Category:Scraping Use Cases
How to Scrape Grocery Delivery Data with Python (Basic to Advanced)

Full Stack Developer



Grocery delivery apps control billions in consumer spending data. Walmart, Uber Eats, DoorDash, and Instacart each process millions of orders monthly, adjusting prices by region, time of day, and local stock levels.
That data matters. Competitor pricing shifts hourly. Discounts appear and vanish based on inventory. Stock availability changes between zip codes within the same city.
If you're building price trackers, market intelligence tools, or competitive analysis dashboards, you need reliable access to that data.
But these platforms don't hand it over.
Anti-bot systems, geo-restrictions, address validation, and session-based access create layers of friction designed to stop automated extraction.
In this guide, we'll walk through scraping grocery delivery platforms from easiest to hardest, show you how to pull complete product catalogs, and demonstrate working Python code for each approach.
Why Scrape Grocery Delivery Data?
Raw delivery data unlocks operational insights that surface-level browsing can't provide.
Track Competitor Pricing and Launch Strategic Campaigns
Grocery platforms adjust prices based on demand, inventory levels, and competitor activity.
A product priced at $3.99 in one zip code might be $4.49 in another. Prices drop when stock ages, climb during peak hours, and shift when competitors run promotions.
If you're operating in this space, you need to know what competitors charge, how often they discount, and which SKUs they prioritize.
Automated scraping lets you track these changes across regions and time windows, feeding that data into pricing algorithms or promotional calendars.
Monitor Discount Patterns and Stock Availability
Discounts aren't random. Platforms push promotions on slow-moving inventory, seasonal items, or high-margin products.
By tracking which items go on sale, when discounts appear, and how long they last, you can reverse-engineer inventory strategies and predict when similar items will be discounted next.
Stock tracking adds another layer. Out-of-stock items signal supply issues, demand spikes, or distribution gaps. Monitoring availability across stores reveals which regions face shortages and which products move fastest.
Build Market Trend Reports and Demand Analysis
Aggregated delivery data shows market trends before they hit traditional retail analytics.
When a product category sees sudden growth across multiple platforms, that's a demand signal. When certain items consistently sell out in specific regions, that's a distribution opportunity.
Scraping delivery platforms at scale lets you build datasets that track:
- Category growth rates by region
- Emerging product trends before they saturate
- Price elasticity across different markets
- Seasonal demand patterns for specific SKUs
This isn't public data. Platforms don't publish it. But it's all visible if you know how to extract it.
Setup, Prerequisites, and Tools
Scraping grocery delivery platforms requires more than basic Python knowledge. You'll face session management, cookie handling, API payloads, and HTML parsing, sometimes all in the same scraper.
Do you need to be an expert? No.
Will it help to understand HTTP requests, JSON structure, and basic DOM traversal? Yes.
If you've built a few web scrapers before, you'll move faster. If not, start simple and work through each example methodically.
Tools and Libraries
We'll use three core Python libraries across every script in this guide:
requests sends HTTP requests and handles responses. It's the foundation for making API calls, submitting forms, and fetching HTML.
BeautifulSoup parses HTML and extracts elements based on tags, classes, and attributes. When data lives in the rendered DOM, this is how you pull it out.
csv (built-in) writes structured output to CSV files. After scraping, you'll want clean tabular data for analysis or storage.
Install the required packages:
pip install requests beautifulsoup4Some platforms require additional parsing tools like json or urllib.parse for encoding URLs and handling API payloads. We'll introduce those as needed.
Bypassing Anti-Bot Protections and Geo-Blocks
Grocery platforms don't block you because they're hostile to automation. They block you because automated traffic looks different from human traffic.
Headers mismatch. Request patterns repeat. TLS fingerprints don't align with real browsers. IP addresses cycle too fast or originate from known datacenter ranges.
You could build evasion logic yourself — rotating proxies, spoofing headers, managing sessions, solving CAPTCHAs — but that's weeks of work and constant maintenance as platforms update their defenses.
Or you route everything through Scrape.do.
Scrape.do handles proxy rotation, TLS fingerprint spoofing, session persistence, and CAPTCHA solving automatically. You send a request with your target URL, and Scrape.do returns clean HTML or rendered content.
Sign up for a free account and grab your API token from the dashboard:

