Category:Scraping Basics
Web Scraping in Perl

Technical Writer

Perl is a great option for web scraping because of its powerful text manipulation features and the wide range of modules available on CPAN. This detailed guide will show how Perl can efficiently extract data from web pages, including static and dynamic content.
Essential Perl Modules for Web Scraping
Perl provides various modules for web scraping, including automating HTTP requests, parsing HTML, and handling repetitive tasks like form submissions. Let's see some essential Perl modules for web scraping:
LWP::UserAgent
LWP::UserAgent is a Perl module that serves as a web client, allowing you to send HTTP requests and receive responses. It’s part of the libwww-perl library, which provides a simple and consistent API for web interactions.
Here's an example of how to make a simple GET request:
use strict;
use warnings;
use LWP::UserAgent;
my $ua = LWP::UserAgent->new();
my $url = 'https://books.toscrape.com/';
my $response = $ua->get($url);
print $response->decoded_content;You can handle various HTTP response status codes as follows:
if ($response->code == 200) {
print "Success: " . $response->decoded_content;
} elsif ($response->code == 404) {
print "Error 404: Page not found.";
} elsif ($response->code == 500) {
print "Error 500: Internal server error.";
} else {
print "Unexpected response: " . $response->status_line;
}HTTP::Request
HTTP::Request is another module from the libwww-perl library, designed for making advanced HTTP requests. It allows for greater control over the requests sent, enabling you to construct custom requests with specific headers, methods, and data. This module works in conjunction with LWP::UserAgent to effectively manage requests and responses.
Here's how to create a custom GET request:
use LWP::UserAgent;
use HTTP::Request;
my $ua = LWP::UserAgent->new;
my $url = 'https://httpbin.org/get';
my $request = HTTP::Request->new(GET => $url);
my $response = $ua->request($request);
if ($response->is_success) {
my $data = $response->decoded_content;
print $data;
} else {
print "Failed to retrieve data: ", $response->status_line, "\n";
}Now, to make a POST request with JSON data, you can use the following code:
use LWP::UserAgent;
use HTTP::Request::Common;
my $ua = LWP::UserAgent->new;
my $url = 'https://httpbin.org/post';
my $request = POST $url,
Content_Type => 'application/json',
Content => '{ "title": "Scrape.do Services", "body": "Best Rotating Proxy & Web Scraping API", "userId": 1 }';
my $response = $ua->request($request);
if ($response->is_success) {
my $data = $response->decoded_content;
print $data;
} else {
print "Failed to post data: ", $response->status_line, "\n";
}If the POST request is successful, the response will confirm the sent JSON data. See the below result:
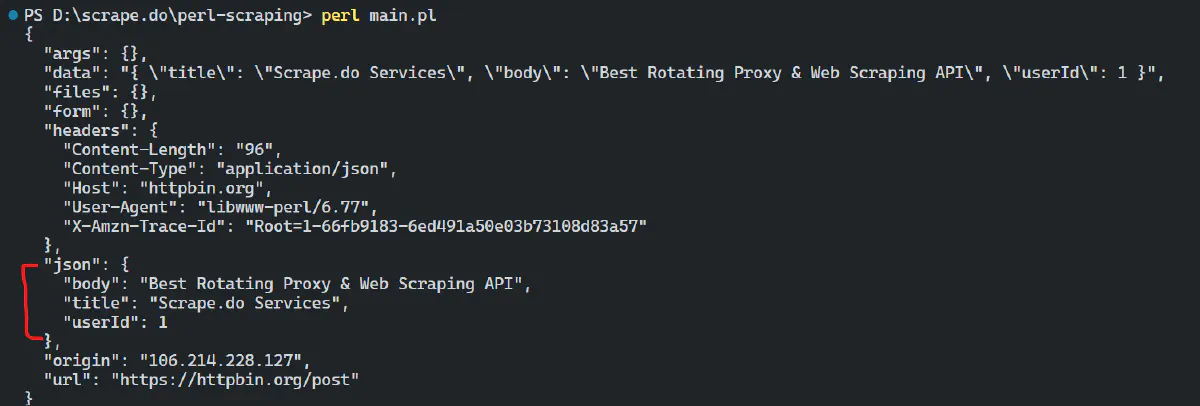
By default, the user agent is set to “libwww-perl/6.77”. You can change it to your custom user agent like this:
use LWP::UserAgent;
use HTTP::Request::Common;
my $ua = LWP::UserAgent->new;
$ua->agent("MyApp/1.0"); # Custom user agent
my $url = 'https://httpbin.org/post';
my $request = POST $url,
Content_Type => 'application/json',
Content => '{ "title": "Scrape.do Services", "body": "Best Rotating Proxy & Web Scraping API", "userId": 1 }';
my $response = $ua->request($request);
if ($response->is_success) {
my $data = $response->decoded_content;
print $data;
} else {
print "Failed to post data: ", $response->status_line, "\n";
}This will change the user agent in the request:
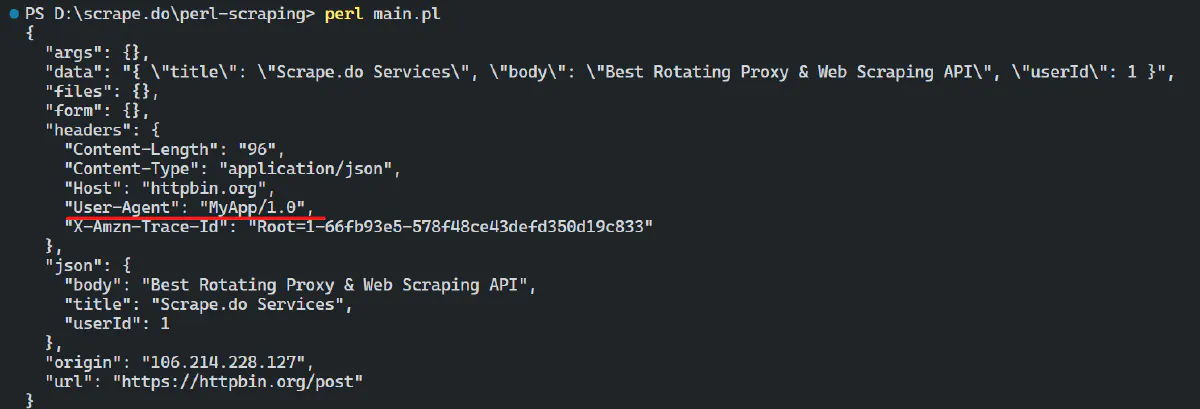
HTML::TreeBuilder
HTML::TreeBuilder is a parser that converts HTML documents into a tree structure. To use HTML::TreeBuilder, follow these steps:
- Create a New TreeBuilder Object: Initialize an empty tree using the new method.
- Parse HTML Content: Use the
parse_contentmethod to convert the HTML content into a structured tree. - Traverse and Manipulate the Tree: After building the tree, you can traverse it using methods like
look_down,content_list, andas_textto extract or modify data. - Delete the Tree: Call the
deletemethod to free up memory after processing.
