Category:Scraping Basics
Web Scraping in Rust

Technical Writer

Rust is a powerful programming language known for its high performance, type safety, and concurrency. Its efficiency and ability to handle large-scale tasks make it an excellent choice for various applications, including web scraping. However, Rust is not as beginner-friendly as Python or JavaScript due to its complex syntax. Not a problem, this is a minor trade-off when performance is crucial for your web scraping tasks. Rust is definitely worth considering if top-notch performance is a priority.
Setting Up the Environment
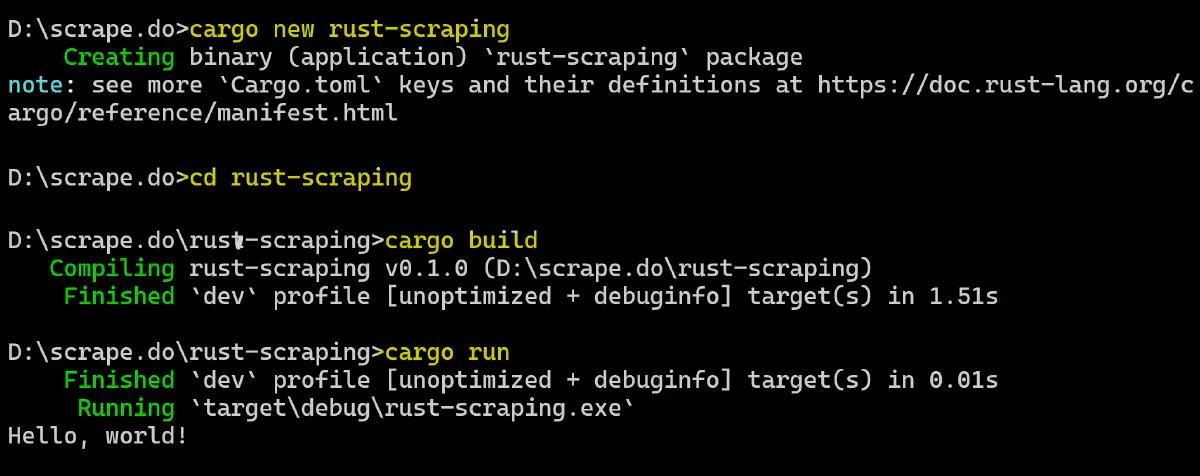
Let's get started with Rust! To create a new Rust project (rust-scraping in my case), open your terminal and run the following Cargo new command:
cargo new rust-scrapingThis command will create a new directory called rust-scraping, containing:
Cargo.toml: The manifest file where you specify the project's dependencies.src/: The folder that contains your Rust files. By default, it initializes with a samplemain.rsfile.
Here’s the sample main.rs file:
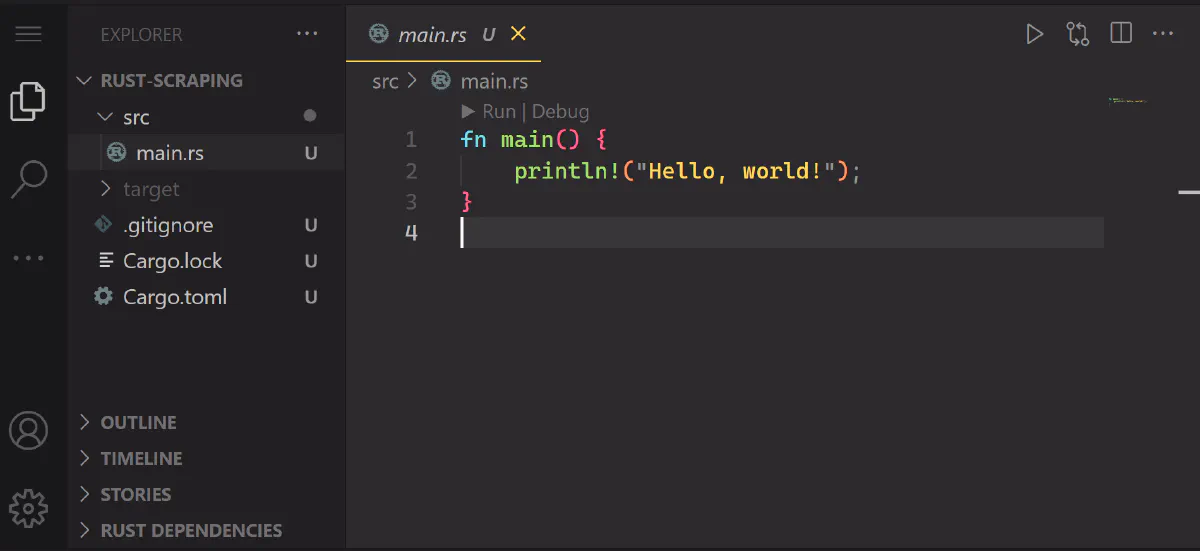
This is the simplest Rust script possible! The main() function serves as the entry point of any Rust application, and it will soon include some web scraping logic.
Next, open the terminal of your IDE and compile your Rust application using the following command:
cargo buildThis command creates a target/ folder in your project’s root directory, which contains the binary files. To run the compiled binary executable, use the command:
cargo runYou should see the following output in the terminal:
Hello, World!Here’s what the complete process looks like:
Great! Your Rust project is up and running. Now it's time to add web scraping functionality.
For web scraping in Rust, you’ll need the following libraries:
- reqwest: Convenient and higher-level HTTP Client.
- scraper: For parsing and querying the HTML of the page.
- Tokio: An asynchronous runtime for Rust.
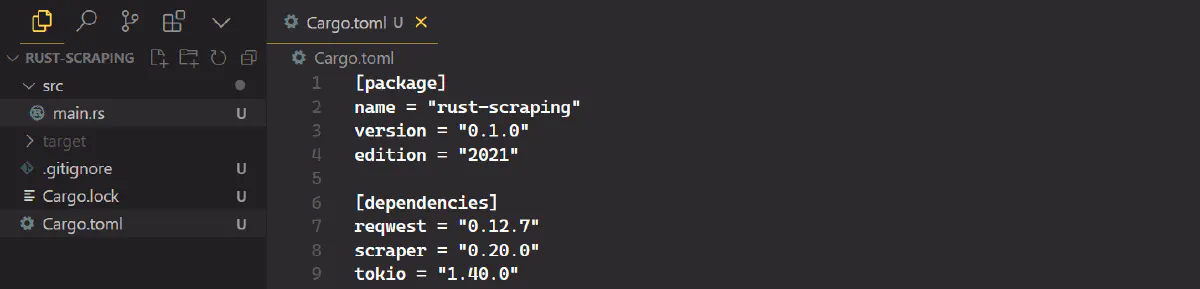
Add these dependencies to your project by running:
cargo add scraper reqwest tokioYour Cargo.toml file will now include these libraries:
Making HTTP Requests
Reqwest is a widely used library for making HTTP requests in Rust which supports both synchronous and asynchronous operations. This versatility makes it suitable for various web scraping needs.
GET Requests
Let's start by making a simple GET request using the reqwest::blocking module. Before running the code, make sure you update your Cargo.toml to include the blocking feature:
[dependencies]
reqwest = { version = "0.12.7", features = ["blocking"] }
scraper = "0.20.0"
tokio = "1.40.0"Here’s the code:
use reqwest;
fn main() -> Result<(), Box<dyn std::error::Error>> {
let body = reqwest::blocking::get("https://httpbin.org/get")?.text()?;
println!("Data: {}", body);
Ok(())
}The blocking client will wait until it receives a response. This method is convenient for applications that only need to make a few requests.
