Category:Scraping Use Cases
Scraping Zomato Menus and Restaurant Data with Python

Full Stack Developer



Zomato once aimed to be the global Yelp-TripAdvisor hybrid for restaurants.
Today, it’s a different beast: laser-focused on food delivery and restaurant discovery in India, and still active in UAE for reviews.
Behind the scenes, they're laying the groundwork to expand again and become a competitor to DoorDash.
And if you're trying to extract Zomato restaurant data for automation, research, or analysis, you'll notice something quickly; you don’t get far before you're blocked.
In this guide, you’ll learn how to scrape restaurant and menu data from Zomato without running into those blocks, using Python and Scrape.do.
Find code samples on the GitHub repo ⚙
Setup and Prerequisites
You won’t need a headless browser or advanced bot evasion tricks for this one but you still need the right tools to get consistent results.
Let’s walk through what needs to be in place before your first request:
Install Required Libraries
This script is built with Python using three essentials: requests to send HTTP requests, BeautifulSoup to parse the response, and json to handle structured data.
If you don’t have them installed yet, run:
pip install requests beautifulsoup4No need for anything beyond that.
Generate a Scrape.do API Token
While Zomato might let your first request through without much fuss, it doesn’t take long for the site to start pushing back.
IP bans, stripped content, and silent failures start to appear after just a few requests even if your script looks clean.
The reason is simple: Zomato tracks more than just your IP. It fingerprints headers, detects basic scrapers, and silently blocks automated access once patterns emerge.
That’s where Scrape.do comes in.
It routes every request through rotating proxies, applies real-user header profiles, and handles retries automatically. You just send a request and Scrape.do does the rest.
Create a free account and get your API token. You’ll plug this token into your script to make every request go through the Scrape.do API.
Pick and Prepare a Data Storage/Processing Workflow
In real-world use, you won't scrape just one page. You will scrape thousands daily.
So doing this manually or saving to a simple CSV file won't cut it.
Start thinking now about how you’ll store and work with the data.
Here are a few solid options, depending on your use case:
- For quick testing or exploration: Save results to a
.jsonor.csvfile and review them manually. - For ongoing projects: Use SQLite or PostgreSQL to store structured restaurant data you can query, join, and update as needed.
- For heavy processing or analysis: Feed your scraped data into Pandas or stream it to BigQuery for aggregation, filtering, and reporting.
- For automation and scale: Schedule scrapers with cronjobs, or use a workflow manager like Apache Airflow to trigger daily crawls, retry failed jobs, and integrate with downstream tools.
You don’t need to biuld the full pipeline today. But setting up the right foundation now will save you a lot of rework later.
Collect Restaurant Information
We’ll begin with a single restaurant page, The Cheesecake Factory in Dubai and extract key details: name, address, price range, image, rating, and review count.
