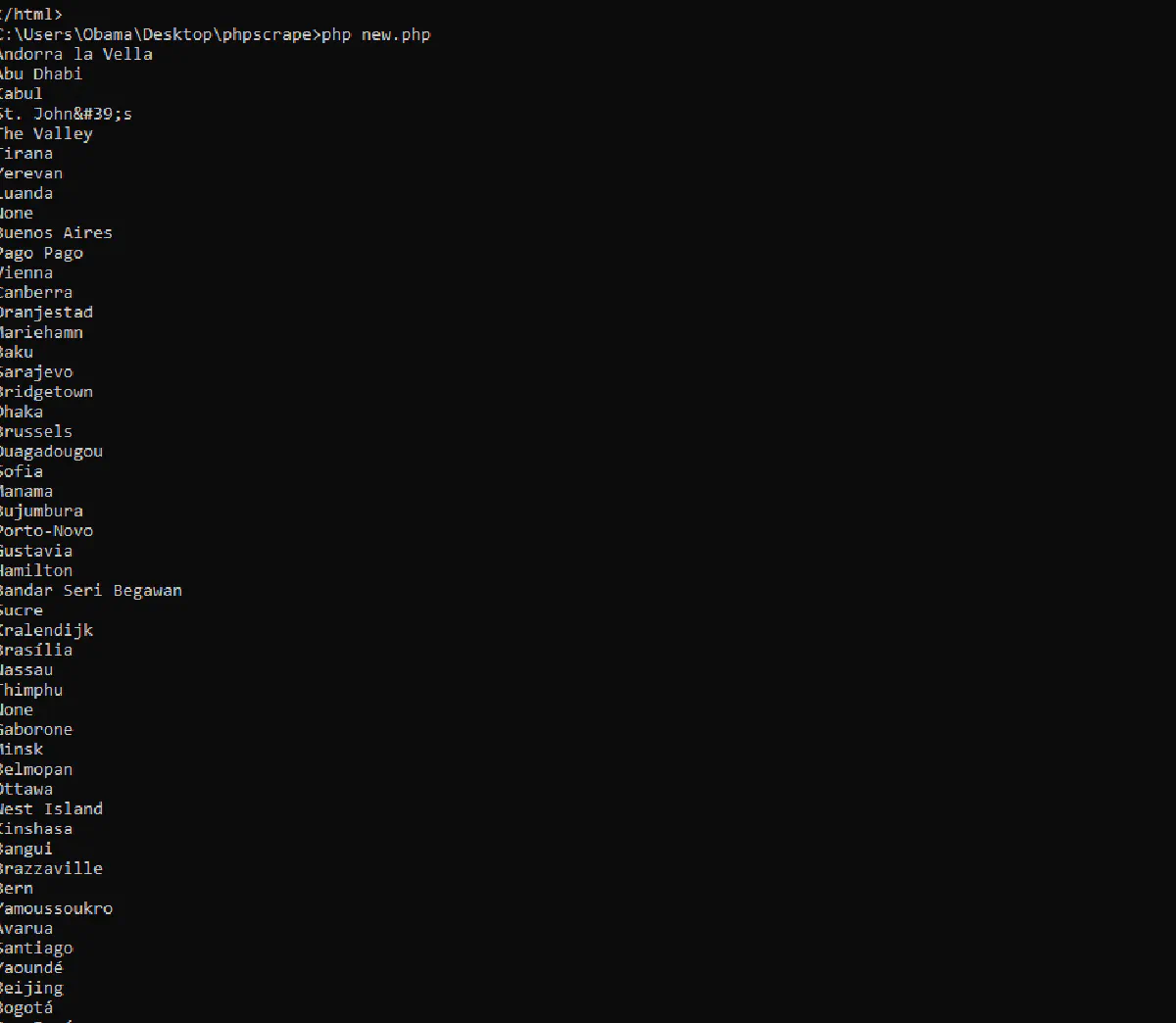
For this example of how to make Get requests with cURL, we’ll be using scrapethissite, a demo site for scraping data. If we want to know get only the country capitals on the site using cURL, here’s how you’d do that.
<?php
// Initialize cURL session
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/simple/");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); // Return the response as a string
// Disable SSL verification (not recommended for production)
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
$response = curl_exec($ch); // Execute the request and store the response
if (curl_errno($ch)) {
// If there's an error, display it
echo 'Error:' . curl_error($ch);
} else {
// Use a regular expression to find all <span class="country-capital"> elements
preg_match_all('/<span class="country-capital">([^<]+)<\/span>/', $response, $matches);
// Check if matches are found
if (!empty($matches[1])) {
foreach ($matches[1] as $capital) {
// Output the capital city name
echo $capital . "\n";
}
} else {
echo "No elements found with class 'country-capital'.";
}
}
curl_close($ch); // Close the cURL sessionThe result would look like this:
To achieve the same result with Guzzle, you’d have to first, istall all the dependencies you’ll need:
composer require guzzlehttp/guzzle symfony/dom-crawler symfony/css-selectorNext, run the following script:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
class CapitalScraper {
private $client;
public function __construct() {
// Initialize the Guzzle client
$this->client = new Client([
'verify' => false, // Disable SSL verification for simplicity
]);
}
public function scrapeCapitals($url) {
try {
// Make a GET request to the specified URL
$response = $this->client->request('GET', $url);
// Check if the request was successful
if ($response->getStatusCode() === 200) {
// Get the HTML content from the response
$html = $response->getBody()->getContents();
// Initialize Symfony's DomCrawler with the HTML content
$crawler = new Crawler($html);
// Use CSS selectors to filter and extract the capital names
$capitals = $crawler->filter('.country-capital')->each(function (Crawler $node) {
return $node->text();
});
// Output the results
if (!empty($capitals)) {
foreach ($capitals as $capital) {
echo $capital . "\n";
}
} else {
echo "No elements found with class 'country-capital'.";
}
} else {
echo "Failed to fetch the webpage. HTTP Status Code: " . $response->getStatusCode();
}
} catch (Exception $e) {
echo "An error occurred: " . $e->getMessage();
}
}
}
// Usage example:
$scraper = new CapitalScraper();
$scraper->scrapeCapitals('https://www.scrapethissite.com/pages/simple/');cURL PHP and Guzzle PHP also provide the flexibility to execute various HTTP request methodsallowing you interact with web services and APIs to retrieve, create, modify, or delete data as needed.
