Category:Scraping Tools
5 Best ScrapingBee Alternatives in 2026

Lead Software Engineer



You don't quite enjoy ScrapingBee forcing you to use stealth proxies for 75 credits and wait for 10s of seconds to get a single response.
Or you heard the news that the scraping industry giant Oxylabs acquired your current web scraBEEng API. (sorry, had to do it)
Regardless of the reasons, you're looking for another web scraping API that's better than ScrapingBee in at least one way.
Then, you've come to the right place:
| API Name | Avg. Success Rate | Avg. Response Time | Starting Price | Avg. Price per 1K Requests |
|---|---|---|---|---|
| ScrapingBee | 92.69% | 11.7s | $49 | $3.90 |
| Scrape.do | 98.19% | 4.7s | Freemium | $0.80 |
| ScraperAPI | 92.70% | 15.7s | $49 | $8.49 |
| ZenRows | 92.64% | 10.0s | $69 | $4.48 |
| ScrapingAnt | 45.45% | 32.7s | $19 | $0.76 |
| ScrapFly | N/A | N/A | $30 | $4.11 |
The table below compares ScrapingBee with five alternatives based on independent benchmark data from the best web scraping APIs; run across Amazon, Indeed, GitHub, Zillow, Capterra, Google, and X (Twitter). ScrapFly couldn't be tested due to SMS verification requirements.
What ScrapingBee Does Well
Before we cover alternatives, here's where ScrapingBee actually delivers value:
AI-Powered Extraction
ScrapingBee's AI extraction parameter accepts plain-English instructions and returns structured JSON or CSV output.
You can specify "extract product names and prices" instead of writing custom CSS selectors or XPath expressions.
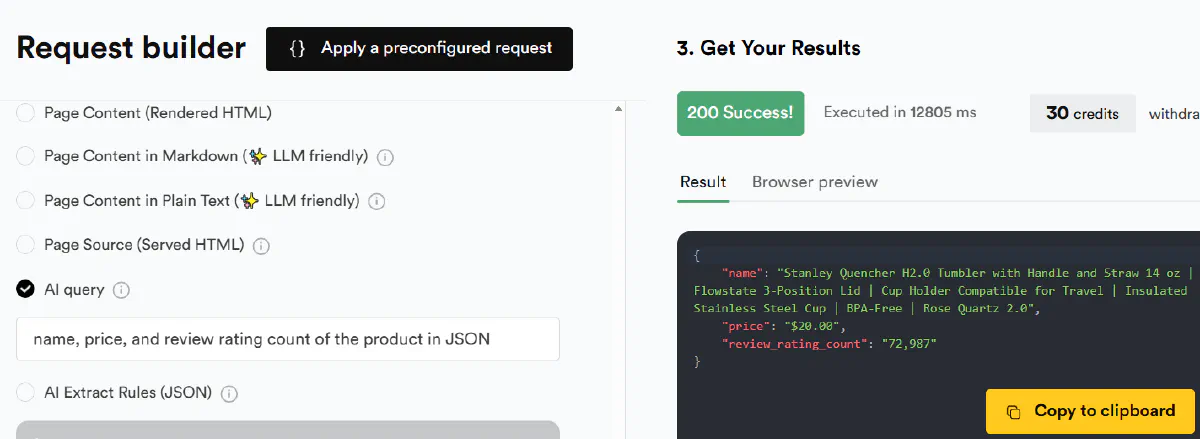
This eliminates manual parsing work for common data extraction patterns.
Strong Performance on Standard Targets
ScrapingBee delivered 99.11% success on Amazon, 99.29% on Indeed, 100% on GitHub, and 99.6% on X (Twitter) in testing. These are mainstream platforms with moderate bot protection, and ScrapingBee handles them reliably.
Speed was also solid on simple targets: GitHub came back in 3.2 seconds, Indeed in 5.6 seconds, and X in 9.1 seconds. For e-commerce and social media scraping, the performance holds up where it counts.
Downsides of ScrapingBee
The problems start when you look at default settings and edge cases.
JavaScript Rendering Enabled by Default
Every request costs 5 credits unless you explicitly disable rendering.
