
OnTheMarket Scraper
Scrape Listings and Prices from OnTheMarket
Extract property listings, pricing data, agent details, and market insights from one of the UK's top 3 property portals. OnTheMarket uses reCAPTCHA, strict rate limits, and IP-based session tracking. Scrape.do handles them automatically.
Start scraping today with 1000 free credits. No Credit Card Required
18M Monthly Visits. Exclusive Listings. One API.
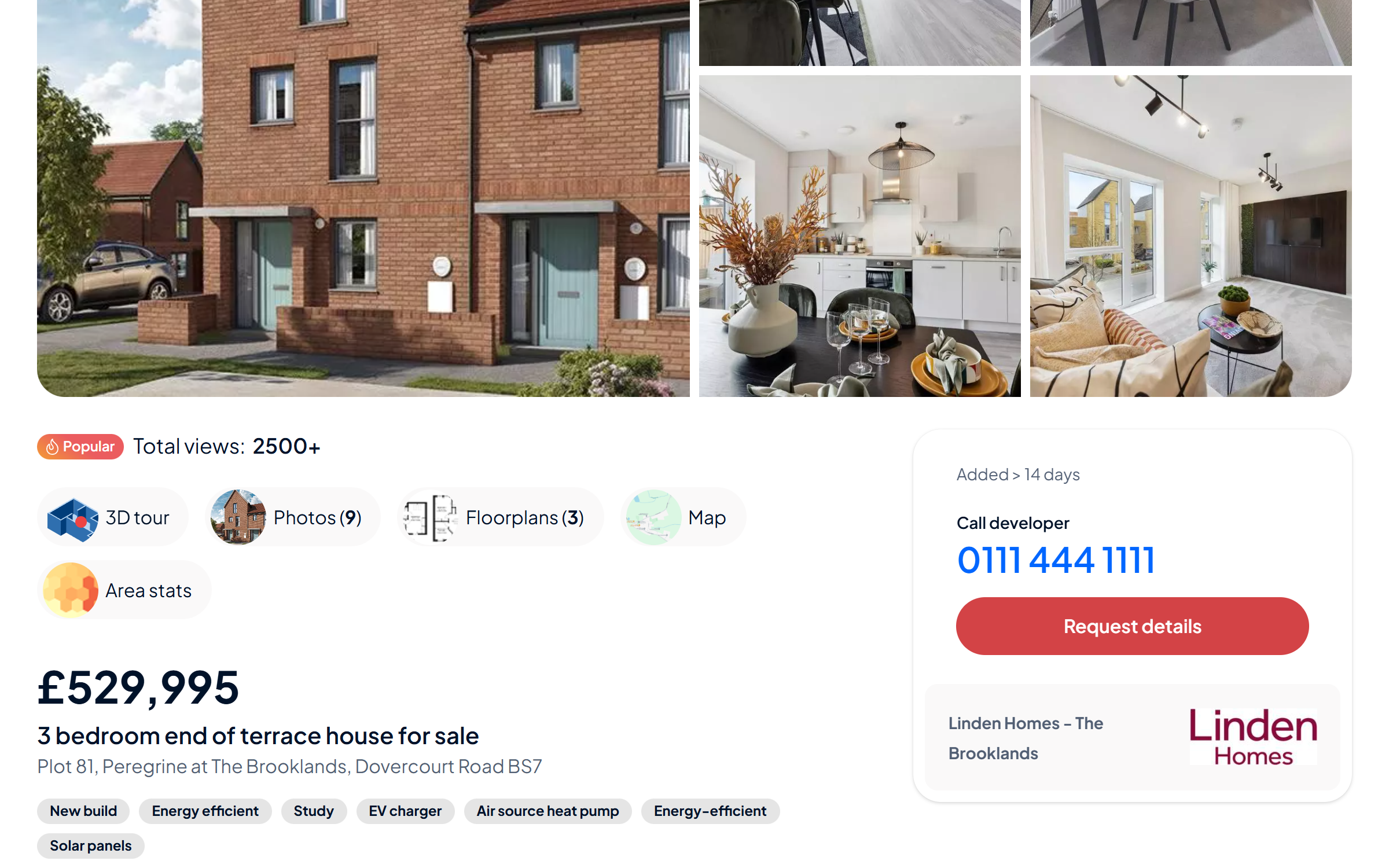
OnTheMarket is one of the top 3 property portals in the UK, attracting over 18 million monthly visits in 2026. It lists properties for sale and to rent across England, Scotland, and Wales.
What makes OnTheMarket especially valuable for scrapers is its "Only With Us" feature. Some properties appear on OnTheMarket days before they show up on Rightmove or Zoopla. If you're tracking new listings, monitoring price changes, or feeding data into valuation models, this early access is a competitive edge.
CloudFront WAF. Instant Blocks. Handled.
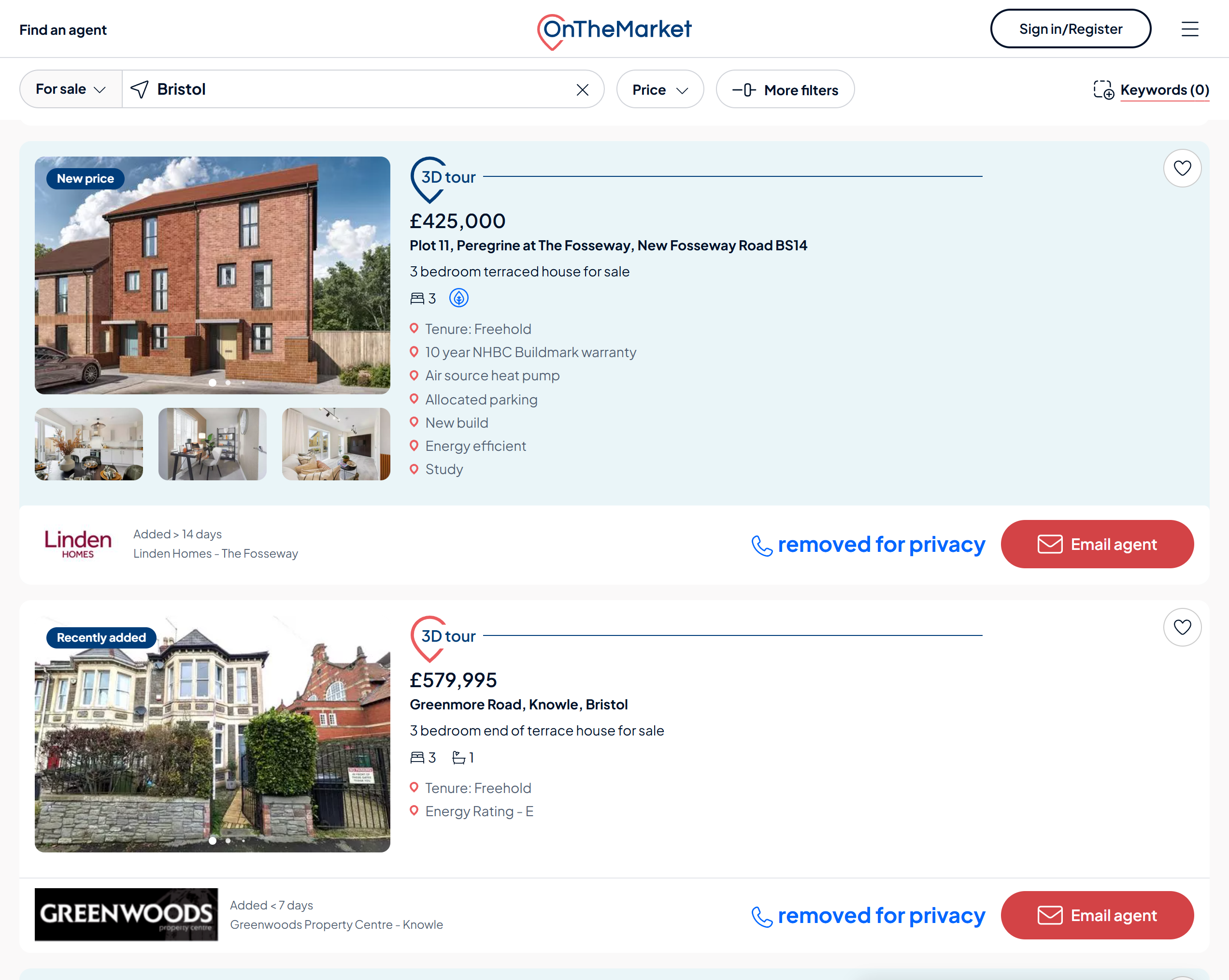
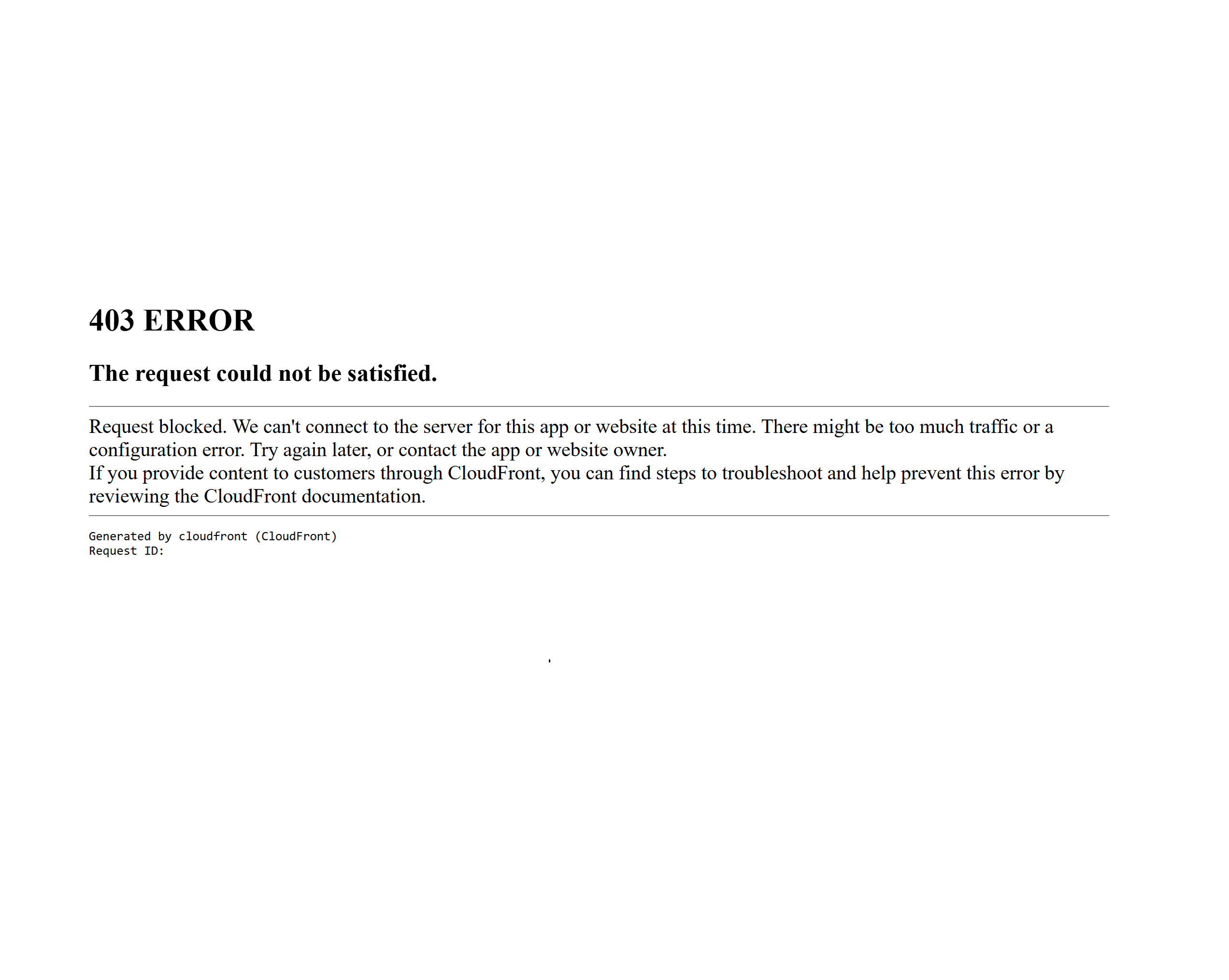
OnTheMarket uses Amazon CloudFront as its WAF where bots get blocked instantly. If your request looks automated, you'll see a 403 error before the page even loads. The site also uses reCAPTCHA and tracks IP-based sessions aggressively.