Managing Headers, Cookies, and Sessions
cURL and Guzzle have a lot of uses in PHP web scraping. With these libraries, you can easily set and manage headers, cookies, and sessions. Here’s an example:
- Headers:
// cURL
curl_setopt($curl, CURLOPT_HTTPHEADER, ['Authorization: Bearer your_token']);
// Guzzle
$headers = ['Authorization' => 'Bearer your_token'];
$response = $client->get('https://api.example.com/data', ['headers' => $headers]);
- Cookies:
// curl
$curl = curl_init(); // Initialize cURL session
curl_setopt($curl, CURLOPT_URL, "https://www.scrapethissite.com/pages/simple/"); // Set the URL
curl_setopt($curl, CURLOPT_COOKIE, 'session_id=12345'); // Set the cookies
$response = curl_exec($curl); // Execute the request
curl_close($curl); // Close the cURL session
// Guzzle
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Cookie\CookieJar;
$client = new Client();
$cookies = CookieJar::fromArray(['session_id' => '12345'], 'api.example.com'); // Set the cookies
$response = $client->get('https://api.example.com/data', ['cookies' => $cookies]); // Make the GET request with cookiesRemember, these are not ready-to-use examples, and to use this, you’ll need to replace 'api.example.com' with the actual domain where the session_id cookie is valid.
- Sessions: Guzzle automatically manages sessions if you use a CookieJar instance across multiple requests, but for more complex session management, consider using PHP's built-in session handling or dedicated session libraries.
Parsing HTML Content
Parsing HTML content is a common requirement when scraping data from web pages. PHP provides several tools for this, including built-in classes like DOMDocument, XPath, and third-party libraries like Symfony's DomCrawler. Here’s how to use these tools effectively.
Using DOMDocument for HTML Parsing
DOMDocument PHP is a core PHP class that’s fundamental for parsing HTML. It creates a Document Object Model (DOM) representation of the HTML structure, allowing you to navigate and manipulate it. Here’s an example:
$html = file_get_contents('https://example.com');
$dom = new DOMDocument();
@$dom->loadHTML($html); // @ suppresses warnings for malformed HTML
// Find all <a> tags
$links = $dom->getElementsByTagName('a');
foreach ($links as $link) {
echo $link->getAttribute('href') . "\n";
}XPath for Precise Data Extraction
XPath PHP is a powerful language for navigating XML and HTML structures. It can be used with DOMXPath to run XPath queries on a DOMDocument object for precise data extraction. Here’s an example that finds all div elements with the class product:
$html = file_get_contents('https://example.com'); // Fetch HTML content
$dom = new DOMDocument();
@$dom->loadHTML($html); // Load HTML into DOMDocument
$xpath = new DOMXPath($dom);
// Find all <div> elements with class 'product'
$products = $xpath->query("//div[@class='product']");
foreach ($products as $product) {
// Extract product name and price
$name = $xpath->query(".//h2[@class='product-name']", $product)->item(0)->nodeValue;
$price = $xpath->query(".//span[@class='price']", $product)->item(0)->nodeValue;
echo "Product: $name, Price: $price\n"; // Output product details
}Using Third-Party Libraries Like Symfony's DomCrawler
For more complex HTML parsing tasks, you can use Symfony's DomCrawler component, as it offers a higher-level abstraction and a more user-friendly API for finding elements, traversing the DOM, and extracting data.
You can install DomCrawler via Composer:
composer require symfony/dom-crawler
Here’s a basic example of how to use it for HTML parsing:
require 'vendor/autoload.php';
use Symfony\Component\DomCrawler\Crawler;
$html = '<html><body><p class="example">Hello, World!</p></body></html>';
$crawler = new Crawler($html);
// Find all <p> elements with class "example"
$crawler->filter('p.example')->each(function (Crawler $node) {
echo $node->text(); // Output: Hello, World!
});DomCrawler supports more advanced queries, including filtering based on attributes, classes, and more.
$html = '<html><body>
<div class="container">
<p class="example">Hello, World!</p>
<a href="https://example.com">Example</a>
</div>
</body></html>';
$crawler = new Crawler($html);
// Extract text content from elements
$text = $crawler->filter('p.example')->text(); // "Hello, World!"
$link = $crawler->filter('a')->attr('href'); // "https://example.com"
echo $text;
echo $link;
Handling Dynamic Content
Web scraping can be challenging when dealing with JavaScript-rendered content, as the data you want may not be present in the initial HTML response. In such cases, traditional HTML parsers like DOMDocument won't suffice, and you'll need to use a technique that can handle dynamic content.
Techniques to Scrape JavaScript-Rendered Content
- Headless Browsers: Headless browsers like Puppeteer, Playwright, and Selenium can render JavaScript just like a regular browser. They allow you to interact with the page, execute JavaScript, and extract content after the page has fully loaded.
- API Inspection: Many dynamic websites load data via API calls. You can inspect these calls using browser developer tools and replicate them in your PHP script.
