Category:Scraping Tools
2026's Top Amazon Scraper APIs (In-Depth Comparison)

Lead Software Engineer



Amazon is THE ecommerce platform, especially if your business works in the US, and scraping it at scale is not an easy task.
To make it easier, we tested 7 scraping APIs with dedicated Amazon endpoints to see which ones actually deliver. Not generic web scrapers that might work on Amazon, but tools with purpose-built parsers for product data, search results, and seller information.
| API Provider | Success Rate | Speed (ms) | Cost per 1K | Starting Price | PDP | Variations | Search | Seller Offers | Best Sellers |
|---|---|---|---|---|---|---|---|---|---|
| Scrape.do | 100% | 3,029 | $0.12 | Freemium | Yes | (Code Available) | Yes | Yes | (Code Available) |
| Bright Data | 97.83% | 10,209 | $1.50 | Pay-as-you-go | Yes | No | Yes | Yes | Yes |
| Oxylabs | 100% | 7,435 | $0.89 | $75 | Yes | Yes | Yes | Yes | Yes |
| ScraperAPI | 100% | 11,807 | $0.49 | $49 | Yes | No | Yes | Yes | No |
| ScrapingBee | 99.37% | 3,223 | $0.20 | $49 | Yes | No | Yes | No | No |
| ScrapingDog | 89.79% | 2,591 | $0.20 | $40 | Yes | No | Yes | Yes | No |
| WebScrapingAPI | 93.27% | 7,921 | $2.45 | Freemium | Yes | No | Yes | Yes | Yes |
Table updated December 15, 2025. PDP = Product Detail Pages. Variations = Color/Size/Model. Search = Search results and category pages.
1. Scrape.do
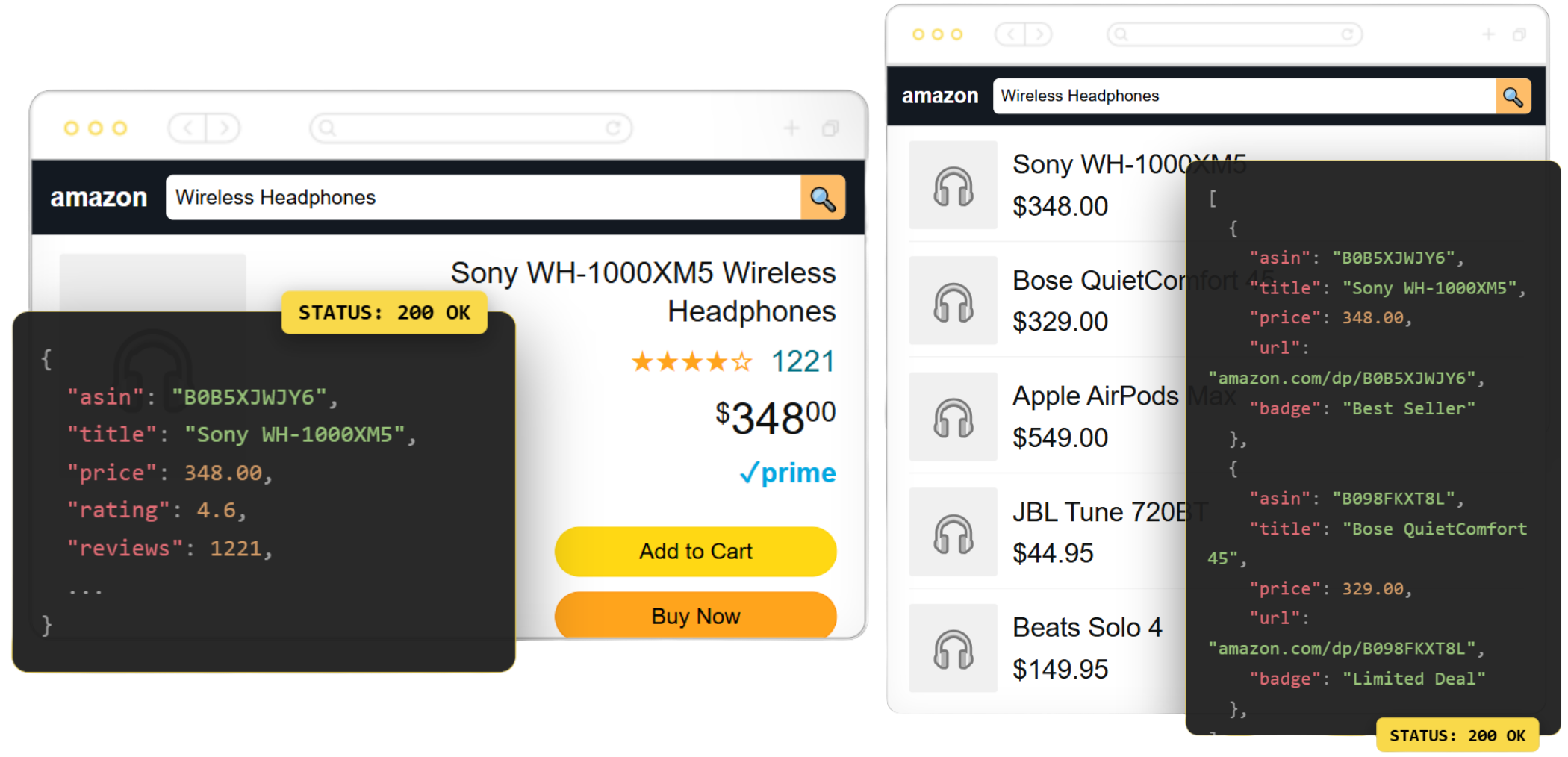
The Scrape.do Amazon Scraper API extracts structured product data from Amazon.com and all international Amazon marketplaces. Unlike generic web scrapers, it returns clean, structured JSON responses with product details, pricing, seller offers, and search results ready to use in your applications.
For Amazon scraping specifically, Scrape.do provides dedicated API endpoints for product pages, search results, and seller offers. The API returns structured JSON data with pre-parsed fields like ASIN, title, price, ratings, images, and technical details, eliminating the need to write custom HTML parsers. For product variations and best sellers, Scrape.do offers production-ready code and tutorials rather than dedicated endpoints.
