Category:Scraping Basics
Building a Versatile Python Web Crawler from Scratch [2025 guide]

Software Engineer


Tried to run a fresh website crawl just to hit blocks on the second page?
Not as uncommon as you think.
In this guide, we'll build a web crawler from scratch. No frameworks, no shortcuts.
We’ll start by writing a simple Python script that sends a request, extracts links from a page, and follows them recursively.
Then we’ll level it up with real-world crawling features such as:
- concurrency,
- rate limiting,
- avoiding duplicate and dead URLs,
- logging,
- using
robots.txtfor ethical scraping, - and exporting results into structured formats like CSV.
We’ll use requests to fetch pages, BeautifulSoup to parse HTML, and (optionally) Scrape.do to bypass firewalls and CAPTCHAs when sites push back.
Find fully-functioning code here ⚙
Let's start with definitions:
What Is a Python Web Crawler?
A web crawler, sometimes called a spider or bot, is a script that visits web pages, follows their links, and collects content. At its core, a crawler starts with a list of URLs (often called a seed list), visits each one, finds links on the page, and repeats the process.
It can collect page titles, metadata, prices, article text, or anything else that's publicly available in the HTML.
Python is one of the best languages for building web crawlers because it has a clean syntax, strong libraries for HTTP and HTML parsing, and wide community support for scraping-related tools.
A Brief History
Web crawling started as a way to index the internet when early search engines like AltaVista and later Google sent out bots to discover and catalog pages, following links from one page to the next.
These crawlers were simple. The web was mostly static HTML, with few restrictions and almost no anti-bot systems.
That simplicity didn’t last.
As the web evolved, so did the challenges. Today, pages are built with JavaScript frameworks that render content only in the browser. Many sites are hidden behind login walls, use dynamic URLs, or load content via background AJAX calls.
And to protect themselves from scraping and abuse, sites now use:
- Bot detection systems like Cloudflare and DataDome
- Behavior analysis and TLS fingerprint checks
- CAPTCHA walls and aggressive IP blocking
- Geo-restrictions and rate-limiting based on traffic patterns
All of this means that requests.get() by itself is rarely enough. Modern crawlers need more than basic HTTP calls.
They need to mimic real browsers, rotate identities, respect site policies, and recover from failures automatically.
That's why we’re building something smarter in this guide.
Is Web Crawling Legal in 2026?
Yes, crawling is legal, as long as you follow the rules. The key is to stick to publicly available, non-authenticated pages and respect the limitations defined by the site’s robots.txt file.
This file is a standard way for websites to tell crawlers what’s allowed and what isn’t. Ignoring it might not be illegal in most situations, but it is bad practice and it increases your chances of getting blocked.
What’s off-limits?
- Pages behind logins (e.g., user dashboards, private messages)
- Pages clearly disallowed in
robots.txt - Content that violates terms of service (like excessive pricing data from certain marketplaces)
It’s also important to scrape responsibly, don’t overload a server with rapid-fire requests or endless crawling.
If you're unsure, check the site’s robots.txt, and refer to our guide on web scraping legality for deeper insight.
In short: don’t scrape what you wouldn’t browse manually.
Building a Basic Web Crawler in Python
Let’s start with the simplest version of a crawler: one that visits a URL, collects all the links on the page, and then follows each of those links, repeating the process.
We won’t worry about rate limiting, proxy rotation, or robots.txt just yet. The goal is to understand the core mechanics.
Prerequisites
Make sure you have Python 3 installed, along with these libraries:
pip install requests beautifulsoup4We’ll use:
requeststo make HTTP callsBeautifulSoupto parse HTML and extract links
Also, create a new Python file (e.g., basic_crawler.py) to follow along.
Writing the Crawler
We’ll build this in steps.
1. Sending the First Request
Let’s write a function that fetches the HTML of a page.
import requests
def fetch(url):
try:
response = requests.get(url, timeout=5, headers={"User-Agent": "MyCrawler"})
if response.status_code == 200:
content_type = response.headers.get("Content-Type", "")
if "text/html" in content_type:
return response.text
except requests.RequestException:
pass
return ""2. Extracting Links from the Page
Now, we’ll extract all the links using BeautifulSoup.
By default, a crawler will follow every link it finds, including external domains. But unless you’re intentionally crawling the wider web, that’s rarely what you want.
We’ll setup our crawler to only follow links that match the original domain.
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def extract_links(html, base_url):
soup = BeautifulSoup(html, "html.parser")
base_parsed = urlparse(base_url)
base_domain = ".".join(base_parsed.netloc.split(".")[-2:]) # wikipedia.org
links = set()
for tag in soup.find_all("a", href=True):
href = tag["href"]
absolute = urljoin(base_url, href)
parsed = urlparse(absolute)
# Allow all subdomains under the base domain (like *.wikipedia.org)
if parsed.netloc.endswith(base_domain) and absolute.startswith("http"):
links.add(absolute)
return links3. Skipping Non-HTML Links
Not every link on a page is meant to be crawled.