This isn't a one-time setting; you need to remember to turn it off for each API call to static pages.
There's no warning system when you accidentally use JS rendering on pages that don't need it. You'll burn through your credit allocation 5x faster than necessary, and only realize it when you check your usage dashboard after the damage is done.
Stealth Proxy Pricing Spikes
Some domains force stealth proxies at 75 credits per request, regardless of whether rendering is enabled. Capterra dropped to 59% success rate with 36-second response times and cost $15 per 1,000 requests, a 75x markup over the base $0.20 price.
There's no way to predict which domains require stealth proxies until you try scraping them. The documentation doesn't list per-domain requirements, so you discover the multiplier only after requests start failing or your credits disappear faster than expected.
1. Scrape.do
Scrape.do is the fastest and most reliable scraping API tested, delivering 98.19% success rates without default parameter traps or unpredictable pricing spikes.
The platform achieved 4.7-second average response time, 2.5x faster than ScrapingBee, with near-perfect success on Amazon (99.86%), Indeed, GitHub, Zillow, Capterra, and Google (all 100%).
Pros
- Fastest response times across all domains: Averaged 4.7s vs ScrapingBee's 11.7s. Amazon came back in 6.8s vs 10.6s, and Google in 1.6s (ScrapingBee didn't test Google). When speed determines how many pages you can scrape per hour, that 2.5x difference compounds.
- Higher success rate: Hit 98.19% average vs 92.69%, with perfect 100% on 5 out of 7 domains compared to ScrapingBee's 2 out of 6. The reliability gap widens on difficult targets: Scrape.do handled Capterra at 100% while ScrapingBee dropped to 59%.
- Transparent pricing, no default traps: Parameters are disabled by default. You opt in to rendering or premium proxies explicitly, and the credit multiplier applies only when you choose to enable features. No surprise 5x burn rate.
- Better value on protected sites: Difficult domains cost $0.58-$2.90 per 1K requests vs ScrapingBee's $15 spikes on Capterra. Even with rendering and premium proxies enabled, Scrape.do costs less than ScrapingBee's stealth proxy tier.
Cons
- No AI extraction engine: Requires manual parsing with BeautifulSoup or similar libraries. Custom scrapers are available for a handful of popular domains, but there's no plain-English instruction interface like ScrapingBee's AI engine.
ScrapingBee vs Scrape.do
Scrape.do is 2.5x faster on average (4.7s vs 11.7s) and costs less ($0.80 vs $3.90 per 1K). The pricing structure is transparent with opt-in parameters, while ScrapingBee defaults rendering ON and forces stealth proxies on certain domains.
Protected site handling shows the clearest difference: Scrape.do scraped Capterra successfully at $0.58 per 1K, while ScrapingBee struggled to 59% success at $15 per 1K. ScrapingBee offers AI extraction for natural language queries, but Scrape.do requires manual parsing for most use cases.
Check in-depth comparison of Scrape.do vs ScrapingBee or start free with Scrape.do and see the difference for yourself.
2. ScraperAPI
ScraperAPI matches ScrapingBee's success rate (92.70%) but struggles with speed, averaging 15.7 seconds per request.
The service hit 99.21% on Amazon and 100% on GitHub, proving reliability on e-commerce targets. But it stumbled badly on Google, dropping to 81.72%, the worst performance on that domain among all providers tested.
Pros
- Comparable success on e-commerce: The 99.21% success rate on Amazon matches production requirements for product scraping. If your primary use case is extracting listings, prices, and reviews from e-commerce platforms, ScraperAPI delivers consistent results.
- Templates for common use cases: Pre-built scrapers exist for SERP, e-commerce, and real estate scraping. These templates handle pagination, rate limiting, and data extraction patterns without requiring you to build from scratch.
Cons
- Slower than ScrapingBee: Averaged 15.7s per request vs ScrapingBee's 11.7s. Indeed took 25.9 seconds, and Zillow required 19.4 seconds. When you're scraping thousands of pages, that 34% speed penalty cuts your throughput significantly.