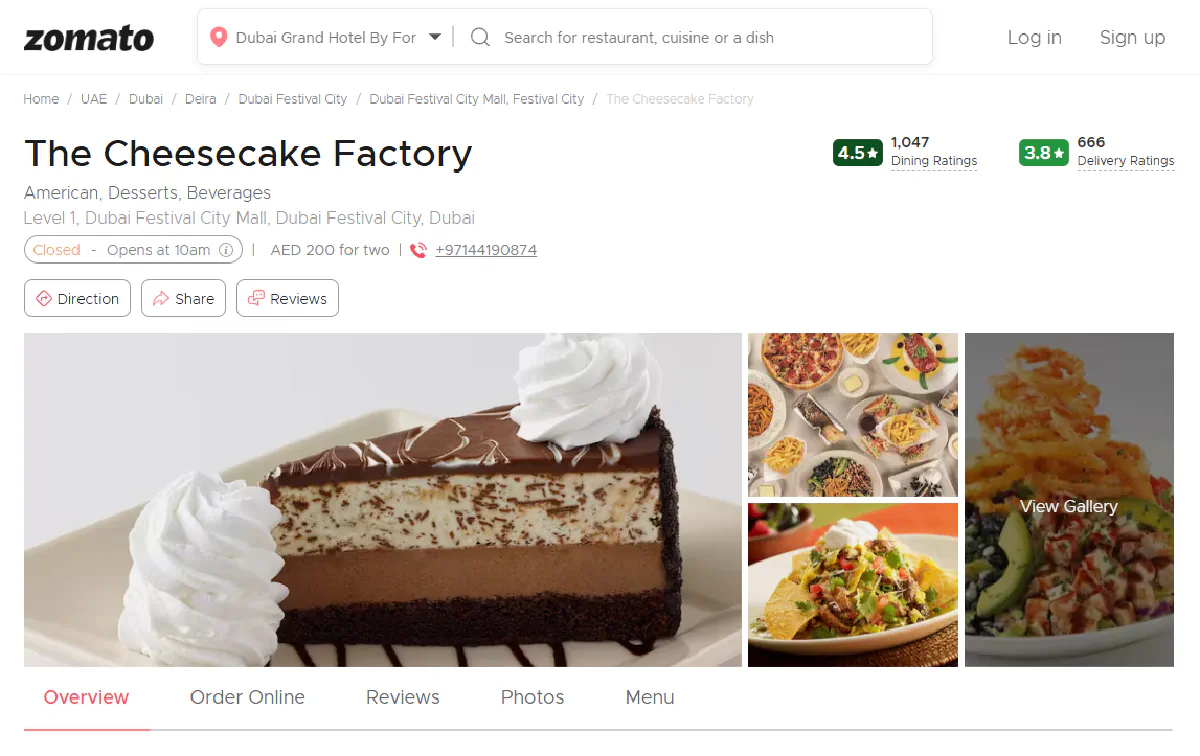
Now, traditionally, you’d open the page, inspect each element in DevTools, and manually figure out which div, span, or meta tag holds the info you want.
But fortunately for you, Zomato makes this process easier.
To appear in Google’s rich search results, Zomato includes structured data inside each restaurant page. This comes in the form of a <script type="application/ld+json"> block containing machine-readable metadata following Schema.org standards.
And this is a gift for scraping.
Instead of parsing the messy DOM, we can grab this JSON-LD block directly and get clean, structured data in one go.
Let’s walk through it step by step.
First, import the libraries and set up the API request using Scrape.do:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import json
# Scrape.do token
token = "<your_token>"
# Zomato restaurant URL
target_url = urllib.parse.quote_plus("https://www.zomato.com/dubai/the-cheesecake-factory-dubai-festival-city")
# Scrape.do API URL
api_url = f"http://api.scrape.do/?token={token}&url={target_url}"Then we send the request and parse the response:
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")The JSON-LD block we’re after is the second script tag of type application/ld+json. We’ll extract and load it like this:
json_ld = soup.find_all("script", type="application/ld+json")[1].string
data = json.loads(json_ld)From here, we can print and access all the fields directly:
print("Name:", data["name"])
print("Address:", data["address"]["streetAddress"])
print("Price Range:", data["priceRange"])
print("Image URL:", data["image"])
print("Rating Value:", data["aggregateRating"]["ratingValue"])
print("Review Count:", data["aggregateRating"]["ratingCount"])Here’s what the output looks like:
Name: The Cheesecake Factory
Address: Level 1, Dubai Festival City Mall, Dubai Festival City, Dubai
Price Range: AED 200 for two people (approx.)
Image URL: https://b.zmtcdn.com/data/pictures/chains/0/201340/99a877e5e9aac1815d6ecfc226829407.jpg?output-format=webp
Rating Value: 4.5
Review Count: 1047Simple as that :)
Scrape Entire Menu from a Restaurant in Zomato
Restaurant metadata is useful but if you're looking to track pricing, analyze offerings, or build food-related datasets, you’ll need access to the menu itself.
In this section, we’ll scrape the full delivery menu of a McDonald’s branch in New Delhi.