Web pages often contain links to files like PDFs, images, videos, and sitemaps (e.g. .xml, .jpg, .pdf, .zip, etc.). These aren't useful for a typical crawler and trying to parse them like HTML will either fail silently or waste resources.
We will add a safeguard that skips any URL ending in common file extensions:
def should_skip_url(url):
skip_extensions = (
".xml", ".json", ".pdf", ".jpg", ".jpeg", ".png", ".gif",
".svg", ".zip", ".rar", ".mp4", ".mp3", ".ico"
)
return url.lower().endswith(skip_extensions)Then, before visiting any link, we check:
if (url in visited or should_skip_url(url)):
continueThis, combined with checking the page’s Content-Type header, ensures your crawler only processes real HTML pages and avoids XML parsing errors or crawling unwanted binary files.
4. Following New Links Automatically
A web crawler isn’t very useful if it only visits one page.
The core of crawling is link discovery; visit a page, extract its links, then visit those links and repeat the process. This creates a recursive structure that simulates how search engines explore the web.
To manage this, we use a queue for the pages we plan to visit, and a visited set to keep track of where we’ve already been. Without these controls, the crawler could easily:
- Visit the same page over and over
- Loop endlessly through internal links
- Hit dynamic filters or calendars that generate infinite URLs
We also add a max_pages limit to stay in control. This is especially useful when testing a new domain or structure you don’t fully understand. It lets you watch the crawler behave without it spiraling out of control.
Here’s what that logic looks like in code:
from collections import deque
def crawl(seed_url, max_pages=10):
visited = set()
queue = deque([seed_url])
while queue and len(visited) < max_pages:
url = queue.popleft()
if url in visited or should_skip_url(url):
continue
print(f"Crawling: {url}")
html = fetch(url)
if not html:
continue
links = extract_links(html, url)
queue.extend(links - visited)
visited.add(url)5. Sample Output
Let’s try running our crawler on Wikipedia, one of the most link-rich and well-structured websites on the internet. It’s a great place to test link extraction, especially across language subdomains.
crawl("https://en.wikipedia.org/", max_pages=10)You should see your crawler printing out each visited URL, including ones like:
https://en.wikipedia.org/wiki/Main_Pagehttps://lij.wikipedia.org/wiki/Pagina_principalehttps://de.wikipedia.org/wiki/Wikipedia:Hauptseite
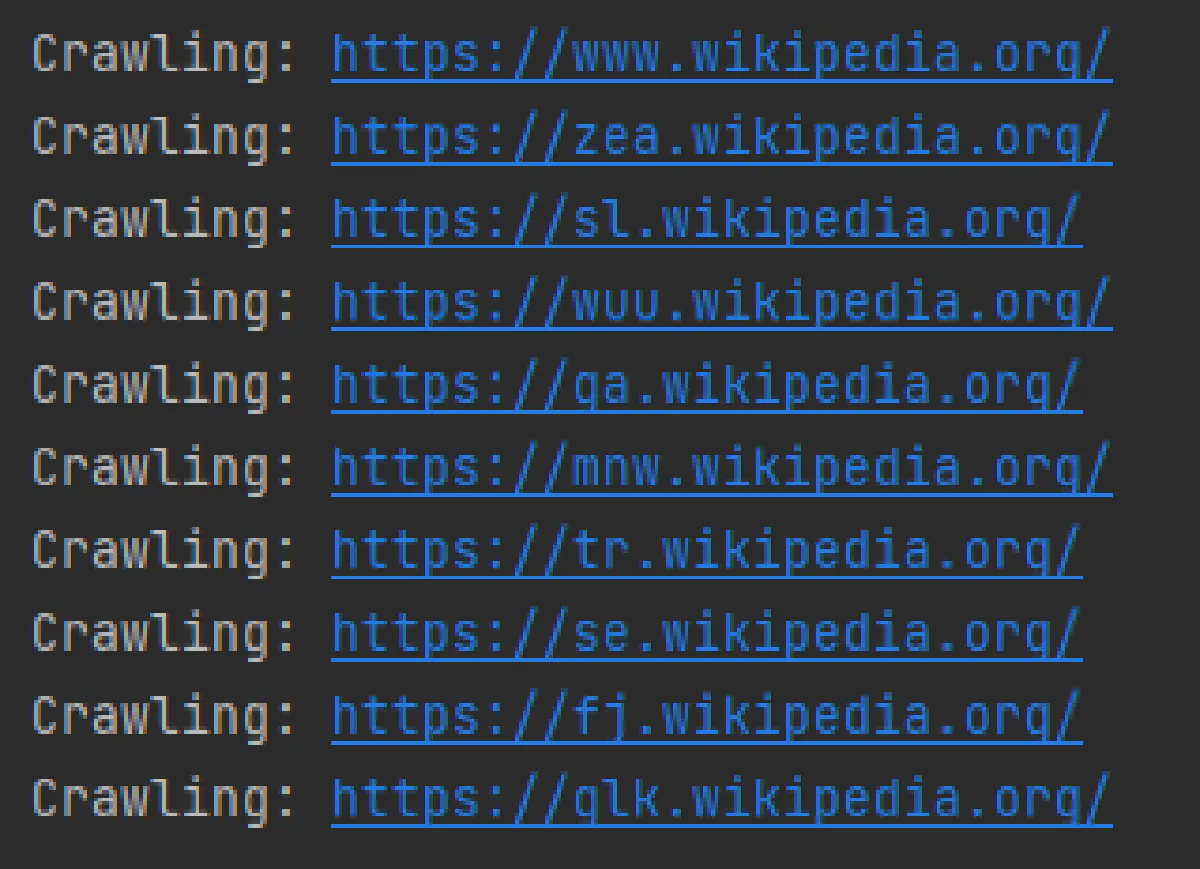
This confirms that your crawler is correctly extracting and following links across subdomains.