- Most expensive per 1K: At $8.49 average cost per 1,000 requests, ScraperAPI costs more than every other provider tested. Capterra spiked to $36.75 per 1K, making it prohibitively expensive for protected sites that already have low success rates.
- Limited geo-targeting on entry plan: The $49 plan restricts you to US and EU locations. Scraping region-specific content in Asia, Latin America, or other markets requires upgrading to plans starting at $149/month.
ScrapingBee vs ScraperAPI
ScrapingBee is faster (11.7s vs 15.7s) and cheaper on average ($3.90 vs $8.49 per 1K). Both providers include global geo-targeting, but ScraperAPI restricts cheaper tiers to US/EU only.
The Google performance gap is notable: ScrapingBee didn't test Google, but ScraperAPI's 81.72% success rate was the worst among all providers. Both services suffer from unpredictable pricing spikes on protected domains, making budget planning difficult for production scraping operations.
3. ZenRows
ZenRows delivers 92.64% success with 10.0-second response times, making it faster than ScrapingBee but with forced parameter combinations that eliminate cost optimization.
The platform ranked as the second-fastest provider overall.
Critically, ZenRows automatically enables both rendering and premium proxies on certain domains with no option to disable, forcing you to spend 25 requests per call regardless of whether cheaper methods would work.
Pros
- Faster than ScrapingBee: Averaged 10.0s per request vs 11.7s, with clear wins on GitHub (2.5s vs 3.2s) and Zillow (3s vs 5.7s). The speed advantage compounds when scraping large datasets or running time-sensitive operations.
- No default parameter traps: Unlike ScrapingBee, ZenRows doesn't enable JavaScript rendering by default. Parameters activate only when the system determines they're required for the target domain, not as a global setting you need to remember to disable.
Cons
- Higher starting price: The $69/month plan costs 41% more than ScrapingBee's $49, but only includes 10K protected results with both rendering and premium proxies enabled. That's enough for testing but not for sustained production scraping.
- Forced parameters on popular domains: ZenRows auto-enables the 25x credit multiplier (render + premium proxies) on certain websites with no opt-out. This creates the same pricing trap as ScrapingBee's stealth proxies, just implemented differently.
- Similar pricing on protected sites: Indeed, Google, and X all cost $7 per 1K requests, comparable to ScrapingBee's $5-15 range when stealth proxies are required. The forced parameter activation eliminates any cost advantage on these domains.
ScrapingBee vs ZenRows
ZenRows is faster (10.0s vs 11.7s) and doesn't enable rendering by default, but both providers force expensive parameter combinations on certain domains.
ScrapingBee's stealth proxy tier costs 75 credits; ZenRows forces 25 credits but applies it more broadly.
The starting cost differs significantly: ScrapingBee at $49 vs ZenRows at $69. Protected site costs land in similar ranges ($4-7 per 1K for ZenRows, $5-15 for ScrapingBee), but ZenRows is more upfront about when forced parameters apply. Success rates are nearly identical at 92.69% vs 92.64%.
4. ScrapingAnt
ScrapingAnt offers the cheapest base price at $19/month but catastrophic reliability, failing on over half of all requests tested.
The service averaged 45.45% success rate with 32.7-second response times, the slowest among all providers. ScrapingAnt couldn't scrape Capterra at all, failed on GitHub (19.94%), Google (21.2%), Amazon (47.54%), and Zillow (41.2%).
Pros
- Cheapest starting price: At $19 for 100K credits, it costs 61% less than ScrapingBee's $49. For projects with extremely tight budgets or experimental use cases, the low entry point reduces initial commitment.
- Low base cost when it works: On the rare domains where ScrapingAnt succeeds, the cost drops to $0.19 per 1K requests. That's 95% cheaper than ScrapingBee's base rate.
Cons
- Catastrophic success rate: The 45.45% average means requests fail more often than they succeed. ScrapingBee's 92.69% success rate is literally twice as reliable, making ScrapingAnt unsuitable for any production environment where data completeness matters.
- Slowest response times: Averaged 32.7s per request, with Zillow taking 49.9 seconds (the slowest single result measured across all providers), Google 44.6 seconds, and Indeed 40.8 seconds. Even when requests succeed, the speed penalty makes large-scale scraping impractical.