To install HTML::Tree, copy and paste the appropriate command into your terminal.
cpanm HTML::TreeHere’s a simple example of using HTML::TreeBuilder to parse and extract data from an HTML document:
use LWP::Simple;
use HTML::TreeBuilder;
# Fetch the webpage content
my $url = "https://news.ycombinator.com/";
my $html_content = get($url) or die "Couldn't fetch the webpage!";
# Parse the HTML content
my $tree = HTML::TreeBuilder->new;
$tree->parse_content($html_content);
# Extract the article titles and links
foreach my $span ($tree->look_down(_tag => 'span', class => 'titleline')) {
# Get the <a> tag inside the <span> which contains the title and link
if (my $link_element = $span->look_down(_tag => 'a')) {
my $title = $link_element->as_text; # Extract the title text
my $link = $link_element->attr('href'); # Extract the link URL
print "Title: $title\n";
print "Link: $link\n";
print "--------\n";
}
}
# Clean up
$tree->delete;In this example, the code fetches HTML content from a URL, parses it into a tree, and extracts text from elements with a specific class attribute.
The output is:
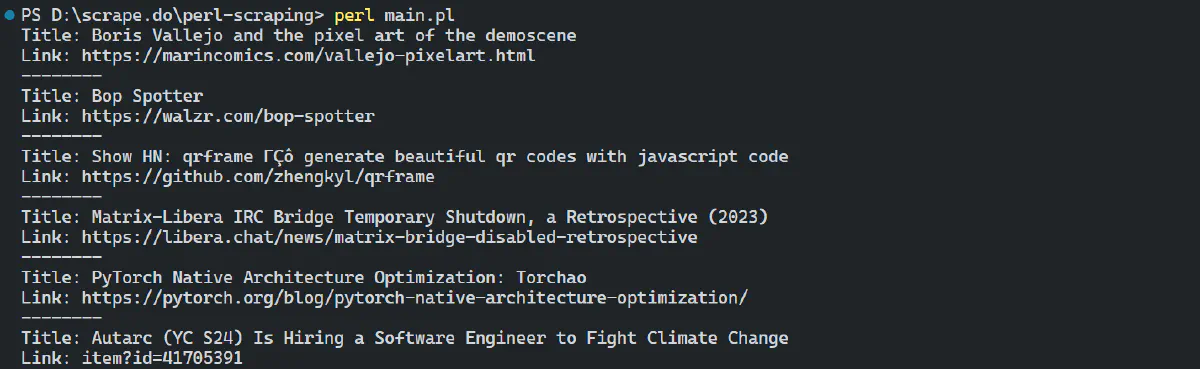
Great! We’ve successfully extracted all the news articles from the Hacker News website.
WWW::Mechanize
WWW::Mechanize is a powerful Perl module that extends LWP::UserAgent to automate web interactions. It is often described as a "browser emulator" because it can perform actions like filling out forms, clicking links, and handling cookies.
Here’s how to automate the login process to a website:
use WWW::Mechanize;
# Create a new WWW::Mechanize object
my $mech = WWW::Mechanize->new();
# Login page URL
my $url = 'https://news.ycombinator.com/login';
$mech->get($url);
die "Couldn't access $url" unless $mech->success();
# Fill out the login form
$mech->submit_form(
form_number => 1,
fields => {
acct => 'username', # Replace with your actual username
pw => 'password' # Replace with your actual password
}
);
# Check if the login was successful
if ($mech->content() =~ /logout/) {
print "\nLogin successful!\n\n";
} else {
die "Login failed!";
}In this code, the submit_form method from the WWW::Mechanize module is used to fill out and submit the login form. The fields acct and pw correspond to the username and password, which are filled in automatically. After submission, the script checks the response to determine if the login was successful by looking for the presence of the word "logout" in the page content.
The output is:

Handling JavaScript-Heavy Websites
Many modern websites use JavaScript, particularly Single-Page Applications (SPAs) and those with dynamic content loading, like infinite scrolling. Traditional scraping methods that only work with static HTML won't work for these sites. Instead, you can use headless browsers like Chrome or Firefox with tools like Selenium to execute the JavaScript and scrape content from these websites effectively.
Take the BBC News website, for example. It loads content as you scroll down and uses JavaScript for interactive elements.
Install the Selenium::Chrome module:
cpan Selenium::ChromeHere's how you can use Perl and Selenium to scrape headlines from BBC News:
use Selenium::Chrome;
my $driver = Selenium::Chrome->new(binary => 'C:/Program Files/chromedriver.exe');
$driver->get('https://www.bbc.com/innovation');
my @headlines = $driver->find_elements('//h2[@data-testid="card-headline"]', 'xpath');
for my $i (0 .. $#headlines) {
eval {
my $headline = $headlines[$i]->get_text;
if ($headline) {
print(( $i + 1 ) . ". " . $headline . "\n");
}
};
}
$driver->shutdown_binary;In Perl, the Selenium::Chrome module allows you to use the ChromeDriver without needing the Java Runtime Environment (JRE) or a Selenium server running.
Run the code, and you will see the headlines extracted.

While scraping rendered HTML works, it can be slow. A more efficient way is to intercept and replicate the AJAX calls websites use to fetch data behind the scenes.
To identify these calls, you can use your browser's developer tools. Open the developer tools (usually by pressing F12), go to the "Network" tab, and filter by "XHR" to see AJAX requests. Look for requests that return JSON data, as this often contains the information you need.
In the BBC News example, when you click on the next page, it triggers an AJAX request to an API endpoint that contains the content for that page.
