Category:Scraping Use Cases
People Search Scraping: How to Extract Data from People Lookup Sites

Founder @ Scrape.do


⚠ Scraping people search data carries legal and ethical responsibilities. Only access publicly available information, respect privacy laws in your jurisdiction, and never use scraped personal data for harassment, discrimination, or unauthorized surveillance.
People search sites aggregate public records (names, addresses, phone numbers, ages, emails, and family connections) into searchable profiles that anyone can look up for free.
Great for scrapers. Terrible for bots.
Every major people search engine runs behind Cloudflare, enforces strict US-only geoblocking, and some stack additional anti-bot systems like DataDome on top. Getting a clean HTML response requires more than a basic requests call: you need residential proxies, CAPTCHA solving, and proper browser emulation.
This guide breaks down which people search sites give you the most data, how hard each one is to scrape, and what to watch out for when building scrapers against them. Each site has a dedicated tutorial with working Python code and step-by-step extraction guides.
Why Scrape People Search Data
People search data is scattered across dozens of sites, each with different coverage, accuracy, and access restrictions. Scraping lets you consolidate that data programmatically instead of clicking through profiles one by one.
The most obvious use case is lead generation: sales teams scrape people search sites to enrich lead lists with phone numbers, addresses, and emails that CRM databases miss. Got a name but no phone number? A people search scraper closes that gap at scale.
But there's more to it than sales. Skip tracing relies heavily on this data — debt collectors, process servers, and PIs use it to locate people who've moved or changed contact info. Scraping multiple sources at once beats relying on any single database.
Identity verification is another big one. Fintech companies and insurance providers cross-reference applicant details against public records to flag inconsistencies. If someone claims an address that doesn't show up in any people search database, that's worth looking into.
Then there's journalism and OSINT. Investigative reporters and intelligence analysts use public records to verify sources and map connections between individuals. The family member and associate data that some sites expose is especially useful here.