For applications that require handling multiple requests concurrently without blocking the main thread, it's best to use the asynchronous Client from Reqwest, which uses connection pooling to improve performance. Include the necessary dependencies in your Cargo.toml:
[dependencies]
reqwest = { version = "0.12.7" }
scraper = "0.20.0"
tokio = { version = "1.40.0", features = ["full"] }Here's an example of making asynchronous HTTP requests:
use reqwest::Client;
use std::error::Error;
use tokio; // Async runtime
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Async client
let client = Client::new();
// URLs to fetch
let urls = vec![
"https://httpbin.org/get",
"https://httpbin.org/ip",
"https://httpbin.org/user-agent",
];
// Vector to hold futures
let mut tasks = vec![];
// Perform async requests concurrently
for url in urls {
let client = client.clone();
// Spawn async task for each request
let task = tokio::spawn(async move {
let response = client.get(url).send().await?.text().await?;
println!("Response from {}: {}", url, response);
Ok::<_, reqwest::Error>(())
});
tasks.push(task);
}
// Await all tasks to complete
for task in tasks {
task.await??;
}
Ok(())
}The code uses the tokio async runtime and reqwest HTTP client to fetch data from URLs concurrently. It speeds up the process since all requests are made at the same time instead of one after the other. Finally, it waits for all tasks to finish before exiting.
POST Requests
You can use POST requests to send data, such as submitting forms or sending JSON payloads.
To begin, make sure that serde_json is added to your dependencies for handling JSON data. Run the following command:
cargo add serde_jsonbHere's a simple code for sending a JSON payload via a POST request:
use reqwest::Client;
use serde_json::json; // Macro for creating JSON objects
#[tokio::main]
async fn main() -> Result<(), reqwest::Error> {
let client = Client::new();
let payload = json!({
"title": "Scrape.do Services",
"body": "Best Rotating Proxy & Web Scraping API",
"userId": "1"
});
let response = client
.post("https://httpbin.org/post")
.json(&payload)
.send()
.await?;
let data = response.text().await?;
println!("Data: {}", data);
Ok(())
}Here’s the result:
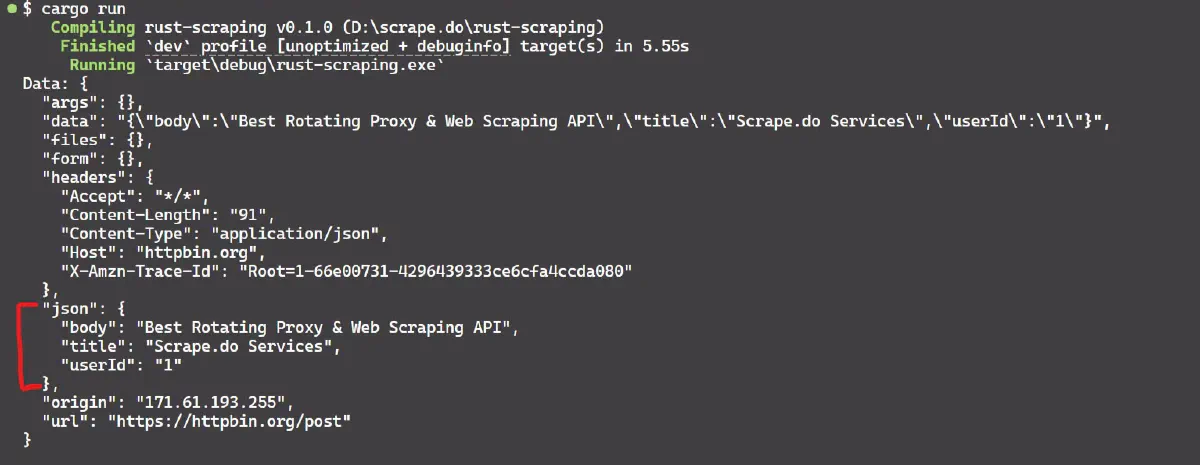
The post() method sends the request, and the json() method adds the payload for easy submission of JSON data.
Customizing Requests with Headers and Sessions
You can customize your requests by adding headers or managing cookies and sessions using the same client instance.
Here's how to include custom headers:
use reqwest::Client;
#[tokio::main]
async fn main() -> Result<(), reqwest::Error> {
let client = Client::new();
let response = client
.get("https://httpbin.org/headers")
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36")
.send()
.await?
.text()
.await?;
println!("Response with Headers: {}", response);
Ok(())
}The result is:
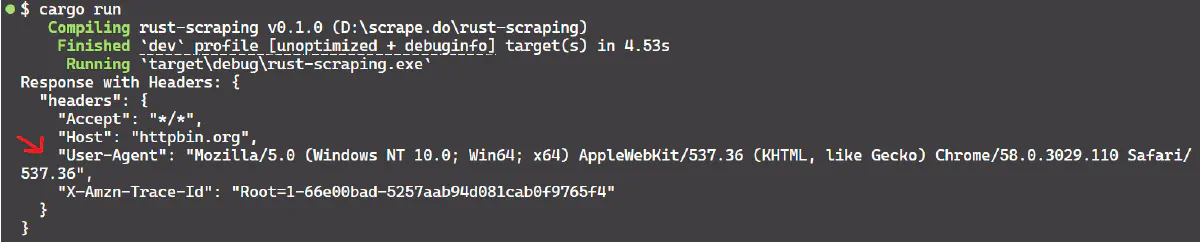
Now, here’s how to manage sessions with cookies:
use reqwest::Client;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let client = Client::builder().cookie_store(true).build()?;
let _ = client
.get("https://httpbin.org/cookies/set?remember_me=true")
.send()
.await?;
let response = client
.get("https://httpbin.org/cookies")
.send()
.await?
.text()
.await?;
println!("Response with Cookies: {}", response);
Ok(())
}Make sure to add the cookies feature along with the existing json feature for reqwest:
[dependencies]
# Added "cookies" feature
reqwest = { version = "0.12.7", features = ["json", "cookies"] }The result is:
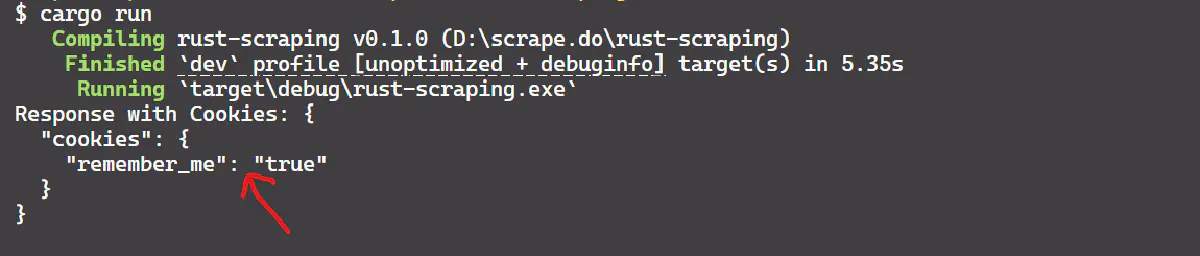
Error Handling and Retry Logic
Implementing proper error handling and retry logic is good practice when building robust web scrapers. These practices help you to manage common errors gracefully and make sure your scraper can retry requests when necessary ultimately increasing the chances of success.