- Using a Service: When dealing with JavaScript-rendered content, use a service like Scrape.do can be an effective solution. Scrape.do handles the complexities of JavaScript rendering and returns the processed HTML, allowing you to focus on extracting the data you need.Scrape.do is a web scraping API that simplifies scraping dynamic content. It manages the browser automation for you, so you can easily scrape content from JavaScript-heavy websites without setting up headless browsers or handling complex configurations.
Using Headless Browsers with PHP
Headless browsers provide a solution by simulating a real browser environment without a graphical interface. They can execute JavaScript, render the page, and then provide the fully loaded HTML for scraping.
Puppeteer, a Node.js library, is a popular choice for controlling Chrome or Chromium in headless mode. To integrate it with PHP, we typically use a separate Node.js script to handle the scraping and then pass the results to PHP for further processing.
Let’s create an example of using a headless browser to scrape dynamic content and process it in PHP. We’ll use this Scraping course dummy site, which generates dynamic content via infinite scrolling.
First, make sure Node.js is installed, then install Puppeteer:
npm install puppeteer
Next, we’ll create a JavaScript file named scrape_images.js with the following content:
// Import the Puppeteer library, which provides a high-level API to control headless Chrome or Chromium browsers.
const puppeteer = require('puppeteer');
(async () => {
// Launch a new browser instance in headless mode (i.e., without a graphical user interface).
const browser = await puppeteer.launch({ headless: true });
// Open a new page (tab) in the browser.
const page = await browser.newPage();
// Navigate to the specified URL with the 'networkidle2' option, which waits until there are no more than 2 network connections for at least 500ms.
// This helps ensure that the page is fully loaded before proceeding.
await page.goto('https://www.scrapingcourse.com/infinite-scrolling', { waitUntil: 'networkidle2' });
// Infinite scrolling logic: This section will repeatedly scroll the page down until no new content is loaded.
let previousHeight;
while (true) {
// Evaluate the current scroll height of the page. This is used to determine if the page height changes after scrolling.
previousHeight = await page.evaluate('document.body.scrollHeight');
// Scroll the page to the bottom by setting the scroll position to the current scroll height.
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)');
// Wait for 2 seconds to allow new content to load after scrolling.
// This delay gives time for any asynchronous JavaScript on the page to fetch and render more content.
await new Promise(resolve => setTimeout(resolve, 2000));
// Re-evaluate the scroll height of the page after scrolling. If the height hasn't changed, it means no new content was loaded.
let newHeight = await page.evaluate('document.body.scrollHeight');
// If the new height is the same as the previous height, break the loop as it indicates the end of the content.
if (newHeight === previousHeight) {
break; // Exit the loop.
}
}
// Scrape all image URLs from the page. This step is done after all content has been loaded via infinite scrolling.
const imageUrls = await page.evaluate(() => {
let urls = [];
// Select all <img> elements on the page and extract their 'src' attribute, which contains the image URL.
document.querySelectorAll('img').forEach((img) => {
urls.push(img.src);
});
// Return the list of URLs as an array.
return urls;
});
// Print the extracted image URLs as a JSON string to the console. This output can be captured by another script, such as PHP, for further processing.
console.log(JSON.stringify(imageUrls)); // Output the URLs as JSON
// Close the browser to free up resources. This is important for cleaning up after the script completes its task.
await browser.close();
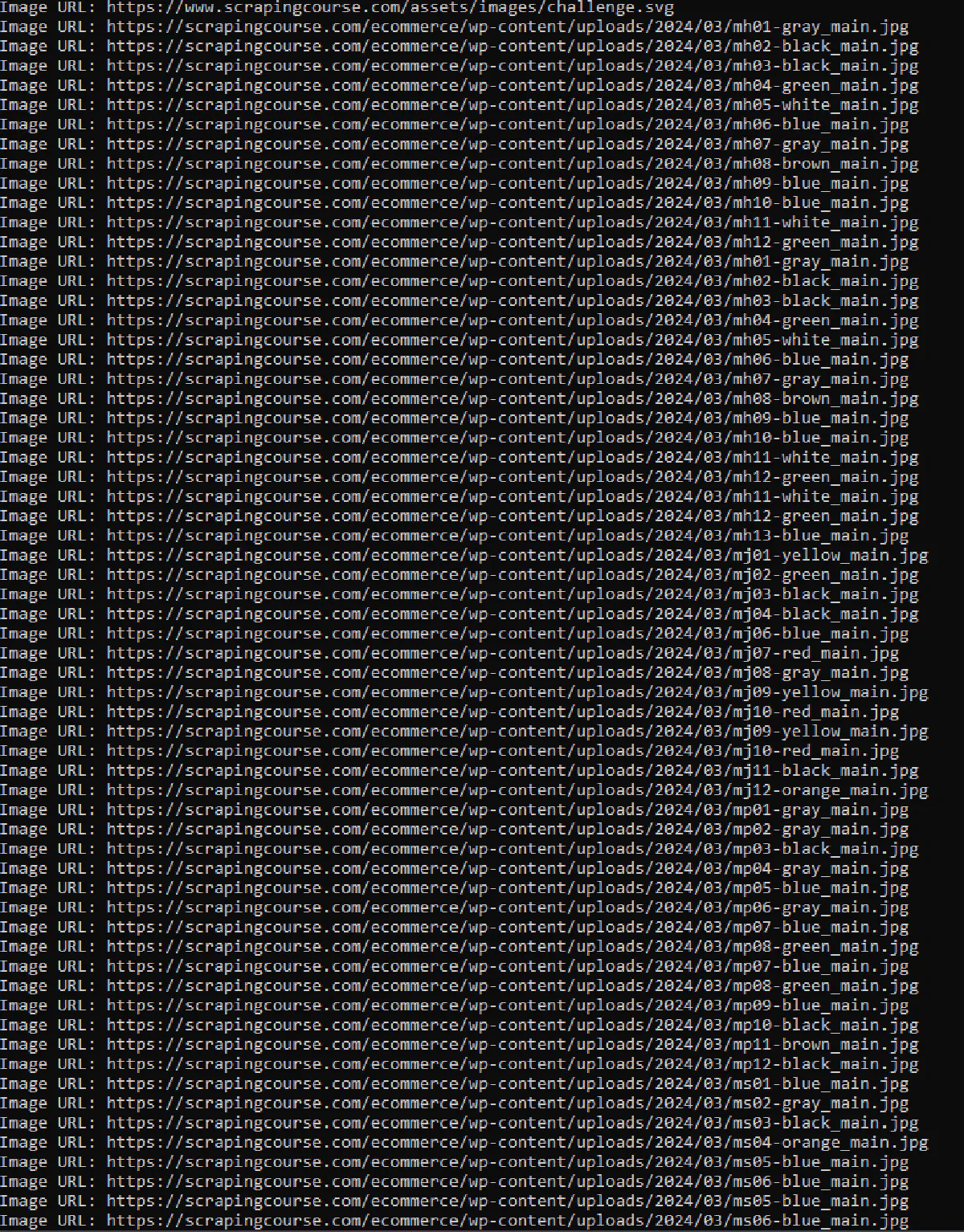
})();This code effectively scrapes image URLs from the website using Puppeteer. It launches a headless browser, navigates to the target website, and continuously scrolls down to load all content. Once fully loaded, it extracts the image URLs from all image elements on the page and outputs them as JSON.