And finally, data enrichment — marketing teams scrape people search sites to fill gaps in existing datasets. A database with names and ZIP codes becomes far more actionable when you add phone numbers, emails, and age demographics.
Regardless of the use case, the challenge is the same: this data is publicly available, but getting it at scale means bypassing aggressive anti-bot defenses.
People Search Sites Compared
Not all people search sites are equal. They differ in how much data they expose for free, what protections they use, and how difficult they are to scrape.
Here's how the five major US people search engines stack up:
| Site | Free Data | Protection | Scraping Difficulty |
|---|---|---|---|
| SearchPeopleFree | Name, exact age, address, ZIP, phone, email, spouse, family | DataDome + Cloudflare | High |
| Whitepages | Name, age range, address, ZIP, phone | Cloudflare Turnstile | Medium-High |
| TruePeopleSearch | Name, age, address, ZIP, phone, email, aliases, relatives | Cloudflare | Medium |
| FastPeopleSearch | Name, age, address, ZIP, phone, email, aliases, relatives | Cloudflare | Medium |
| PeopleSearchNow | Name, age, address | Cloudflare + Slider CAPTCHA | Medium-High |
Every site on this list requires US-based IP addresses and Cloudflare bypass as a baseline. The differences come down to what's behind those walls.
Let's look at each one.
SearchPeopleFree
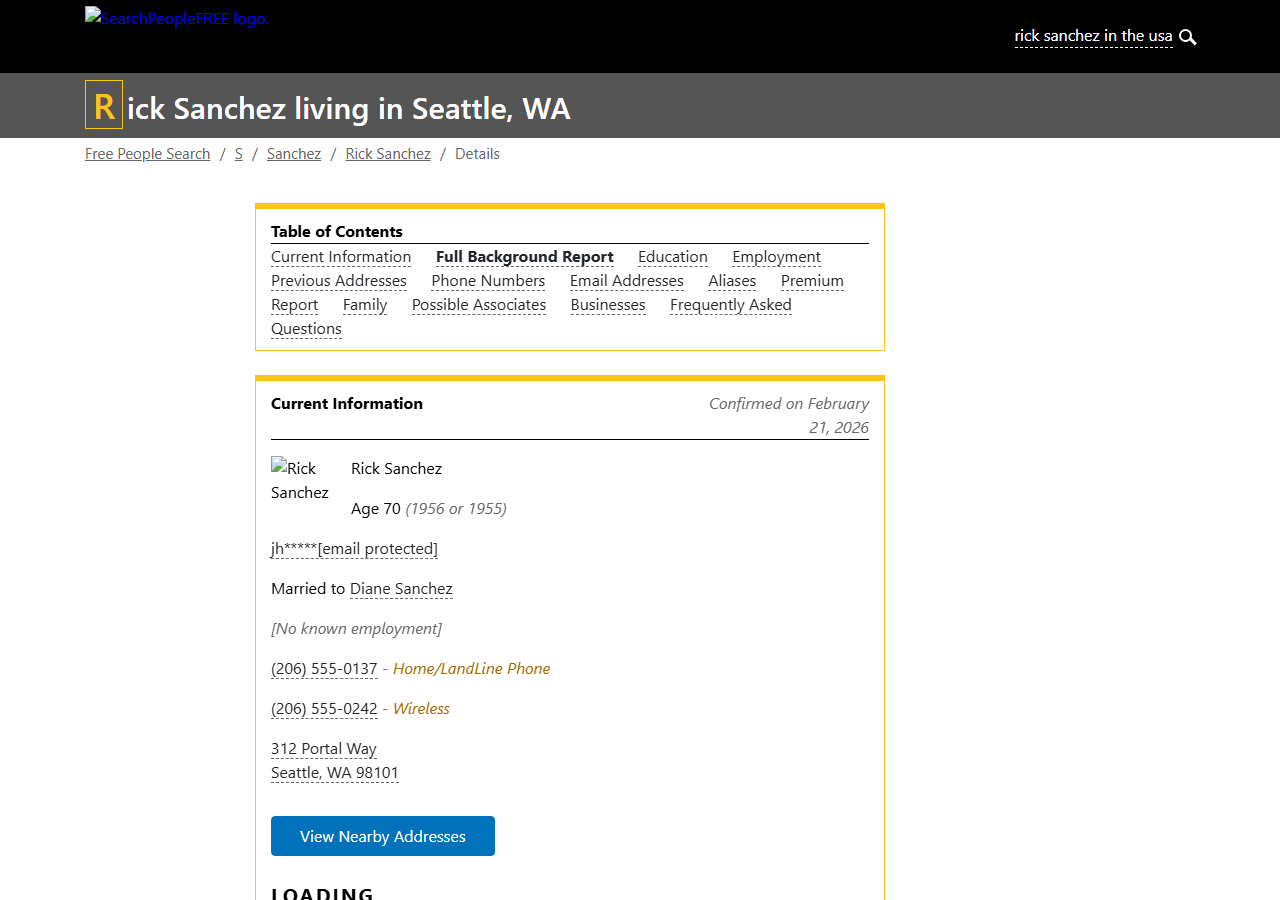
SearchPeopleFree leads the pack in data coverage. It's the only site that exposes exact age, email addresses, spouse names, and family member lists on free profiles: 10 structured data fields from a single API call. Most competitors restrict at least some of these fields to premium tiers.
The tradeoff is protection. SearchPeopleFree stacks DataDome on top of Cloudflare, creating a dual-layer anti-bot system that analyzes both network fingerprints and behavioral signals. It also uses Cloudflare's email obfuscation to XOR-encrypt emails in the HTML, though they're available in plaintext through JSON-LD structured data.
Data fields: Name, exact age, address, ZIP, phone, email, spouse, family Protection: DataDome + Cloudflare | Difficulty: High Full scraping guide →
Whitepages
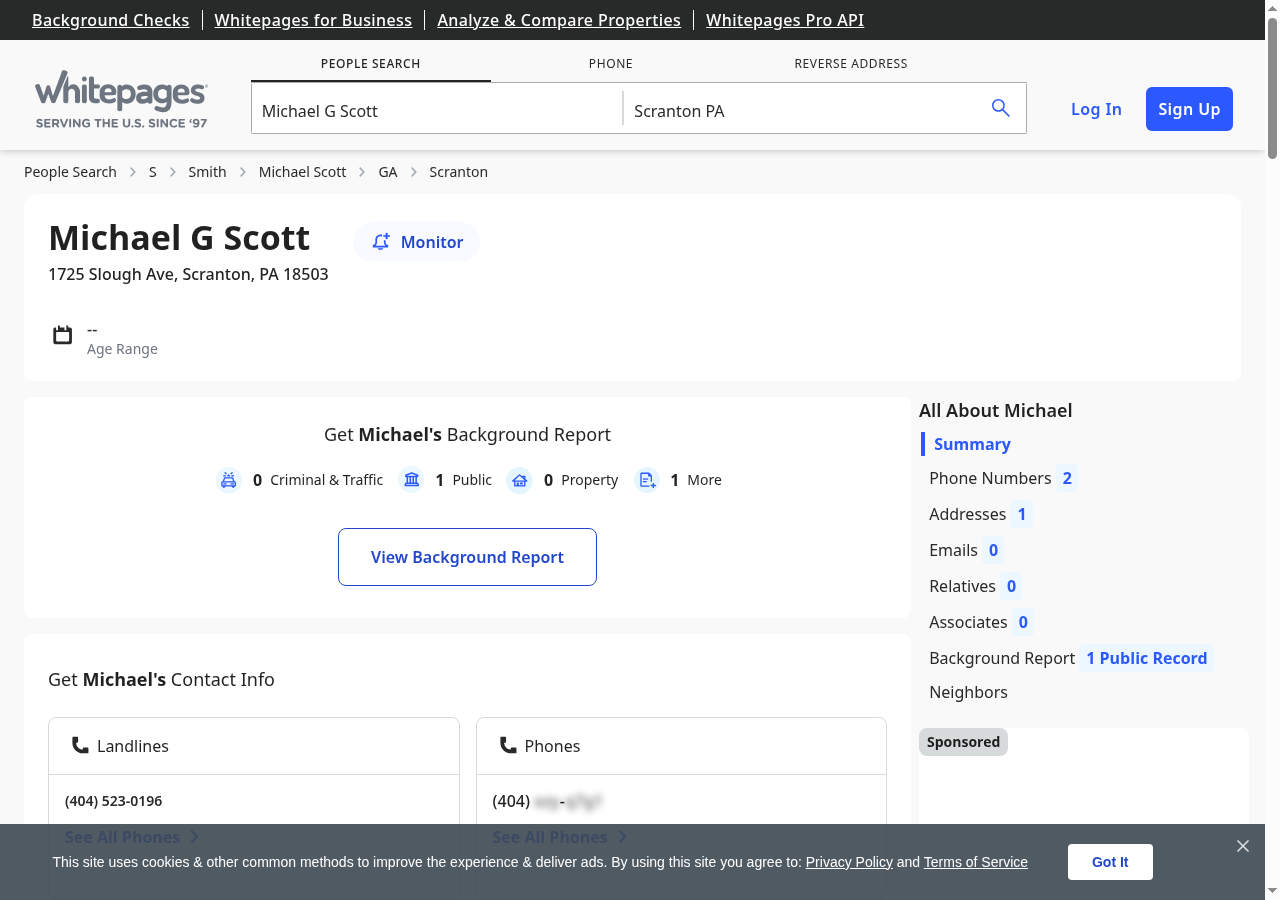
Whitepages is the largest people search engine with 260 million records, but it gates key data behind a paywall. Exact age shows as ranges like "in their 50s," and emails, phone history, and family data require a premium subscription.