Test and Export Results
Now that our crawler is fetching and following links correctly, let’s make it do something more useful: record the pages it visits.
We’ll store the final list of visited URLs in a CSV file. That way, you can inspect the results, import them elsewhere, or use them as input for another scraper.
Here’s how to add CSV exporting to the bottom of our crawl() function:
import csv
def crawl(seed_url, max_pages=10):
visited = set()
queue = deque([seed_url])
while queue and len(visited) < max_pages:
url = queue.popleft()
if (url in visited or should_skip_url(url)):
continue
print(f"Crawling: {url}")
html = fetch(url)
if not html:
continue
links = extract_links(html, url)
queue.extend(links - visited)
visited.add(url)
# Export visited URLs to CSV
with open("crawled_urls.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["URL"])
for url in visited:
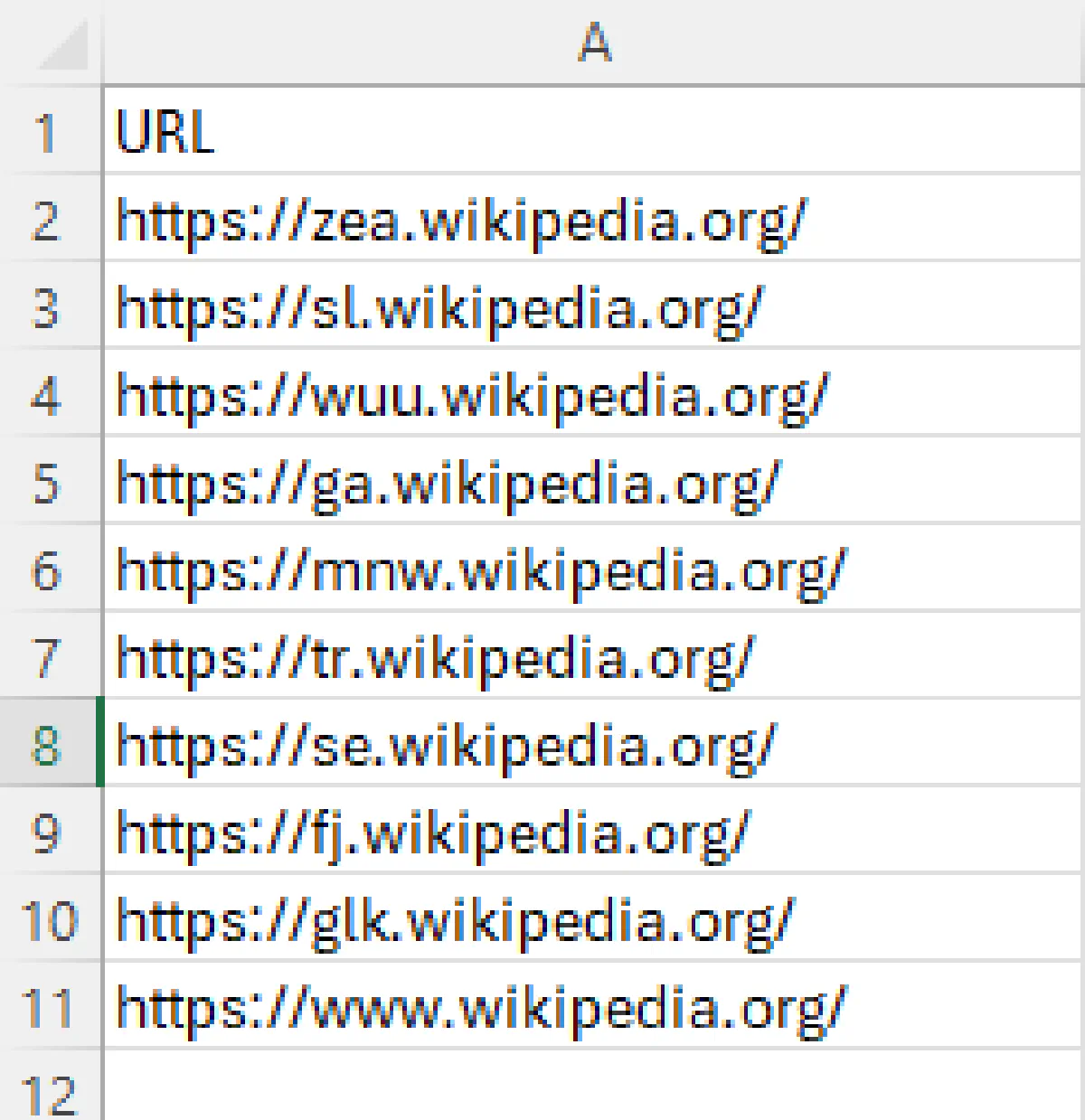
writer.writerow([url])After running the crawler, you should see a file named crawled_urls.csv in your directory.
