Category:Scraping Use Cases
Reddit Scraping with Python: Posts, Comments, and Search Results

Full Stack Developer



Reddit is one of the biggest sources of user-generated content on the internet, with millions of posts and comments organized across thousands of active subreddits.
If you've ever tried scraping Reddit programmatically, you probably reached for the official API through PRAW. It works, but it requires OAuth setup, enforces strict rate limits, and caps the data you can pull per request.
There's a faster way.
Reddit's internal web endpoints (the same ones the site uses to load content in your browser) return structured HTML that you can parse directly with BeautifulSoup. No API keys, no OAuth tokens, no rate limit headers to manage.
The catch is Reddit's anti-bot protection, which silently blocks automated requests without returning an error. We'll handle that with Scrape.do and build three complete scrapers: one for subreddit posts, one for search results, and one for comments.
[Plug-and-play codes on our GitHub repo]
How Reddit Blocks Scrapers
Reddit has two layers of bot protection. The first is a reCAPTCHA challenge page that asks you to "Prove your humanity." If your request looks automated enough, Reddit won't even serve the page content.
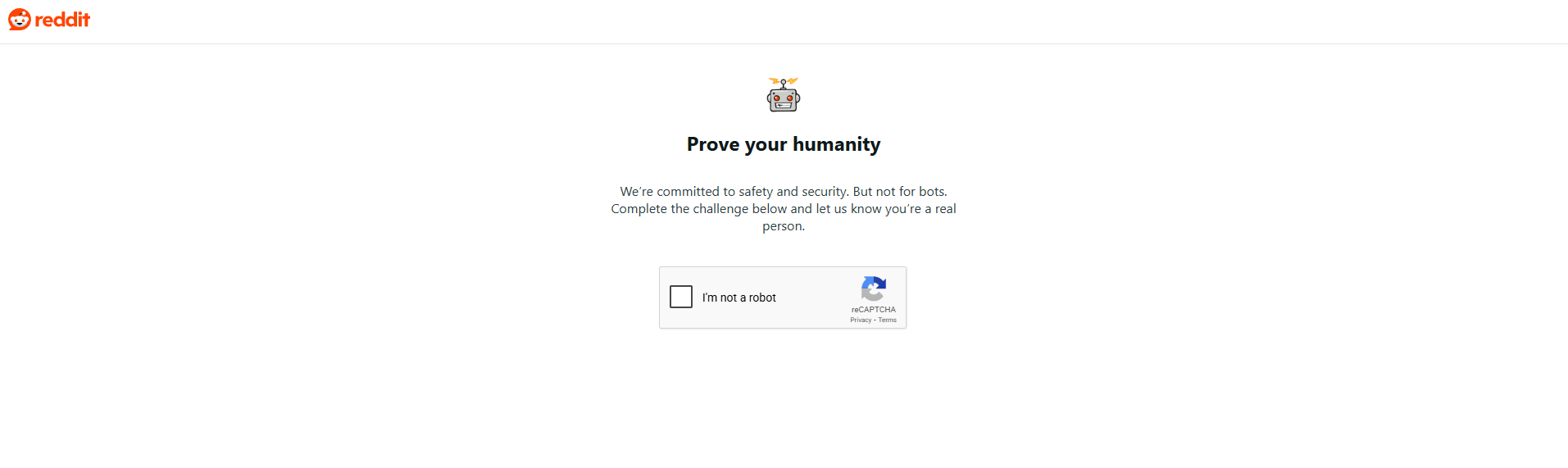
The second layer is subtler. Even when you get past the CAPTCHA (or it doesn't trigger), Reddit returns a 200 status code with a stripped-down version of the page. A subreddit that normally shows 25 posts per page will only return 3. Search pages come back empty. Your script reports success, but the data is gutted.
This second block is harder to catch. The status code says 200, the HTML has valid structure, and your parser runs without errors. You only notice something is wrong when you open the CSV and find 3 rows instead of 25.