The free tier still gives you name, current address, ZIP code, and primary phone number, enough for lead qualification and identity matching. Whitepages uses Cloudflare Turnstile for verification, which runs invisible JavaScript challenges in the background.
Data fields: Name, age range, address, ZIP, phone Protection: Cloudflare Turnstile | Difficulty: Medium-High Full scraping guide →
TruePeopleSearch
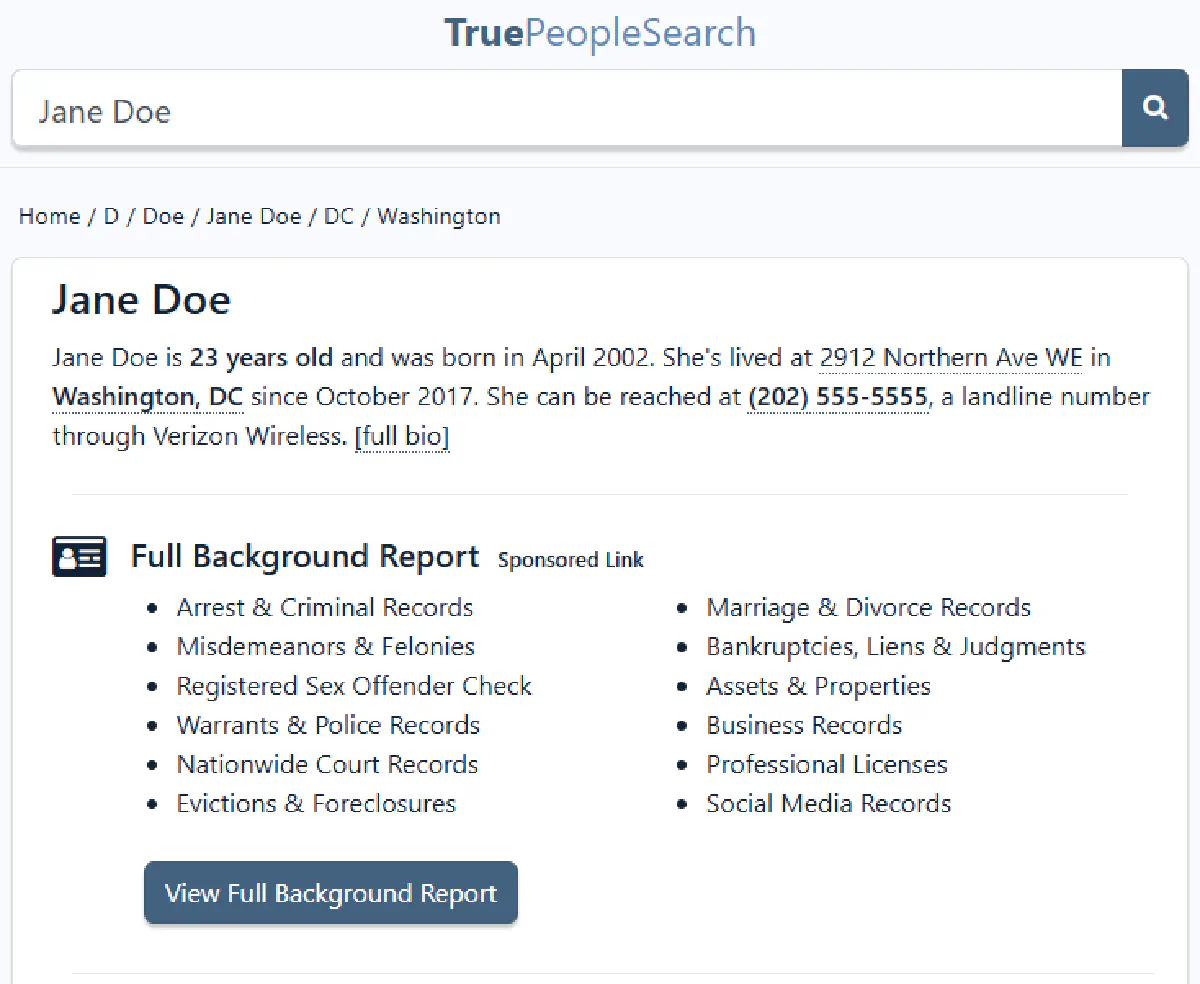
TruePeopleSearch offers a rich dataset without a paywall. Beyond the basics (name, age, address, phone), the page embeds a JSON-LD ProfilePage schema with email addresses, aliases, relatives, and full ZIP codes, all accessible without a premium account.
