
Fruitful Yield Scraper
Scrape Products and Prices from Fruitful Yield
Extract supplement pricing, brand catalogs, and organic product data from one of the longest-running natural health retailers in the Midwest. Fruitful Yield is protected by Cloudflare bot detection. Scrape.do handles it automatically.
Start scraping today with 1000 free credits. No Credit Card Required
64K Monthly Visits. Niche Health Data. One API.
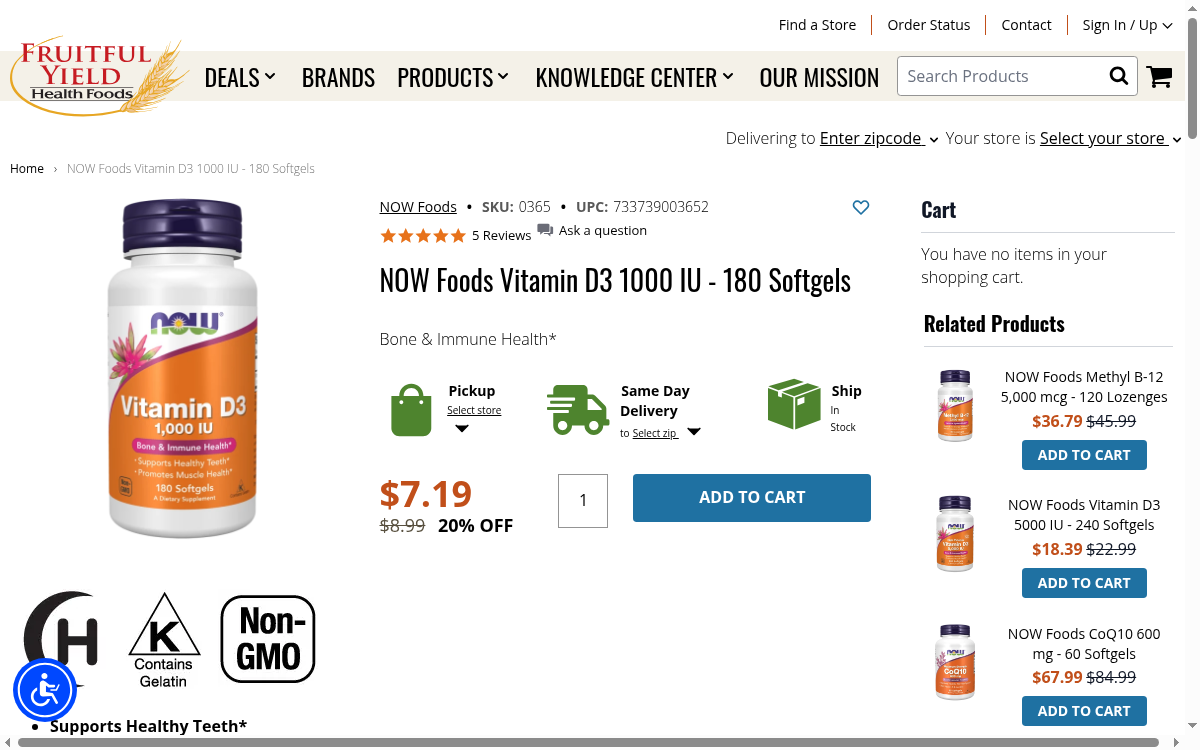
Fruitful Yield is a family-owned natural health food chain operating since 1962 in the Chicago area, attracting over 64,000 monthly visits to its online store. The catalog covers vitamins, supplements, organic foods, natural body care, and specialty health items — each with brand details, SKUs, and frequent sale pricing.
With Scrape.do you can track supplement pricing across brands like NOW Foods, Garden of Life, and Nature's Way, monitor sale rotations and discount patterns, build competitive pricing datasets for the natural health products market, and compare availability across niche supplement categories.
Cloudflare. Rate-Limited. Handled.