Here's a direct request to Reddit for the r/fishing subreddit:
response = requests.get("https://www.reddit.com/r/fishing/new/")
soup = BeautifulSoup(response.text, "html.parser")
posts = soup.find_all("shreddit-post")
print(f"Status: {response.status_code}") # 200
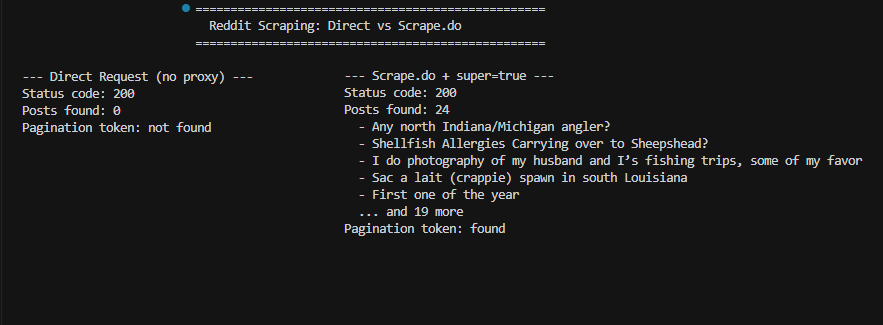
print(f"Posts found: {len(posts)}") # 3Status 200, but only 3 posts. The same page in a browser shows 25+. Reddit detected the automated request and served a limited response.
Routing the request through Scrape.do with super=true handles both the CAPTCHA and the soft block:
target = "https://www.reddit.com/svc/shreddit/community-more-posts/new/?name=fishing"
api_url = f"http://api.scrape.do?token={token}&url={quote(target)}&super=true"
response = requests.get(api_url)
posts = soup.find_all("shreddit-post")
print(f"Posts found: {len(posts)}") # 2424 posts, full pagination tokens, all the data intact. The super=true parameter activates premium residential proxies that bypass both Reddit's CAPTCHA and its soft blocking. One thing worth noting: you don't need render=true (JavaScript rendering) for Reddit. All the data we need is in the initial HTML response, so we can skip the slower JS rendering and keep requests fast.
Scraping Subreddit Posts
Reddit doesn't serve subreddit posts from the main page HTML the way you'd expect. Instead, it uses an internal API endpoint called Shreddit:
/svc/shreddit/community-more-posts/{sort}/This endpoint takes the subreddit name as a parameter and returns a full HTML page containing <shreddit-post> custom elements. Each element has clean attributes for every piece of data we need, so there's no digging through nested divs or fragile CSS selectors.
Prerequisites
You'll need Python 3.x with three libraries:
pip install requests beautifulsoup4You'll also need a Scrape.do account. Grab your API token from the dashboard and replace <your_token> in the scripts below.
Configuration and URL Setup
The script starts with the Scrape.do token, target subreddit, and sort configuration:
import requests
from urllib.parse import quote
from bs4 import BeautifulSoup
import csv
import re
token = "<your_token>"
subreddit = "fishing"
# Sort options: "new", "hot", "top", "rising"
sort = "new"
# Time filter (only applies when sort="top"):
# "hour", "day", "week", "month", "year", "all"
time_filter = "month"
max_pages = 3
target_base = f"https://www.reddit.com/svc/shreddit/community-more-posts/{sort}/"
params = f"name={subreddit}"
if sort == "top":
params += f"&t={time_filter}"Four sort options are available: new, hot, top, and rising. The time filter (t=) only applies when sorting by top, letting you narrow results to the last hour, day, week, month, year, or all time. The quote() function from urllib.parse handles URL encoding when we pass the full target URL to Scrape.do's API.