Scrape.do provides high-quality datacenter IPs that hide your bots and let you scrape OnTheMarket with rates as low as 10 cents for 1,000 results. No proxy lists, no CAPTCHA solvers, no maintenance.
How to Scrape OnTheMarket
Select a Target
Send API Request
import requests
import urllib.parse
token = "<SDO-token>"
targetUrl = "https://www.onthemarket.com/details/12345/"
render = "false" # set to "true" to enable JavaScript rendering
super = "false" # set to "true" to enable residential proxies
encodedUrl = urllib.parse.quote(targetUrl)
url = f"https://api.scrape.do/?token={token}&url={encodedUrl}&render={render}&super={super}"
response = requests.get(url)
print(response.text)Get HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>3 bedroom terraced house for sale - Bristol</title>
</head>
<body>
<div class="property-header">
<h1>3 bedroom terraced house for sale</h1>
<p class="address">Southville, Bristol, BS3</p>
</div>
<div class="price-container">
<span class="price">£529,995</span>
<span class="price-qualifier">Guide Price</span>
</div>
<div class="key-features">
<span class="bedrooms">3 bedrooms</span>
<span class="bathrooms">2 bathrooms</span>
<span class="type">Terraced house</span>
<span class="tenure">Freehold</span>
</div>
<div class="gallery">
<img src="https://media.onthemarket.com/...image1.jpg">
<img src="https://media.onthemarket.com/...image2.jpg">
</div>
<div class="agent">
<span class="name">Keller Williams</span>
<span class="branch">Bristol, BS1</span>
<span class="phone">0117 XXX XXXX</span>
</div>
<div class="description">
<p>A beautifully presented three bedroom
terraced house in the heart of Southville...</p>
</div>
<!-- ... remaining page content ... -->
</body>
</html>
Scrape.do has been a game-changer with powerful scraping tools, but what truly sets them apart is their excellent customer support.

CTO


Average Response Time
No tickets connect with expert engineers.

Success rate

Proxies

Faster gateway than the closest competitor.







Reliable, Scalable,Unstoppable Web Scraping
Sounds great, but I have a few questions..
Yes. Scrape.do uses real browser environments with rotating residential proxies to bypass OnTheMarket's reCAPTCHA, rate limits, and IP-based session tracking. Success rates exceed 95% on listing and detail pages.
You can extract property titles, prices, addresses, number of bedrooms and bathrooms, property type, descriptions, agent contact details, listing photos, floorplans, and price history.
OnTheMarket loads listings and property details through client-side JavaScript. Use Scrape.do's headless browser mode (render=true) to execute JavaScript and capture the fully rendered page content, including lazy-loaded images and interactive maps.