Below is an example that shows how to handle non-success status codes and implement retry logic in Rust:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
match reqwest::get("https://httpbin.org/status/404").await {
Ok(response) => {
if response.status().is_success() {
println!("Response: {:?}", response);
} else {
println!("Received a non-success status: {}", response.status());
}
}
Err(e) => {
// Log the error if the request fails
eprintln!("Error occurred: {}", e);
},
}
Ok(())
}To implement retries, you can use a simple loop or an external crate like retry:
use reqwest::Client;
use tokio::time::{sleep, Duration};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let client = Client::new();
let mut attempts = 0;
while attempts < 3 {
let response = client.get("https://httpbin.org/status/500").send().await;
match response {
Ok(res) if res.status().is_success() => {
println!("Success: {}", res.text().await?);
break;
}
_ => {
attempts += 1;
eprintln!("Attempt {} failed. Retrying...", attempts);
sleep(Duration::from_secs(2)).await;
}
}
}
if attempts == 3 {
eprintln!("All attempts failed.");
}
Ok(())
}Handling Rate Limiting and Using Proxies
To respect rate limits, you can add delays between requests as shown below:
tokio::time::sleep(Duration::from_secs(1)).await;To bypass IP restrictions, configure Reqwest to use a proxy:
use reqwest::Client;
use reqwest::Proxy;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Create a proxy from the given URL
let result = Proxy::http("http://your.proxy.url:8080");
match result {
Ok(proxy) => {
// Build a client with the proxy
let client = Client::builder().proxy(proxy).build()?;
// Send a GET request through the proxy and get the response text
let response = client
.get("https://httpbin.org/ip")
.send()
.await?
.text()
.await?;
println!("Response with proxy: {}", response);
}
Err(error) => {
// Handle error if proxy creation fails
println!("Error creating proxy: {}", error);
}
}
Ok(())
}Parsing HTML Data
The Rust scraper crate is a powerful tool for parsing HTML and querying elements using CSS selectors. It uses Servo's html5ever and selectors crates to enable browser-grade parsing of intricate HTML structures.
Let’s see how to fetch and parse data from the Hacker News website, extracting the title, URL, and score points of each news article. Take a look at the website:
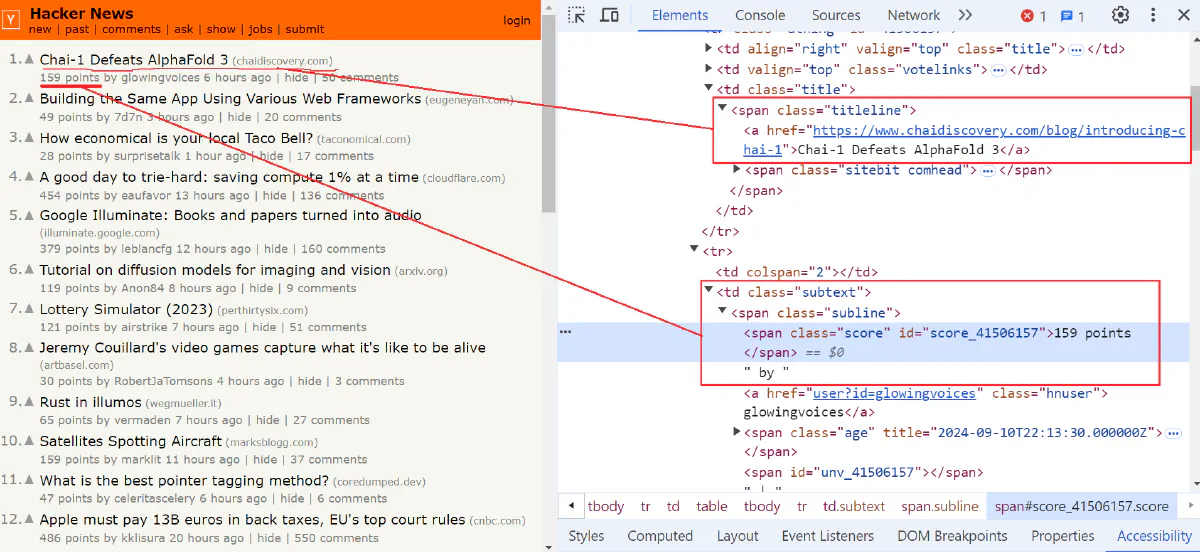
First, we need to fetch the HTML content of the target page using the reqwest crate:
use reqwest;
use scraper::{Html, Selector};
use serde_json::json;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Fetch the HTML content of the Hacker News page
let html_content = reqwest::get("https://news.ycombinator.com/")
.await?
.text()
.await?;
// Continue with the data extraction process...
Ok(())
}Once we have the HTML content, the next step is to parse it into a structured format:
// Parse the HTML response into a document object
let document = Html::parse_document(&html_content);The line Html::parse_document(&response) converts the raw HTML data (response) into a structured Html document. Then, this document will be used for querying and extracting elements using CSS selectors.
Now, set up CSS selectors to extract titles, URLs, and score points.
// Set up CSS selectors for titles, URLs, and scores
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();Now that we have the parsed document and selectors. So, use the selectors to navigate the DOM and retrieve titles, URLs, and scores for each article.
// Initialize a vector to store scraped data
let mut articles = Vec::new();
// Select titles and subtext (which includes the score)
let titles = document.select(&title_sel);
let subtexts = document.select(&subtext_sel);
// Iterate through pairs of titles and subtexts
for (title_elem, subtext_elem) in titles.zip(subtexts) {
// Extract title and URL
let title_text = title_elem.text().collect::<Vec<_>>().join(" ");
let article_link = title_elem
.value()
.attr("href")
.unwrap_or_default()
.to_string();
// Extract score
let score_text = subtext_elem
.select(&score_sel)
.next()
.and_then(|score| score.text().next())
.unwrap_or("0 points")
.to_string();
// Store the extracted data in a structured format
let article_json = json!({
"title": title_text,
"score": score_text,
"URL": article_link
});
articles.push(article_json);
}Finally, print the number of articles scraped and display the extracted data.
// Print the total number of articles scraped
println!(
"Page scraped successfully, found {} articles.",
scraped_articles.len()
);
// Print the scraped data
for article in &scraped_articles {
println!("{}\n", article);
}Here’s the complete code combining all the above code snippets:
use reqwest;
use scraper::{Html, Selector};
use serde_json::json;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Fetch the HTML content of the Hacker News page
let html_content = reqwest::get("https://news.ycombinator.com/")
.await?
.text()
.await?;
// Parse the HTML response into a document object
let document = Html::parse_document(&html_content);
// Set up CSS selectors for titles, URLs, and scores
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();
// Initialize a vector to store scraped data
let mut articles = Vec::new();
// Select titles and subtext (which includes the score)
let titles = document.select(&title_sel);
let subtexts = document.select(&subtext_sel);
// Iterate through pairs of titles and subtexts
for (title_elem, subtext_elem) in titles.zip(subtexts) {
// Extract title and URL
let title_text = title_elem.text().collect::<Vec<_>>().join(" ");
let article_link = title_elem
.value()
.attr("href")
.unwrap_or_default()
.to_string();
// Extract score
let score_text = subtext_elem
.select(&score_sel)
.next()
.and_then(|score| score.text().next())
.unwrap_or("0 points")
.to_string();
// Store the extracted data in a structured format
let article_json = json!({
"title": title_text,
"score": score_text,
"URL": article_link
});
articles.push(article_json);
}
// Print the total number of articles scraped
println!(
"Page scraped successfully, found {} articles.",
articles.len()
);
// Print the scraped data
for article in &articles {
println!("{}\n", article);
}
Ok(())
}Run the code and you will see the number of articles scraped along with their titles, URLs, and scores in the console.