Parsing and Extracting Post Data
For each page, we send the request through Scrape.do and parse the response with BeautifulSoup:
all_posts = []
for page in range(max_pages):
target_url = f"{target_base}?{params}"
api_url = f"http://api.scrape.do?token={token}&url={quote(target_url)}&super=true"
response = requests.get(api_url)
if response.status_code != 200:
print(f"Page {page + 1} failed: {response.status_code}")
break
soup = BeautifulSoup(response.text, "html.parser")
posts = soup.find_all("shreddit-post")
if not posts:
print(f"No more posts found on page {page + 1}")
break
for post in posts:
all_posts.append({
"title": post.get("post-title", ""),
"author": post.get("author", ""),
"score": post.get("score", ""),
"comments": post.get("comment-count", ""),
"timestamp": post.get("created-timestamp", ""),
"permalink": "https://www.reddit.com" + post.get("permalink", ""),
})
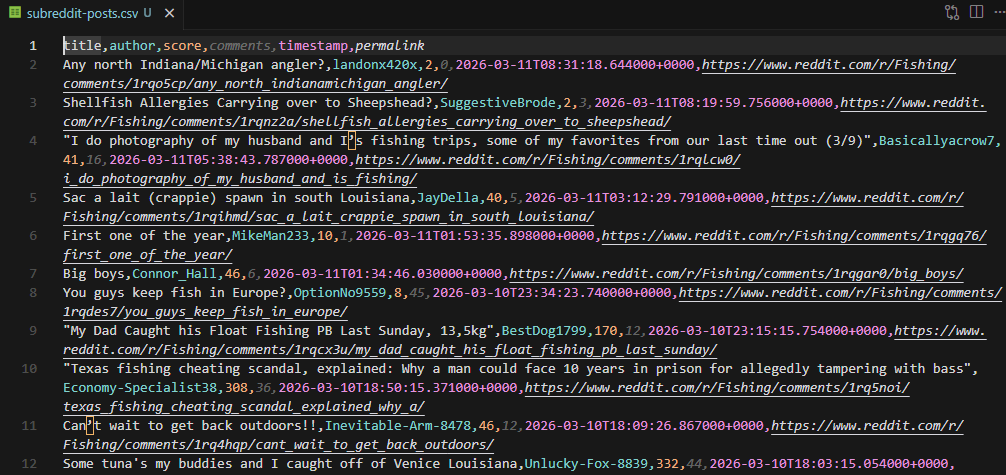
print(f"Page {page + 1}: {len(posts)} posts")The shreddit-post elements store everything as HTML attributes: post-title, author, score, comment-count, created-timestamp, and permalink. This is much cleaner than scraping traditional HTML where data is buried inside nested elements. Each page returns around 25 posts.
Paginating Through Subreddit Posts
One page gives you ~25 posts. To get more, you need the pagination token that Reddit embeds in the response HTML:
after_match = re.search(r'after=([^&"\s]+)', response.text)
if not after_match:
print("No more pages available")
break
after_token = after_match.group(1)
params = f"after={after_token}&name={subreddit}"
if sort == "top":
params += f"&t={time_filter}"The after token is a base64-encoded cursor that tells Reddit where to start the next page. We extract it with a regex, then append it to the parameters for the next request. The max_pages variable at the top controls how deep the scraper goes.
You'll notice about 1 post overlap between pages. This is normal for cursor-based pagination on Reddit and something to handle in post-processing if you need unique results.
Finally, export everything to CSV:
with open("subreddit-posts.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["title", "author", "score", "comments", "timestamp", "permalink"])
writer.writeheader()
writer.writerows(all_posts)
print(f"\nTotal: {len(all_posts)} posts saved to subreddit-posts.csv")Running this with max_pages = 3 on r/fishing produces around 72 posts across the three pages.
Scraping Reddit Search Results
Subreddit scraping targets one community. Reddit's search lets you find posts across the entire platform matching any query.
The search endpoint uses a standard URL format instead of the Shreddit API:
/search/?q={query}The selectors are completely different from subreddit posts. Search results use [data-testid="sdui-post-unit"] containers instead of <shreddit-post> elements, and pagination uses a cursor + iId system instead of an after token.
Configuration
import requests
from urllib.parse import quote
from bs4 import BeautifulSoup
import csv
import re
token = "<your_token>"
query = "best fishing rod"
# Sort options: "relevance", "hot", "new", "top", "comments"
sort = "relevance"
# Time filter (only applies when sort="top"):
# "hour", "day", "week", "month", "year", "all"
time_filter = "year"
max_pages = 3
search_params = f"q={quote(query)}"
if sort != "relevance":
search_params += f"&sort={sort}"
if sort == "top":
search_params += f"&t={time_filter}"Search has five sort options compared to subreddit's four: relevance (default), hot, new, top, and comments (most commented). The comments sort is useful for finding high-engagement discussions. Sort and time filter parameters are only appended when they differ from defaults, keeping the URL clean.