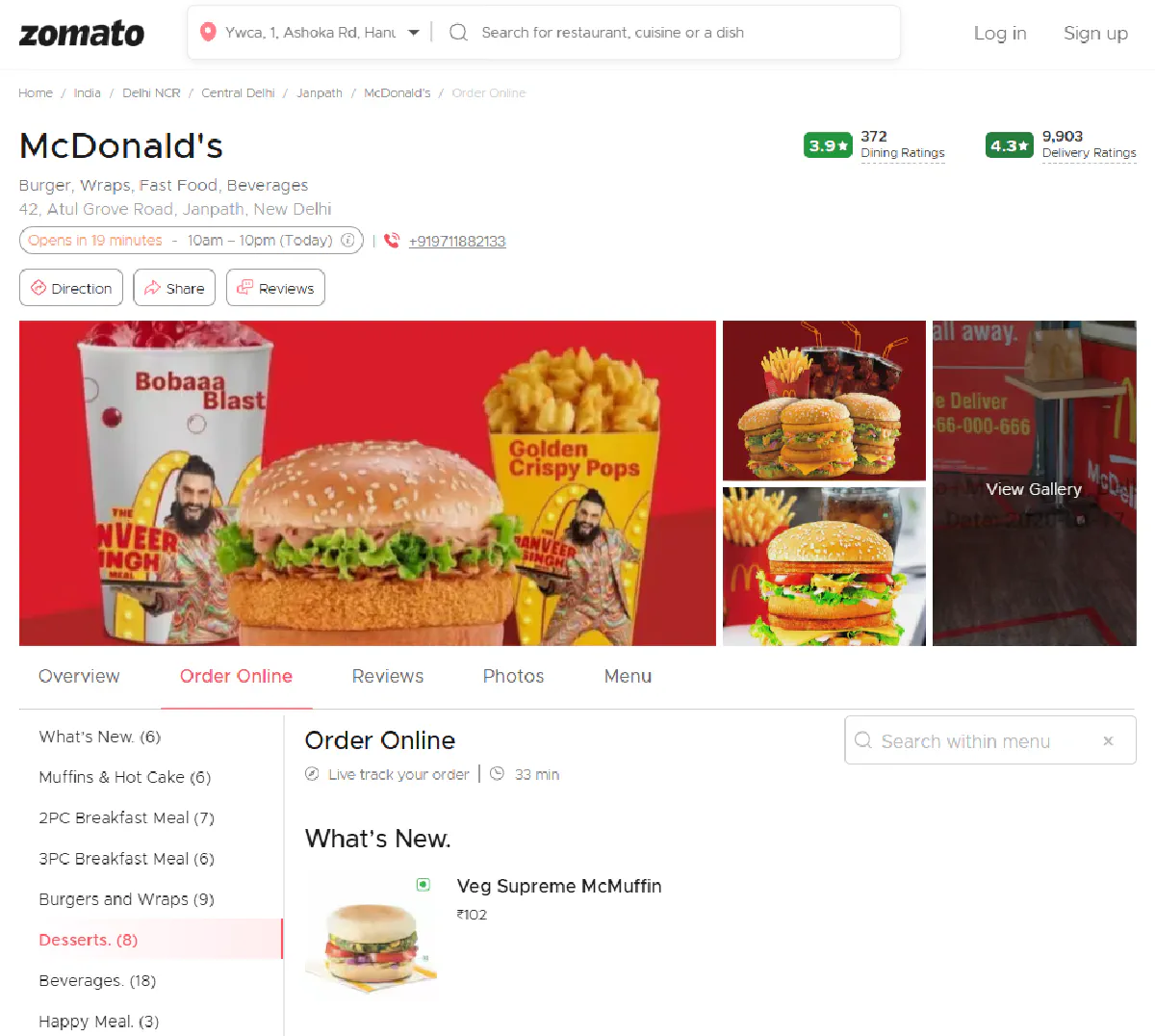
We'll extract:
- Item names
- Prices
- Menu categories
- Delivery-specific ratings (not dine-in)
But here's the catch: menu data isn’t stored in the visible HTML. Zomato, like many modern platforms, renders the page dynamically using JavaScript.