Next, create a PHP script named scrape_images.php to execute the Puppeteer script and handle the output:
<?php
// Run the Puppeteer script
$output = shell_exec('node scrape_images.js');
// Decode the JSON output
$imageUrls = json_decode($output, true);
if (is_array($imageUrls)) {
// Process and display the image URLs in PHP
foreach ($imageUrls as $url) {
echo "Image URL: $url\n";
}
} else {
echo "Failed to retrieve image URLs or the output is not an array.\n";
}Finally, you can run the code as before:
php scrape_images.php
Here’s what the result would look like.
Scraping APIs vs Traditional PHP Scraping
Building your own scraper in PHP gives you full control—but it also means managing:
- Proxy rotation
- Header and TLS fingerprint spoofing
- CAPTCHA detection and solving
- Rate limiting and session handling
- Geo-targeting
- JavaScript rendering
Each of these takes time to implement, debug, and maintain. And even then, a single WAF update can break your scraper overnight.
That’s where scraping APIs like Scrape.do come in.
Instead of solving each challenge yourself, you can offload the infrastructure to Scrape.do and focus entirely on extracting and storing the data.
Scrape.do handles:
- IP rotation with 100M+ residential, mobile, and datacenter proxies
- Header, fingerprint, and browser simulation
- CAPTCHA solving and retries
- JavaScript rendering and session persistence
- Domain-specific optimizations and failover retries
You only need to send a request—Scrape.do does the rest.
And you only pay for successful results.
Try it for free with 1000 credits.
Dealing with Anti-Scraping Measures
PHP data scraping can be a game of cat and mouse when dealing with websites that use anti-scraping measures to protect their data. Understanding these mechanisms and employing ethical techniques to bypass them is essential for effective and responsible scraping with PHP.
Common Anti-Scraping Mechanisms
- IP Blocking: Websites can block your IP address if they detect multiple requests coming from the same IP in a short period.
- CAPTCHAs: CAPTCHA systems are used to differentiate between bots and humans by presenting challenges that are difficult for bots to solve.
- Rate Limiting: Websites often limit the number of requests you can make in a given time frame to prevent excessive scraping.
- User-Agent Detection: Some websites block requests from non-browser User Agents (e.g., cURL, and Python requests) to filter out bots.
- JavaScript Challenges: Some sites use JavaScript to generate dynamic content or to challenge scrapers with JavaScript execution tests.
Techniques to bypass IP blocks, CAPTCHAs, and rate-limiting
Handling IP blocks: To bypass IP blocks, you can introduce delays between requests to mimic human browsing behavior. This can help avoid triggering rate limits.
function makeRequest($url) {
sleep(rand(1, 5)); // Random delay between 1 and 5 seconds
// Make the request
}
A better way to avoid IP blocks is using proxies to mask your IP address. Rotating proxies can distribute requests across multiple IP addresses, reducing the likelihood of getting blocked. Scrape.do offers a large pool (over 95 million) of rotating proxies, including data center, mobile, and residential options. This variety is important, as it ensures you can access websites from various locations without restrictions.
- Bypassing CAPTCHAs: You can use services like 2Captcha and Anti-Captcha that provide API access to human workers or AI that can solve CAPTCHAs, or develop custom machine learning models to solve simple CAPTCHAs, although these require significant expertise. A simpler way would be using Scrape.do to get all your data, as it solves the captcha issue by detecting it and immediately assigning an IP from a new location. Fully automatic, no need to waste your time!
- Mimicking Real Users: You can randomize User-Agent strings to mimic requests coming from different browsers and devices, and also maintain session cookies across requests to simulate a continuous browsing session. When using headless browser PHP like Puppeteer, you can use additional configurations or plugins like puppeteer-extra-plugin-stealth to evade headless browser detection.
Ethical Considerations and Adhering to Website Terms of Service
Ethical scraping involves respecting the target website’s terms of service (ToS) and considering the potential impact on their servers and resources. Here are some guidelines:
- Respect Robots.txt: Always check the website's robots.txt file to see if it permits or disallows scraping of specific pages or content.
- Avoid Overloading Servers: Limit the frequency of your requests to avoid putting excessive load on the website’s servers. Implement delays and respect rate limits.