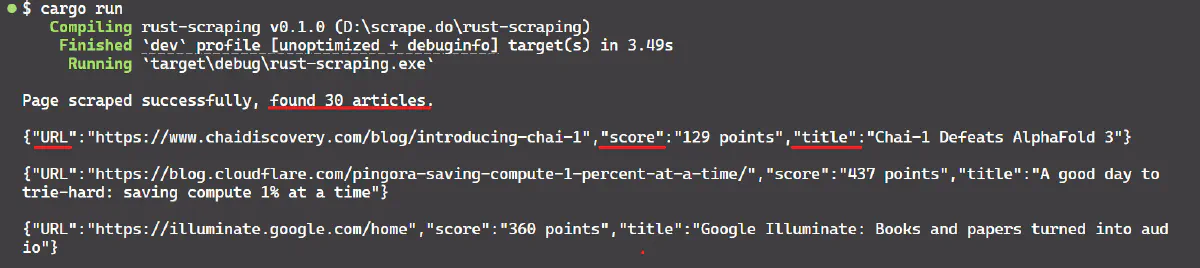
Concurrency and Asynchronous Programming
When building web scrapers, handling multiple requests efficiently is key to increasing performance. Rust’s concurrency model and strong asynchronous programming features make it a great choice for this task. Let’s explore how it works.
Rust's async/await syntax, provided by the tokio runtime, allows us to perform non-blocking asynchronous operations. This means you can handle other tasks while waiting for network requests.
Let’s build a web scraper that fetches data from multiple pages of Hacker News concurrently. First, import the necessary modules:
use reqwest;
use scraper::{Html, Selector};
use serde_json::json;
use std::error::Error;
use tokio::task;
use futures::future::join_all;Make sure to add the dependencies by running the command:
cargo add futures tokio --features "tokio/full"Here's the code to scrape multiple pages:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
let page_numbers = vec![1, 2, 3]; // Pages to scrape
let tasks: Vec<_> = page_numbers.into_iter()
.map(|num| task::spawn(scrape_page(num)))
.collect();
let results = join_all(tasks).await;
for result in results {
match result {
Ok(Ok(articles)) => {
for article in articles {
println!("{}\n", article);
}
}
Ok(Err(e)) => eprintln!("Error while scraping page: {}", e),
Err(e) => eprintln!("Task failed: {:?}", e),
}
}
Ok(())
}The #[tokio::main] macro makes the main function asynchronous using the tokio runtime. The join_all function from the futures crate allows handling multiple asynchronous tasks at once, and task::spawn creates new tasks for each page.
Next, the scrape_page function performs the actual scraping of each page:
async fn scrape_page(page_num: u32) -> Result<Vec<serde_json::Value>, Box<dyn Error + Send + Sync>> {
let url = format!("https://news.ycombinator.com/?p={}", page_num);
let response = reqwest::get(&url).await?.text().await?;
let document = Html::parse_document(&response);
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();
let mut articles = Vec::new();
let titles = document.select(&title_sel);
let subtexts = document.select(&subtext_sel);
for (title_elem, subtext_elem) in titles.zip(subtexts) {
let title_text = title_elem.text().collect::<Vec<_>>().join(" ");
let article_url = title_elem.value().attr("href").unwrap_or_default().to_string();
let score_text = subtext_elem
.select(&score_sel)
.next()
.and_then(|score| score.text().next())
.unwrap_or("0 points")
.to_string();
let article_json = json!({
"title": title_text,
"score": score_text,
"URL": article_url
});
articles.push(article_json);
}
println!("Scraped page {}, found {} articles.", page_num, articles.len());
Ok(articles)
}Each call to scrape_page runs asynchronously, allowing you to scrape multiple pages at the same time.
Here's the full code, combining all the snippets above:
use reqwest;
use scraper::{Html, Selector};
use serde_json::json;
use std::error::Error;
use tokio::task;
use futures::future::join_all;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
let page_numbers = vec![1, 2, 3]; // Pages to scrape
let tasks: Vec<_> = page_numbers.into_iter()
.map(|num| task::spawn(scrape_page(num)))
.collect();
let results = join_all(tasks).await;
for result in results {
match result {
Ok(Ok(articles)) => {
for article in articles {
println!("{}\n", article);
}
}
Ok(Err(e)) => eprintln!("Error while scraping page: {}", e),
Err(e) => eprintln!("Task failed: {:?}", e),
}
}
Ok(())
}
async fn scrape_page(page_num: u32) -> Result<Vec<serde_json::Value>, Box<dyn Error + Send + Sync>> {
let url = format!("https://news.ycombinator.com/?p={}", page_num);
let response = reqwest::get(&url).await?.text().await?;
let document = Html::parse_document(&response);
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();
let mut articles = Vec::new();
let titles = document.select(&title_sel);
let subtexts = document.select(&subtext_sel);
for (title_elem, subtext_elem) in titles.zip(subtexts) {
let title_text = title_elem.text().collect::<Vec<_>>().join(" ");
let article_url = title_elem.value().attr("href").unwrap_or_default().to_string();
let score_text = subtext_elem
.select(&score_sel)
.next()
.and_then(|score| score.text().next())
.unwrap_or("0 points")
.to_string();
let article_json = json!({
"title": title_text,
"score": score_text,
"URL": article_url
});
articles.push(article_json);
}
println!("Scraped page {}, found {} articles.", page_num, articles.len());
Ok(articles)
}Here are some key points to consider:
- Tokio provides a runtime for async programming in Rust, allowing you to handle tasks such as HTTP requests without blocking the main thread.
- The async/await syntax makes it easy to manage asynchronous tasks.
- Join_all runs multiple tasks concurrently. It works like a task queue where each task is executed in parallel.
- Rust’s ownership and type system helps prevent common concurrency problems such as deadlocks and race conditions, making concurrent programming safer and more reliable.
Handling Large Data Sets and Pagination
When scraping websites, data is often distributed across multiple pages. To extract all the content, handling pagination is important. Once you’ve collected data from multiple pages, it’s important to store it correctly in formats like CSV or JSON for further analysis.
On the Hacker News website, you can find a "More" button at the bottom of the page. Clicking this button loads additional content. To scrape all available pages, you need to repeatedly click this button until no more pages are available.