Standard Cloudflare protection without additional anti-bot layers makes it one of the easier targets in the group.
Data fields: Name, age, address, ZIP, phone, email, aliases, relatives Protection: Cloudflare | Difficulty: Medium Full scraping guide →
FastPeopleSearch
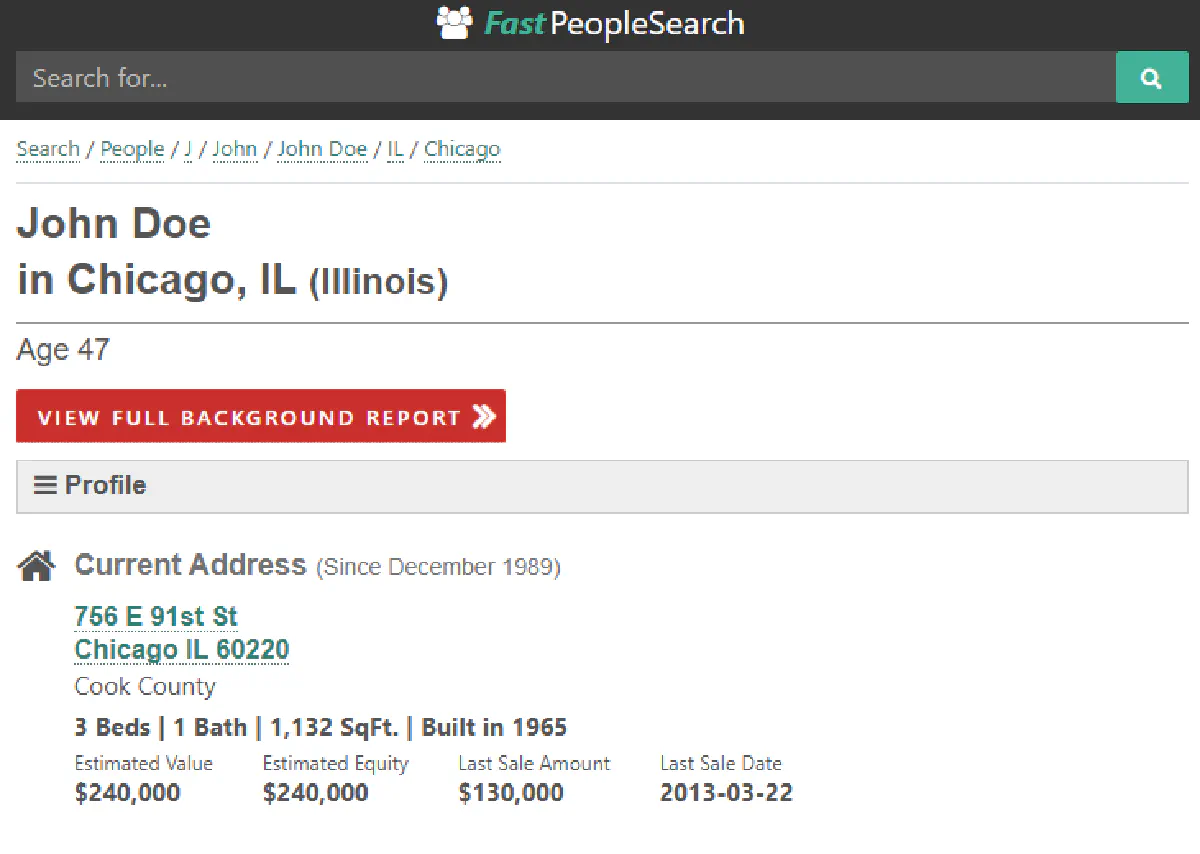
FastPeopleSearch matches TruePeopleSearch in data coverage with phone numbers, emails, aliases, and relatives all extracted from JSON-LD. Emails are uniquely found in a FAQPage JSON-LD block, a technique that bypasses Cloudflare's XOR obfuscation entirely.
Like TruePeopleSearch, it runs standard protection against Cloudflare bypass, manageable with the right proxy setup.