What sets Scrape.do apart is the geo-targeting coverage. The API supports country-level and ZIP code-level targeting across all 21 Amazon marketplaces, letting you access location-specific pricing, stock availability, and shipping information for any delivery location on Earth.
In our tests, Scrape.do achieved 100% success rate with an average response time of 3,029ms, the fastest among all providers that hit perfect reliability.
Why Choose Scrape.do Amazon API
- Speed and reliability combined: 3-second average response time with 100% success rate. Other providers that matched this reliability took 3-4x longer per request. At scale, this difference compounds into hours of saved processing time.
- Lowest cost per request: At $0.12 per 1,000 requests, Scrape.do costs 4-12x less than competitors for identical Amazon data. The freemium tier includes 1,000 requests monthly with no expiration, enough to test production workflows before committing.
- Most complete endpoint coverage: PDP scraper, product variation crawler, search results parser, seller offers extractor, and best sellers tracker. Most competitors offer only 2-3 of these. The variation scraper handles color/size/model combinations that other APIs skip entirely.
- Granular geo-targeting: Country and ZIP code-level targeting covers every Amazon marketplace. Scrape US prices from specific regions, or compare pricing across EU countries without managing separate proxy pools.
- JSON output in seconds, without blocks: Scrape.do processes millions of requests daily. All anti-bot measures including AWS WAF and CAPTCHAs are handled automatically—you just receive clean, structured data.
- Open-source code available: GitHub repository with production-ready scrapers for all Amazon endpoints. Fork and customize instead of building from scratch.