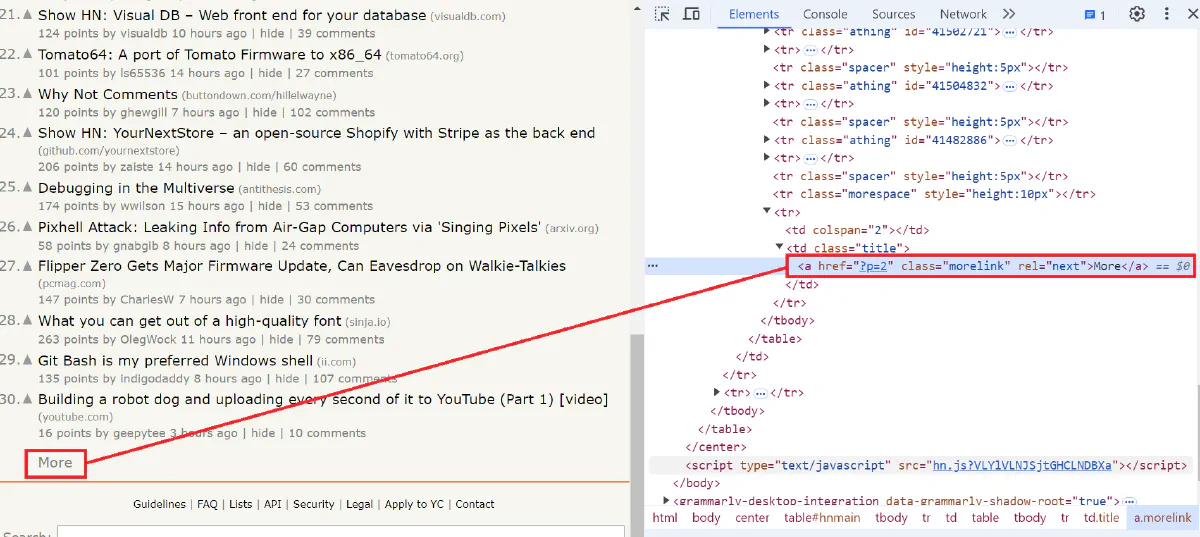
Add these dependencies by running the following command:
cargo add csv serde --features "serde/derive"Here’s the code snippet for handling pagination:
// Locate the "More" link to navigate to the next page
let more_link = document.select(&more_link_selector).next();
if let Some(link) = more_link {
let next_page_url = link.value().attr("href").unwrap_or("");
page_url = format!("https://news.ycombinator.com/{}", next_page_url);
} else {
// Break the loop if no "More" link is found, indicating no more pages
break;
}This code updates the page_url with the URL of the next page if a "More" link is found. If not, the loop breaks, showing that all pages have been scraped.
Now, to store the scraped data in a CSV file, use the following code:
use reqwest;
use scraper::{Html, Selector};
use serde::{Deserialize, Serialize};
use csv::Writer;
use std::error::Error;
// Define a struct to represent an article with its title, score, and URL
#[derive(Debug, Serialize, Deserialize)]
struct ArticleData {
title: String,
score: String,
url: String,
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize a vector to store scraped article data
let mut data = Vec::new();
// Start with the first page URL
let mut url = "https://news.ycombinator.com/".to_string();
// Loop until there are no more pages to scrape
loop {
// Fetch the HTML content of the current page
let response = reqwest::get(&url).await?.text().await?;
let doc = Html::parse_document(&response);
// Define selectors for different parts of the article
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();
let next_sel = Selector::parse("td.title > a.morelink").unwrap();
// Extract titles and subtexts from the HTML document
let titles = doc.select(&title_sel);
let subtexts = doc.select(&subtext_sel);
// Iterate over the titles and subtexts to extract article details
for (title, subtext) in titles.zip(subtexts) {
let title_text = title.text().collect::<Vec<_>>().join(" ");
let article_url = title.value().attr("href").unwrap_or_default().to_string();
let score = subtext
.select(&score_sel)
.next()
.and_then(|score| score.text().next())
.unwrap_or("0 points")
.to_string();
// Create a new ArticleData instance and add it to the vector
let article = ArticleData {
title: title_text,
score,
url: article_url,
};
data.push(article);
}
// Find the "More" link to navigate to the next page
let next = doc.select(&next_sel).next();
if let Some(link) = next {
let next_url = link.value().attr("href").unwrap_or("");
url = format!("https://news.ycombinator.com/{}", next_url);
} else {
// If no "More" link is found, it means there are no more pages to scrape
break;
}
}
// Print the total number of articles scraped
println!("Total articles scraped: {}", data.len());
// Write the scraped data to a CSV file
let mut csv_writer = Writer::from_path("scraped_data.csv")?;
for article in &data {
csv_writer.serialize(article)?;
}
Ok(())
}This code saves the scraped data to a CSV file named scraped_data.csv. The csv::Writer is used to serialize each ArticleData instance into CSV format.
The output is:
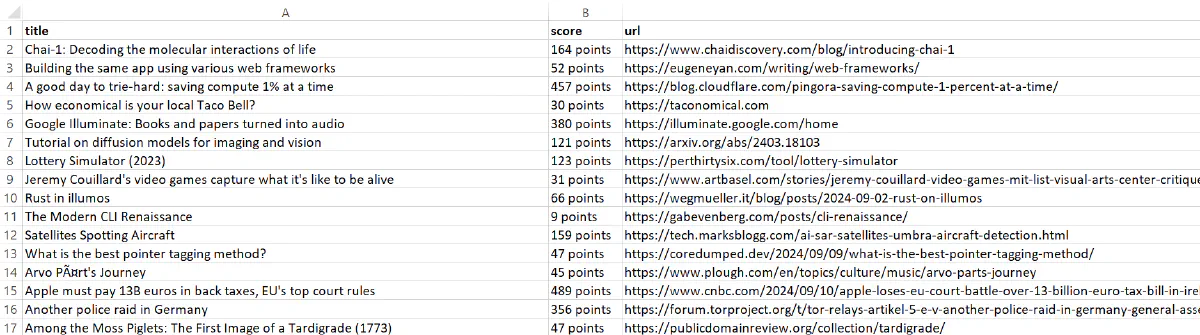
Nice! The data looks more clean and readable.
Next, to save the data in a JSON file, use the following code:
use reqwest;
use scraper::{Html, Selector};
use serde::{Deserialize, Serialize};
use serde_json::to_string_pretty;
use std::error::Error;
use std::fs::File;
use std::io::Write;
#[derive(Debug, Serialize, Deserialize)]
struct ArticleData {
title: String,
score: String,
url: String,
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let mut data = Vec::new();
let mut url = "https://news.ycombinator.com/".to_string();
loop {
let response = reqwest::get(&url).await?.text().await?;
let doc = Html::parse_document(&response);
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();
let next_sel = Selector::parse("td.title > a.morelink").unwrap();
let titles = doc.select(&title_sel);
let subtexts = doc.select(&subtext_sel);
for (title, subtext) in titles.zip(subtexts) {
let title_text = title.text().collect::<Vec<_>>().join(" ");
let article_url = title.value().attr("href").unwrap_or_default().to_string();
let score = subtext
.select(&score_sel)
.next()
.and_then(|score| score.text().next())
.unwrap_or("0 points")
.to_string();
let article = ArticleData {
title: title_text,
score,
url: article_url,
};
data.push(article);
}
let next = doc.select(&next_sel).next();
if let Some(link) = next {
let next_url = link.value().attr("href").unwrap_or("");
url = format!("https://news.ycombinator.com/{}", next_url);
} else {
break;
}
}
println!("Total articles scraped: {}", data.len());
let json_file = "scraped_data.json";
let mut file = File::create(json_file)?;
let json_data = to_string_pretty(&data)?;
file.write_all(json_data.as_bytes())?;
Ok(())
}This code converts the data vector of ArticleData structs into a formatted JSON string and writes it to scraped_data.json.