Data fields: Name, age, address, ZIP, phone, email, aliases, relatives Protection: Cloudflare | Difficulty: Medium Full scraping guide →
PeopleSearchNow
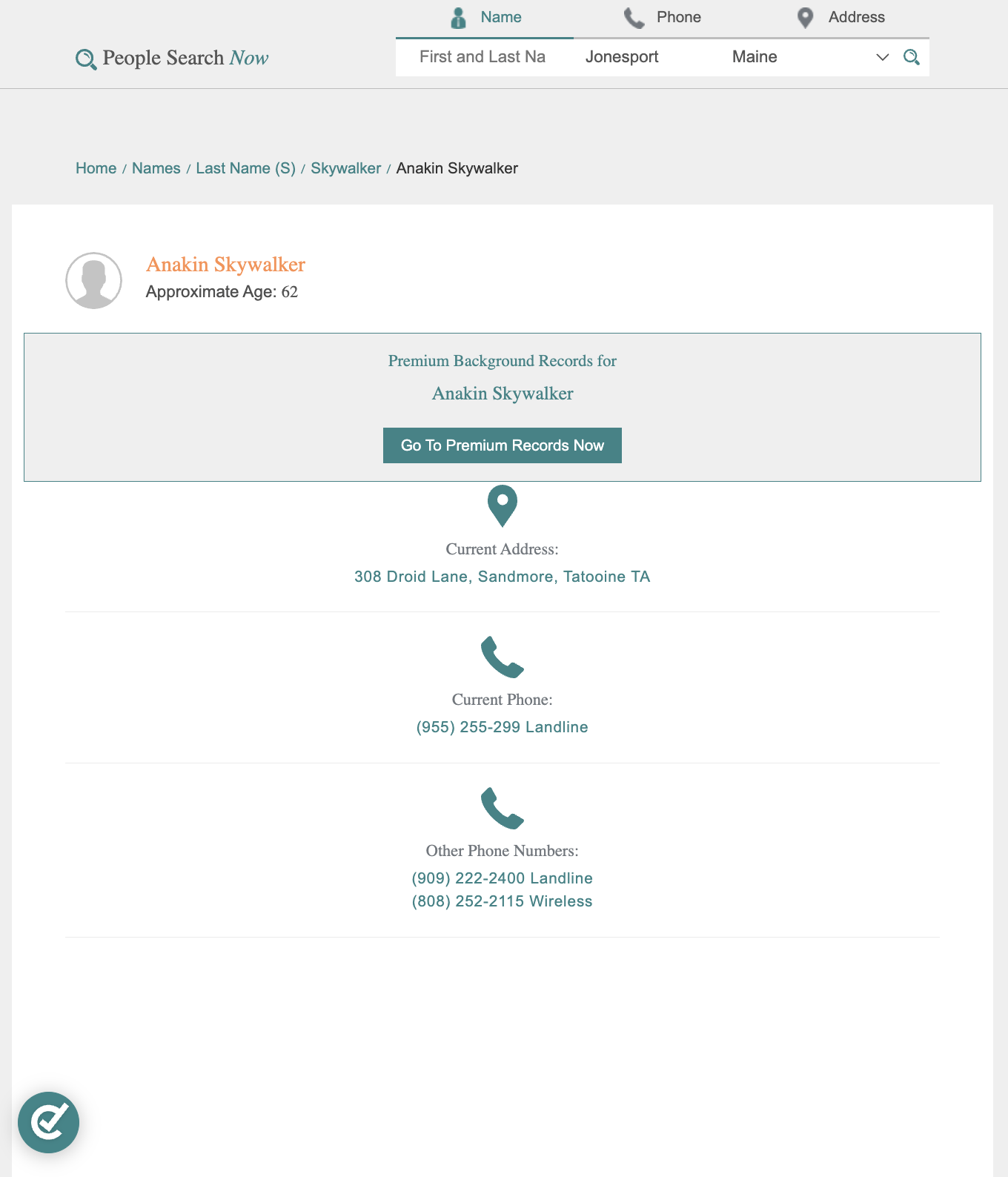
PeopleSearchNow is the most limited on free profiles, providing name, approximate age, and address without phone, email, or family data. But the clean CSS-based HTML structure makes it easy to parse once you're past the protections.
The catch is the slider CAPTCHA, an active challenge that requires explicit interaction, harder to bypass than passive Turnstile checks.
Data fields: Name, age, address Protection: Cloudflare + Slider CAPTCHA | Difficulty: Medium-High Full scraping guide →
What's Blocking Your Scraper