- Respect Data Privacy: Be mindful of the data you’re scraping, particularly if it involves user data or sensitive information. Ensure compliance with data protection regulations like GDPR.
- Obtain Permission When Possible: If you plan to scrape a website extensively or for commercial purposes, consider asking the website owner for permission.
- Transparency: Consider informing the website owner about your scraping activities, especially if the data will be used for public or commercial purposes.
Data Storage and Management
After successfully scraping data, proper storage and management are crucial for easy access and analysis. Depending on your needs, you might store the data in formats like JSON or CSV, or use databases like MySQL or MongoDB for more complex storage and querying. Let’s look at some example scripts for storing scraped data in each of these formats, along with best practices for data validation and cleaning.
Storing Scraped Data in JSON Format
JSON is a lightweight data interchange format that's easy to read and write for both humans and machines. Here’s how to store scrapped data in JSON:
$data = [
['title' => 'Book 1', 'author' => 'Author 1', 'price' => 9.99],
['title' => 'Book 2', 'author' => 'Author 2', 'price' => 12.99],
];
$jsonData = json_encode($data, JSON_PRETTY_PRINT);
if (file_put_contents('scraped_data.json', $jsonData) !== false) {
echo "Data successfully saved to scraped_data.json";
} else {
echo "Error saving data to file";
}
Storing Scraped Data in CSV Format
CSV (Comma-Separated Values) is a simple format for storing tabular data. Each line corresponds to a row, and each value is separated by a comma.
// Sample data array, representing scraped data
$data = [
['title' => 'Book 1', 'author' => 'Author 1', 'price' => 9.99],
['title' => 'Book 2', 'author' => 'Author 2', 'price' => 12.99],
// Add more data here as needed
];
// Open a file in write mode ('w' mode will overwrite the file if it already exists)
$file = fopen('scraped_data.csv', 'w');
// Add column headers to the CSV file
fputcsv($file, ['Title', 'Author', 'Price']);
// Loop through each row of data
foreach ($data as $row) {
// Write the data row to the CSV file
fputcsv($file, $row);
}
// Close the file to ensure data is saved and resources are freed
fclose($file);
// Output a success message
echo "Data successfully saved to scraped_data.csv";
Storing Data in MySQL Database
For larger datasets or when you need to query the data, a relational database like MySQL can be useful.
function saveToMysql($data, $tableName) {
// Database connection details
$servername = "localhost";
$username = "your_username";
$password = "your_password";
$dbname = "your_database";
// Create a new MySQLi connection
$conn = new mysqli($servername, $username, $password, $dbname);
// Check for a successful connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
// Loop through each row of data
foreach ($data as $row) {
// Escape each value to prevent SQL injection and other security issues
$escapedValues = array_map([$conn, 'real_escape_string'], array_values($row));
// Prepare the column names and values for the SQL statement
$columns = implode(", ", array_keys($row));
$values = "'" . implode("', '", $escapedValues) . "'";
$sql = "INSERT INTO $tableName ($columns) VALUES ($values)";
// Execute the SQL query
if (!$conn->query($sql)) {
// If there's an error, output the SQL statement and the error message
echo "Error: " . $sql . "<br>" . $conn->error;
}
}
// Close the database connection
$conn->close();
}
// Example usage with sample data
$scrapedData = [
['title' => 'Product 1', 'price' => 19.99],
['title' => 'Product 2', 'price' => 29.99]
];
// Save the data to the 'products' table
saveToMysql($scrapedData, 'products');
Storing Scraped Data in a MongoDB Database
MongoDB is a popular NoSQL database, ideal for storing unstructured or semi-structured data.
require 'vendor/autoload.php'; // Ensure MongoDB PHP Library is installed
// Connect to MongoDB
$client = new MongoDB\Client("mongodb://localhost:27017");
// Select a database and collection
$collection = $client->scraping_db->books;
// Data to insert
$data = [
['title' => 'Book 1', 'author' => 'Author 1', 'price' => 9.99],
['title' => 'Book 2', 'author' => 'Author 2', 'price' => 12.99],
// Add more data here
];
// Insert data into MongoDB
$insertManyResult = $collection->insertMany($data);
echo "Inserted " . $insertManyResult->getInsertedCount() . " documents into MongoDB.";
Best Practices for Data Validation and Cleaning
Ensuring data quality is crucial for accurate analysis. Hwew are some key rules to follow when cleaning data and validating it:
- Type Checking: Ensure that data types are correct (e.g., prices are numeric).
- Required Fields: Check for the presence of mandatory fields before storing data.
- Range Checking: Validate that numeric values fall within expected ranges.
- Regex Validation: Use regular expressions to validate strings like email addresses or phone numbers.
- Trimming: Remove leading and trailing whitespace from strings.
- Normalization: Standardize data formats (e.g., converting all text to lowercase, consistent date formats).
- Deduplication: Identify and remove duplicate entries.
- Error Handling: Implement error handling to manage missing or malformed data without crashing the script.
Error Handling and Logging
Implementing error handling and logging is important to ensure that your scripts can gracefully handle issues such as request failures, timeouts, and parsing errors. Proper logging also helps in monitoring the scraping process and troubleshooting any issues that arise.
Let’s look at how to implement error handling and logging in your scraping scripts.
Error Handling
Error handling is the process of responding to and managing errors that occur during the execution of your code. In web scraping, common issues include request failures, timeouts, and parsing errors.
function makeRequest($url) {
try {
// Initialize cURL session
// cURL is a tool that allows you to make HTTP requests in PHP. The curl_init() function initializes a new session.
$ch = curl_init();
// Set the URL to request
// CURLOPT_URL is used to specify the URL you want to fetch with cURL.
curl_setopt($ch, CURLOPT_URL, $url);
// Return the response as a string instead of outputting it directly
// CURLOPT_RETURNTRANSFER tells cURL to return the response as a string, rather than outputting it directly to the browser.