Here's what your CSV output should look like:
Now that we’ve got a basic working crawler, let’s talk about crawling responsibly by reading and respecting robots.txt.
Ethical Crawling: Reading and Applying robots.txt
Before you crawl any website, it’s good practice to check what you’re actually allowed to crawl.
The robots.txt file, located at the root of most websites (e.g. https://example.com/robots.txt), tells crawlers which parts of a site are open for automated access and which are off-limits.
Ignoring it won’t get you sued in most cases, but it can get your crawler IP-banned or worse, flagged as abusive.
And in some industries, that line does carry legal weight.
Let’s see how to load and follow the rules in Python.
Step 1: Fetch and Parse robots.txt
We’ll use Python’s built-in urllib.robotparser module, it’s lightweight and does the job.
import urllib.robotparser
def is_allowed(url, user_agent="MyCrawler", fallback=True):
rp = urllib.robotparser.RobotFileParser()
parsed = urlparse(url)
robots_url = f"{parsed.scheme}://{parsed.netloc}/robots.txt"
try:
rp.set_url(robots_url)
rp.read()
return rp.can_fetch(user_agent, url)
except:
print(f"[robots.txt not accessible] Proceeding with: {url}")
return fallbackStep 2: Integrate with Our Crawler
We’ll call is_allowed() before making a request to any URL:
def crawl(seed_url, max_pages=10):
visited = set()
queue = deque([seed_url])
user_agent = "MyCrawler"
while queue and len(visited) < max_pages:
url = queue.popleft()
if (
url in visited or
should_skip_url(url) or
not is_allowed(url, user_agent)
):
continue
print(f"Crawling: {url}")
html = fetch(url)
if not html:
continue
links = extract_links(html, url)
queue.extend(links - visited)
visited.add(url)
# Export visited URLs to CSV
with open("crawled_urls.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["URL"])
for url in visited:
writer.writerow([url])Now your crawler is ethical and much less likely to get blocked.
Adding Advanced Functions to Your Python Crawler
At this point, you’ve got a working, ethical crawler. It follows links, respects robots.txt, and exports results.
But it’s still basic, slow, single-threaded, and unprepared for real-world obstacles like failed requests or large sitemaps.
Now we’ll add features that make your crawler faster, safer, and more reliable:
- Multithreading for performance
- Throttling to avoid being flagged
- Header and proxy rotation to reduce blocking
- Retry logic for bad requests
- Logging to track progress
- URL filtering to stay focused
- HTML download for archiving
Each of these will be introduced step-by-step, with short explanations, real Python code, and practical output.
Add Multithreading / Concurrency
The default version of our crawler visits one page at a time, fine for 10 pages, but painful at scale. We’ll add multithreading using concurrent.futures.ThreadPoolExecutor, which lets us crawl several pages in parallel without rewriting everything into asyncio.
Updated Approach
We’ll break crawling into two parts:
- A worker function that fetches and processes one URL.
- A thread pool that runs multiple workers in parallel.
Here’s a simple threaded version of our crawl() function:
from concurrent.futures import ThreadPoolExecutor
def threaded_crawl(seed_url, max_pages=50, max_workers=5):
visited = set()
queue = deque([seed_url])
user_agent = "MyCrawler"
def worker(url):
if (
url in visited or
should_skip_url(url) or
not is_allowed(url)
):
return []
print(f"Crawling: {url}")
html = fetch(url)
if not html:
return []
visited.add(url)
return extract_links(html, url)
with ThreadPoolExecutor(max_workers=max_workers) as executor:
while queue and len(visited) < max_pages:
batch = []
while queue and len(batch) < max_workers:
batch.append(queue.popleft())
futures = [executor.submit(worker, url) for url in batch]
for future in futures:
try:
links = future.result()
queue.extend(link for link in links if link not in visited)
except:
continue
# Export results
with open("crawled_urls.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["URL"])
for url in visited:
writer.writerow([url])We can run our threaded crawler as follows:
threaded_crawl("https://www.wikipedia.org/", max_pages=20, max_workers=5)Your crawler is now significantly faster and still respects ethics and structure. You can adjust number of workers you want to use, as per our example we have used 5 threads in parallel.
Add Rate Limiting and Throttling
If your crawler hits a website too quickly even politely and ethically you risk being flagged as a bot or triggering automated blocks. Web servers expect human-like timing: a few seconds between actions, not a barrage of requests per second.