Every people search site blocks automated access. But they don't all block you the same way. Here's what your scraper is up against, and what each defense looks like.
Geoblocking
All five sites reject non-US traffic before the page loads. No redirect, no error message. The connection gets dropped or you see a hard block page:
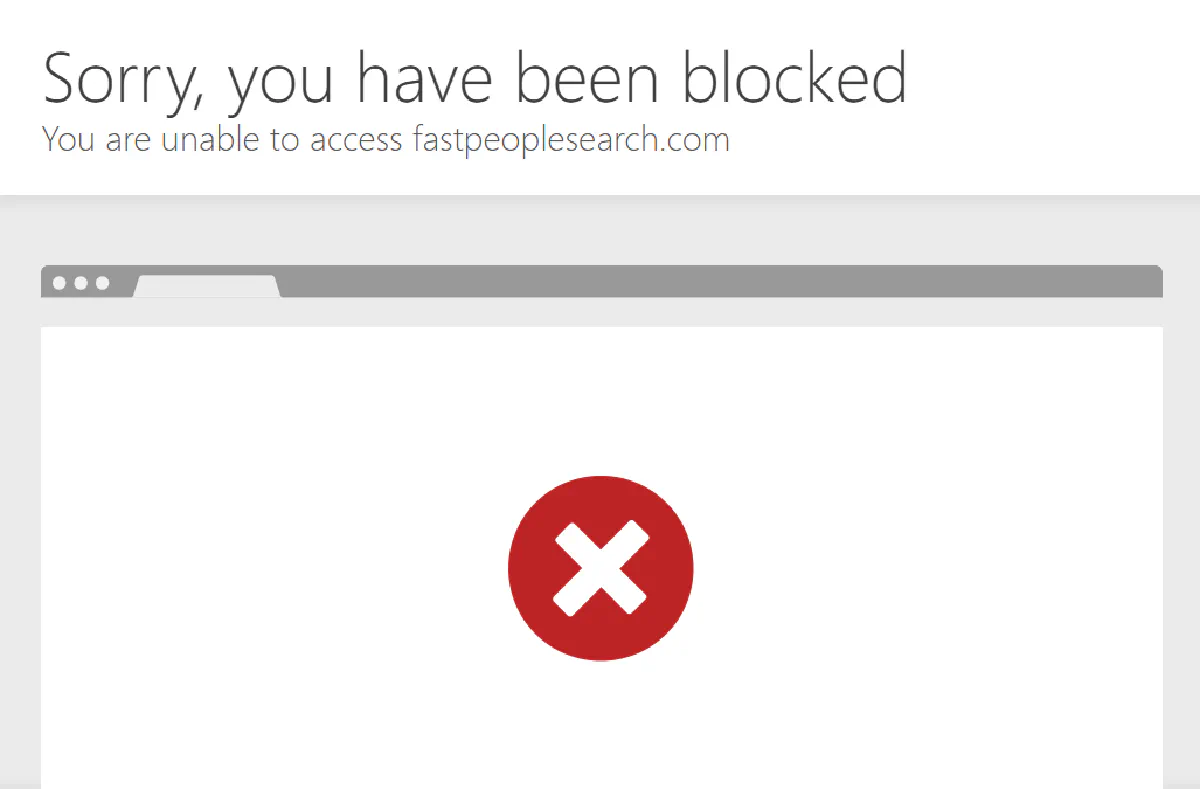
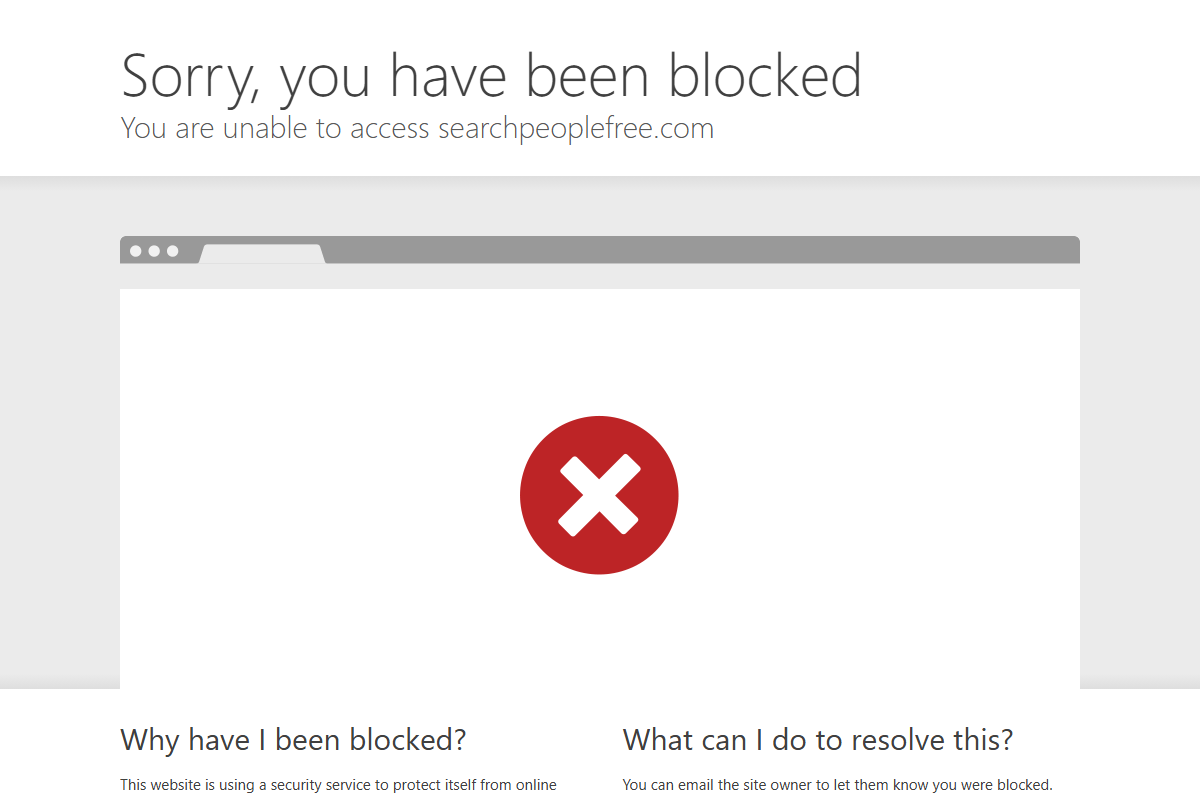
Datacenter proxies and most VPNs fail this check too. Cloudflare's IP reputation system flags them as non-residential. You need actual US residential IPs to get past the geoblock.
Cloudflare Challenges
Even with a valid US IP, Cloudflare steps in with JavaScript verification, fingerprint analysis, and invisible challenges.