Start free with Scrape.do and test on Amazon with 1000 free credits
2. Bright Data
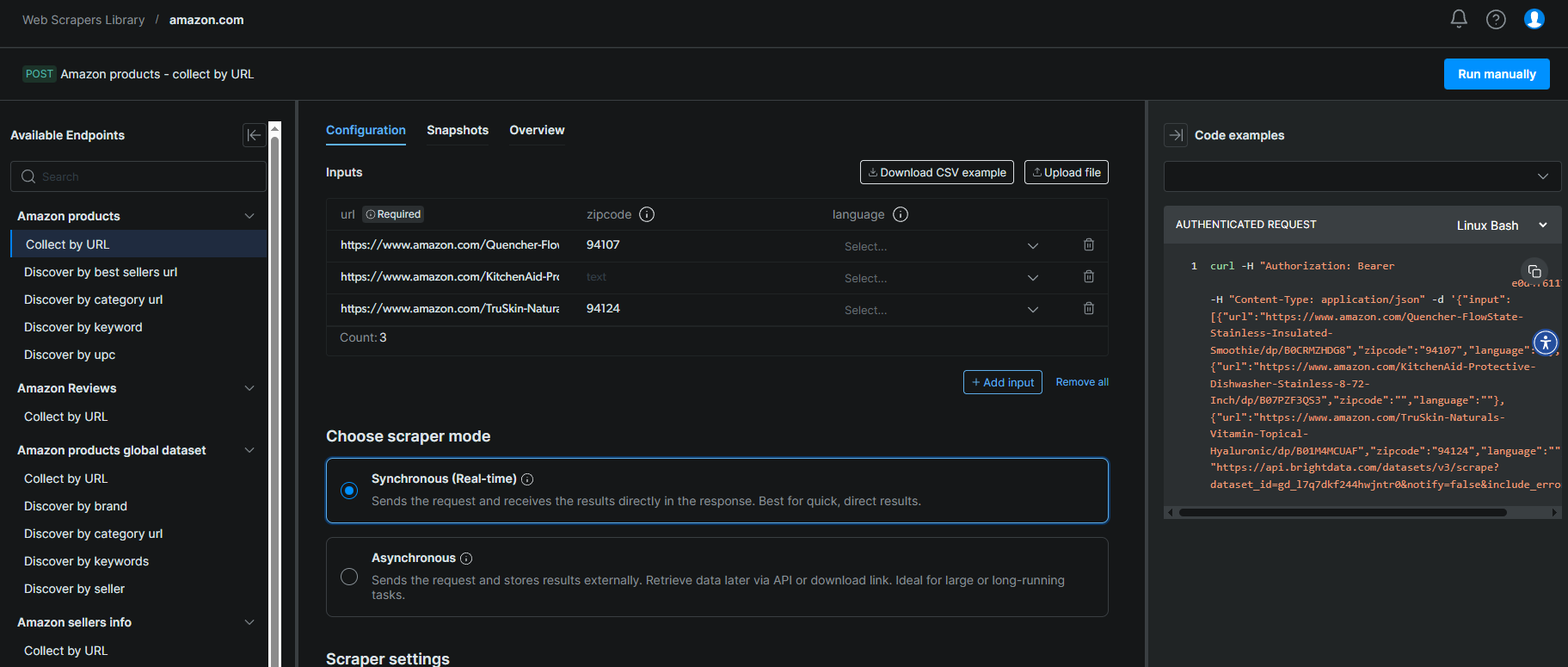
Bright Data operates the largest proxy network in the industry with 150+ million IPs across 195 countries. The company's Amazon scraper is part of their Web Scraper API suite, which includes ready-made collectors for 120+ websites.
The Amazon integration offers two approaches: the Web Scraper API for programmatic access, and pre-built no-code collectors that extract product data into structured datasets. Bright Data also sells ready-made Amazon datasets if you need historical data without running your own scrapes.
For teams that need massive scale quickly, Bright Data's bulk collection feature processes up to 5,000 URLs per request.
The trade-off, yes there is one, is speed, with our tests showing an average response time of 10,209ms, roughly 3x slower than the fastest providers.
In our tests, Bright Data achieved 97.83% success rate, slightly below perfect but consistent across different product categories.
Why Choose Bright Data Amazon API
- Enterprise-grade infrastructure: The 150M+ IP network handles volume that smaller providers struggle with. If you're scraping millions of products monthly, Bright Data's infrastructure won't be your bottleneck.
- Ready-made datasets available: Skip scraping entirely and purchase pre-collected Amazon data. Useful for building historical baselines or training ML models without waiting for fresh scrapes.
- Bulk URL processing: Submit 5,000 URLs in a single API call for batch processing. Better for scheduled jobs than real-time scraping, but efficient for large catalog updates.
- Compliance focus: Bright Data emphasizes legal compliance with documentation on ethical scraping practices. Relevant for enterprise teams with legal review requirements.