To fix this, we’ll add two things:
- A delay between requests, using
time.sleep() - A randomized backoff range, so our pattern isn’t predictable
Add This to the Worker Function
Update the worker() inside threaded_crawl() like this:
import time
import random
def worker(url):
if (
url in visited or
should_skip_url(url) or
not is_allowed(url)
):
return []
print(f"Crawling: {url}")
html = fetch(url)
# Random delay to avoid aggressive crawling
time.sleep(random.uniform(1.5, 3.5))
if not html:
return []
visited.add(url)
return extract_links(html, url)This adds a 1.5–3.5 second random pause after each request, mimicking natural human delay.
Optional: Make It Configurable
You can replace the hardcoded values with a global or parameter:
def threaded_crawl(seed_url, max_pages=50, max_workers=5, delay_range=(1.5, 3.5)):
...
def worker(url):
...
time.sleep(random.uniform(*delay_range))This way, you can pass different throttle levels depending on the site or your testing needs.
Rotating Headers, User Agents, and Proxies
If you’re crawling more than a few pages especially from dynamic or well-defended sites you’ll eventually run into blocks. Even if your requests are respectful, websites can detect:
- Too many hits from the same IP
- Repetitive User-Agent strings
- Headers that don’t match real browser behavior
To avoid this, we rotate:
- User-Agents to simulate different browsers
- Headers to mimic real-world requests
- Proxies to distribute traffic across IPs
User-Agent Pool
Start with a basic pool of common desktop and mobile User-Agent strings:
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/114.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Version/15.4 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) Gecko/20100101 Firefox/113.0",
"Mozilla/5.0 (iPhone; CPU iPhone OS 16_0 like Mac OS X) AppleWebKit/605.1.15 Mobile/15E148 Safari/604.1"
]Optional: Proxy Rotation
You could rotate proxies manually, like this:
PROXIES = [
"http://proxy1.example.com:8080",
"http://proxy2.example.com:8000",
# ...
]But here's the reality: Free public proxies are slow, unreliable, and often blocked.
If you’re building something for production, you’ll need access to:
- Residential or mobile IPs
- Global geotargeting
- Session persistence
- Real-time IP rotation
We’ll show how to do this properly using Scrape.do’s Web Scraping API later in the guide.
For now, we’ll show where the proxy code would go but leave it commented out:
Updated fetch() Function with Rotation Logic
def fetch(url):
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive"
}
# Placeholder for proxy rotation (e.g., paid proxy service or Scrape.do)
# proxies = {"http": random.choice(PROXIES), "https": random.choice(PROXIES)}
try:
response = requests.get(
url,
timeout=5,
headers=headers,
# proxies=proxies
)
if response.status_code == 200:
content_type = response.headers.get("Content-Type", "")
if "html" in content_type:
return response.text
except requests.RequestException:
pass
return ""Add Error Handling and Retry Logic
Even when you're crawling correctly, network requests can fail; timeouts, server errors, random connection drops. Without proper handling, a single failed request can slow or break your crawl.
Instead of silently skipping failures, we’ll:
- Catch and log exceptions
- Retry failed requests a limited number of times
- Back off slightly between retries
Step 1: Add Retry to fetch()
We'll add a retry loop around requests.get() with a delay between attempts:
def fetch(url, max_retries=3):
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive"
}
# Uncomment if using proxies
# proxies = {"http": random.choice(PROXIES), "https": random.choice(PROXIES)}
for attempt in range(max_retries):
try:
response = requests.get(
url,
timeout=5,
headers=headers,
# proxies=proxies
)
if response.status_code == 200:
content_type = response.headers.get("Content-Type", "")
if "html" in content_type:
return response.text
break # stop retrying on non-200 status
except requests.RequestException as e:
print(f"[retry {attempt+1}] Error fetching {url}: {e}")
time.sleep(1.5 + attempt * 1.0) # increasing backoff
return ""💡 This tells the crawler to wait up to 3 times before moving on and wait between trials, adding more wait time after each fail.
Ignore Certain Paths and Subdomains
Even within a single domain, there can be pages you don’t want to crawl:
- Login pages (
/login,/admin) - Search URLs with
?q=that generate infinite combinations - Subdomains like
blog.example.comthat aren’t part of the main site
We'll add two filters:
- Ignore certain paths
- Stick to the original subdomain only (if desired)
Step 1: Define Ignore Lists
We’ll define two new variables:
EXCLUDED_PATHS = ["/login", "/admin", "/signup", "/cart", "/checkout"]
EXCLUDED_QUERY_PARAMS = ["?q=", "?search=", "?filter="]Step 2: Update the Link Filtering Logic
Modify extract_links() to skip any link that matches an unwanted path or query:
def extract_links(html, base_url):
soup = BeautifulSoup(html, "html.parser")
base_parsed = urlparse(base_url)
base_domain = base_parsed.netloc
base_subdomain = base_domain.split(".")[-2:]
links = set()
for tag in soup.find_all("a", href=True):
href = tag["href"]
absolute = urljoin(base_url, href)
parsed = urlparse(absolute)
# Same domain check
if parsed.netloc != base_domain:
continue
# Skip excluded paths
if any(path in parsed.path for path in EXCLUDED_PATHS):
continue
# Skip unwanted query params
if any(q in parsed.query for q in EXCLUDED_QUERY_PARAMS):
continue
# Optional: skip subdomains that aren’t a match
if parsed.netloc.split(".")[-2:] != base_subdomain:
continue
if absolute.startswith("http"):
links.add(absolute)
return linksOnce this is added, the crawler:
- Ignores login, checkout, and admin pages
- Skips search/filter loops
- Stays on the same subdomain by default
Add Logging and Monitoring
Right now your crawler prints to the console. That works early on, but it's not enough if you're:
- Running long crawls
- Debugging failures
- Keeping crawl history
- Deploying to a server or scheduler
Instead of using print(), we’ll use Python’s built-in logging module.