Extracting Search Results
all_results = []
for page in range(max_pages):
target_url = f"https://www.reddit.com/search/?{search_params}"
api_url = f"http://api.scrape.do?token={token}&url={quote(target_url)}&super=true"
response = requests.get(api_url)
if response.status_code != 200:
print(f"Page {page + 1} failed: {response.status_code}")
break
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all(attrs={"data-testid": "sdui-post-unit"})
if not results:
print(f"No more results on page {page + 1}")
break
for result in results:
title_el = result.find(attrs={"data-testid": "post-title-text"})
title = title_el.get_text(strip=True) if title_el else ""
subreddit = ""
for link in result.find_all("a"):
href = link.get("href", "")
if href.startswith("/r/") and href.endswith("/") and "/comments/" not in href:
subreddit = link.get_text(strip=True)
break
post_url = ""
post_link = result.find("a", href=lambda h: h and "/comments/" in h)
if post_link:
post_url = "https://www.reddit.com" + post_link.get("href", "")
all_results.append({
"title": title,
"subreddit": subreddit,
"url": post_url,
})
print(f"Page {page + 1}: {len(results)} results")Each search result container holds the post title in a [data-testid="post-title-text"] element. The subreddit name comes from the first <a> tag whose href starts with /r/ and ends with /. The post URL is the link containing /comments/ in its href. Note that search returns fewer results per page (~7) compared to subreddit posts (~25).
Pagination
Search pagination works differently from subreddit posts. Instead of a single after token, Reddit uses a cursor and iId pair:
cursor_match = re.search(r'cursor=([^&"\s]+)', response.text)
iid_match = re.search(r'iId=([^&"\s]+)', response.text)
if not cursor_match:
print("No more pages available")
break
cursor = cursor_match.group(1)
iid = iid_match.group(1) if iid_match else ""
search_params = f"q={quote(query)}&cursor={cursor}&iId={iid}"
if sort != "relevance":
search_params += f"&sort={sort}"
if sort == "top":
search_params += f"&t={time_filter}"Both values are extracted via regex and appended to the next page's search parameters. The sort and time filter settings carry over to maintain consistent results across pages.
Export to CSV:
with open("search-results.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["title", "subreddit", "url"])
writer.writeheader()
writer.writerows(all_results)
print(f"\nTotal: {len(all_results)} results saved to search-results.csv")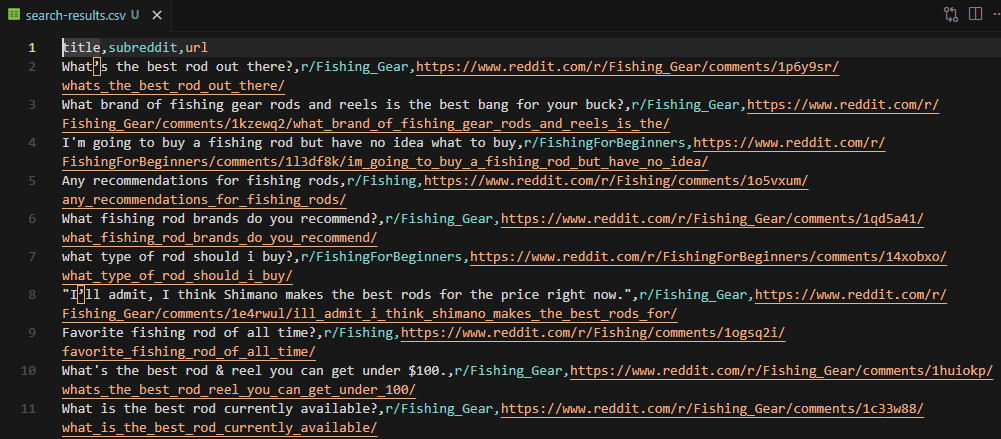
Scraping Reddit Comments
Comment search uses the same /search/ endpoint as post search, but with type=comments added to the URL. The selectors change again, and the extracted data includes the comment body, author, and the thread it belongs to.
Configuration
import requests
from urllib.parse import quote
from bs4 import BeautifulSoup
import csv
import re
token = "<your_token>"
query = "best fishing rod"
# Sort options: "relevance", "new", "top"
sort = "relevance"
# Time filter (only applies when sort="top"):
# "hour", "day", "week", "month", "year", "all"
time_filter = "all"
max_pages = 3
search_params = f"q={quote(query)}&type=comments"
if sort != "relevance":
search_params += f"&sort={sort}"
if sort == "top":
search_params += f"&t={time_filter}"Comment search has three sort options: relevance, new, and top. The type=comments parameter is what tells Reddit to return comments instead of posts, and it needs to persist across all paginated requests.