3. Oxylabs
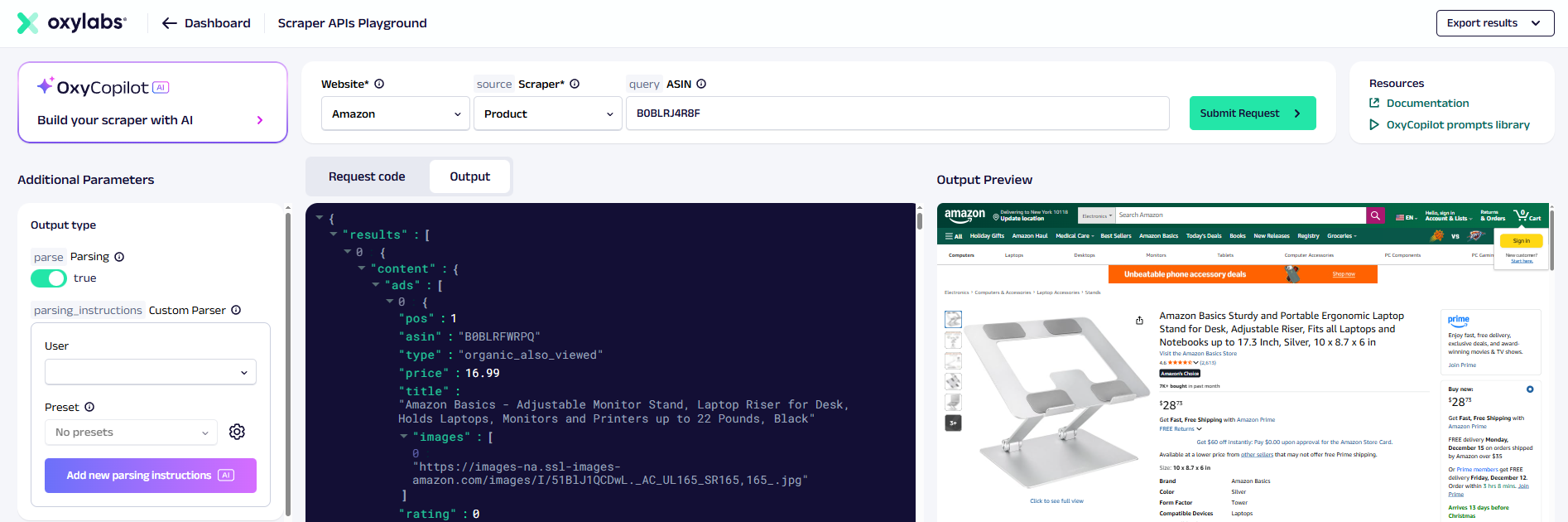
Oxylabs is a premium scraping provider with 100+ million IPs and specialized e-commerce APIs.
Their Amazon scraper returns detailed JSON responses with extensive field coverage, parsing more data points per product than most competitors.
The API extracts everything visible on a product page: pricing tiers, shipping options, seller information, product specifications, and customer Q&A. Oxylabs also offers OxyCopilot, an AI assistant that generates scraping code snippets, which speeds up integration for developers unfamiliar with their API structure.
One standout feature is the product variation scraper. While most APIs only handle the default product page, Oxylabs can crawl through color, size, and model combinations to capture pricing across all variants.
In our tests, Oxylabs achieved 100% success rate with 13,522ms average response time. Perfect reliability but slower than mid-tier options.
Why Choose Oxylabs Amazon API
- Most detailed response structure: Oxylabs parses more fields per product than any other provider. If you need shipping estimates, seller ratings, product specifications, and Q&A data in a single request, the API delivers without custom parsing. For customer feedback specifically, there are also options to scrape amazon reviews.
- Product variation support: The variation scraper handles products with multiple options (colors, sizes, configurations). Each variation returns its own ASIN, price, and availability data.
- Extended endpoint coverage: PDP, search, seller offers, best sellers, and category pages all have dedicated endpoints. The response structure stays consistent across endpoint types.
- AI code generation: OxyCopilot generates integration code for common scraping scenarios. Reduces initial setup time for teams new to the API.