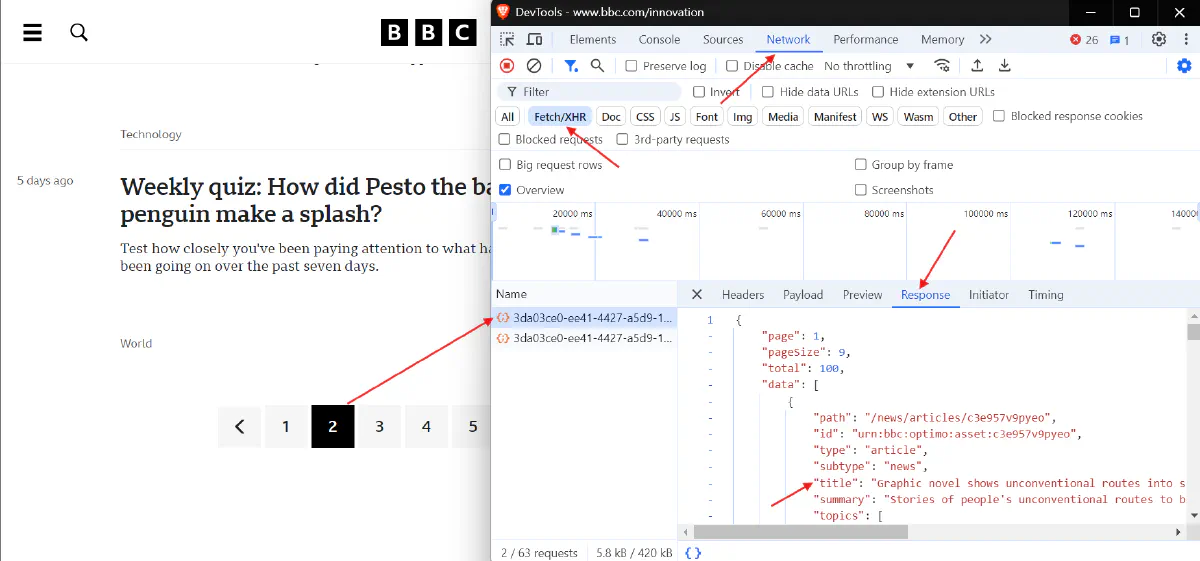
Once you have the API endpoint URL, you can use libraries like LWP::UserAgent to make HTTP requests and download the data directly. Here's a code:
use LWP::UserAgent;
use HTTP::Request;
use JSON;
# Initialize the user agent for making HTTP requests
my $ua = LWP::UserAgent->new;
# Base URL of the AJAX request without the page parameter
my $base_url = "https://web-cdn.api.bbci.co.uk/xd/content-collection/3da03ce0-ee41-4427-a5d9-1294491e0448?country=in&size=9";
# Initialize the page number to start fetching data from
my $page = 1;
my $has_more_data = 1; # Flag to track if there is more data to fetch
# Loop until there is no more data to fetch
while ($has_more_data) {
# Inform the user about the current page being fetched
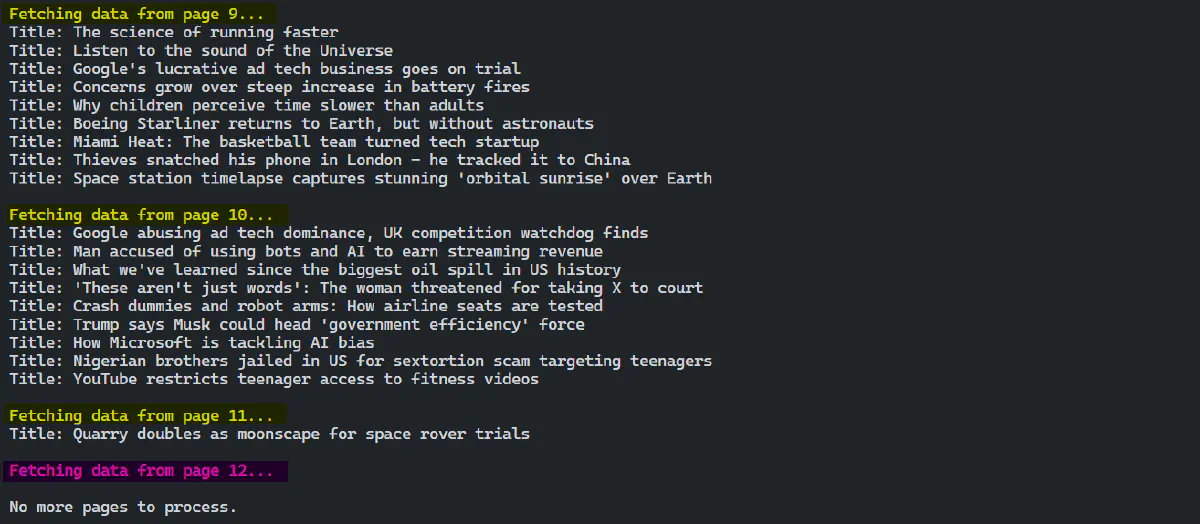
print "Fetching data from page $page...\n";
# Construct the URL for the current page
my $url = $base_url . "&page=" . $page;
# Prepare the HTTP GET request for the constructed URL
my $request = HTTP::Request->new(GET => $url);
# Send the request and get the response
my $response = $ua->request($request);
# Check if the request was successful
if ($response->is_success) {
# Decode the JSON content from the response
my $content = $response->decoded_content;
my $json_data = decode_json($content);
# Process the fetched data (e.g., print the titles of articles)
foreach my $article (@{$json_data->{data}}) {
my $title = $article->{title};
print "Title: $title\n";
}
# Determine if there is more data to fetch based on the total articles and current page
if ($json_data->{total} <= $page * $json_data->{pageSize}) {
# If the total articles is less than or equal to the processed articles, there's no more data
$has_more_data = 0;
} else {
# Move to the next page if there's more data
$page++;
}
} else {
# Handle the case where the HTTP GET request fails
die "HTTP GET error: ", $response->status_line;
}
}
# Inform the user that all data has been fetched
print "No more pages to process.\n";This code fetches data from all pages of the BBC News and prints the titles of articles.
Handling Cookies and Sessions
When scraping websites that require user login, maintaining the session state across multiple requests is important. The HTTP::Cookies module in Perl allows you to effectively manage cookies. This module lets you:
- Store cookies received from the server.
- Include cookies with your HTTP requests, enabling you to maintain a session after logging in.
Here's an example of how to log in to a website using LWP::UserAgent along with HTTP::Cookies to manage the session:
use strict;
use warnings;
use LWP::UserAgent;
use HTTP::Cookies;
use HTTP::Request;
# Create a new cookie jar to manage session cookies
my $cookie_jar = HTTP::Cookies->new();
# Initialize a user agent with the cookie jar
my $ua = LWP::UserAgent->new(cookie_jar => $cookie_jar);
my $login_url = 'https://news.ycombinator.com/login';
my $username = 'username';
my $password = 'password';
# Fetch the login page to get session cookies
my $login_page = $ua->get($login_url);
# Prepare the login request with credentials
my $login_request = HTTP::Request->new(POST => $login_url);
$login_request->content("acct=$username&pw=$password");
# Send the login request and get the response
my $response = $ua->request($login_request);
if ($response->is_success || $response->code == 302) {
print "Login attempt completed. Check the response content to verify success.\n";
# Fetch the profile page after successful login
my $profile_url = "https://news.ycombinator.com/user?id=$username";
my $profile_response = $ua->get($profile_url);
if ($profile_response->is_success) {
print "Fetched profile page content:\n";
print $profile_response->decoded_content;
} else {
print "Failed to fetch profile page: " . $profile_response->status_line . "\n";
}
} else {
print "Login attempt failed: " . $response->status_line . "\n";
}Here’s the explanation of the code:
- A new cookie jar is created using
HTTP::Cookies->new(), which will store session cookies. - An instance of
LWP::UserAgentis created with the cookie jar passed as an argument. This allows the user agent to automatically manage cookies during HTTP requests. - When the login request is sent, any cookies set by the server (like session cookies) are stored in the cookie jar.
- When fetching the profile page after a successful login, the user agent automatically includes the stored cookies in the request, maintaining the session.
The output would be similar to this:
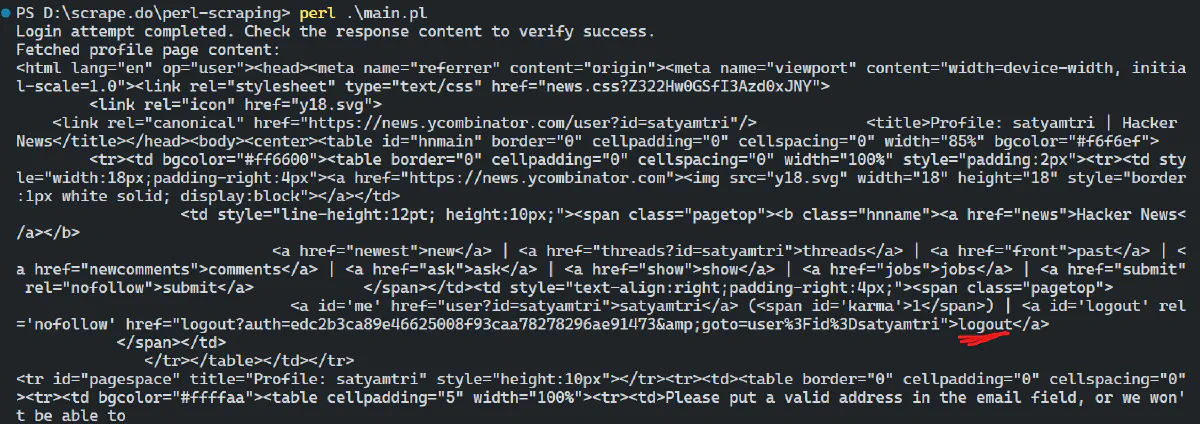
The output confirms that the session is maintained, allowing access to the protected page after login, as indicated by key pointers like logout options.