Step 1: Setup Basic Logging
Add this near the top of your script:
import logging
logging.basicConfig(
filename="crawler.log",
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s"
)This will:
- Save logs to
crawler.log - Include timestamps
- Separate info and error messages
Step 2: Replace print() with Logs
In the worker() function, replace:
print(f"Crawling: {url}")With:
logging.info(f"Crawling: {url}")And in fetch(), update this:
print(f"[retry {attempt + 1}] Error fetching {url}: {e}")To:
logging.warning(f"[retry {attempt + 1}] Error fetching {url}: {e}")Now in the output, you'll also see:
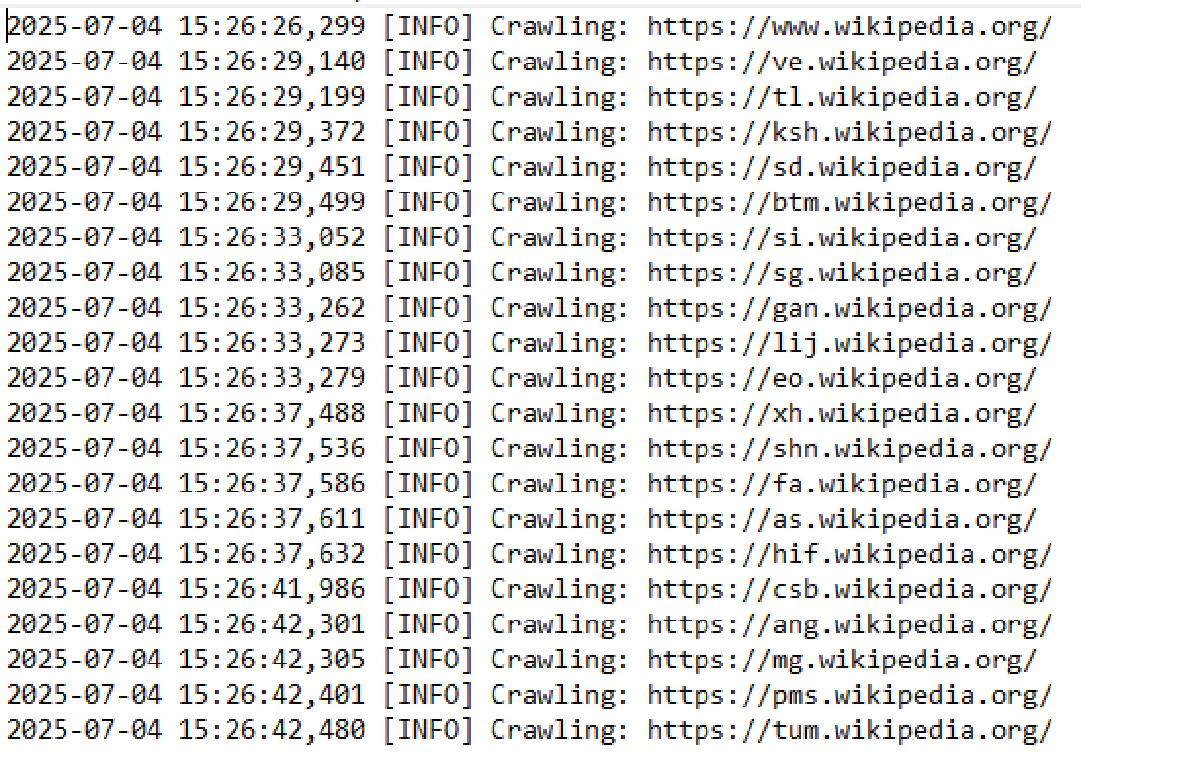
A persistent, timestamped log of your crawler's activity, necessary for debugging and monitoring.
Download Crawled Pages
Sometimes you want to archive what your crawler finds. Maybe you need to analyze it offline, audit changes over time, or use the HTML later in a separate parser.
We’ll modify the crawler so that after successfully fetching a page, it saves the HTML to disk.