4. ScraperAPI
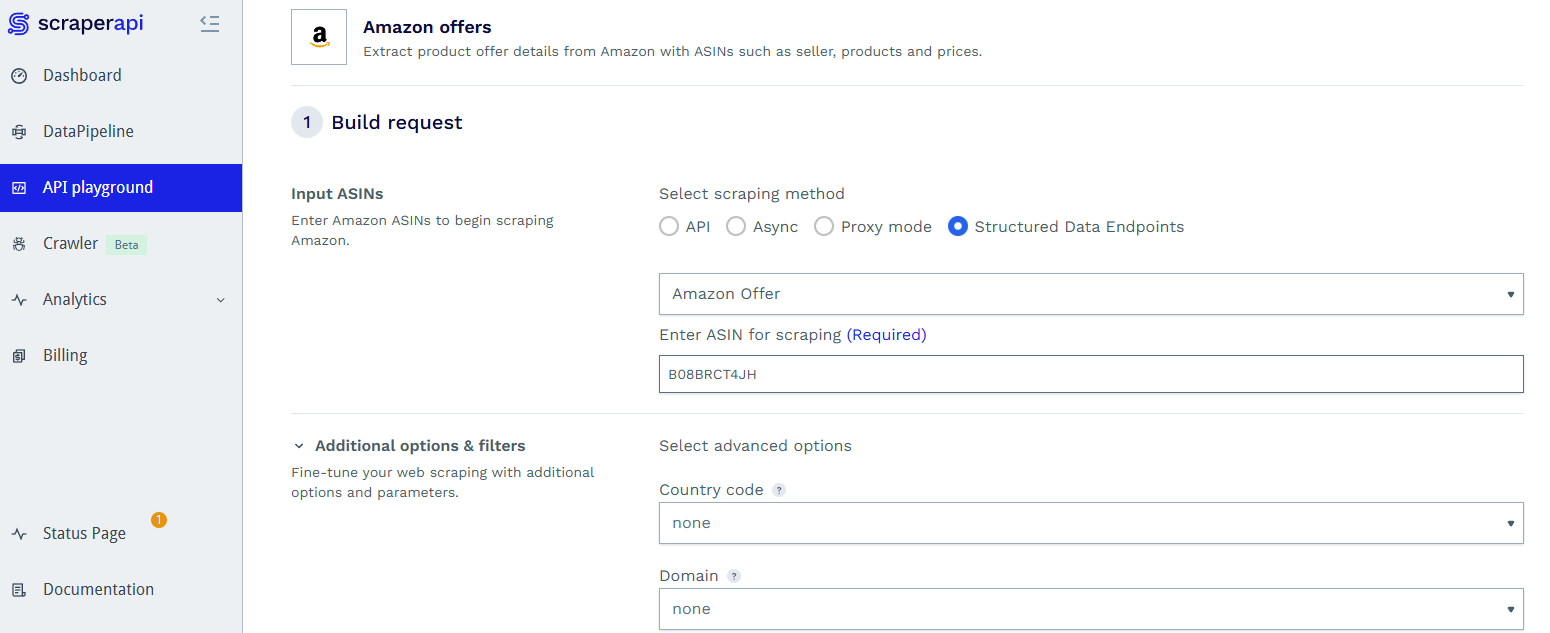
ScraperAPI focuses on reliability over features, offering a straightforward API that handles proxy rotation and CAPTCHA solving automatically. The Amazon integration includes dedicated endpoints for product pages, search results, and seller offers.
The API uses a credit-based pricing model where different proxy tiers cost different amounts. Standard requests use 1 credit, premium proxies cost 10 credits, and ultra-premium (required for heavily protected pages) costs 30-75 credits. This multiplier system makes cost prediction tricky since you won't know which tier a target requires until you scrape it.
ScraperAPI's strength is in handling Amazon's base protection without requiring manual configuration. The automatic retry logic and proxy rotation work well for straightforward product scraping. If you prefer to scrape amazon search results with your own parser, these APIs give you clean HTML to work with.
In our tests, ScraperAPI achieved 100% success rate with 11,807ms average response time.
Why Choose ScraperAPI Amazon API
- Perfect success rate: 100% reliability in our tests means fewer failed requests to retry. For production workflows where consistency matters more than speed, ScraperAPI delivers.
- Automatic proxy tier selection: The API selects the appropriate proxy type based on the target. No manual configuration required to handle different Amazon page types.
- Pre-built templates: Ready-made scraping templates for e-commerce, SERP, and real estate data. Useful for teams running multiple scraping projects beyond Amazon.
- Scheduling built-in: Native scheduling feature for periodic data collection. Run daily price checks without external cron jobs.
