
Bath & Body Works Scraper
Scrape Products and Prices from Bath & Body Works
Extract product pricing, fragrance catalogs, and promotional deals from North America's largest specialty body care retailer. Bath & Body Works deploys PerimeterX bot protection with JavaScript rendering requirements that block standard scrapers. Scrape.do handles it automatically.
Start scraping today with 1000 free credits. No Credit Card Required
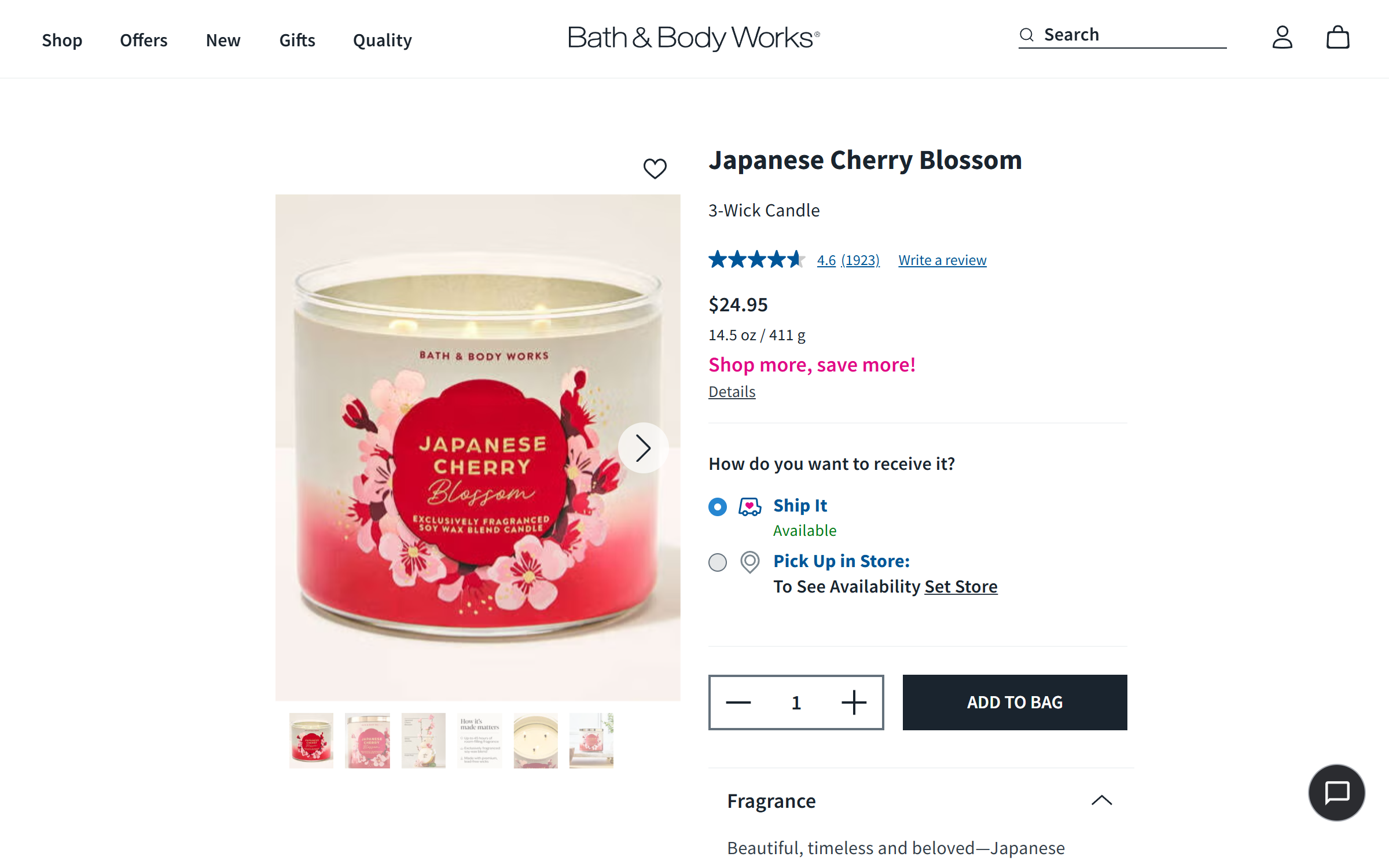
23M+ Monthly Visits. 150+ Fragrances. One API.
Bath & Body Works is the largest specialty retailer for body care and home fragrance in North America, pulling in over 23 million monthly visits to its ecommerce platform. The site catalogs thousands of products across body care, hand soaps, candles, and wallflowers, with frequent seasonal rotations and Semi-Annual Sale events that reshape the entire catalog.
With Scrape.do you can track pricing across product lines, monitor promotional discounts during flash sales, build fragrance availability datasets, and compare scent collections across categories. All data points from a single API call — no browser automation required.