Working with Data Formats: JSON and XML
When scraping, we often encounter data formats like JSON and XML. Here's how to extract and handle data in both formats using Perl.
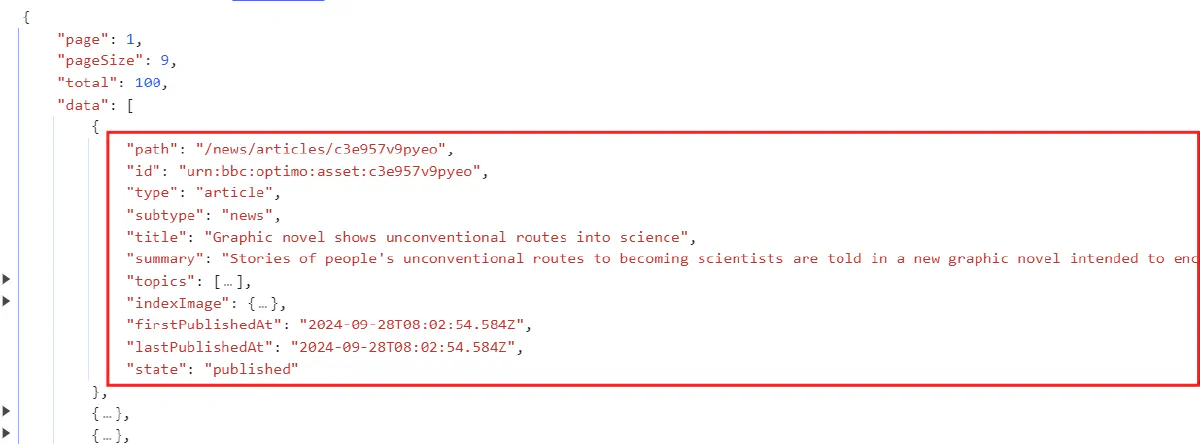
To extract data from JSON APIs, you can use Perl's JSON module to parse responses. Here's the data returned by our JSON API:
Let's send a GET request to a JSON API, parse the response, and handle nested data structures. Here's the code:
use LWP::UserAgent;
use JSON;
my $ua = LWP::UserAgent->new;
# URL for the JSON API
my $url = 'https://web-cdn.api.bbci.co.uk/xd/content-collection/3da03ce0-ee41-4427-a5d9-1294491e0448?country=in&size=9';
# Send a GET request
my $response = $ua->get($url);
if ($response->is_success) {
# Decode the JSON response
my $json_data = decode_json($response->decoded_content);
# Accessing nested data
foreach my $article (@{$json_data->{data}}) {
print "Title: " . $article->{title} . "\n";
print "Summary: " . $article->{summary} . "\n";
print "Published At: " . $article->{firstPublishedAt} . "\n";
print "Image URL: " . $article->{indexImage}->{model}->{blocks}->{src} . "\n\n";
}
} else {
die "HTTP GET error: " . $response->status_line;This Perl code sends a GET request to the URL that returns JSON data. It then decodes the JSON response using decode_json, converting it into a Perl data structure. Finally, it iterates over the array of articles contained in the data key of the JSON response. For each article, it prints the title and publication date.
The output of the code looks like this:

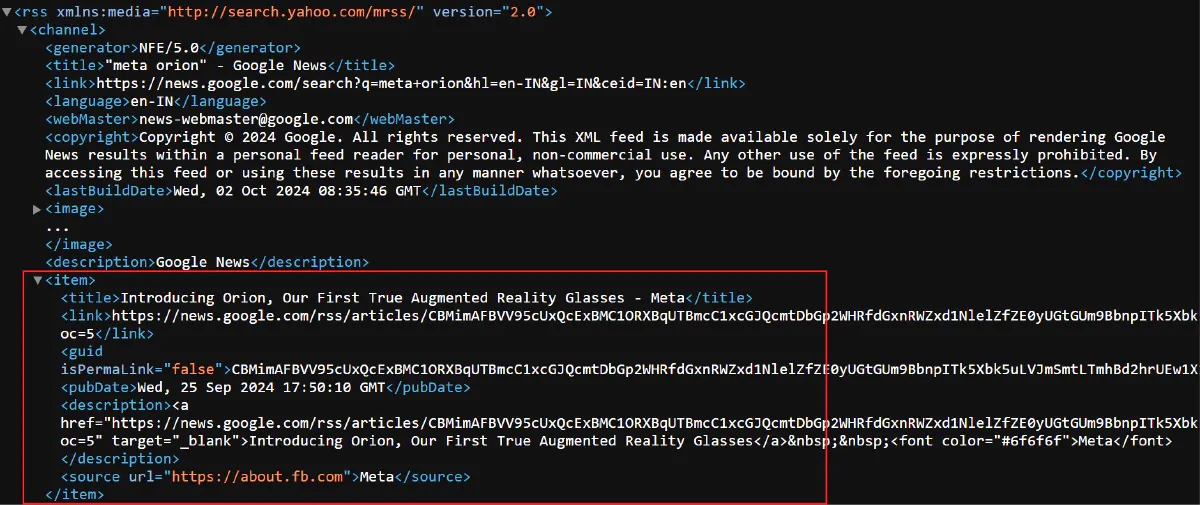
Now, for handling XML responses like RSS feeds, you can use Perl modules such as XML::Simple or XML::LibXML. First, take a look at the preview of a Google News RSS feed:
Here’s the code using XML::Simple to parse a Google News RSS feed and extract useful data like headlines and publication dates.
use LWP::UserAgent; # For fetching the RSS feed
use XML::Simple; # For parsing the XML content of the RSS feed
my $ua = LWP::UserAgent->new;
my $rss_url = 'https://news.google.com/rss/search?q=meta+orion&hl=en-IN&gl=IN&ceid=IN:en'; # URL of the RSS feed
my $response = $ua->get($rss_url); # Fetch the RSS feed
if ($response->is_success) {
my $xml_parser = XML::Simple->new; # Create a new XML::Simple object for parsing XML
my $data = $xml_parser->XMLin($response->decoded_content); # Parse the XML content of the RSS feed
foreach my $item (@{ $data->{channel}->{item} }) { # Loop through each item in the RSS feed
print "Article Title: " . $item->{title} . "\n";
print "Publication Date: " . $item->{pubDate} . "\n\n";
}
} else {
die "Failed to fetch RSS feed: " . $response->status_line;
}This code fetches XML data from the RSS feed, parses it into a Perl data structure, and extracts the article titles and publication dates. It uses XML::Simple to parse the XML and iterates through each item in the RSS feed to print the desired information.