5. ScrapingBee
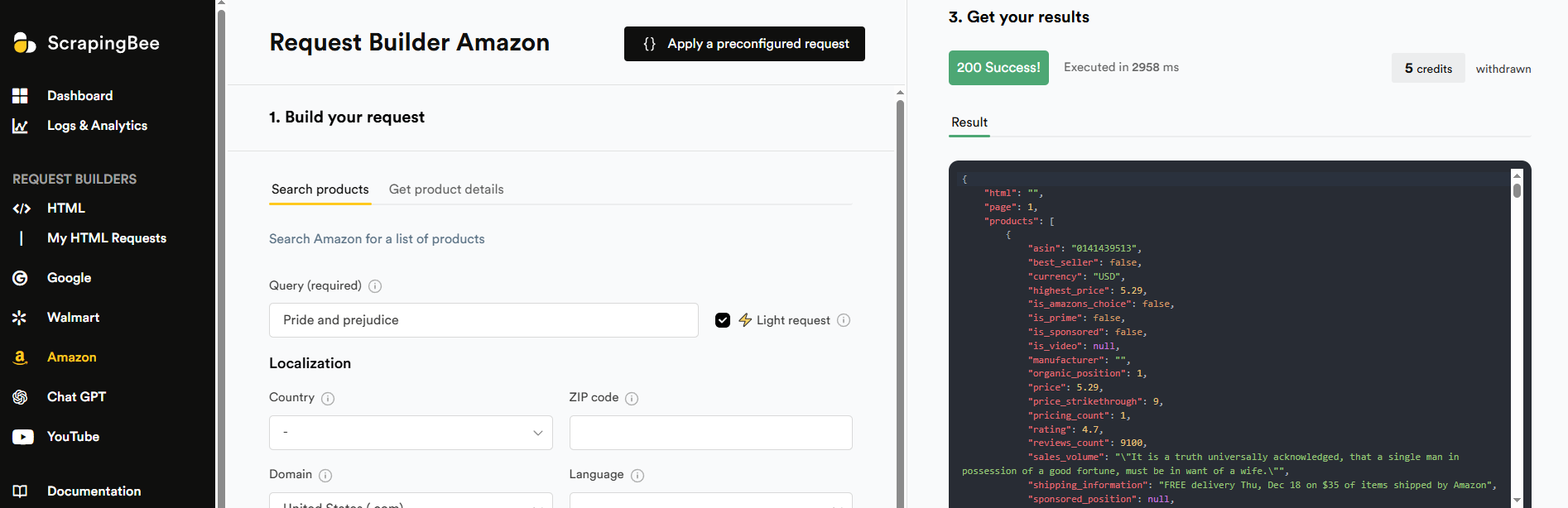
ScrapingBee runs thousands of headless browsers for JavaScript rendering and offers an AI-powered extraction engine that accepts plain-English instructions. The Amazon scraper handles product pages and search results with detailed parameter options.
The API defaults to JavaScript rendering on all requests, which costs 5 credits per call. For Amazon product pages, this is often unnecessary since the critical data loads in the initial HTML. You'll need to explicitly disable rendering to avoid burning credits on pages that don't require it.
ScrapingBee's screenshot capture feature is useful for visual verification of scraped data, though it adds latency to each request.
In our tests, ScrapingBee achieved 99.37% success rate with 3,223ms average response time, making it one of the faster options with near-perfect reliability.
Why Choose ScrapingBee Amazon API
- Fast response times: 3.2-second average puts ScrapingBee among the fastest providers. For real-time price monitoring or user-facing applications, this speed matters.
- Near-perfect reliability: 99.37% success rate with only occasional failures. The gaps are small enough that simple retry logic handles edge cases.
- AI extraction engine: Submit plain-English instructions like "extract product name, price, and rating" and receive structured JSON. Reduces development time for simple scraping tasks.
- Detailed parameter control: Granular options for headers, cookies, and rendering behavior. More control than fully-automated alternatives for teams with specific requirements.
6. ScrapingDog
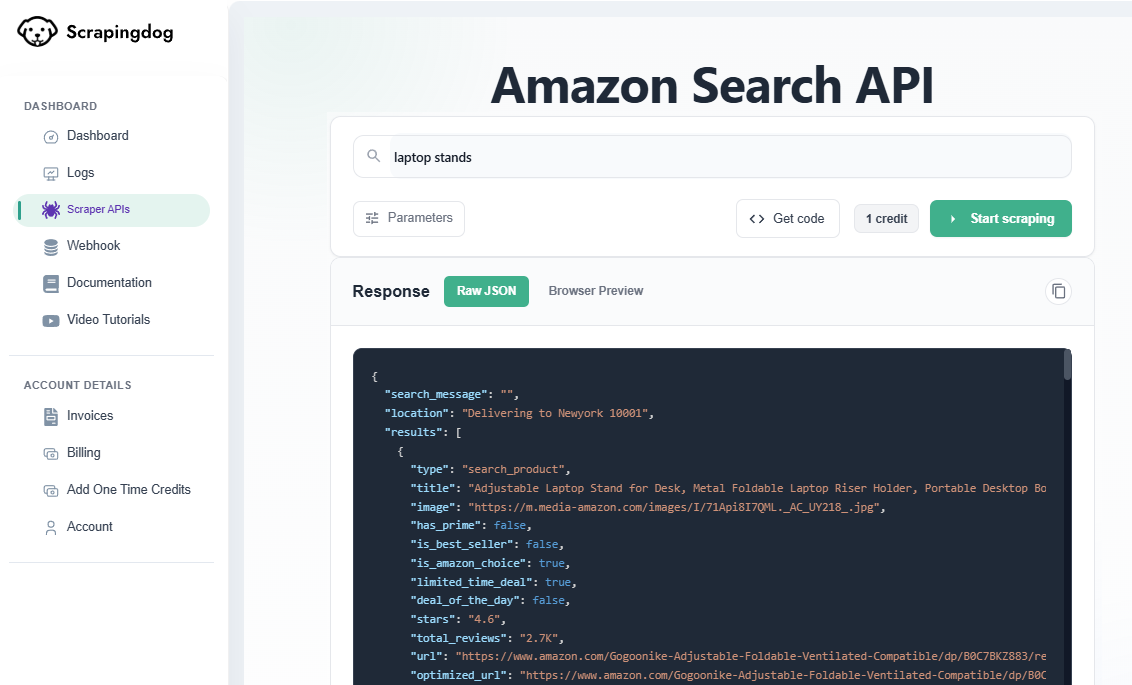
ScrapingDog positions itself as a budget-friendly option with dedicated Amazon endpoints for product pages, search results, and seller offers. The API combines proxy rotation with headless Chrome for JavaScript-heavy pages.