Step 1: Create a Slug from Each URL
Since URLs can contain characters that don’t work in filenames, we’ll generate safe filenames from them using hashing:
import hashlib
import os
def save_page(html, url, folder="pages"):
os.makedirs(folder, exist_ok=True)
file_id = hashlib.md5(url.encode()).hexdigest()
filepath = os.path.join(folder, f"{file_id}.html")
with open(filepath, "w", encoding="utf-8") as f:
f.write(html)This function:
- Creates a
pages/folder if it doesn’t exist - Hashes the URL to generate a consistent, unique filename
- Saves the raw HTML into a
.htmlfile
Step 2: Call This from the Worker
Inside the worker() function, right after a successful fetch(), add:
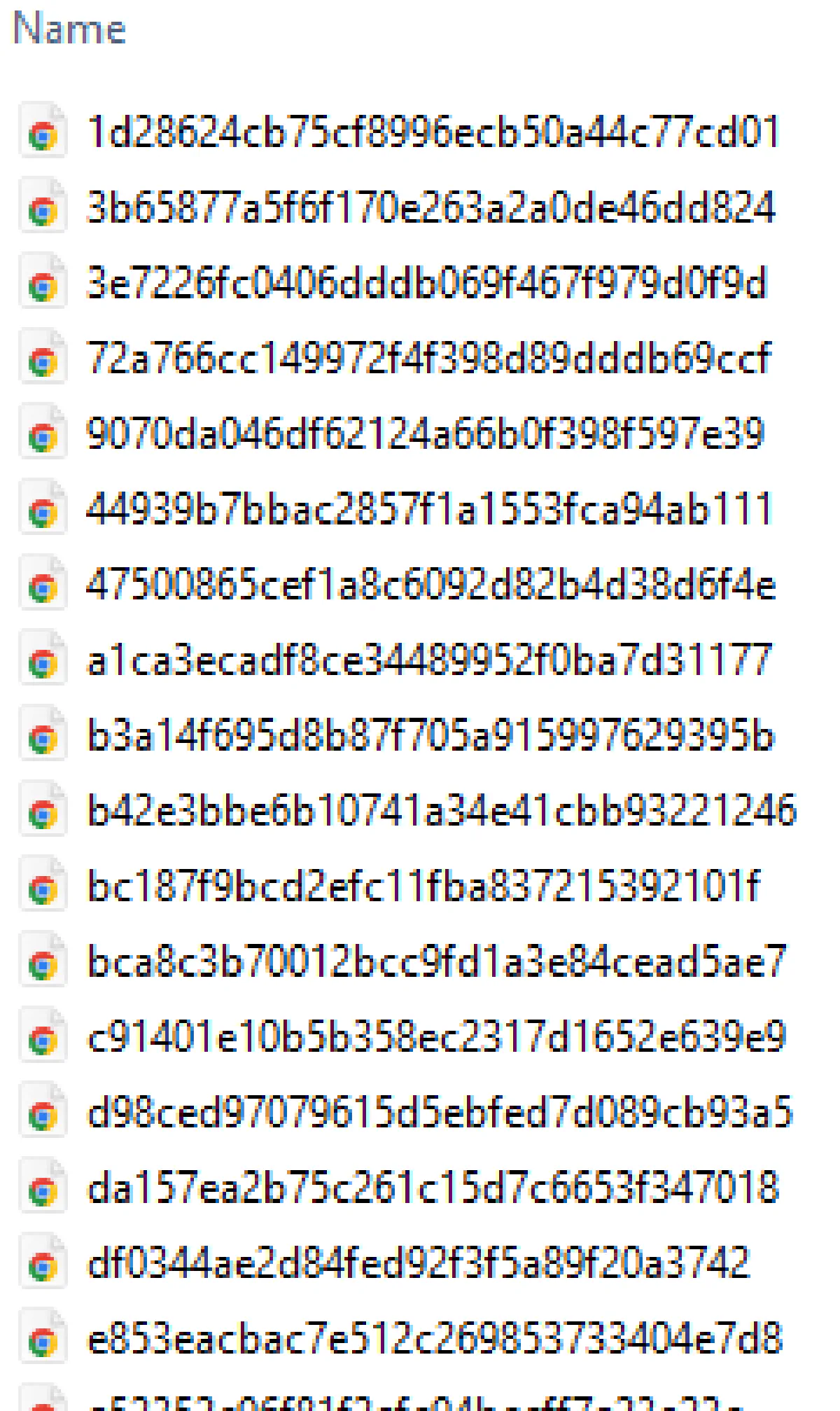
save_page(html, url)This will store every successfully crawled page, with the filename based on its MD5 hash.
Result
You now have a local copy of every page your crawler visits. These can be used for parsing, comparison, or debugging later.
Python Crawling Tools
At this point, you’ve built a capable crawler using only core Python libraries. But depending on your project goals, you may want to take advantage of more advanced tooling. These tools can help you scale faster, handle dynamic content, and bypass protection mechanisms more effectively.
Crawling Framework for Python: Scrapy
Scrapy is one of the most mature and widely used frameworks for web crawling in Python. It's ideal for building complex crawlers that need to process structured data, manage large queues, or support plugins.
Why Scrapy is useful:
- Comes with built-in request handling, auto-throttling, and caching
- Supports output to JSON, CSV, or databases out of the box
- Handles retries, redirects, and proxies through middleware
Scrapy is especially valuable if you’re running multiple crawlers or managing scheduled, production-grade scraping jobs.
Headless Browsers for JavaScript Rendering
Some websites don’t expose their content until after JavaScript runs. For those cases, tools like Selenium and Playwright can load and render pages like a real browser.
