
Yankee Candle Scraper
Scrape Products and Prices from Yankee Candle
Extract pricing, fragrance details, and product specs from the world's leading premium scented candle brand. Yankee Candle sits behind Cloudflare with CDN-level bot detection that blocks automated requests. Scrape.do handles it automatically.
Start scraping today with 1000 free credits. No Credit Card Required
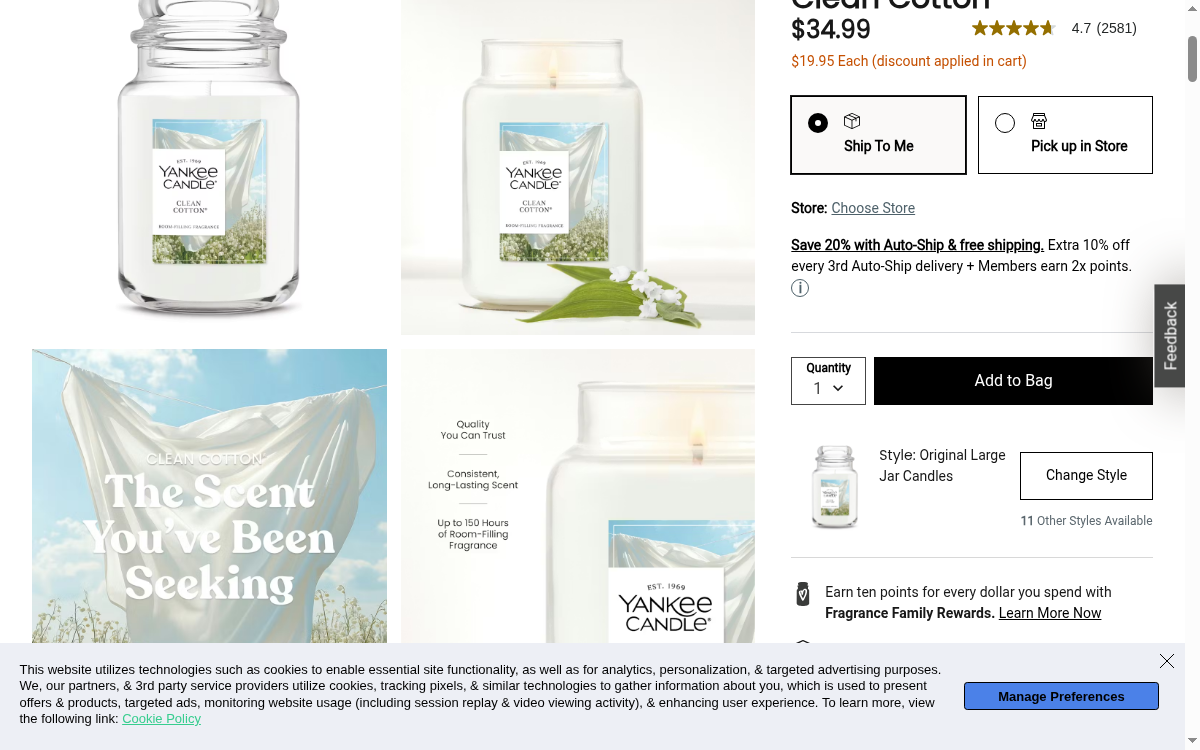
3.1M Monthly Visits. 150+ Fragrances. One API.
Yankee Candle is the world's best-known premium candle brand, drawing over 3.1 million monthly visits to its ecommerce site. The catalog spans 150+ signature fragrances across original jar candles, tumblers, wax melts, car fresheners, and seasonal limited editions — each with detailed burn times, size variants, and customer ratings.
With Scrape.do you can monitor pricing across candle formats, track seasonal fragrance launches and discontinuations, build competitive datasets for the home fragrance market, and aggregate customer review sentiment. One API call per page, no infrastructure overhead.