The output looks like this:
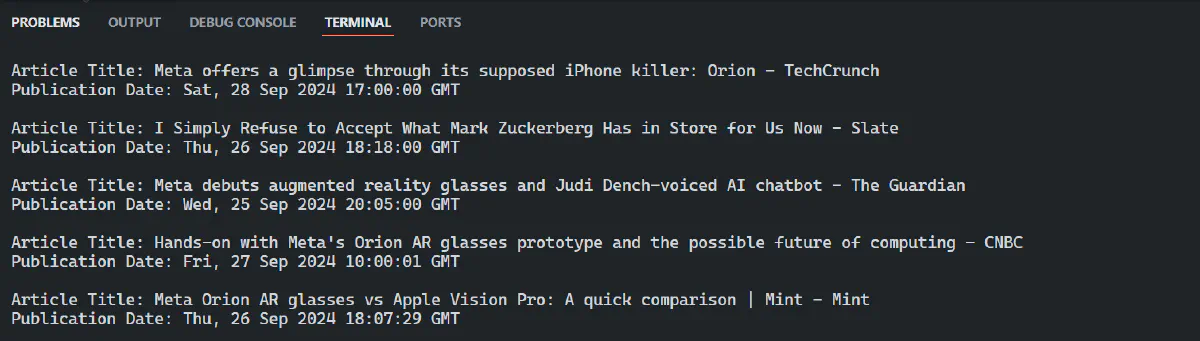
Great! The data looks clean and readable.
Rate Limiting and Proxy Support
When scraping websites, it's crucial to use strategies for rate limiting and proxy support to prevent being blocked. Many websites have restrictions on the number of requests allowed within a specific timeframe. Exceeding these limits can lead to temporary or permanent blocking of your IP address.
In Perl, you can handle rate limiting by introducing a delay (sleep) between requests using Time::HiRes to avoid overwhelming the server. Consider using a random delay within a reasonable range to mimic human behaviour.
Here's a code for adding a random delay between requests in Perl:
use LWP::UserAgent;
use Time::HiRes qw(sleep);
my $ua = LWP::UserAgent->new;
my @urls = (
'https://www.google.com',
'https://www.bing.com',
'https://www.duckduckgo.com'
);
foreach my $url (@urls) {
my $response = $ua->get($url);
if ($response->is_success) {
print "Fetched: $url\n";
} else {
print "Error fetching $url: " . $response->status_line . "\n";
}
# Sleep for a random time between 1 and 5 seconds
my $sleep_time = 1 + rand(4);
sleep($sleep_time);
}Next, proxies allow you to route your requests through different IP addresses. This helps distribute your scraping activities and avoid triggering IP-based blocks.
Here’s a basic proxy setup:
use LWP::UserAgent;
my $ua = LWP::UserAgent->new;
# Set up a proxy for both HTTP and HTTPS requests
$ua->proxy(['http', 'https'], 'http://10.10.1.11:3128');
# Example request through the proxy
my $response = $ua->get('https://www.randomuser.me/api');
if ($response->is_success) {
print "Response received: " . $response->decoded_content . "\n";
} else {
warn "Error: " . $response->status_line;
}To prevent being blocked by websites, it's important to rotate proxies for each request as many websites tend to block a single IP quickly. Before doing this, you must maintain a list of proxies and randomly select one for each request. Let's compile a list of free proxies from the Free Proxy List.
proxies = (
"198.50.251.188:8080",
"95.216.194.46:1080",
"134.122.58.174:3128",
"185.199.231.30:8080"
)Here’s a code of how to implement proxy rotation:
use strict;
use warnings;
use LWP::UserAgent;
use Time::HiRes qw(sleep);
# List of proxies to be used
my @proxies = (
'http://198.50.251.188:8080',
'http://95.216.194.46:1080',
'http://134.122.58.174:3128',
'http://185.199.231.30:8080',
);
my $ua = LWP::UserAgent->new;
# Iterate over each proxy in the list
foreach my $proxy (@proxies) {
# Set the proxy for the user agent
$ua->proxy(['http', 'https'], $proxy);
my $url = 'https://randomuser.me/api/';
# Introduce a delay before sending the request
sleep 3; # Sleep for 3 seconds
# Send a GET request through the proxy
my $response = $ua->get($url);
if ($response->is_success) {
print "Response received from $proxy: " . $response->decoded_content . "\n";
last;
} else {
warn "Error from $proxy: " . $response->status_line;
}
}Note that, free proxies are often unreliable and can quickly get blocked by websites with strong anti-scraping measures.
It's good to use a reliable premium proxy service. Best choices, such as Scrape.do's residential proxies, can help you access even the most secure websites. Scrape.do manages proxy rotation and helps you evade anti-bot systems, allowing you to focus on web scraping without concerns about being blocked.
Here's an example of using Scrape.do proxies in Perl:
use strict;
use warnings;
use LWP::UserAgent;
use IO::Socket::SSL;
my $ua = LWP::UserAgent->new();
# Set up the proxy with authentication
my $proxy = 'http://[email protected]:8080';
$ua->proxy(['http', 'https'], $proxy);
# Disable SSL verification to avoid the SSL error
$ua->ssl_opts(verify_hostname => 0, SSL_verify_mode => IO::Socket::SSL::SSL_VERIFY_NONE);
# URL to request
my $url = 'https://httpbin.co/ip';
# Send a GET request through the proxy
my $response = $ua->get($url);
if ($response->is_success) {
print "Response:\n";
print $response->decoded_content; # Print the IP address returned by httpbin.co
} else {
die "HTTP GET error: " . $response->status_line;
}The result is:
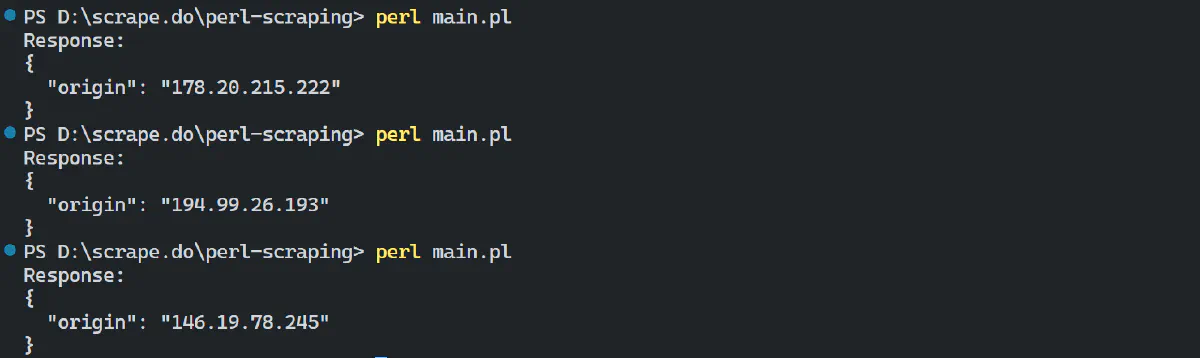
The output shows that Scrape.do proxies automatically handle proxy rotation. Each time you run the code, it uses a new residential proxy, which helps you scrape under the radar and avoid getting blocked.