ScrapingBee vs ScrapingAnt
ScrapingBee succeeds twice as often (92.69% vs 45.45%) and responds 2.8x faster (11.7s vs 32.7s). ScrapingAnt's cheaper average cost ($0.76 vs $3.90 per 1K) becomes meaningless when requests fail more than half the time.
Production viability separates these services clearly: ScrapingBee works reliably enough for real applications, while ScrapingAnt's sub-50% success rate on mainstream sites makes it unusable for any workflow that requires consistent data extraction.
The only similarity is that both impose severe credit multipliers when advanced features are enabled.
5. ScrapFly
ScrapFly's $30 starting package includes 200K basic requests. Rendering and residential proxies cost 30 credits combined (5 for render + 25 for residential), cutting the effective request count to 6,666 for protected sites.
ScrapFly offers AI extraction with LLMs, a dedicated Screenshot API, and integrations with LangChain, LlamaIndex, Zapier, Make, and N8N.
Pros
- Lower starting price: At $30, it costs 39% less than ScrapingBee's $49. Teams with budget constraints can access the platform at a lower entry point, assuming they clear the verification barrier.
- Broader integration ecosystem: Native support for LangChain and LlamaIndex makes ScrapFly attractive for AI-powered scraping workflows. The Zapier, Make, and N8N connections enable no-code automation that ScrapingBee doesn't support.
- Dedicated Screenshot API: Offers full-page captures, element-specific screenshots, viewport customization, and format conversion. ScrapingBee provides basic screenshot functionality, but ScrapFly treats it as a first-class product feature.
Cons
- SMS verification required: You can't test the platform without providing a phone number. Multiple user reports mention getting banned without explanation or detailed reasoning, raising concerns about arbitrary enforcement and service reliability.
- Similar pricing spikes: Averages $4.11 per 1K requests compared to ScrapingBee's $3.90. Both services hide costs until you start scraping specific domains, making budget forecasting difficult.
- Can't verify performance: Testing was blocked by access restrictions, so the reliability and speed claims can't be validated against the same benchmark conditions used for other providers.
ScrapingBee vs ScrapFly
ScrapingBee allows instant testing without phone verification, while ScrapFly gates access behind SMS requirements. Pricing shows similar unpredictability ($3.90 vs $4.11 per 1K average), with both platforms hiding per-domain costs until you start scraping.
ScrapFly offers more integrations (LangChain, LlamaIndex, automation platforms) compared to ScrapingBee's core scraping focus. Screenshot capabilities favor ScrapFly with its dedicated API versus ScrapingBee's basic capture functionality. The trust factor tilts toward ScrapingBee since it's immediately testable, while ScrapFly's ban reports and verification requirements create friction before you can evaluate the actual service quality.
What to Pick?
- For speed and reliability without pricing traps: Scrape.do delivers 98.19% success at 4.7s average with transparent opt-in parameters and no default feature costs. Parameters are disabled unless you explicitly enable them, eliminating surprise credit burns.
- For pre-built templates on mainstream sites: ScraperAPI provides ready-made SERP and e-commerce scrapers that handle common extraction patterns out of the box, though at 15.7s average response time and $8.49 per 1K requests.
- For faster alternative with similar reliability to ScrapingBee: ZenRows hits 92.64% success at 10.0s response time with a clearer cost structure than ScrapingBee's stealth proxy surprises, though the $69 starting price is steep.
- For AI integrations and screenshot needs: ScrapFly offers LangChain/LlamaIndex support and dedicated screenshot API capabilities, but SMS verification requirements and unexplained ban reports create barriers to adoption.
- Skip entirely: ScrapingAnt's 45.45% success rate makes it unusable for production work regardless of the $19 entry price. Failing more than half the time eliminates any cost advantage.
Overall, Scrape.do is the best alternative to ScrapingBee. It combines higher success rates (98.19%), faster response times (4.7s), and more transparent pricing ($0.80 avg per 1K) without default parameter traps or unpredictable stealth proxy costs.
Lead Software Engineer