This means most of the real content including the menu is injected from JavaScript variables after the page loads.
Not to worry, though, since the structure is predictable.
When you visit a Zomato restaurant page with delivery enabled, the frontend loads a massive JavaScript object named window.__PRELOADED_STATE__. This object holds everything: restaurant info, delivery options, menu items, prices, categories, and more.
So, again, instead of scraping HTML, we’re going to:
- Request the page via Scrape.do.
- Parse the JavaScript variable containing the state.
- Extract and decode the menu and restaurant info from that JSON blob.
Let’s start with the full input to get everything loaded and working:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import json
# Your Scrape.do token
token = "<your_token>"
# Target Zomato URL (McDonald's Janpath, New Delhi)
target_url = urllib.parse.quote_plus("https://www.zomato.com/ncr/mcdonalds-janpath-new-delhi/order")
api_url = f"http://api.scrape.do/?token={token}&url={target_url}"
# Fetch and parse
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract the JavaScript state object
script = soup.find("script", string=lambda s: s and "window.__PRELOADED_STATE__" in s)
json_text = script.string.split('JSON.parse("')[1].split('")')[0]
data = json.loads(json_text.encode().decode('unicode_escape'))Yes, our aim is to extract the menu. But the menu without the restaurant info is not going to make a lot of sense, so we'll get basic info of the place:
restaurant = data["pages"]["restaurant"]["182"]
info = restaurant["sections"]["SECTION_BASIC_INFO"]
contact = restaurant["sections"]["SECTION_RES_CONTACT"]
name = info["name"]
location = contact["address"]
rating_data = info["rating_new"]["ratings"]["DELIVERY"]
rating = rating_data["rating"]
review_count = rating_data["reviewCount"]
print(f"Restaurant: {name}")
print(f"Address : {location}")
print(f"Delivery Rating: {rating} ({review_count} reviews)\n")And finally, we'll loop through the menu and print each item along with its category and price:
menus = restaurant["order"]["menuList"]["menus"]
for menu in menus:
category = clean_text(menu["menu"]["name"])
for cat in menu["menu"]["categories"]:
for item in cat["category"]["items"]:
item_name = clean_text(item["item"]["name"])
item_price = item["item"]["price"]
print(f"{category} - {item_name}: ₹{item_price}")The result is a fully structured list of every menu item, matched with its category and price:
Restaurant: McDonald's
Address : 42, Atul Grove Road, Janpath, New Delhi
Delivery Rating: 4.3 (9,903 reviews)
What's New. - Veg Supreme McMuffin: ₹102
What's New. - Veg Supreme McMuffin With Beverage: ₹154
...
<-------- Many more menu items, omitted -------->
...
Happy Meal. - HappyMeal McAloo Tikki Burger®: ₹257
Happy Meal. - HappyMeal Chicken McGrill®: ₹300Clean, hierarchical, and immediately usable.
This structure is stable across Zomato delivery URLs, which means once you get this flow working, you can apply it to any delivery restaurant link.
Conclusion
Zomato doesn't have the most aggressive anti-bot protection. But that doesn't mean you won't get blocked.
After just a few requests, IP bans and stripped content start to kick in, especially on delivery pages.
With the right setup, scraping Zomato is completely doable.
And Scrape.do makes it effortless.
You don't need to worry about:
- Rotating IPs or managing sessions
- Headers, TLS fingerprints, or JavaScript execution
- Parsing inconsistent HTML or handling soft blocks
Just send a request and get back clean, structured data every time.
The techniques here work for Zomato, but if you need to scale across multiple platforms for comprehensive food delivery data scraping, the same principles apply to each platform.
Get your 1000 monthly free credits and start scraping Zomato today.
Full Stack Developer