Give it a try—sign up for free and get 1,000 API calls.
Error Handling and Robustness
Building resilient web scrapers involves implementing effective error handling and logging mechanisms. This ensures that your scraper can gracefully manage various types of errors and keeps a record of operations for debugging purposes.
When scraping websites, you'll encounter various errors, including timeouts, 404 errors (resource not found), and malformed responses. Using Try::Tiny, you can catch exceptions and manage them gracefully.
Here's an example of using Try::Tiny to handle different error types:
use LWP::UserAgent;
use Try::Tiny;
my $ua = LWP::UserAgent->new;
# Set a timeout for requests
$ua->timeout(10);
my $url = 'https://books.toscrape.com/';
try {
my $response = $ua->get($url);
if ($response->is_success) {
print "Response received: " . $response->decoded_content;
} else {
die "HTTP error: " . $response->status_line;
}
}
catch {
my $error = $_;
# Check if the error is due to a timeout
if ($error =~ /Timeout/) {
print "Request timed out. Retrying...\n";
# Implement retry logic here...
}
# Check if the error is due to a 404 HTTP error
elsif ($error =~ /HTTP error: 404/) {
print "Error 404: Resource not found.\n";
}
# Handle any other unexpected errors
else {
print "An unexpected error occurred: $error\n";
}
};Next, implement retry logic to recover from temporary issues like network timeouts. This allows your scraper to attempt a request multiple times before giving up. Here’s how you can integrate retry logic in your Perl scraper:
use LWP::UserAgent;
use Try::Tiny;
my $ua = LWP::UserAgent->new;
my $max_retries = 3; # Set maximum retries
my $url = 'https://ss.toscrape.com/';
# Retry logic to handle failed attempts
for my $attempt (1..$max_retries) {
try {
my $response = $ua->get($url);
if ($response->is_success) {
print "Response received: " . $response->decoded_content;
last;
} else {
die "HTTP error: " . $response->status_line;
}
}
catch {
my $error = $_;
warn "Attempt $attempt failed: $error\n";
# Check if the maximum number of retries has been reached
if ($attempt == $max_retries) {
die "Max retries reached. Exiting.\n";
}
# Implement exponential backoff for retries
sleep(2 ** $attempt); # Wait for 2^attempt seconds before the next attempt
};
}Next, logging allows you to track scraper execution, identify errors over time, and diagnose issues effectively. Log::Log4perl is a popular logging framework for Perl.
First, you need to install the Log::Log4perl module:
cpan Log::Log4perlHere's an example of setting up logging with Log::Log4perl:
use LWP::UserAgent;
use Try::Tiny;
use Log::Log4perl; # Install Log::Log4perl for logging capabilities
# Initialize logging for monitoring and error tracking
Log::Log4perl->init(\q(
log4perl.rootLogger = DEBUG, LOG1
log4perl.appender.LOG1 = Log::Log4perl::Appender::File
log4perl.appender.LOG1.filename = scraper.log
log4perl.appender.LOG1.layout = Log::Log4perl::Layout::PatternLayout
log4perl.appender.LOG1.layout.ConversionPattern = %d %p %m%n
));
# Get the logger instance for logging messages
my $logger = Log::Log4perl->get_logger();
my $ua = LWP::UserAgent->new;
my $url = 'https://books.toscrape.com/';
# Attempt to scrape the URL with a maximum of 3 retries
for my $attempt (1..3) {
try {
my $response = $ua->get($url);
if ($response->is_success) {
print "Response received: " . $response->decoded_content;
last;
} else {
# Log the HTTP error for monitoring and debugging
$logger->error("HTTP error: " . $response->status_line);
die "HTTP error: " . $response->status_line;
}
}
catch {
# Catch any errors that occur during the attempt
my $error = $_;
# Log the error for monitoring and debugging
$logger->warn("Attempt $attempt failed: $error");
# Check if the maximum number of retries has been reached
if ($attempt == 3) {
# Log the max retries error for monitoring and debugging
$logger->error("Max retries reached. Exiting.");
die "Max retries reached. Exiting.\n";
}
# Implement exponential backoff for retries to avoid overwhelming the server
sleep(2 ** $attempt); # Wait for 2^attempt seconds before the next attempt
};
}Log::Log4perl is configured to log messages to a file named scraper.log.
Handling CAPTCHA Challenges
CAPTCHAs are a common challenge in web scraping. However, you can bypass or solve these challenges by integrating third-party CAPTCHA-solving services.
Several CAPTCHA-solving services are available, relying on either human solvers or automated systems. Some popular options include 2Captcha, Death By Captcha, and CapSolver.
Here's a code example showing how to use the 2Captcha API. First, sign up on the 2Captcha website to get your API key.
use strict;
use warnings;
use LWP::UserAgent;
use JSON;
# Your 2Captcha API key
my $api_key = 'YOUR_2CAPTCHA_API_KEY';
my $ua = LWP::UserAgent->new;
# Step 1: Send the CAPTCHA for solving
my $captcha_image_url = 'URL_TO_YOUR_CAPTCHA_IMAGE'; # URL of the CAPTCHA image
my $response = $ua->post(
'https://2captcha.com/in.php',
{
key => $api_key,
method => 'url',
url => $captcha_image_url,
json => 1,
}
);
# Decode the response
my $result = decode_json($response->decoded_content);
if ($result->{status}) {
my $captcha_id = $result->{request};
# Step 2: Poll for the result
sleep(20); # Wait before checking for the result
my $solution_response;
do {
$solution_response = $ua->get(
"https://2captcha.com/res.php?key=$api_key&action=get&id=$captcha_id&json=1"
);
my $solution_result = decode_json($solution_response->decoded_content);
if ($solution_result->{status}) {
print "CAPTCHA solved: " . $solution_result->{request} . "\n";
last; # Exit loop if solved
} else {
print "Waiting for solution...\n";
sleep(5); # Wait before retrying
}
} while (1);
} else {
die "Error sending CAPTCHA: " . $result->{request};
}While CAPTCHA-solving services like 2Captcha are useful, they have limitations. They may not support all CAPTCHA types, and they can be slow or expensive when scaled. A more efficient solution is to use an advanced scraping API that bypasses CAPTCHA challenges effectively.
Scrape.do offers a more comprehensive anti-bot API solution. It provides all the tools required to bypass CAPTCHAs and any other anti-bot at scale regardless of CAPTCHA type and complexity, First, sign up for a free API key.
Here’s how to integrate Scrape.do API in Perl:
use LWP::UserAgent;
use URI;
# Define API token and target URL
my $token = "YOUR_API_TOKEN";
my $target_url = "https://www.g2.com/products/mysql/reviews";
# Base URL for the API
my $base_url = "http://api.scrape.do";
my $ua = LWP::UserAgent->new;
# Construct URI with query parameters for the API request
my $uri = URI->new($base_url);
$uri->query_form(
token => $token,
url => $target_url,
render => "true",
waitUntil => "domcontentloaded",
blockResources => "true",
geoCode => "us",
super => "true"
);
# Send GET request to the API
my $response = $ua->get($uri);
# Print the response status code and content
print "Status Code: " . $response->code . "\n";
print $response->content . "\n";When you execute this code, it bypasses CAPTCHAs and retrieves the HTML content from G2's review page.