The trade-off for lower pricing is reduced reliability. Our tests showed an 89.06% success rate, the lowest among all providers tested. Roughly 1 in 10 requests failed, which requires robust retry logic and increases effective cost when factoring in wasted API calls.
Where ScrapingDog excels is raw speed. At 2,490ms average response time, it's the fastest provider we tested. If your use case tolerates some failures and prioritizes throughput over reliability, the speed advantage is significant.
In our tests, ScrapingDog achieved 89.06% success rate with 2,490ms average response time.
Why Choose ScrapingDog Amazon API
- Fastest response times: 2.5-second average beats every other provider. For high-volume scraping where you can retry failures, the speed compounds into substantial time savings.
- Budget-friendly pricing: $0.20 per 1,000 requests with a $40/month starting tier including 200,000 requests. Lower barrier to entry than enterprise-focused competitors.
- Lightweight integration: Simple API structure without complex parameter systems. Quick to integrate for straightforward product scraping.
- Acceptable for fault-tolerant workflows: If your pipeline handles retries gracefully, the 89% success rate may be acceptable given the speed and cost benefits.
7. WebScrapingAPI
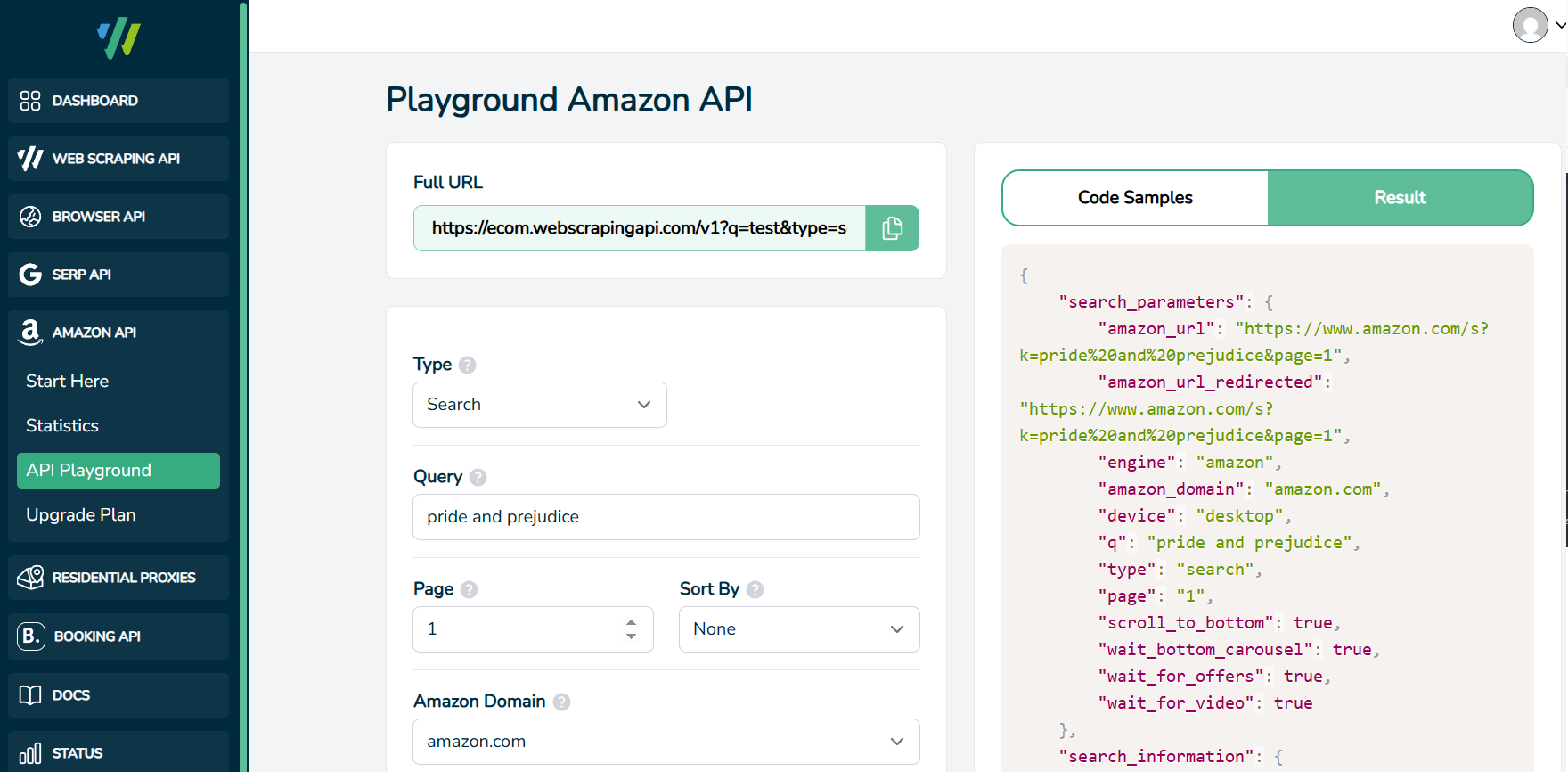
WebScrapingAPI offers the most generous free tier among Amazon scraping APIs, with 5,000 requests monthly at no cost. The platform provides endpoints for product pages, search results, seller offers, best sellers, and related searches.
The standout feature is flat-rate pricing: every request costs 1 credit regardless of whether JavaScript rendering or premium proxies are enabled. Competitors typically charge 5-25x more for protected pages. This predictability helps with budgeting, though the base rate of $2.45 per 1,000 requests is higher than some alternatives.
WebScrapingAPI offers official SDKs for Python, Node.js, Java, and Scrapy integration, reducing setup time for common tech stacks.
In our tests, WebScrapingAPI achieved 93.27% success rate with 7,921ms average response time.
Why Choose WebScrapingAPI Amazon API