Whitepages uses Turnstile, Cloudflare's newer system that runs verification silently in the background:
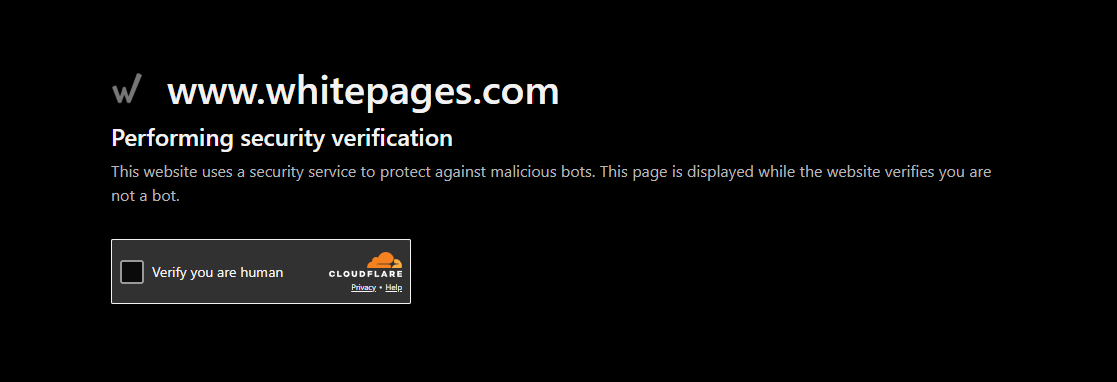
TruePeopleSearch and FastPeopleSearch escalate to traditional CAPTCHAs when they detect automated patterns:
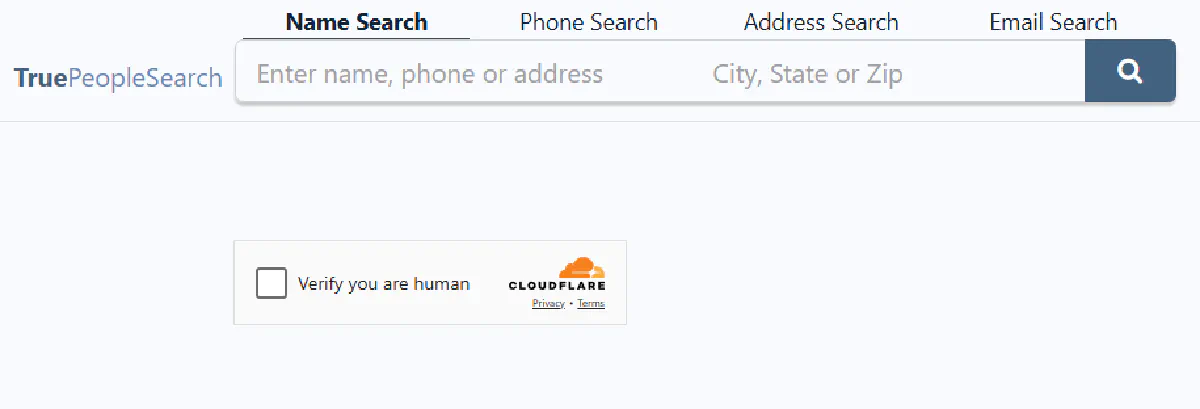
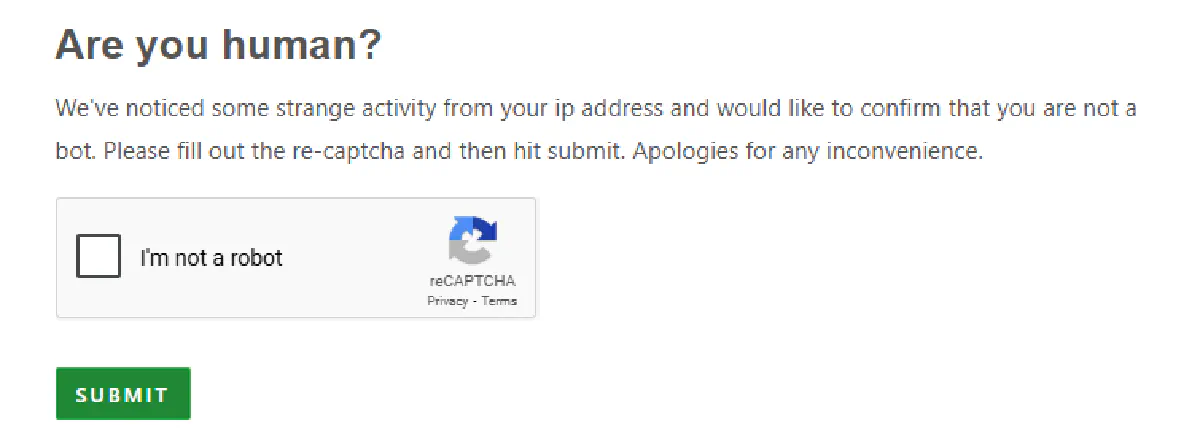
Standard HTTP libraries can't pass any of these. They don't execute JavaScript, don't maintain browser state, and don't produce the fingerprints Cloudflare expects.