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// Set a timeout for the request
// CURLOPT_TIMEOUT sets the maximum number of seconds to allow cURL functions to execute. If the request takes longer than 10 seconds, it will be terminated.
curl_setopt($ch, CURLOPT_TIMEOUT, 10); // Set timeout to 10 seconds
// Execute the cURL request and store the response
// curl_exec() executes the cURL session and returns the response as a string because CURLOPT_RETURNTRANSFER is set to true.
$response = curl_exec($ch);
// Check if there was a cURL error
// curl_errno() returns the error number for the last cURL operation. If it returns a non-zero value, it means an error occurred.
if (curl_errno($ch)) {
// Throw an exception if a cURL error occurred
throw new Exception('Request Error: ' . curl_error($ch)); // curl_error() returns a string containing the last error for the current session.
}
// Check for HTTP errors
// curl_getinfo() retrieves information about the cURL session, such as the HTTP status code.
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($httpCode >= 400) {
// Throw an exception if the HTTP status code is 400 or higher (indicating an error)
throw new Exception('HTTP Error: ' . $httpCode);
}
// Close the cURL session
// curl_close() closes the cURL session and frees all resources. This is important to prevent memory leaks.
curl_close($ch);
// Return the response from the cURL request
return $response;
} catch (Exception $e) {
// Log the error message using a custom logging function
// If an exception is caught, log the error message for debugging and return null.
logError($e->getMessage());
return null;
}
}
function parseHtml($html) {
try {
// Create a new DOMDocument instance
// DOMDocument is a class that represents an entire HTML or XML document. It provides methods for navigating and manipulating the document's structure.
$dom = new DOMDocument();
// Load the HTML content into the DOMDocument object
// loadHTML() parses the HTML string and loads it into the DOMDocument object. The @ operator suppresses any warnings that might be generated by malformed HTML.
@$dom->loadHTML($html);
// Additional parsing logic can be added here...
// You can use DOMXPath or other methods to query and manipulate the DOMDocument object.
// Return the DOMDocument object for further processing
return $dom;
} catch (Exception $e) {
// Log the error message using a custom logging function
// If an exception is caught during parsing, log the error message for debugging and return null.
logError('Parsing Error: ' . $e->getMessage());
return null;
}
}
// Example logError function
function logError($message) {
// Define the log file path
$logFile = 'error_log.txt';
// Format the log message with a timestamp
$logMessage = date('Y-m-d H:i:s') . ' - ' . $message . PHP_EOL;
// Append the log message to the log file
file_put_contents($logFile, $logMessage, FILE_APPEND);
}
The provided code demonstrates a solid foundation for error handling in web scraping. It effectively utilizes try-catch blocks, custom error handling for cURL and HTTP errors, and basic error logging.
Logging
Logging is essential for monitoring the execution of your scripts and identifying issues. PHP provides several ways to implement logging, including writing to log files or using external logging libraries. Here’s a simple implementation of logging:
function logError($message) {
// Define the log file path
$logFile = 'scraping_log.txt';
// Format the log message with a timestamp
$logMessage = date('Y-m-d H:i:s') . ' - ERROR: ' . $message . PHP_EOL;
// Append the log message to the log file
file_put_contents($logFile, $logMessage, FILE_APPEND);
}
Optimizing Scraping Performance
If you’re dealing with dealing with large volumes of data or need to scrape data in real-time, you’ll need to optimize your scraping performance. To do that, you can use any of the following techniques:
Caching: Use caching to store previously scraped data and avoid re-scraping the same content. Tools like Redis or Memcached can help with this.
Rate Limiting: Implement rate limiting to avoid being blocked by the target site. This involves introducing delays between requests or limiting the number of requests per second.
User-Agent Rotation: Rotate User-Agent strings and other headers to mimic requests coming from different browsers and devices, reducing the risk of being blocked.
Proxy Rotation: Use a pool of web scraping proxies and rotate them regularly to distribute the load and avoid IP bans.
In addition to these techniques, you can also use synchronous requests with Guzzle and implement multi-threading in PHP to boost performance. Let’s discuss those in more detail.
Asynchronous Requests with Guzzle
Guzzle supports asynchronous requests, allowing you to send multiple requests simultaneously without waiting for each one to complete before starting the next. This can significantly speed up your scraping tasks. Here’s an example of how to use Guzzle to send asynchronous requests:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Promise\Utils;
use GuzzleHttp\Exception\RequestException;
$client = new Client();
// Array of URLs to scrape
$urls = [
'http://example.com/page1',
'http://example.com/page2',
'http://example.com/page3',
// Add more URLs here
];
$promises = [];
// Create an array of promises for asynchronous requests
foreach ($urls as $url) {
$promises[$url] = $client->getAsync($url);
}
// Wait for all the requests to complete using Utils::settle
$results = Utils::settle($promises)->wait();
// Process the results
foreach ($results as $url => $result) {
if ($result['state'] === 'fulfilled') {
$response = $result['value'];
echo "Scraped $url successfully: " . substr($response->getBody(), 0, 100) . "\n"; // Example processing
} else {
$reason = $result['reason'];
// Check if the reason is a RequestException, which it likely is
if ($reason instanceof RequestException) {
// Get the HTTP status code if available
$statusCode = $reason->getResponse() ? $reason->getResponse()->getStatusCode() : 'unknown status';
$message = $reason->getMessage();
echo "Failed to scrape $url: HTTP $statusCode - " . strtok($message, "\n") . "\n";
} else {
echo "Failed to scrape $url: " . $reason . "\n";
}
}
}
In the example, getAsync() sends a request but doesn’t wait for it to complete. Instead, it returns a promise that will be resolved when the request is completed. Promise\settle() is used to wait for all promises to be settled, meaning they are either completed successfully or failed. After all requests are settled, you can process the results. Each result indicates whether the request was fulfilled or rejected.