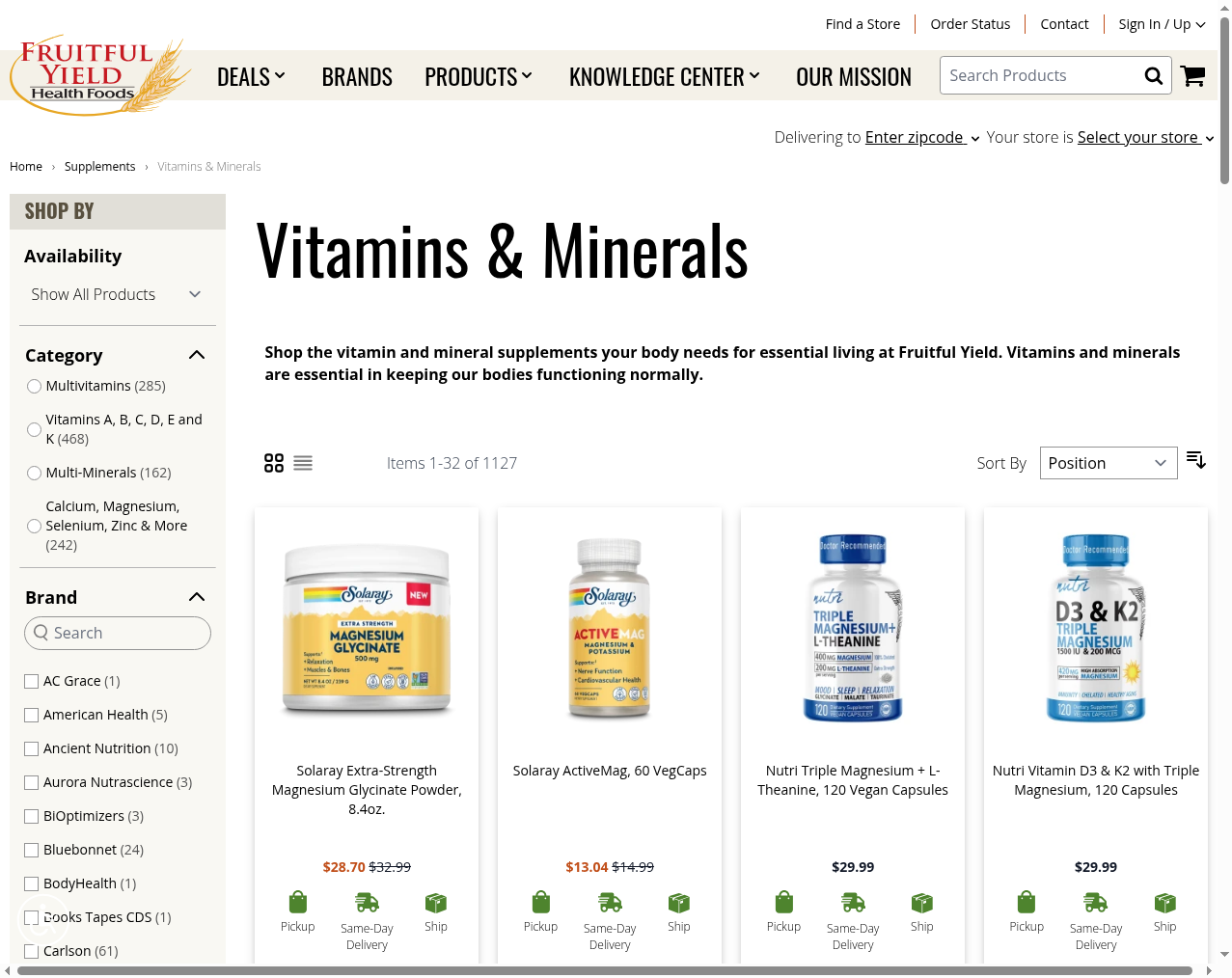
Fruitful Yield uses Cloudflare for bot management and DDoS protection, applying IP reputation checks and rate limiting to block automated scraping patterns. While individual requests succeed, sustained crawling triggers Cloudflare's challenge pages and temporary IP blocks.
Scrape.do handles Cloudflare's detection layers through automatic IP rotation and request pacing. Standard requests work without rendering or super proxy — you get full product HTML with pricing, brand info, and SKUs at just $1 per 1,000 requests.
How to Scrape Fruitful Yield
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
targetUrl = "https://www.fruitfulyield.com/vitamin-d-3-1000-iu-180-softgels.html"
render = "false" # set to "true" to enable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Vitamin D-3 1000 IU 180 Softgels | Fruitful Yield</title>
</head>
<body>
<div class="product-info-main">
<h1 class="page-title">Vitamin D-3 1000 IU 180 Softgels</h1>
</div>
<div class="product-info-price">
<span class="old-price">$12.99</span>
<span class="special-price">$9.74</span>
</div>
<div class="product-brand">
<span class="brand-label">Brand:</span>
<a class="brand-link">NOW Foods</a>
</div>
<div class="product-sku">
<span class="sku-label">SKU:</span>
<span class="sku-value">NOW-0372</span>
</div>
<div class="product-description">
<p>Structural Support. Vitamin D-3 1,000 IU Softgels for bone health and immune function.</p>
</div>
<div class="product-image">
<img src="https://www.fruitfulyield.com/media/catalog/...vitamin-d3.jpg" alt="Vitamin D-3">
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do automatically rotates IPs and manages request patterns to bypass Cloudflare's bot detection on Fruitful Yield. Standard mode works without render or super proxy, keeping costs minimal.
You can extract product names, regular and sale prices, brand names, SKUs, product descriptions, supplement facts, product images, and full category listings across vitamins, supplements, and organic products.
Yes. Fruitful Yield carries products from major supplement brands with frequent sale rotations. Scraping their catalog gives you niche pricing data for the natural health market that larger retailers often don't surface, including brand-specific discounts and regional availability.






