
OZON Scraper
Scrape Products and Prices from Ozon.ru
Extract product prices, reviews, and inventory data from Russia's largest marketplace. Ozon.ru runs its own anti-bot system with browser fingerprinting, CAPTCHAs, and aggressive rate limits. Scrape.do handles them automatically.
Start scraping today with 1000 free credits. No Credit Card Required
500M+ Monthly Visits. Every Category. One API.
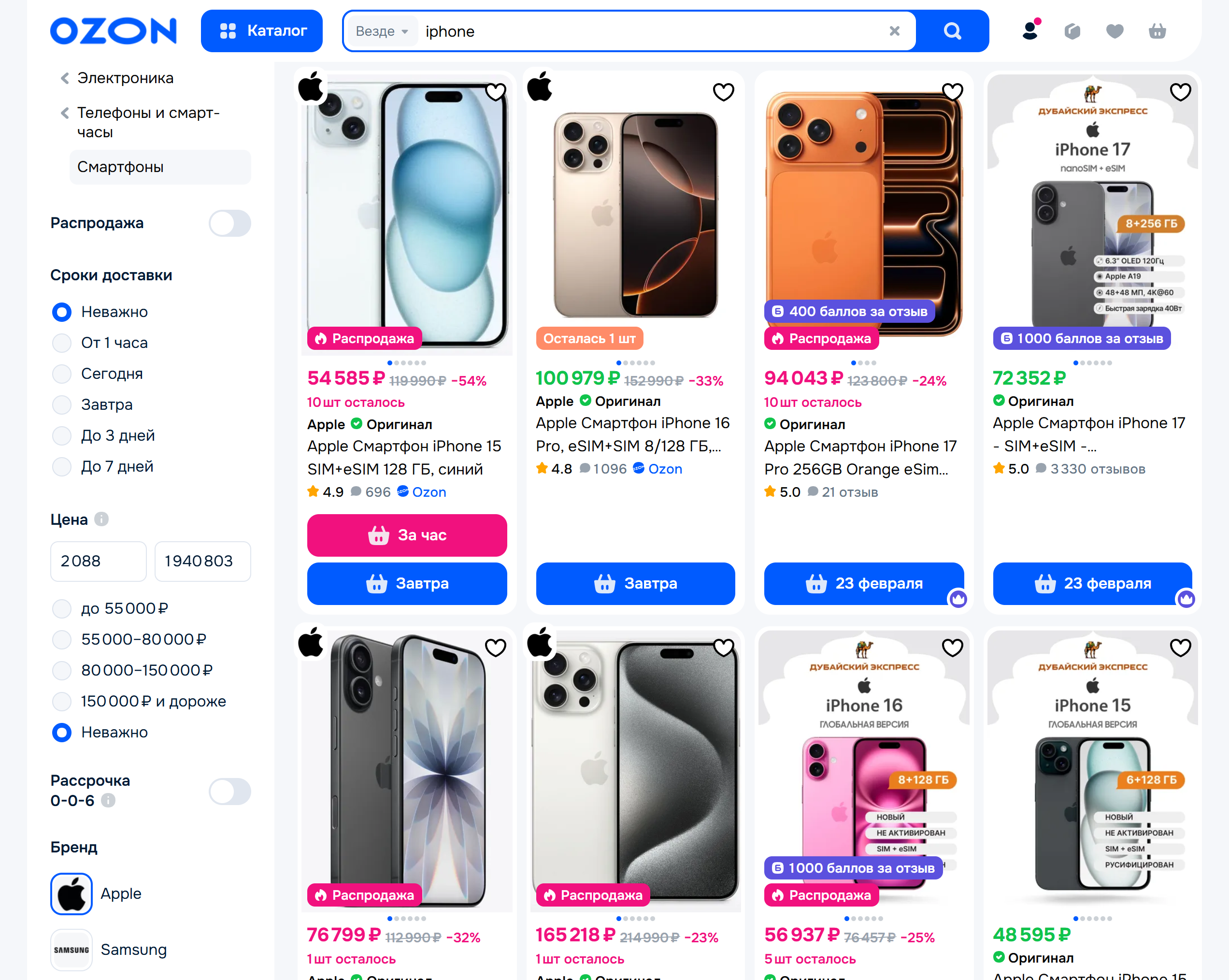
Ozon.ru is the largest e-commerce platform in Russia, pulling in over 500 million monthly visits in 2026. From phones to shoes, it lists products across every category imaginable, making it a scraping goldmine.
With Scrape.do you can track competitor pricing, check product availability and inventory levels, feed LLMs and AI agents with accurate real-time data, and conduct large-scale market analysis. All through a single API call.
Custom Anti-Bot. Aggressive Rate Limits. Handled.
Ozon has its own in-house detection system that aggressively monitors IP addresses, scrutinizes non-Russian and non-regional IPs, and blocks datacenter proxies and low-quality residential proxies on sight.
Rate limits are the other big problem where Ozon blocks your IP after just a few back-to-back requests, making any kind of bulk extraction impossible with standard tools.
Scrape.do rotates high-quality residential IPs to avoid IP bans and rate limits, so you get clean data without maintaining proxy lists or CAPTCHA solvers.