The output is:
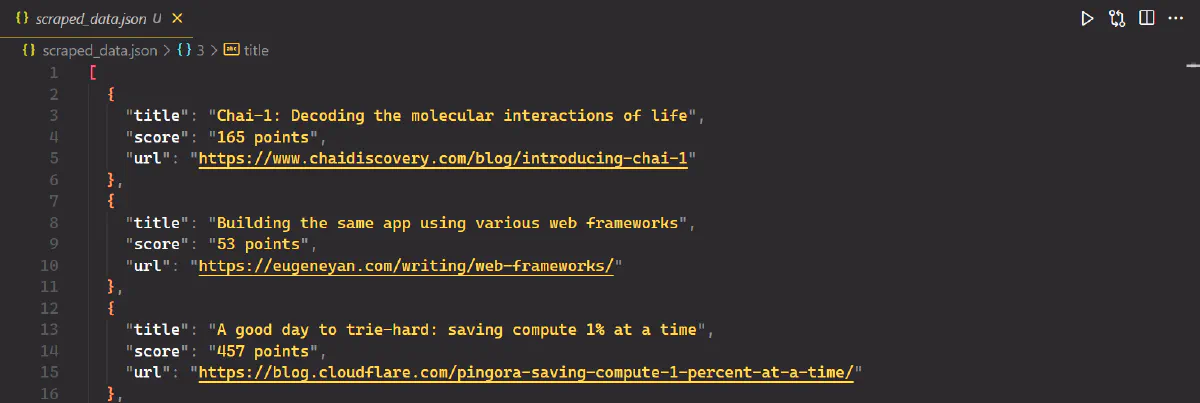
Dealing with Anti-Scraping Mechanisms
Websites often employ various anti-scraping mechanisms to protect their content from being extracted by bots. However, there are multiple strategies to bypass these mechanisms, such as rotating user agents and IP addresses, implementing delays between requests, using headless browsers, and more. Let’s explore these techniques in detail.
Rotating User Agents
Websites can detect and block scrapers by monitoring the User-Agent header. To counter this, you can rotate User-Agent strings. Using a fake User-Agent to mimic real users is a common tactic to avoid detection. Here's how you can rotate user agents using the reqwest crate in Rust:
use rand::seq::SliceRandom;
use reqwest::header::{HeaderMap, HeaderValue, USER_AGENT};
use reqwest::Client;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// List of user agents
let user_agents = vec![
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0",
// Add more user agents here...
];
// Randomly select a user agent
let selected_user_agent = user_agents.choose(&mut rand::thread_rng()).unwrap();
// Set up headers with the selected user agent
let mut request_headers = HeaderMap::new();
request_headers.insert(USER_AGENT, HeaderValue::from_str(selected_user_agent)?);
// Create a client with custom headers
let client = Client::builder().default_headers(request_headers).build()?;
let response = client
.get("https://httpbin.org/headers")
.send()
.await?
.text()
.await?;
println!("{}", response);
Ok(())
}This code randomly selects a User-Agent from a predefined list and includes it in the request headers to help you avoid detection by simulating requests from different browsers or devices.
Using Proxies
Websites can detect and block scrapers by identifying repeated requests from the same IP address. To further avoid blocking, use proxy services to rotate IP addresses. Below is an example showing how to use a proxy with reqwest:
use reqwest::Proxy;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Define your proxy URL
let proxy_url = "http://your_proxy_address:port"; // Replace with your proxy URL
// Set up the proxy configuration
let proxy = Proxy::all(proxy_url)?;
// Create a client with proxy settings
let client = reqwest::Client::builder().proxy(proxy).build()?;
// Send a GET request via the proxy
let response = client
.get("https://httpbin.org/ip")
.send()
.await?
.text()
.await?;
println!("{}", response);
Ok(())
}Replace "http://your_proxy_address:port" with your actual proxy server details.
Note: While free proxies may be ideal for performing basic tasks, they often fail in real web scraping projects. Consider using premium proxy services that offer residential IPs, automatic IP rotation, and geolocation features to improve your scraping success rate. One such great option is Scrape.do.
Delays and Random Intervals Between Requests
Sending multiple requests in a short time often results in IP bans. To reduce the risk of blocking and look like legitimate users, introduce random delays between requests.
Here’s a simple implementation using Rust's tokio::time module:
use rand::Rng;
use reqwest;
use std::error::Error;
use tokio::time::{sleep, Duration};
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// List of URLs to scrape
let target_urls = vec![
"https://httpbin.org/get",
"https://httpbin.org/ip",
"https://httpbin.org/headers",
];
for target_url in target_urls {
// Fetch the URL
let response = reqwest::get(target_url).await?;
let fetched_data = response.text().await?;
println!("Fetched: {}\nData: {}", target_url, fetched_data);
// Random delay between 1 to 5 seconds
let random_delay = rand::thread_rng().gen_range(1..=5);
println!("Sleeping for {} seconds", random_delay);
sleep(Duration::from_secs(random_delay)).await;
}
Ok(())
}This code iterates through a list of URLs, fetches data, and then waits for a random duration between 1 to 5 seconds before proceeding to the next request.
Dealing with JavaScript-Heavy Websites Using Headless Browsers
For JavaScript-heavy websites that dynamically render content, you need a method that can execute JavaScript to fully render and scrape the content. One way to do this is by using headless_chrome, which is a popular Rust library with headless browser capabilities. You can install it using the following command:
cargo add headless_chromeThis high-level API controls headless Chrome or Chromium over the DevTools Protocol. It offers enough functionality for most browser testing and web scraping needs, including advanced features like network request interception and JavaScript coverage monitoring.
Here’s a quick example of taking a screenshot of a webpage using headless_chrome:
use headless_chrome::protocol::cdp::Page;
use headless_chrome::Browser;
use std::error::Error;
fn main() -> Result<(), Box<dyn Error>> {
let browser = Browser::default()?;
let tab = browser.new_tab()?;
// Navigate to Hacker News
tab.navigate_to("https://news.ycombinator.com")?;
// Take a screenshot of the entire browser window
let jpeg_data = tab.capture_screenshot(Page::CaptureScreenshotFormatOption::Jpeg, None, None, true)?;
// Save the screenshot to disk
std::fs::write("screenshot.jpeg", jpeg_data)?;
Ok(())
}The result is:
For more advanced web scraping tasks, Rust provides Selenium bindings through the thirtyfour library. This allows you to simulate complex browser interactions like clicking, typing, and scrolling, similar to Python’s Selenium or Playwright. thirtyfour integrates with WebDriver/Selenium, creating a robust environment for automated UI testing and more complex web scraping tasks.
Testing and Debugging
Testing and debugging are important steps when developing a reliable web scraper. Let’s take a look at the process of testing and debugging your Rust-based web scraper. We’ll cover different approaches including unit and integration tests, debugging tools, and logging techniques for performance monitoring.
Writing Unit and Integration Tests
Unit tests are designed to test individual functions or components of your scraper in isolation. For example, you might write tests to confirm that HTML parsing functions work properly or that your code handles common errors appropriately, all without the need for live data scraping.
In our unit testing approach, we will verify that the scrape_data function extracts titles and URLs from a provided HTML string.