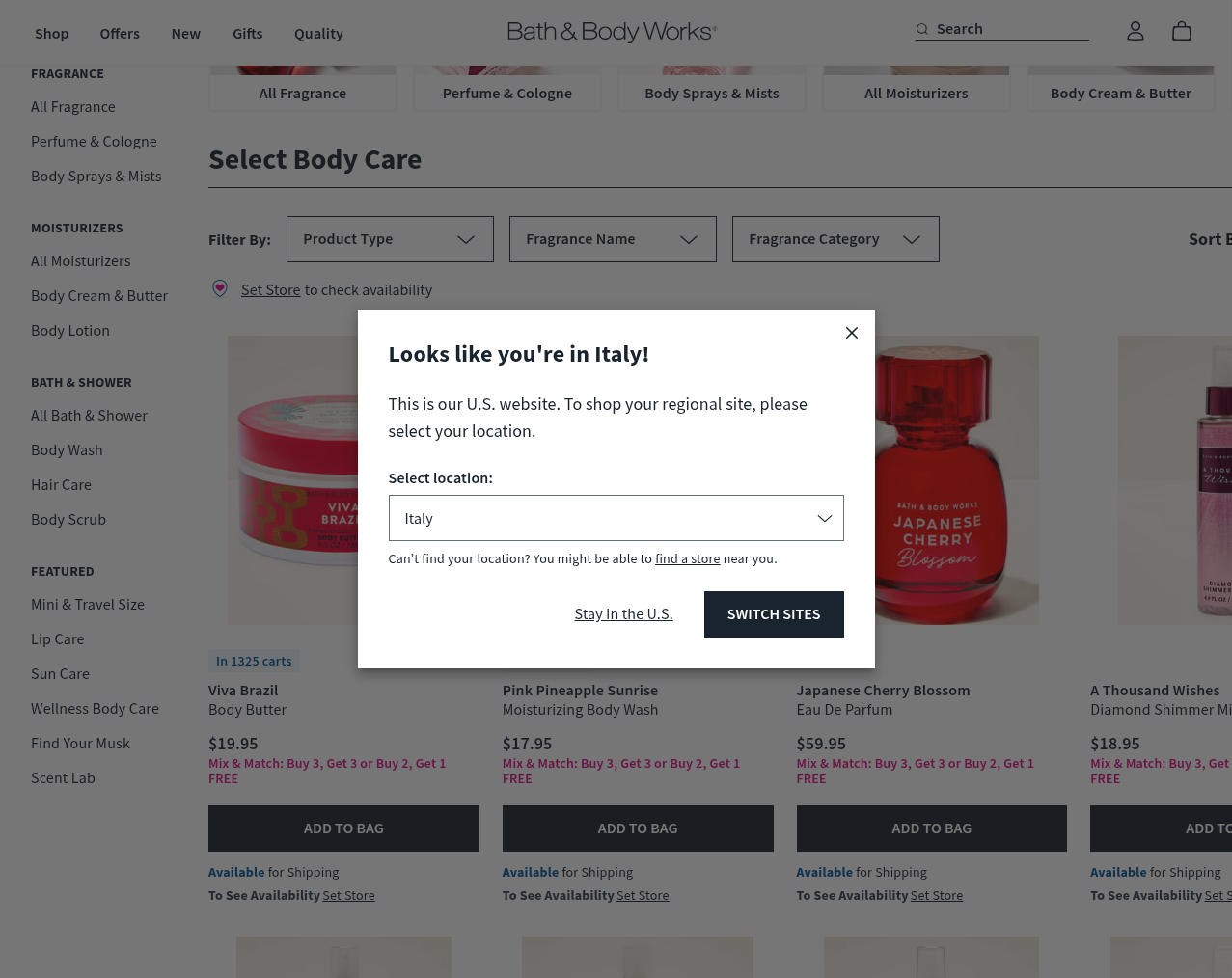
PerimeterX. JavaScript-Rendered. Handled.
Bath & Body Works uses PerimeterX as its bot management platform, deploying advanced browser fingerprinting and behavioral analysis to block automated access. The site also requires full JavaScript rendering — plain HTTP requests return a 502 error with no product data.
Scrape.do bypasses PerimeterX by using the render=true parameter to execute JavaScript in a real browser environment, combined with geoCode=us to route through US-based residential IPs. You get fully rendered product pages with pricing, sizes, and fragrance details without managing headless browsers or proxy pools.
How to Scrape Bath & Body Works, Inc.
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
targetUrl = "https://www.bathandbodyworks.com/p/japanese-cherry-blossom-single-wick-candle-028022703"
render = "true" # set to "false" to disable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
geoCode = "us"
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}&geoCode={geoCode}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Japanese Cherry Blossom Single Wick Candle | Bath & Body Works</title>
</head>
<body>
<div class="product-detail">
<h1 class="product-name">Japanese Cherry Blossom Single Wick Candle</h1>
</div>
<div class="product-price">
<span class="price-sales">$12.95</span>
<span class="price-standard">$16.95</span>
</div>
<div class="product-scent">
<span class="scent-label">Scent-Scription:</span>
<p>Japanese Cherry Blossom</p>
</div>
<div class="product-size">
<span class="size-value">7 oz / 198 g</span>
</div>
<div class="product-rating">
<span class="rating-value">4.6 out of 5</span>
<span class="review-count">2,341 reviews</span>
</div>
<div class="product-image">
<img src="https://www.bathandbodyworks.com/dw/image/...candle.jpg" alt="Japanese Cherry Blossom">
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do uses browser rendering with render=true and US-based residential proxies via geoCode=us to bypass PerimeterX's bot detection and JavaScript challenges. Success rates are consistently above 95%.
You can extract product names, regular and sale prices, fragrance descriptions (Scent-Scriptions), product sizes, customer ratings and reviews, product images, availability status, and category listings.
Bath & Body Works requires full JavaScript rendering to load product data. Standard HTTP requests without JS execution return a 502 from PerimeterX. Use Scrape.do with render=true to get a fully rendered page with all product details.