Slider CAPTCHAs and Active Challenges
PeopleSearchNow goes further with active slider CAPTCHAs that require explicit mouse interaction:
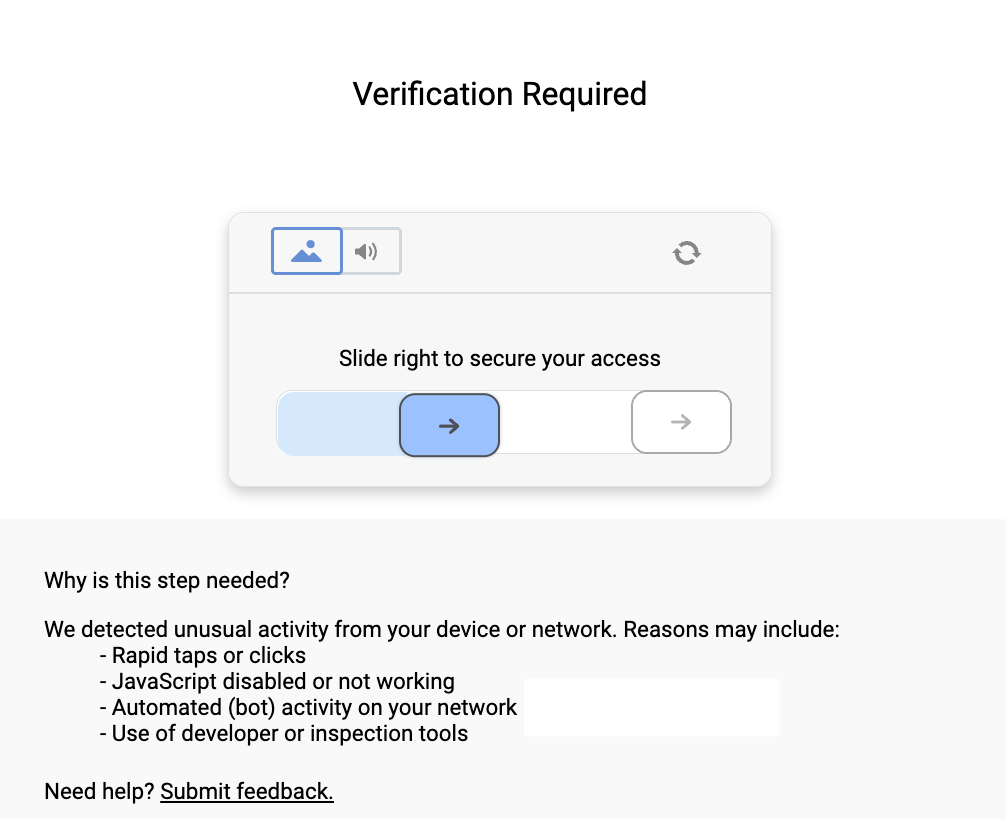
Unlike passive verification, slider CAPTCHAs need a real browser environment with convincing movement patterns, making them harder to bypass than standard Cloudflare checks.
What to Watch Out For
Age data quality varies. SearchPeopleFree gives exact ages. TruePeopleSearch and FastPeopleSearch show specific numbers. Whitepages only shows approximate ranges. Check the source before building your pipeline.
Data freshness isn't guaranteed. Addresses listed as "current" may be months or years old. Cross-referencing across multiple sites improves accuracy but doesn't eliminate stale records.
Rate limits escalate. Some sites tighten their Cloudflare rules after detecting repeated requests from the same session. Rotate through proxy IPs and add delays between calls even when using a web scraping API.
Extraction methods aren't interchangeable. Each site structures its HTML differently: JSON-LD schemas, Vue.js data attributes, CSS class selectors, header parsing. A scraper built for one site won't work on another. Each needs its own parsing logic.
Scraping People Information with Scrape.do
Despite the differences in protection levels and data formats, every people search site on this list shares one thing: they all fall to the same Scrape.do configuration.
The pattern is identical across all five sites:
import requests
import urllib.parse
token = "<your_token>"
target_url = "https://www.searchpeoplefree.com/find/john-smith/abc123"
encoded_url = urllib.parse.quote_plus(target_url)
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true&geoCode=us"
response = requests.get(api_url)Two parameters do the heavy lifting:
super=true: Switches to premium residential proxies with full browser emulation. This handles Cloudflare challenges, DataDome verification, CAPTCHA solving, and TLS fingerprinting automatically.geoCode=us: Routes traffic through US-based residential IPs, bypassing the geoblock that every people search site enforces.
The response comes back as fully rendered HTML, ready to parse with BeautifulSoup, no headless browser required. From there, the extraction logic varies per site, which is why each has its own dedicated guide:
- SearchPeopleFree Scraping Guide: JSON-LD extraction for 10 data fields including email, spouse, and family
- Whitepages Scraping Guide: CSS selectors + JSON-LD for age range extraction
- TruePeopleSearch Scraping Guide: Data attributes + ProfilePage JSON-LD extraction
- FastPeopleSearch Scraping Guide: Header parsing + Person/FAQPage JSON-LD extraction
- PeopleSearchNow Scraping Guide: Class-based HTML selectors for name, age, and address
Each guide includes a complete working Python scraper, tested against real pages with fictional data, and available on GitHub.
Conclusion
People search sites hold valuable public record data, but they protect it aggressively with geoblocking, Cloudflare, CAPTCHAs, and layered anti-bot systems.
Scrape.do bypasses all of them with the same two-parameter setup:
- 110M+ residential proxies with US geo-targeting
- Automatic Cloudflare, DataDome, and CAPTCHA bypass
- Pay only for successful responses
Founder @ Scrape.do