Recommended options:
- Selenium lets you automate real browser sessions and interact with forms, dropdowns, and buttons
- Playwright is newer, fast, and supports multiple browsers with better isolation and speed
- Pyppeteer is a Python adaptation of Puppeteer, optimized for controlling Chromium
These are especially helpful when the data is not present in the initial HTML or when dealing with login forms and popups.
Scrape.do: Web Scraping API for Unblocked Access
Everything you've built so far works well for open, lightly protected sites.
But the moment you try crawling a site with rate limits, JavaScript rendering, or WAFs like Cloudflare, you’ll hit a wall.
Scrape.do solves that with a single API call.
You don’t need to install anything. Just pass your target URL through Scrape.do and get back the clean HTML.
Step 1: Get Your API Token
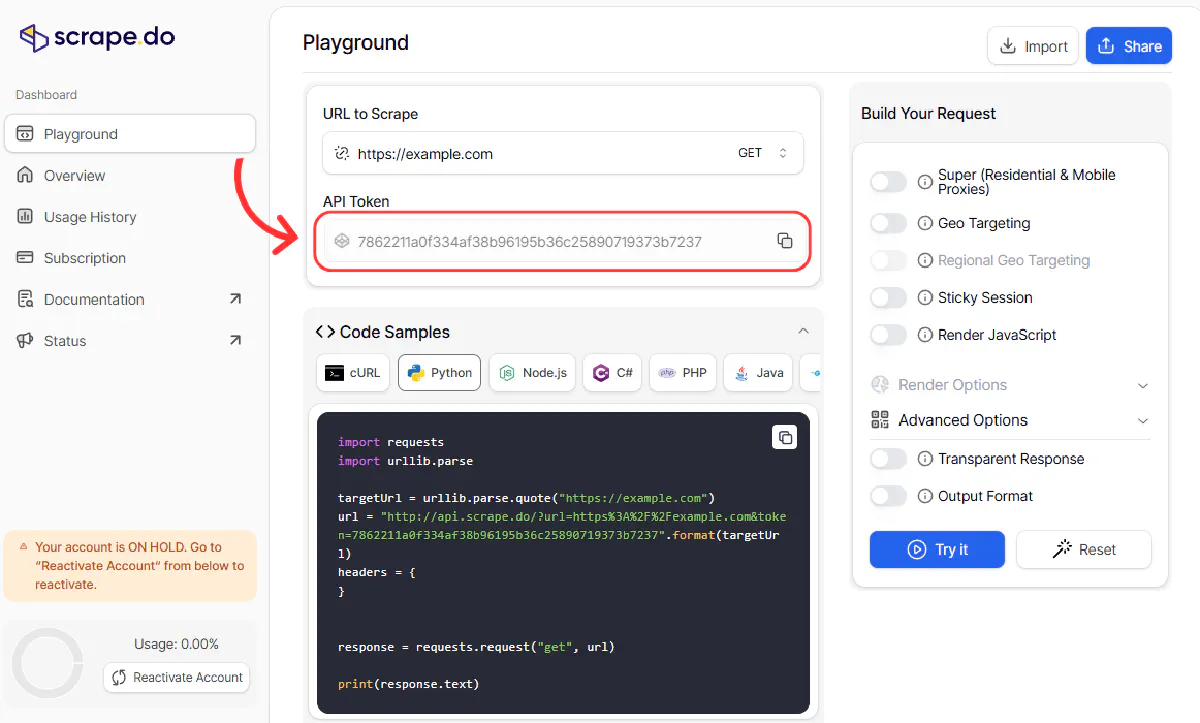
First, sign up at Scrape.do and get your API token. The free plan gives you 1,000 requests per month.
Step 2: Replace Your fetch() Function
Instead of building headers, rotating proxies, and retrying manually, just send a single request to Scrape.do:
def fetch(url, token, render=False):
base = "https://api.scrape.do"
payload = {
"token": token,
"url": url,
}
if render:
payload["render"] = "true"
try:
response = requests.get(base, params=payload, timeout=10)
if response.status_code == 200:
return response.text
except requests.RequestException as e:
logging.warning(f"Scrape.do fetch failed: {e}")
return ""You can now call this in your worker like so:
html = fetch(url, token="your_token_here")Optional: pass
render=Trueif the target site requires JavaScript rendering.
Step 3: Drop the Complexity
Once Scrape.do is in place, you no longer need:
- Proxy rotation logic
- Header randomization
- Manual retry loops
- CAPTCHA detection or solving
It’s all handled on the Scrape.do side while you act on the data you've just collected.
Wrapping Up
Your crawler now handles everything from link traversal and rate limiting to avoiding dead ends and archiving pages.
And with Scrape.do, you’ve seen how easy it is to bypass the messy parts, like IP blocks, CAPTCHAs, and fingerprinting without writing extra logic.
With Scrape.do, you get:
- High success rates, even on protected targets
- IP rotation and proxy management baked in
- Real-time support from technical engineers
- 1000 free requests per month to try it out
Software Engineer