First, create a new Rust file named lib.rs in the src directory with the following content:
use reqwest::Error;
pub async fn fetch_html(url: &str) -> Result<String, Error> {
let response = reqwest::get(url).await?;
let body = response.text().await?;
Ok(body)
}
pub fn scrape_data(html: &str) -> Vec<serde_json::Value> {
use scraper::{Html, Selector};
use serde_json::json;
let document = Html::parse_document(html);
let title_sel = Selector::parse("span.titleline > a").expect("Failed to parse selector");
let mut articles = Vec::new();
let titles = document.select(&title_sel);
for title_elem in titles {
let title_text = title_elem
.text()
.collect::<Vec<_>>()
.join(" ")
.trim()
.to_string();
let url = title_elem.value().attr("href").unwrap_or("");
let article_json = json!( {
"title": title_text,
"url": url
});
articles.push(article_json);
}
articles
}
#[cfg(test)]
mod tests {
use super::scrape_data;
#[test]
fn test_scrape_data() {
let html = r#"
<html>
<body>
<span class="titleline"><a href="https://arstechnica.com/science/2024/09/court-clears-researchers-of-defamation-for-identifying-manipulated-data/">Data sleuths who spotted research misconduct cleared of defamation</a></span>
<span class="titleline"><a href="https://simonwillison.net/2024/Sep/12/openai-o1/">Notes on OpenAI's new o1 chain-of-thought models</a></span>
</body>
</html>
"#;
let articles = scrape_data(html);
assert_eq!(articles.len(), 2);
assert_eq!(articles[0]["title"], "Data sleuths who spotted research misconduct cleared of defamation");
assert_eq!(articles[1]["title"], "Notes on OpenAI's new o1 chain-of-thought models");
}
}To run the unit test, use the command cargo test. You should get output similar to this:
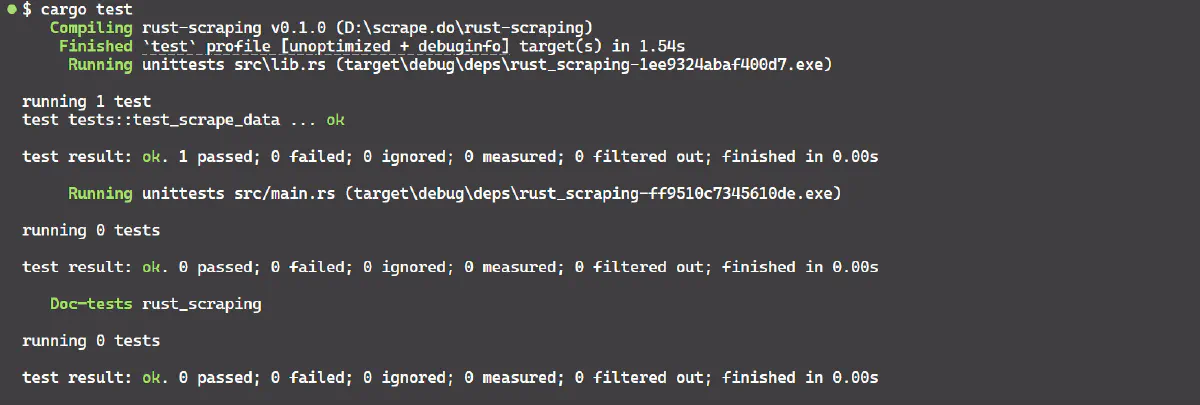
The output confirms that the unit test test_scrape_data passed successfully!
Let's talk about integration testing. Unit tests focus on testing one module at a time in isolation – they're small and can test private code. In contrast, integration tests verify that different components of your scraper work together correctly.
Cargo looks for integration tests in the tests directory next to the src directory in your Rust project.
File src/lib.rs:
use reqwest::Error;
pub async fn fetch_html(url: &str) -> Result<String, Error> {
let response = reqwest::get(url).await?;
let body = response.text().await?;
Ok(body)
}
pub fn scrape_data(html: &str) -> Vec<serde_json::Value> {
use scraper::{Html, Selector};
use serde_json::json;
let document = Html::parse_document(html);
let title_sel = Selector::parse("span.titleline > a").expect("Failed to parse selector");
let mut articles = Vec::new();
let titles = document.select(&title_sel);
for title_elem in titles {
let title_text = title_elem
.text()
.collect::<Vec<_>>()
.join(" ")
.trim()
.to_string();
let url = title_elem.value().attr("href").unwrap_or("");
let article_json = json!({
"title": title_text,
"url": url
});
articles.push(article_json);
}
articles
}File with test: tests/integration_test.rs:
use rust_scraping::{fetch_html, scrape_data};
use tokio;
#[tokio::test]
async fn test_fetch_and_scrape_data() {
let url = "https://news.ycombinator.com";
let html = fetch_html(url).await.expect("Failed to fetch HTML");
let articles = scrape_data(&html);
assert_eq!(
articles[0]["title"],
"Data sleuths who spotted research misconduct cleared of defamation"
);
assert_eq!(
articles[1]["title"],
"Notes on OpenAI's new o1 chain-of-thought models"
);
}Running tests with cargo test command:
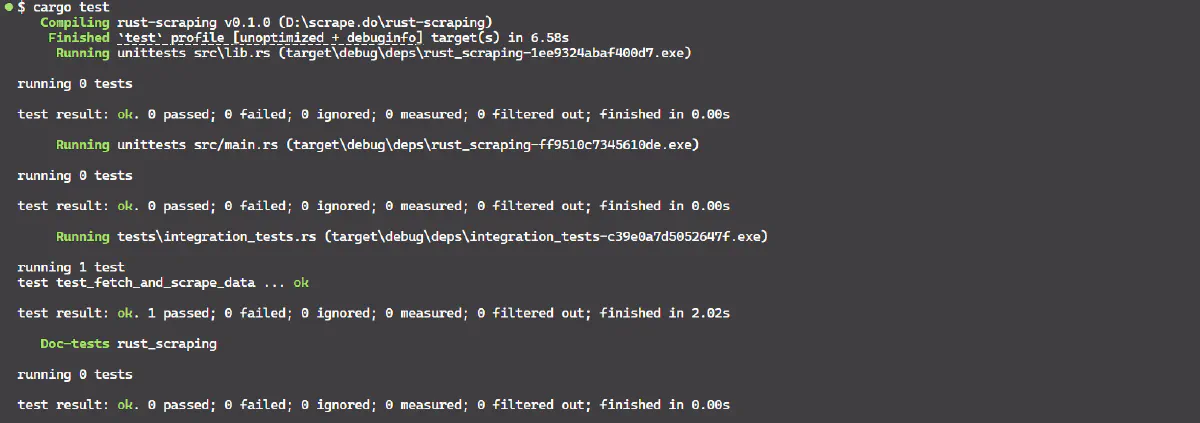
What differences did we observe in both the testing? Unit Test isolates and tests only scrape_data with hardcoded HTML. On the other hand, the Integration Test uses fetch_html to fetch HTML from a URL and then passes it to scrape_data to test the flow of fetching and extracting data together.
Debugging Tools in Rust
Rust provides several debugging tools to help trace and resolve issues in your web scraper.
1. println! Statements: Use println! to print variable values or function entries for tracing code execution. This is the most straightforward way!
fn parse_page(content: &str) -> Result<Data, Error> {
println!("Parsing page with content: {}", content);
// Parsing logic...
}2. The dbg! Macro: dbg! is a very useful macro that quickly prints information. It is a good alternative to println! because it is faster to type and gives more information.
let data = fetch_data();
dbg!(data);3. Logging: the log crate along with env_logger for setting up logging.
