
GameStop Scraper
Scrape Products and Prices from GameStop
Extract product prices, stock availability, and trade-in values from the world's largest video game retailer. GameStop uses Cloudflare WAF with JavaScript rendering requirements that block standard scrapers. Scrape.do handles them automatically.
Start scraping today with 1000 free credits. No Credit Card Required
14M+ Monthly Visits. Every Console. One API.
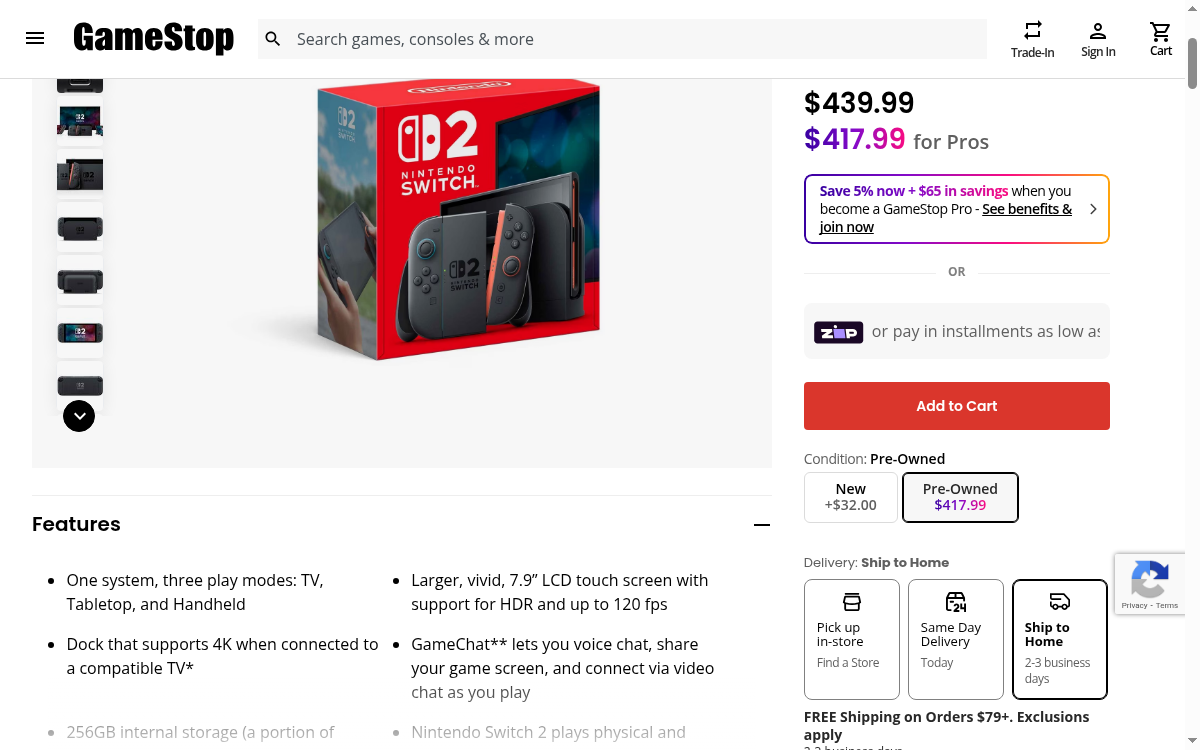
GameStop is the world's largest specialty video game retailer, pulling in over 14 million monthly visits and operating 3,200+ stores across the US, Canada, Australia, and Europe. From the latest Nintendo Switch 2 to pre-owned classics, it lists thousands of games, consoles, accessories, and collectibles.
With Scrape.do you can track product pricing across new and pre-owned conditions, monitor stock availability and pre-order drops, feed LLMs and AI agents with real-time gaming market data, and compare trade-in values at scale. All through a single API call.
Cloudflare WAF. JS Rendering Required. Handled.
GameStop uses Cloudflare as its WAF, blocking automated requests before the page even loads. The site is a fully client-side rendered React application, meaning raw HTTP requests return empty shells with no product data.
Scrape.do's headless browser mode renders the full JavaScript, executes React hydration, and returns the complete page with all product details, pricing, and availability data intact. No browser automation setup, no CAPTCHA solvers, no proxy lists to maintain.
How to Scrape GameStop
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
targetUrl = "https://www.gamestop.com/consoles-hardware/nintendo-switch/consoles/products/nintendo-switch-2/20019700.html"
render = "true" # set to "false" to disable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Nintendo Switch 2 Console | GameStop</title>
</head>
<body>
<div class="product-primary-header">
<h1>Nintendo Switch 2 Console</h1>
</div>
<div class="price-section">
<span class="actual-price">$439.99</span>
<span class="pro-price">$417.99 for Pros</span>
</div>
<div class="condition-toggle">
<span class="condition active">New +$32.00</span>
<span class="condition">Pre-Owned $417.99</span>
</div>
<div class="availability">
<span class="delivery-option">Ship to Home</span>
<span class="delivery-option">Pick Up In-Store</span>
<span class="delivery-option">Same Day Delivery</span>
</div>
<div class="product-features">
<ul>
<li>7.9" LCD touch screen with HDR support</li>
<li>Dock supports 4K output</li>
<li>256GB internal storage</li>
</ul>
</div>
<div class="product-gallery">
<img src="https://media.gamestop.com/...image1.jpg">
<img src="https://media.gamestop.com/...image2.jpg">
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do uses headless browser rendering with rotating residential proxies to bypass GameStop's Cloudflare WAF, JavaScript challenges, and rate limits. Success rates exceed 95% on product and category pages.
You can extract product titles, prices for new and pre-owned conditions, Pro member pricing, stock availability, trade-in values, product images, specifications, customer reviews, and category listings.
GameStop is a React-based single-page application. Use Scrape.do's headless browser mode (render=true) to execute JavaScript and capture the fully rendered page with all product data, pricing, and availability information.