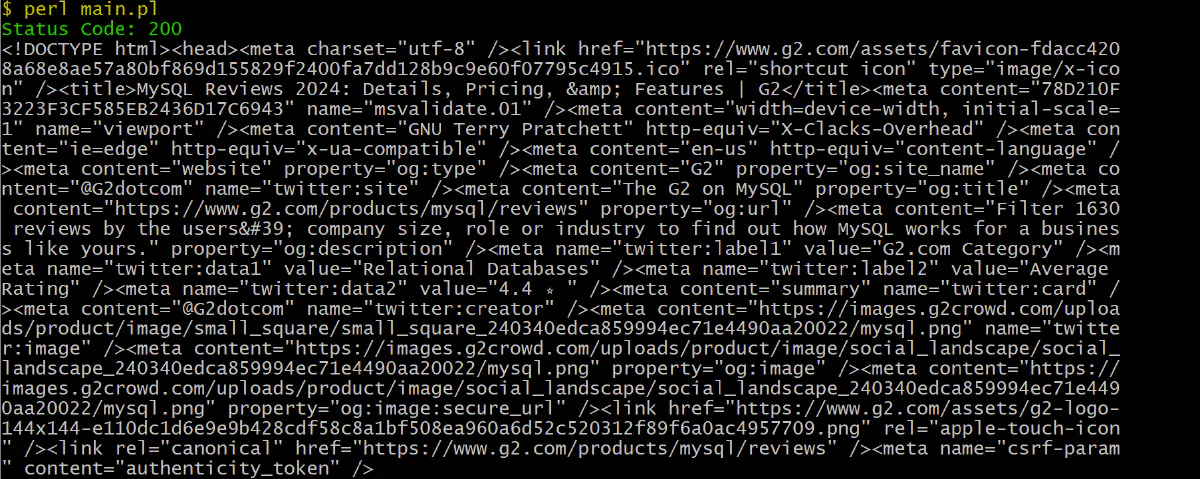
Yes, It’s that simple!
Best Practices for Ethical Web Scraping
When scraping websites, it is important to adhere to ethical practices to avoid legal and technical issues. Best practices include respecting the website's robots.txt file, limiting request rates, using proxies, and rotating user agents.
Let’s see!
The robots.txt file specifies the crawling guidelines for a website. It usually defines the pages that should not be indexed or crawled by bots. Adhering to these rules demonstrates ethical scraping and reduces the risk of being flagged as a bot. You can access the robots.txt file for any website by adding /robots.txt to its URL (e.g., https://www.amazon.com/robots.txt).
Here's an example of fetching and interpreting a robots.txt file in Perl:
use LWP::UserAgent;
my $ua = LWP::UserAgent->new;
# URL for the robots.txt file of Amazon
my $robots_url = 'https://www.amazon.com/robots.txt';
# fetch the robots.txt file
my $response = $ua->get($robots_url);
if ($response->is_success) {
# Get the content of the robots.txt file
my $robots_content = $response->decoded_content;
# Split the content into individual lines
my @lines = split /\n/, $robots_content;
foreach my $line (@lines) {
# Check if the line specifies a disallowed path
if ($line =~ /^Disallow:\s*(.*)/) {
my $disallowed_path = $1;
# Print the disallowed path
print "Disallowed path: $disallowed_path\n";
}
}
} else {
die "Failed to fetch robots.txt: " . $response->status_line;
}The result will show which pages are disallowed for web crawlers:
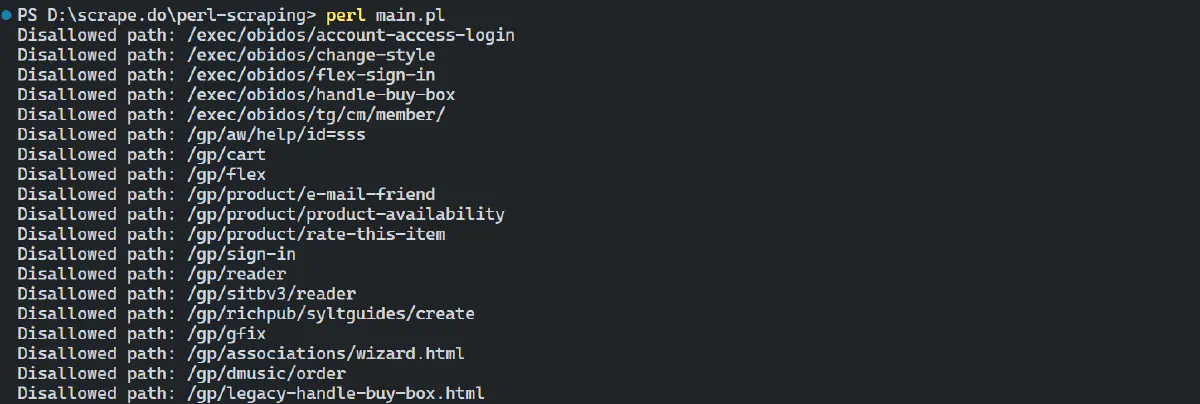
Next, to avoid getting blocked while scraping, also consider implementing the following strategies:
- Limit Request Rates: Avoid sending too many requests in a short period. Implement delays between requests to mimic human behaviour.
- Use Proxies: Use rotating proxies to distribute requests across multiple IP addresses, making it harder to identify and block you.
- User-Agent Rotation: Change your User-Agent string periodically to avoid detection as a bot. This makes your requests appear more like those from regular users.
Performance Optimization
To optimize the performance of your web scraper in Perl, you can use the AnyEvent::HTTP module. This module is an asynchronous HTTP client for Perl that allows you to perform non-blocking HTTP requests. By using it, you can initiate multiple requests without waiting for each one to complete before starting the next.
If you haven't already, install AnyEvent::HTTP using CPAN:
cpan AnyEvent AnyEvent::HTTPHere's an example showing how to use AnyEvent::HTTP to scrape multiple pages in parallel:
use AnyEvent;
use AnyEvent::HTTP;
use feature 'say';
use Time::HiRes qw(time);
# List of URLs to scrape
my @urls = (
'https://news.ycombinator.com/',
'https://news.ycombinator.com/news?p=2',
'https://news.ycombinator.com/news?p=3',
'https://news.ycombinator.com/news?p=4',
);
# Create a condition variable
my $cv = AnyEvent->condvar;
# Start time
my $start_time = time;
# Loop through each URL and send a request
foreach my $url (@urls) {
$cv->begin; # Increment the counter
# Asynchronous HTTP GET request
http_get $url, sub {
my ($body, $hdr) = @_;
if (defined $body) {
say "Fetched $url";
} else {
warn "Failed to fetch $url: $hdr->{Status} - $hdr->{Reason}";
}
$cv->end; # Decrement the counter
};
}
$cv->recv; # Wait until all requests are complete
# End time
my $end_time = time;
say "All requests completed in ", sprintf("%.2f", $end_time - $start_time), " seconds";The code uses AnyEvent->condvar to create a condition variable for managing asynchronous HTTP requests. The http_get function sends requests to specified URLs, with a callback to handle responses. Methods $cv->begin and $cv->end track ongoing requests, while $cv->recv waits for all to complete.