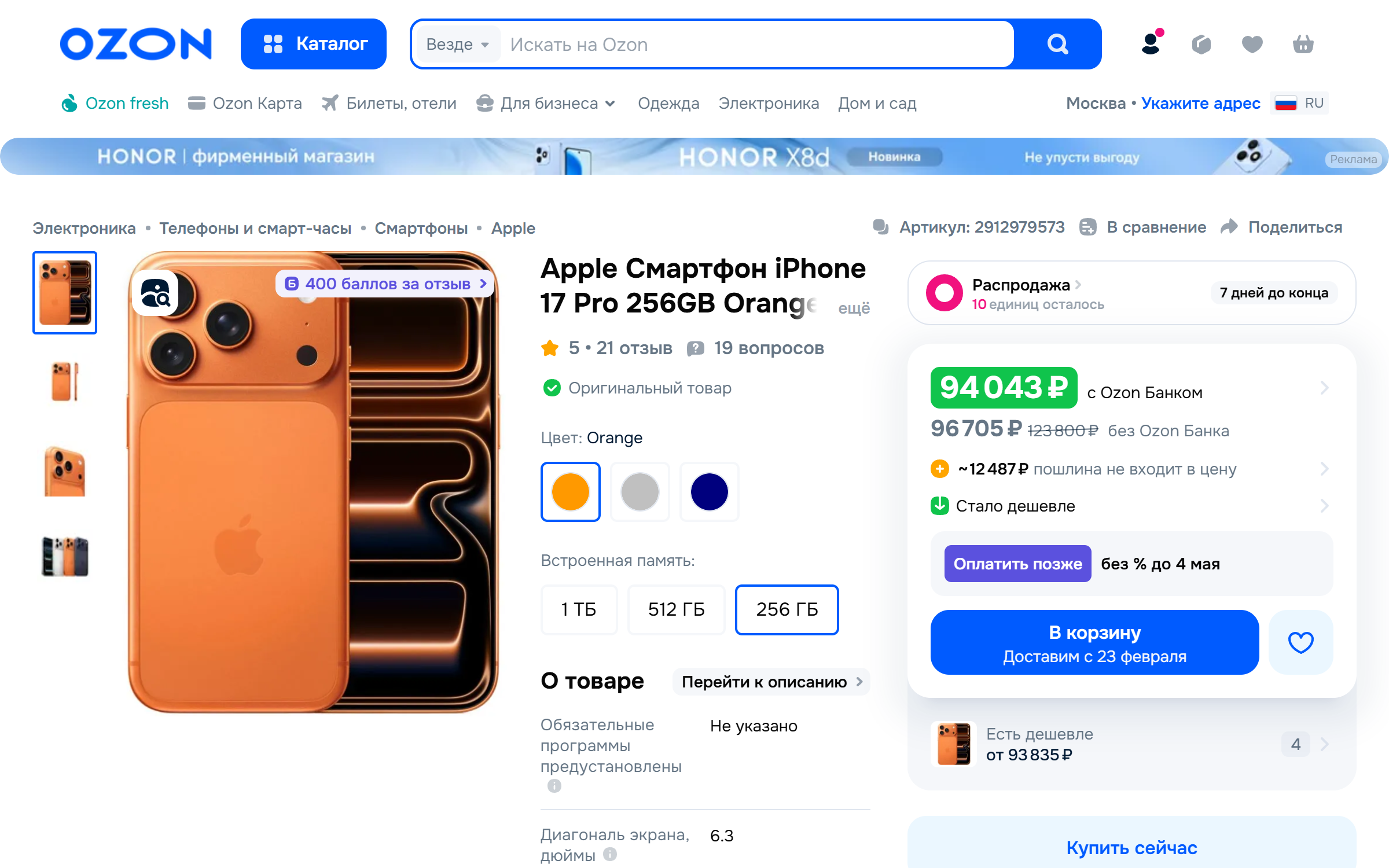
How to Scrape Ozon.ru
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
targetUrl = "https://www.ozon.ru/product/12345/"
render = "false" # set to "true" to enable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
geoCode = "RU"
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}&geoCode={geoCode}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<title>Смартфон Apple iPhone 15 128GB — купить на Озон</title>
</head>
<body>
<div data-widget="webProductHeading">
<h1>Смартфон Apple iPhone 15 128GB</h1>
</div>
<div data-widget="webPrice">
<span class="price">94 043 ₽</span>
<span class="original">123 999 ₽</span>
<span class="discount">-24%</span>
</div>
<div data-widget="webReviewProductScore">
<span class="rating">5.0</span>
<span class="count">21 отзыв</span>
</div>
<div data-widget="webSKU">
Артикул: 2912979573
</div>
<div data-widget="webGallery">
<img src="https://ir.ozone.ru/s3/...image1.jpg">
<img src="https://ir.ozone.ru/s3/...image2.jpg">
</div>
<div data-widget="webCharacteristics">
<span>Цвет: Чёрный</span>
<span>Память: 128 ГБ</span>
<span>Продавец: Apple</span>
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do uses real browser environments with rotating residential proxies to bypass Ozon.ru's in-house fingerprint detection, CAPTCHAs, and strict rate limits. Success rates exceed 95% on product listing and detail pages.
You can extract product titles, prices, discount information, stock levels, seller details, customer reviews and ratings, product images, and category hierarchies.
Ozon.ru relies heavily on React for client-side rendering. Use Scrape.do's headless browser mode (render=true) to execute JavaScript and capture the fully rendered page content.






