
Book Outlet Scraper
Scrape Prices and Inventory from Book Outlet
Extract discounted book prices, list prices, ISBNs, and live stock levels from North America's largest bargain bookstore. Book Outlet sits behind Cloudflare and serves fast-rotating, region-aware inventory that trips up standard scrapers. Scrape.do handles it automatically.
Start scraping today with 1000 free credits. No Credit Card Required
1.4M Monthly Visits. Bargains That Vanish Fast. One API.
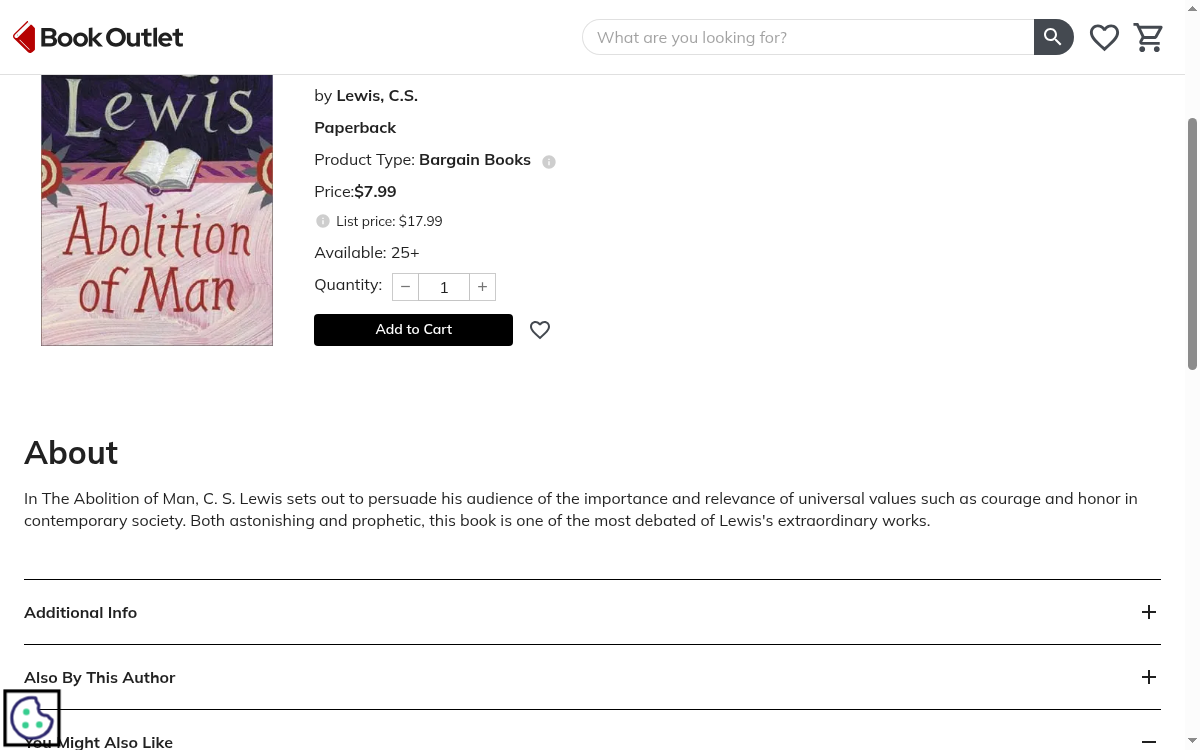
Book Outlet is the direct-to-consumer arm of Book Depot, one of North America's largest bargain book distributors, pulling in over 1.4 million monthly visits across its US and Canadian storefronts. Every title is brand new and discounted at least 50% off the publisher's list price, drawn from a fast-moving catalog of hundreds of thousands of overstock and remaindered books indexed by ISBN.
With Scrape.do you can track sale-vs-list price spreads on individual ISBNs, monitor stock counts that turn over in hours, watch new bargain drops as they land, feed LLMs and AI agents with structured book data, and rebuild discount catalogs at scale. All through a single API call.
Cloudflare. Datacenter Blocks. Handled.
Book Outlet runs behind Cloudflare, which fingerprints incoming requests and serves a “Sorry, you have been blocked” challenge to anything that looks automated or arrives from a flagged datacenter IP. The storefront is a Next.js app that also keys pricing and availability to the visitor's region, so a US shopper and a Canadian shopper see different prices and currencies on the same ISBN.
Scrape.do rotates high-quality residential IPs and lets you pin a geoCode so you collect the exact regional storefront you need, slipping past Cloudflare without CAPTCHA solvers or proxy lists to maintain. You get clean, complete HTML back on every request.
How to Scrape Book Outlet
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
targetUrl = "https://bookoutlet.com/book/abolition-of-man/lewis-cs/9780060652944B"
render = "false" # set to "true" to enable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
geoCode = "US"
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}&geoCode={geoCode}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Abolition of Man by C.S. Lewis - Book Outlet</title>
<meta property="og:title" content="Abolition of Man">
<meta property="og:type" content="book">
<meta property="book:isbn" content="9780060652944">
<meta property="book:author" content="Lewis, C.S.">
</head>
<body>
<div class="product-detail">
<h1 class="product-title">Abolition of Man</h1>
<a class="product-author" href="/author/lewis-cs">Lewis, C.S.</a>
<span class="product-format">Paperback</span>
<span class="product-type">Bargain Books</span>
</div>
<div class="price-block">
<span class="sale-price">$7.99</span>
<span class="list-price">List price: $17.99</span>
<span class="availability">Available: 25+</span>
</div>
<div class="product-image">
<img src="https://images.bookoutlet.com/covers/large/isbn978006/9780060652944-l.jpg">
</div>
<div class="additional-info">
<span class="isbn">ISBN: 9780060652944</span>
<span class="publisher">Publisher: Harper Collins</span>
<span class="published-date">Published: March 1, 2001</span>
<span class="page-count">Page Count: 113</span>
<span class="language">Language: English</span>
<a class="category" href="/books/category/religion-and-spirituality">Religion and Spirituality</a>
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do routes requests through rotating residential IPs to clear Book Outlet's Cloudflare fingerprinting and “Sorry, you have been blocked” challenges, so product and collection pages return complete HTML. Success rates exceed 95%.
Book Outlet serves different prices and currencies on bookoutlet.com (USD) and bookoutlet.ca (CAD) based on visitor region. Pass geoCode=US or geoCode=CA to Scrape.do to pin the exact regional storefront and capture the matching price for each ISBN.
You can extract book titles, authors, ISBNs, sale prices, publisher list prices, the discount spread, format and product type (Bargain Books), live stock availability, publisher, page count, category, cover images, and full collection and category listings.