Multi-threading in PHP
PHP is not inherently designed for multi-threading, but you can achieve parallel processing using libraries or extensions like pthreads or by running multiple processes. Here's a basic example using pthreads to create and manage multiple threads:
<?php
// Define a WorkerThread class that extends the Thread class provided by the pthreads extension
class WorkerThread extends Thread {
// The run() method is called when the thread starts
public function run() {
// Output a message that includes the current thread's ID
echo "Thread " . Thread::getCurrentThreadId() . " is running\n";
}
}
// Create an array to hold the WorkerThread instances
$workers = [];
// Start 5 threads
for ($i = 0; $i < 5; $i++) {
// Create a new WorkerThread instance
$workers[$i] = new WorkerThread();
// Start the thread, which will trigger the run() method
$workers[$i]->start();
}
// Wait for all threads to finish execution
foreach ($workers as $worker) {
// join() waits for the thread to finish before continuing
$worker->join();
}
*Caution: Using multi-threading or processes in PHP can be complex and requires careful management of shared resources. It's generally recommended for specific use cases where performance gains outweigh the added complexity.*
Practical Example
This article covers a lot, so let’s put it to practice with a real-world example. We’ll be scraping the names of Hockey teams from a site and handling pagination. We'll use Guzzle for handling HTTP requests, and Symfony's DomCrawler for parsing HTML.
*Note: This script is for educational purposes only. Respect robots.txt and website terms of service before scraping real websites.*
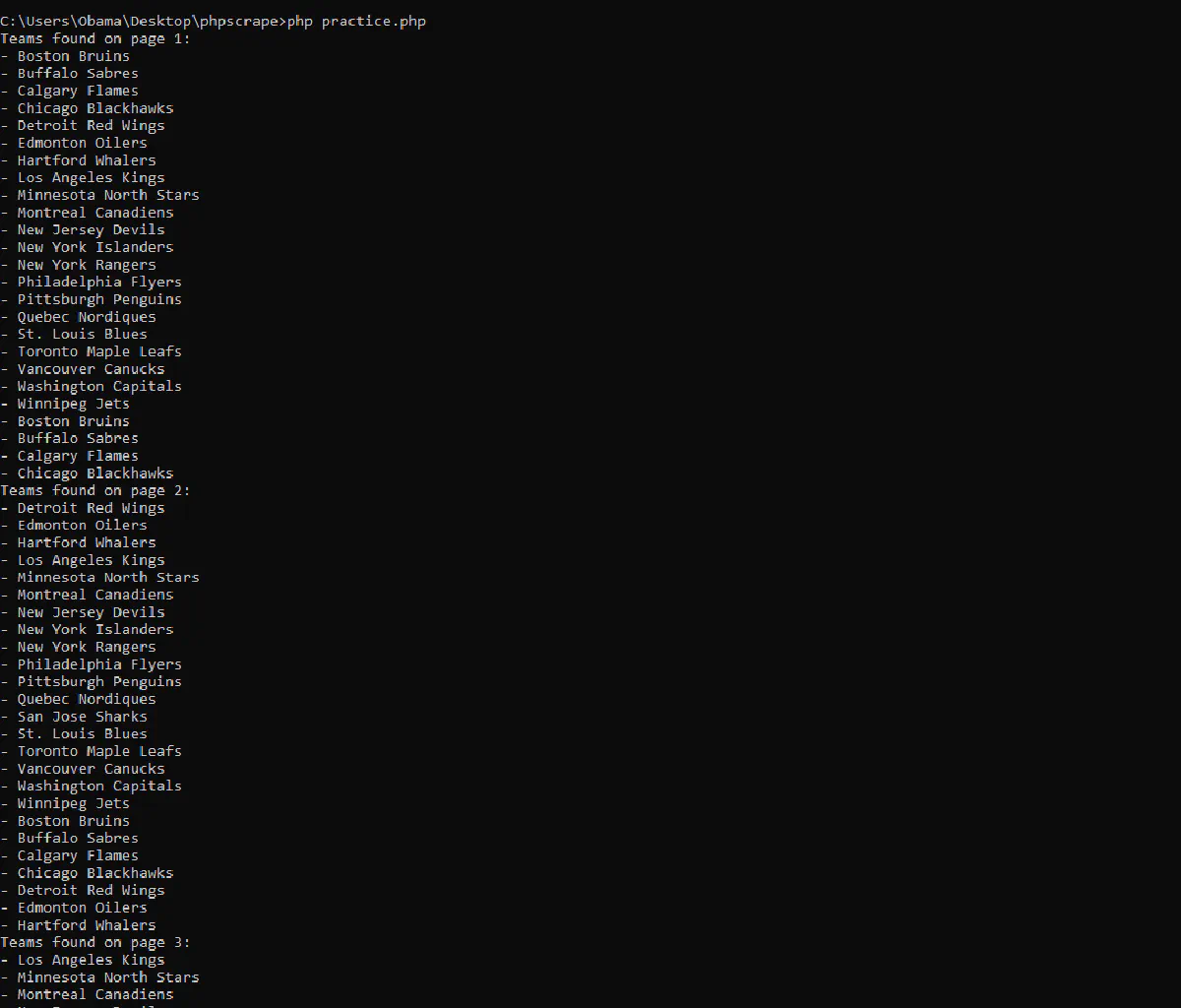
For this example, we’ll be scraping Scrapethissite.com for the titles of 5-star books. This involves navigating through multiple pages and handling pagination. Here’s what that would look like:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Exception\RequestException;
use Symfony\Component\DomCrawler\Crawler;
class FootballTeamScraper {
private $client;
private $baseUrl;
public function __construct($baseUrl) {
$this->client = new Client([
'verify' => false, // Disable SSL verification (not recommended for production)
]);
$this->baseUrl = $baseUrl;
}
public function scrapeAllTeamNames() {
$pageNum = 1;
while (true) {
try {
// Build the URL for the current page
$url = $this->baseUrl . '?page_num=' . $pageNum;
// Fetch the page content
$response = $this->client->request('GET', $url);
// Check if the request was successful
if ($response->getStatusCode() !== 200) {
throw new Exception("Failed to fetch the webpage. HTTP Status Code: " . $response->getStatusCode());
}
$html = $response->getBody()->getContents();
// Create a new Symfony DomCrawler object
$crawler = new Crawler($html);
// Find all team names using CSS selectors
$teamNames = $crawler->filter('tr.team td.name')->each(function (Crawler $node) {
return $node->text();
});
// Display the results if any teams are found
if (!empty($teamNames)) {
echo "Teams found on page $pageNum:\n";
foreach ($teamNames as $teamName) {
echo "- " . trim($teamName) . "\n";
}
} else {
echo "No teams found on page $pageNum.\n";
}
// Check if there is a "next" page link
$hasNextPage = $crawler->filter('a[aria-label="Next"]')->count() > 0;
// If there is no "next" page link, break the loop
if (!$hasNextPage) {
echo "No more pages to process.\n";
break;
}
$pageNum++; // Move to the next page
} catch (RequestException $e) {
echo "An HTTP request error occurred: " . $e->getMessage();
break; // Stop if there is an HTTP error
} catch (Exception $e) {
echo "An error occurred: " . $e->getMessage();
break; // Stop if there is a general error
}
}
}
}
// Usage example:
$baseUrl = 'https://www.scrapethissite.com/pages/forms/';
$scraper = new FootballTeamScraper($baseUrl);
$scraper->scrapeAllTeamNames();
This code demonstrates best PHP web scraping practices, including error handling, URL management, and code organization. It effectively fetches pages, parses the HTML, extracts specific data (titles), and presents the results in a user-friendly format.
For more complex scenarios, it's best to use Scrape.do. Scrape.do handles the low-level details like managing cURL requests, rotating proxies, and bypassing anti-bot measures. You can focus on building the logic for extracting specific data from the website without worrying about infrastructure.