Add dependencies to Cargo.toml:
cargo add env_logger logExample code with logging:
use env_logger::Env;
use log::{info, warn};
use reqwest;
use scraper::{Html, Selector};
use serde_json::json;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize the logger
env_logger::Builder::from_env(Env::default().default_filter_or("info")).init();
info!("Starting the web scraper...");
let response = reqwest::get("http://example.com/404").await?;
if response.status().is_success() {
info!("Successfully fetched the page.");
} else {
warn!("Failed to fetch the page: Status code {}", response.status());
}
let html_content = response.text().await?;
let document = Html::parse_document(&html_content);
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();
let mut articles = Vec::new();
let titles = document.select(&title_sel);
let subtexts = document.select(&subtext_sel);
for (title_elem, subtext_elem) in titles.zip(subtexts) {
let title_text = title_elem.text().collect::<Vec<_>>().join(" ");
let article_link = title_elem.value().attr("href").unwrap_or_default().to_string();
let score_text = subtext_elem.select(&score_sel).next().and_then(|score| score.text().next()).unwrap_or("0 points").to_string();
let article_json = json!( {
"title": title_text,
"score": score_text,
"URL": article_link
});
articles.push(article_json);
}
info!("Found {} articles.", articles.len());
for article in &articles {
println!("{}", article);
}
Ok(())
}The result is:

4. Measuring Execution Time: Use std::time::Instant to measure the time taken by various parts of your scraper.
let start = std::time::Instant::now();
scrape("https://example.com");
println!("Scrape took: {:?}", start.elapsed());5. Handling Errors: Use crates like retry for automatic retries on failure, and anyhow for detailed error reporting with backtraces.
Optimization and Performance Tuning
To handle large volumes of scraped data, you need to optimize your web scraper to efficiently handle this data while minimizing resource usage.
Profiling is the process of identifying performance bottlenecks in your scraper. Benchmarking is the process of measuring the performance of your scraper under different conditions.
In Rust, Criterion.rs is a statistics-driven benchmarking library that helps you detect and measure performance improvements or regressions quickly.
To start with Criterion.rs, add the following to your Cargo.toml file:
[dependencies]
criterion = { version = "0.5", features = ["html_reports"] }
[[bench]]
name = "my_benchmark"
harness = falseNext, define a benchmark by creating a file at benches/my_benchmark.rs with the following contents:
use criterion::{criterion_group, criterion_main, Criterion};
use tokio;
use reqwest;
use scraper::{Html, Selector};
use serde_json::json;
use std::error::Error;
pub async fn scrape_ycombinator() -> Result<Vec<serde_json::Value>, Box<dyn Error>> {
let html_content = reqwest::get("https://news.ycombinator.com/")
.await?
.text()
.await?;
let document = Html::parse_document(&html_content);
let title_sel = Selector::parse("span.titleline > a").unwrap();
let subtext_sel = Selector::parse("td.subtext").unwrap();
let score_sel = Selector::parse("span.score").unwrap();
let mut articles = Vec::new();
let titles = document.select(&title_sel);
let subtexts = document.select(&subtext_sel);
for (title_elem, subtext_elem) in titles.zip(subtexts) {
let title_text = title_elem.text().collect::<Vec<_>>().join(" ");
let article_link = title_elem
.value()
.attr("href")
.unwrap_or_default()
.to_string();
let score_text = subtext_elem
.select(&score_sel)
.next()
.and_then(|score| score.text().next())
.unwrap_or("0 points")
.to_string();
let article_json = json!( {
"title": title_text,
"score": score_text,
"URL": article_link
});
articles.push(article_json);
}
Ok(articles)
}
fn criterion_benchmark(c: &mut Criterion) {
let mut group = c.benchmark_group("scrape_ycombinator");
group.sample_size(10) // Reduce the number of samples if needed
.measurement_time(std::time::Duration::new(30, 0)); // Increase target time to 30 seconds
group.bench_function("scrape_ycombinator", |b| {
// Create a new Tokio runtime
let rt = tokio::runtime::Runtime::new().unwrap();
b.iter(|| {
rt.block_on(async {
let _ = scrape_ycombinator().await.unwrap();
});
});
});
group.finish();
}
criterion_group!(benches, criterion_benchmark);
criterion_main!(benches);Finally, run this benchmark with cargo bench. You should see output similar to the following:
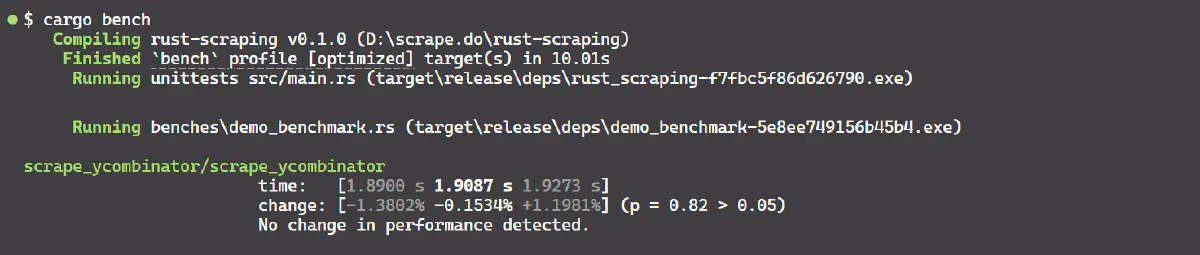
The benchmark result shows that function scrape_ycombinator took between approximately 1.89 s and 1.92 seconds per run on average. This range includes the variability due to factors like network latency.
Another good way is to implement caching mechanisms to avoid redundant network requests for the same data by using libraries like cached in Rust.
Challenges of Web Scraping in Rust
One of the main challenges of web scraping with Rust is the limited availability of libraries and tools. While Rust is becoming increasingly popular for its performance and safety, its ecosystem for web scraping tools and libraries is still relatively small compared to languages like Python or JavaScript.
Another significant challenge is dealing with anti-scraping mechanisms employed by websites to protect their data. While there are various techniques you can use, such as rotating proxies, randomizing user agents, using headless browsers, automating CAPTCHA solving, and varying request rates, these are often temporary solutions that may only work in limited scenarios.
A more robust alternative is Scrape.do, a tool designed to bypass anti-scraping measures, allowing you to focus on scraping the data you need without worrying about proxies, headless browsers, CAPTCHAs, and other challenges.
Let's see Scrape.do in action!
First, sign up to get your free Scrape.do API token from the dashboard.
Great! With this token, you can make up to 1,000 API calls for free, with various features designed to help you avoid getting blocked.
Here’s how to get started using the Scrape.do web scraping API:
import requests
token = "YOUR_API_TOKEN"
target_url = "https://www.g2.com/products/anaconda/reviews"
# Base URL for the API
base_url = "http://api.scrape.do"
# Parameters for the request
params = {
"token": token,
"url": target_url, # The target URL to scrape
"render": "true", # Render the page
"waitUntil": "domcontentloaded", # Wait until the DOM is fully loaded
"blockResources": "true", # Block unnecessary resources from loading
"geoCode": "us", # Set the geolocation for the request
"super": "true" # Use Residential & Mobile Proxy Networks
}
# Making the GET request with parameters
response = requests.get(base_url, params=params)
print(f"Status Code: {response.status_code}")
print(response.text)Here’s the result:

Amazing! You've successfully bypassed a Cloudflare-protected website and scraped its full-page HTML using Scrape.do 🚀
Conclusion
You learned about web scraping with Rust from the basics to advanced concepts like concurrency, pagination, anti-scraping mechanisms, testing, debugging, and optimization techniques. You now understand why Rust is known for its speed and performance in large web scraping tasks.
However, Rust has a limited ecosystem of scraping libraries and can be blocked by advanced anti-bot systems like G2, which use Cloudflare protection. You can overcome these challenges with Scrape.do, the best tool to scrape any website without getting blocked. Get started today with 1000 free credits.
Technical Writer