The output is:
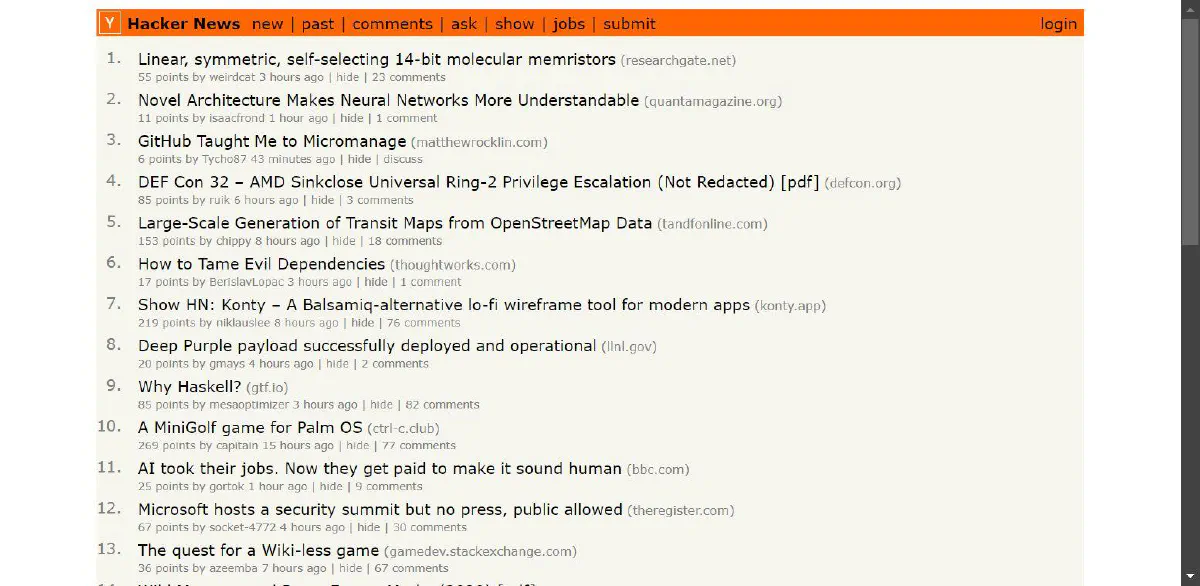
Nice, it successfully fetched URLs asynchronously.
Sending multiple requests simultaneously can greatly reduce the total time needed to scrape large datasets. This optimization is valuable for effectively managing more data in less time, maximizing available network resources, and improving throughput. Be sure to incorporate this approach into your project to boost performance!
Challenges of Web Scraping in Perl
Web scraping with Perl presents a major challenge due to the limited availability of libraries and tools. Although Perl does have libraries for web scraping, they may not be as comprehensive or as actively maintained as those available in other languages such as Python or JavaScript.
For those who are not familiar with Perl, mastering its syntax and the various modules required for effective scraping can be quite challenging.
Another significant challenge is dealing with anti-scraping mechanisms employed by websites to protect their data. While there are various techniques you can use, such as rotating proxies, randomizing user agents, using headless browsers, automating CAPTCHA solving, and varying request rates, these are often temporary solutions that may only work in limited scenarios.
A more robust alternative is Scrape.do, a tool designed to bypass anti-scraping measures, allowing you to focus on scraping the data you need without worrying about proxies, headless browsers, CAPTCHAs, and other challenges.
Let's see Scrape.do in action!
First, sign up to get your free Scrape.do API token from the dashboard.
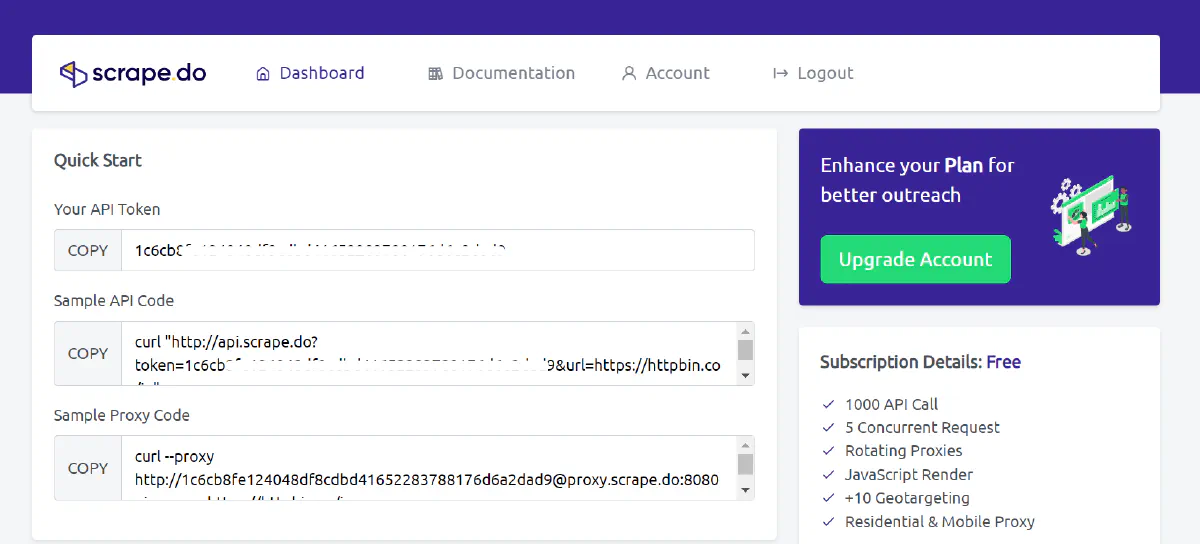
Great! With this token, you can make up to 1,000 API calls for free, with various features designed to help you avoid getting blocked.
Here’s how to get started using the Scrape.do web scraping API:
import requests
token = "YOUR_API_TOKEN"
target_url = "https://www.g2.com/products/anaconda/reviews"
# Base URL for the API
base_url = "http://api.scrape.do"
# Parameters for the request
params = {
"token": token,
"url": target_url, # The target URL to scrape
"render": "true", # Render the page
"waitUntil": "domcontentloaded", # Wait until the DOM is fully loaded
"blockResources": "true", # Block unnecessary resources from loading
"geoCode": "us", # Set the geolocation for the request
"super": "true" # Use Residential & Mobile Proxy Networks
}
# Making the GET request with parameters
response = requests.get(base_url, params=params)
print(f"Status Code: {response.status_code}")
print(response.text)Here’s the result:

Amazing! You've successfully bypassed a Cloudflare-protected website and scraped its full-page HTML using Scrape.do 🚀
Conclusion
This detailed guide covered important modules and techniques in Perl for scraping data from websites. It also explored advanced topics, such as dealing with JavaScript-heavy sites, and discussed methods for making scrapers faster and more efficient. The guide emphasized ethical behaviour, respecting website rules, error handling, and logging.
However, Perl has a limited ecosystem of scraping libraries and can be blocked by advanced anti-bot systems like G2, which use Cloudflare protection. You can overcome these challenges with Scrape.do, the best tool to scrape any website without getting blocked. Get started today with 1000 free credits.
Happy scraping!
Technical Writer