Scrape.do also has a network of servers and proxies to handle large-scale scraping efficiently. It automatically scales resources based on your needs, ensuring faster response times and data retrieval compared to scripts running on your own server.
Additionally, Scrape.do employs techniques to bypass website blocking mechanisms, making it more reliable for complex websites.The best part? You can get access to all of these now for free!
Security and Legal Considerations in Web Scraping
Web scraping can be a powerful tool, but it comes with important security and legal responsibilities. Understanding these aspects helps ensure your activities are not only effective but also compliant with laws and ethical standards.
Security Best Practices for Web Scraping
- Always check the robots.txt file of the website to understand which parts of the site you are allowed to scrape. While robots.txt is not legally binding, respecting it is considered good practice.
- If the site requires authentication, make sure to handle credentials securely. Avoid hardcoding credentials in your scripts, and instead use environment variables or secure vaults.
- Sanitize any data that you send to the website, especially when interacting with forms or URLs, to prevent injection attacks.
- Similarly, validate and sanitize the data you scrape to avoid security vulnerabilities like XSS if the data is displayed in a web application.
- Rotate User-Agent strings to mimic different browsers or devices. This can reduce the likelihood of being identified as a bot.
- Log your scraping activity for monitoring purposes. This helps in troubleshooting and ensures you are aware of how your scraper interacts with the target site.
Legal Aspects of Web Scraping
- Many websites have terms of service that explicitly prohibit scraping. Violating these terms can lead to legal consequences, including being banned from the site, or in some cases, legal action.
- Scraping copyrighted content without permission can lead to intellectual property rights violations. Always check if the data you are scraping is protected by copyright and whether you have the right to use it.
- Only scrape the data that is necessary for your purpose. Collecting excessive data, especially personal data, can violate GDPR principles.
- Under GDPR, individuals have the right to request the deletion of their data. If you store scraped personal data, you must have processes in place to handle such requests.
- Publicly accessible data is generally considered fair game for scraping. However, this does not mean you can scrape it without restrictions.\
- Be aware of the jurisdiction you are operating in and the jurisdiction of the target website. Different countries have different laws regarding web scraping, data privacy, and intellectual property.
Ensuring Compliance with GDPR and Other Data Protection Regulations
- Maintain a data inventory that details what data you collect, why it is collected, where it is stored, and who has access to it. This helps in ensuring compliance with data protection regulations.
- Implement processes to handle requests from individuals exercising their rights under GDPR or CCPA, such as data access, correction, deletion, and objection to processing.
- From the outset, incorporate privacy considerations into the design of your scraping systems. This might involve minimizing data collection, using encryption, and implementing strong access controls.
- When possible, anonymize personal data to reduce the risk of privacy violations. Anonymized data is generally not subject to data protection laws like GDPR.
Conclusion
While this guide gives you the tools to build powerful scrapers in PHP, maintaining reliability and scalability across real-world targets will always be difficult—especially as anti-bot defenses evolve.
That’s where Scrape.do helps.
Whether you're scraping Amazon, real estate listings, or job boards, Scrape.do lets you focus on the logic—not the infrastructure.
- Automatically bypass CAPTCHAs, blocks, and WAFs
- Rotate IPs and headers without lifting a finger
- Scrape JavaScript-heavy sites with full rendering
- Pay only for successful requests
Get started today with 1000 free credits and scrape anything without the headache.
Senior Technical Writer








