
BigBadToyStore Scraper
Scrape Products and Preorders from BigBadToyStore
Extract product prices, stock status, and preorder windows from the US's biggest specialty action figure and collectibles store. BigBadToyStore sits behind Cloudflare with a Turnstile-style human verification challenge that blocks plain HTTP clients and headless browsers. Scrape.do handles it automatically.
Start scraping today with 1000 free credits. No Credit Card Required
6.1M Monthly Visits. Every Franchise. One API.
BigBadToyStore is the biggest US specialty retailer for licensed action figures, statues, and collectibles, pulling in around 6.1 million monthly visits and ranking #20 in the Ecommerce - Other category on SimilarWeb. The catalog runs deep into Hot Toys, Bandai, Hasbro, McFarlane, Mezco, and Good Smile, with thousands of preorders months ahead of release and the BigBadToyBank installment program that locks high-ticket figures at announcement.
With Scrape.do you can track preorder availability windows and street prices across franchises like Marvel Legends, Star Wars Black Series, and Transformers, monitor stock and waitlist signals for limited drops, feed LLMs and AI agents with real-time collectibles pricing, and benchmark BBTS against AmiAmi, Sideshow, and HasbroPulse at scale. All through a single API call.
Cloudflare Turnstile. Bot UA Blocks. Handled.
BigBadToyStore runs behind Cloudflare, with a Turnstile-style "We're confirming that you're human and not a bot." verification page that fires on any request from a non-browser User-Agent, Python requests, cURL, or Go HTTP clients. Hit a product page with the wrong UA and you get a 403 and an empty shell long before the price block loads.
Scrape.do rotates real residential IPs with full browser fingerprints, passes the Cloudflare challenge automatically, and returns the fully populated HTML with the price, stock status, condition variations, and the preorder release window intact. No browser automation to maintain, no Turnstile solvers, no proxy lists.

How to Scrape BigBadToyStore
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
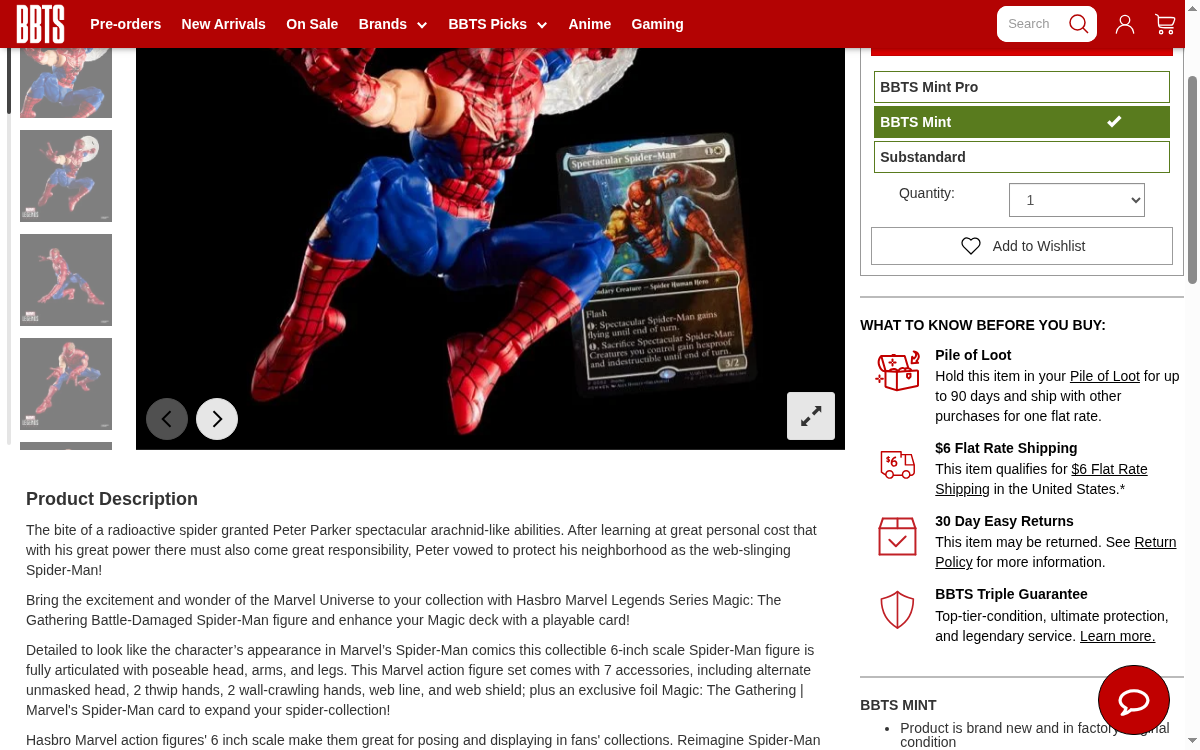
targetUrl = "https://www.bigbadtoystore.com/product/marvel-legends-spider-man-action-figure-exclusive-magic-gathering-card-165682"
render = "false" # set to "true" to enable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Marvel Legends Spider-Man Action Figure with Exclusive Magic: The Gathering Card | BigBadToyStore</title>
</head>
<body>
<div class="product-header">
<h1>Marvel Legends Spider-Man Action Figure with Exclusive Magic: The Gathering Card</h1>
</div>
<div class="product-status">
<span class="status-label">IN STOCK</span>
<span class="price">$39.99</span>
</div>
<div class="product-variations">
<span class="condition active">BBTS Mint</span>
<a class="variation" href="?variation=326967">BBTS Mint Pro</a>
<a class="variation" href="?variation=326971">Substandard</a>
</div>
<div class="shipping-info">
<div class="info-row">Pile of Loot: hold up to 90 days</div>
<div class="info-row">$6 Flat Rate Shipping (US)</div>
<div class="info-row">30 Day Easy Returns</div>
<div class="info-row">BBTS Triple Guarantee</div>
</div>
<div class="product-description">
<p>Bring the excitement and wonder of the Marvel Universe to your collection with
Hasbro Marvel Legends Series Magic: The Gathering Battle-Damaged Spider-Man figure...</p>
</div>
<div class="product-features">
<ul>
<li>6-inch scale (15.24cm)</li>
<li>Made of plastic</li>
<li>Based on the Marvel Comics character</li>
<li>Multiple points of articulation</li>
<li>Includes Magic: The Gathering card</li>
</ul>
</div>
<div class="additional-details">
<span class="brand">Marvel</span>
<span class="series">Marvel Legends</span>
<span class="manufacturer">Hasbro</span>
</div>
<div class="product-gallery">
<img src="https://images.bigbadtoystore.com/images/product/165682/...image1.jpg">
<img src="https://images.bigbadtoystore.com/images/product/165682/...image2.jpg">
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do rotates real residential IPs with full browser fingerprints to pass BigBadToyStore's Cloudflare Turnstile-style human verification, so you get fully rendered product and category HTML instead of the 403 block page. Success rates exceed 95% on product, brand, and franchise pages.
You can extract product titles, prices, in-stock vs preorder status, condition variations (BBTS Mint, BBTS Mint Pro, Substandard), expected release windows for preorders, manufacturer and series tags (Hot Toys, Marvel Legends, Star Wars Black Series, Transformers Studio Series), product images, descriptions, box contents, and franchise-level category listings.
No. BigBadToyStore product and category pages are server-rendered, so a plain render=false Scrape.do call returns the full HTML with price, stock, and preorder data once the Cloudflare challenge is solved. Skip render to keep request costs minimal.