- Largest free tier: 5,000 monthly requests for free with no expiration. Enough to build and test complete scraping workflows before paying anything.
- Flat-rate pricing: No credit multipliers for rendering or premium proxies. Protected pages that cost 25-75 credits elsewhere cost 1 credit here. Predictable budgeting regardless of target difficulty.
- Extensive endpoint coverage: If you want to scrape amazon best sellers, PDP, search, seller offers, and related searches; almost all of them are available. One of the more complete Amazon API offerings despite the mid-tier success rate.
- Official SDK support: Python, Node.js, Java, and Scrapy libraries maintained by WebScrapingAPI. Faster integration than raw HTTP requests for supported languages.
What to Pick
After testing all seven providers on Amazon product pages, here's how they stack up:
Best overall: Scrape.do combines 100% success rate with the fastest response times (3,029ms) and lowest cost ($0.12 per 1K). The complete endpoint coverage, including variation scraping and zipcode-level geo-targeting, makes it the most capable option for serious Amazon data extraction.
Best for enterprise: Bright Data offers the largest infrastructure and ready-made datasets, but at premium pricing. Choose this if you need bulk processing at massive scale or pre-collected historical data.
Best for detailed data: Oxylabs returns the most comprehensive JSON responses with fields other APIs skip. Worth considering if you need shipping estimates, Q&A data, and product specifications in every request.
Best budget option: ScrapingDog at $0.20 per 1K with the fastest raw speed, but the 89% success rate means you'll need retry logic. WebScrapingAPI's free tier (5,000 requests/month) is better for testing.
Avoid if reliability matters: ScrapingDog's 89% success rate wastes roughly 11% of your API budget on failed requests that need retries.
For most Amazon scraping projects, Scrape.do delivers the best combination of reliability, speed, and cost. The 100% success rate eliminates retry overhead, sub-3-second responses keep pipelines moving, and $0.12 per 1K requests leaves room in the budget for scale.
Get 1000 free credits and start scraping Amazon with Scrape.do
Lead Software Engineer