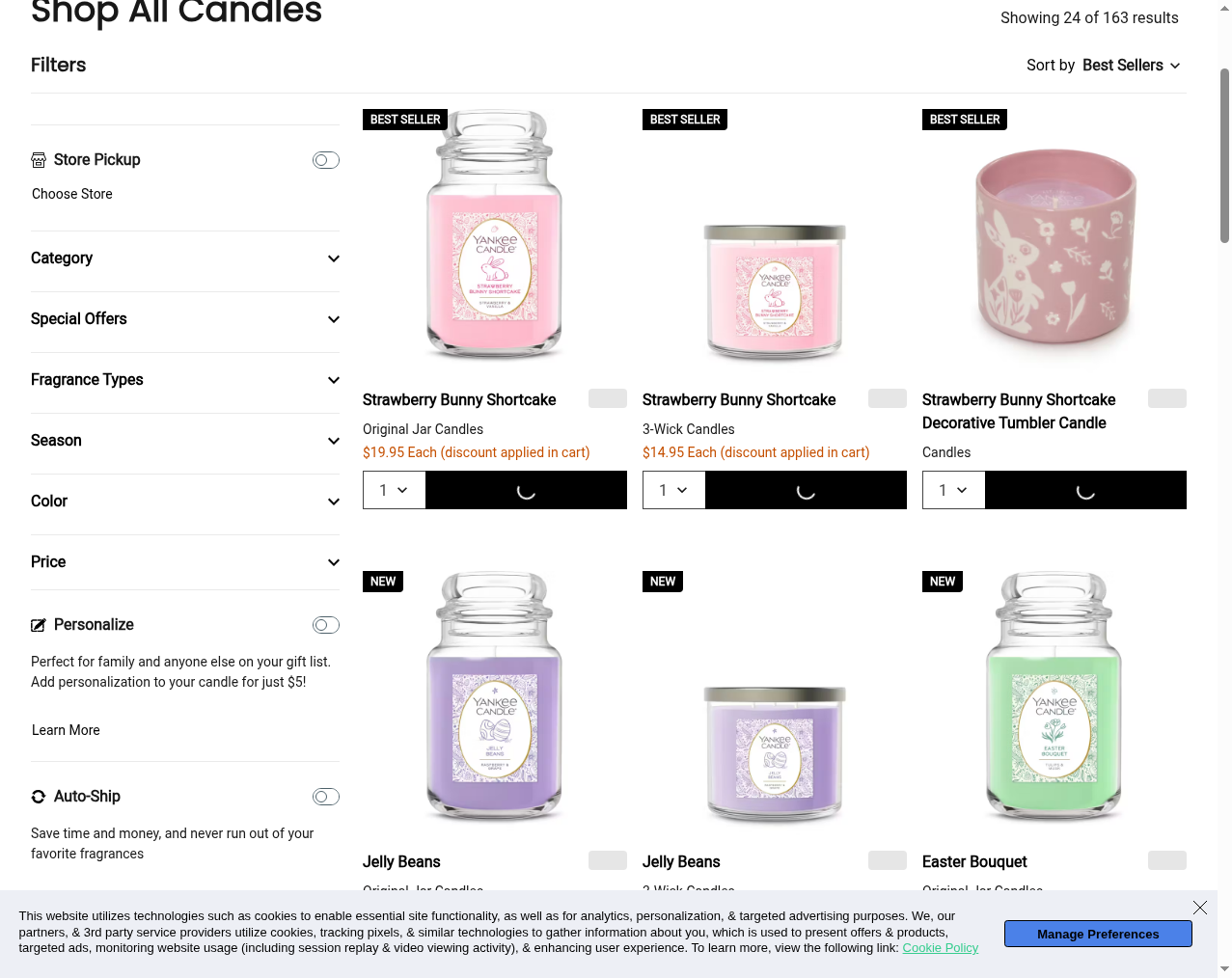
Cloudflare. CDN-Cached. Handled.
Yankee Candle uses Cloudflare for both CDN delivery and bot management, applying IP reputation scoring and request fingerprinting to filter automated traffic. While the site responds to basic HTTP requests, aggressive scraping patterns quickly trigger rate limiting and challenge pages.
Scrape.do rotates through residential IP pools and manages request patterns automatically, keeping you under Cloudflare's detection thresholds. No render or super proxy needed — standard requests return full product HTML with pricing, burn times, and review data at just $1 per 1,000 requests.
How to Scrape Yankee Candle Company
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
targetUrl = "https://www.yankeecandle.com/yankee-candle/candles/candle-styles/original-jar-candles/clean-cotton/SAP_2654258_PR.html"
render = "false" # set to "true" to enable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Clean Cotton Original Large Jar Candle | Yankee Candle</title>
</head>
<body>
<div class="product-detail-page">
<h1 class="product-title">Clean Cotton® Original Large Jar Candle</h1>
</div>
<div class="product-pricing">
<span class="price-value">$31.99</span>
</div>
<div class="product-specs">
<span class="spec-label">Size:</span>
<span class="spec-value">Original Large Jar (22 oz)</span>
<span class="spec-label">Burn Time:</span>
<span class="spec-value">110-150 Hours</span>
</div>
<div class="product-rating">
<span class="stars">4.7 out of 5</span>
<span class="review-count">3,218 Reviews</span>
</div>
<div class="fragrance-notes">
<p>Sun-dried cotton, green notes, white flowers, and a hint of lemon</p>
</div>
<div class="product-image">
<img src="https://www.yankeecandle.com/dw/image/...clean-cotton.jpg" alt="Clean Cotton">
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do manages IP rotation and request patterns to stay under Cloudflare's detection thresholds. Standard requests work without needing render or super proxy modes, keeping costs at $1 per 1,000 requests.
You can extract product names, prices, candle sizes, burn times, fragrance descriptions, fragrance notes, customer ratings and reviews, product images, and full category listings with all available scents.
Yes. Yankee Candle rotates seasonal fragrances frequently. You can scrape category pages to track new arrivals, monitor limited editions before they sell out, and build historical datasets of fragrance availability over time.