Extracting Comment Data
all_comments = []
for page in range(max_pages):
target_url = f"https://www.reddit.com/search/?{search_params}"
api_url = f"http://api.scrape.do?token={token}&url={quote(target_url)}&super=true"
response = requests.get(api_url)
if response.status_code != 200:
print(f"Page {page + 1} failed: {response.status_code}")
break
soup = BeautifulSoup(response.text, "html.parser")
comments = soup.find_all(attrs={"data-testid": "search-sdui-comment-unit"})
if not comments:
print(f"No more comments on page {page + 1}")
break
for comment in comments:
content_el = comment.find(attrs={"data-testid": "search-comment-content"})
body = content_el.get_text(strip=True) if content_el else ""
author = ""
for link in comment.find_all("a"):
if link.get("href") == "#" and link.get_text(strip=True):
author = link.get_text(strip=True)
break
thread_title = ""
subreddit = ""
thread_url = ""
for link in comment.find_all("a"):
href = link.get("href", "")
text = link.get_text(strip=True)
if "/comments/" in href and text != "Go To Thread":
thread_title = text
thread_url = "https://www.reddit.com" + href
elif href.startswith("/r/") and href.endswith("/"):
subreddit = text
all_comments.append({
"author": author,
"comment": body[:500],
"thread_title": thread_title,
"subreddit": subreddit,
"thread_url": thread_url,
})
print(f"Page {page + 1}: {len(comments)} comments")Comment containers use [data-testid="search-sdui-comment-unit"], and the comment text sits inside [data-testid="search-comment-content"]. The author name is extracted from the first <a> tag with href="#" that contains text. Thread title comes from a link with /comments/ in the href (excluding "Go To Thread" links), and the subreddit from links matching the /r/ pattern.
Comment bodies are truncated to 500 characters with body[:500] to keep the CSV manageable. You can remove this limit if you need full comment text.
Pagination
Comment search uses the same cursor + iId pagination as post search:
cursor_match = re.search(r'cursor=([^&"\s]+)', response.text)
iid_match = re.search(r'iId=([^&"\s]+)', response.text)
if not cursor_match:
print("No more pages available")
break
cursor = cursor_match.group(1)
iid = iid_match.group(1) if iid_match else ""
search_params = f"q={quote(query)}&type=comments&cursor={cursor}&iId={iid}"
if sort != "relevance":
search_params += f"&sort={sort}"
if sort == "top":
search_params += f"&t={time_filter}"The key difference from post search pagination is that type=comments must be included in every paginated request. Without it, Reddit falls back to returning posts instead of comments.
Export to CSV:
with open("reddit-comments.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["author", "comment", "thread_title", "subreddit", "thread_url"])
writer.writeheader()
writer.writerows(all_comments)
print(f"\nTotal: {len(all_comments)} comments saved to reddit-comments.csv")
Wrapping Up
Three scripts, three data types. The subreddit scraper pulls posts from any community with sort and pagination control. The search scraper finds posts across all of Reddit. The comment scraper extracts discussions matching any keyword.
All three bypass Reddit's anti-bot protection through Scrape.do's super=true parameter without needing JavaScript rendering, which keeps requests fast and straightforward.
You can extend these scripts by combining them into a single tool, adding deduplication for overlapping pagination results, or scheduling recurring scrapes to track sentiment over time.
FAQ
Is scraping Reddit legal?
Scraping publicly available data from Reddit is generally considered legal. The hiQ Labs v. LinkedIn ruling established precedent for scraping public information. That said, avoid scraping private or login-protected content, respect Reddit's robots.txt, and use reasonable request rates.
Can I scrape Reddit without an API key?
Yes. The approach in this guide uses Reddit's internal web endpoints, not the official API. You don't need Reddit API credentials or OAuth setup. You do need a Scrape.do token for anti-bot bypass, which you can get with a free account (1000 credits/month).
Why does my Reddit scraper return the wrong page?
Reddit has two blocking mechanisms: a reCAPTCHA "Prove your humanity" page and a soft block that serves only 3 posts instead of 25 (still with a 200 status code). Your script won't raise an error in either case. Check whether the number of results matches what you'd see in a browser. Using Scrape.do with super=true bypasses both by routing through residential proxies.
How many posts can I scrape from a subreddit?
Each page returns approximately 25 posts. Use the after pagination token to load additional pages by setting the max_pages variable in the script. There's no hard limit, but very deep pagination may return fewer results per page as Reddit's cursor approaches the end of available content.
What data can I extract from Reddit?
With the three scripts in this guide:
- Subreddit posts: title, author, score, comment count, timestamp, permalink
- Search results: title, subreddit, post URL
- Comments: comment body, author, thread title, subreddit, thread URL
Full Stack Developer