You'll use this token in every request. Parameters like super=true enable premium proxies and header rotation. geoCode= sets your geo-location. render=true executes JavaScript when needed.
This removes the technical burden of bot evasion and lets you focus on extraction logic.
Options for Storage and Automation
Scraping once is testing. Scraping continuously is infrastructure.
For quick tests, dump results to JSON or CSV and analyze manually.
For production workflows, feed scraped data into a database. SQLite works for small datasets. PostgreSQL handles millions of rows with complex queries. MongoDB works if your schema varies across platforms.
To automate collection, schedule scrapers with cron jobs on Linux, Task Scheduler on Windows, or cloud-based tools like AWS Lambda or Google Cloud Scheduler.
For heavy processing, pipe data into Pandas for analysis or stream it to BigQuery for aggregation and reporting.
Don't wait until you have ten thousand rows to think about storage. Set up the right foundation now, even if it's just a local SQLite database.
Scraping Store Lists
Before you scrape products, you need stores. Every grocery platform organizes inventory by location, and most require you to set an address before showing any data.
The complexity of this step varies wildly depending on the platform.
Level 1: Uber Eats (Easiest)
Uber Eats is the simplest platform to scrape because location data travels inside the URL.
When you select a delivery address, Uber Eats encodes that location into the pl= parameter:
https://www.ubereats.com/feed?diningMode=DELIVERY&pl=JTdCJTIyYWRkcmVzcyUyMiUzQSUyMkNlbnRyYWwlMjBQYXJrJTIy...That pl value is a base64-encoded JSON object containing your address, latitude, longitude, and Google Maps place ID.
To scrape a different location, enter a new address on Uber Eats, refresh the page, copy the updated URL with the new pl value, and use it in your script.
No session management. No cookies. No backend calls.
The setup here is exactly the same as any other frontend scraping task.
We'll send a request to a JavaScript-heavy, location-specific Uber Eats feed URL, render it using Scrape.do's headless browser, and extract restaurant/store cards directly from the HTML.
Then, we'll teach Scrape.do to automatically click "Show more" so we can get the full list of results.
Uber Eats shows the first ~100 results on first load and then adds more only when you click the "Show more" button.
To collect the full list, we use Scrape.do's playWithBrowser feature to automate that button click repeatedly.
Here's the full interaction sequence:
import requests
import urllib.parse
import csv
import json
from bs4 import BeautifulSoup
# Scrape.do token
scrape_token = "<your-token>"
# Target UberEats feed URL (Central Park, NY)
ubereats_url = "https://www.ubereats.com/feed?diningMode=DELIVERY&pl=JTdCJTIyYWRkcmVzcyUyMiUzQSUyMkNlbnRyYWwlMjBQYXJrJTIyJTJDJTIycmVmZXJlbmNlJTIyJTNBJTIyQ2hJSjR6R0ZBWnBZd29rUkdVR3BoM01mMzdrJTIyJTJDJTIycmVmZXJlbmNlVHlwZSUyMiUzQSUyMmdvb2dsZV9wbGFjZXMlMjIlMkMlMjJsYXRpdHVkZSUyMiUzQTQwLjc4MjU1NDclMkMlMjJsb25naXR1ZGUlMjIlM0EtNzMuOTY1NTgzNCU3RA=="
# Browser automation sequence for scrape.do (clicks 'Show more' repeatedly)
play_with_browser = [
{"action": "WaitSelector", "timeout": 30000, "waitSelector": "button, div, span"},
{"action": "Execute", "execute": "(async()=>{let attempts=0;while(attempts<20){let btn=Array.from(document.querySelectorAll('button, div, span')).filter(e=>e.textContent.trim()==='Show more')[0];if(!btn)break;btn.scrollIntoView({behavior:'smooth'});btn.click();await new Promise(r=>setTimeout(r,1800));window.scrollTo(0,document.body.scrollHeight);await new Promise(r=>setTimeout(r,1200));attempts++;}})();"},
{"action": "Wait", "timeout": 3000}
]
# Prepare scrape.do API URL
jsonData = urllib.parse.quote_plus(json.dumps(play_with_browser))
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(ubereats_url)}"
f"&token={scrape_token}"
f"&super=true"
f"&render=true"
f"&playWithBrowser={jsonData}"
)
# Fetch the rendered UberEats page
response = requests.get(api_url)
# Parse the HTML with BeautifulSoup directly from response.text
soup = BeautifulSoup(response.text, "html.parser")
store_cards = soup.find_all('div', {'data-testid': 'store-card'})
# Helper to get first text from selectors
def get_first_text(element, selectors):
for sel in selectors:
found = element.select_one(sel)
if found and found.get_text(strip=True):
return found.get_text(strip=True)
return ''
# Extract store data
results = []
for card in store_cards:
a_tag = card.find('a', {'data-testid': 'store-card'})
href = a_tag['href'] if a_tag and a_tag.has_attr('href') else ''
h3 = a_tag.find('h3').get_text(strip=True) if a_tag and a_tag.find('h3') else ''
promo = ''
promo_div = card.select_one('div.ag.mv.mw.al.bh.af')
if not promo_div:
promo_div = card.find('span', {'data-baseweb': 'tag'})
if promo_div:
promo = ' '.join(promo_div.stripped_strings)
rating = get_first_text(card, [
'span.bo.ej.ds.ek.b1',
'span[title][class*=b1]'
])
review_count = ''
for span in card.find_all('span'):
txt = span.get_text(strip=True)
if txt.startswith('(') and txt.endswith(')'):
review_count = txt
break
if not review_count:
review_count = get_first_text(card, [
'span.bo.ej.bq.dt.nq.nr',
'span[class*=nq][class*=nr]'
])
results.append({
'href': href,
'name': h3,
'promotion': promo,
'rating': rating,
'review_count': review_count
})
# Write results to CSV
with open('ubereats_store_cards.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['href', 'name', 'promotion', 'rating', 'review_count']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in results:
writer.writerow(row)
print(f"Wrote {len(results)} store cards to ubereats_store_cards.csv")When we run this script, the terminal should print:
Wrote 223 store cards to ubereats_store_cards.csvAnd the CSV output looks like this:
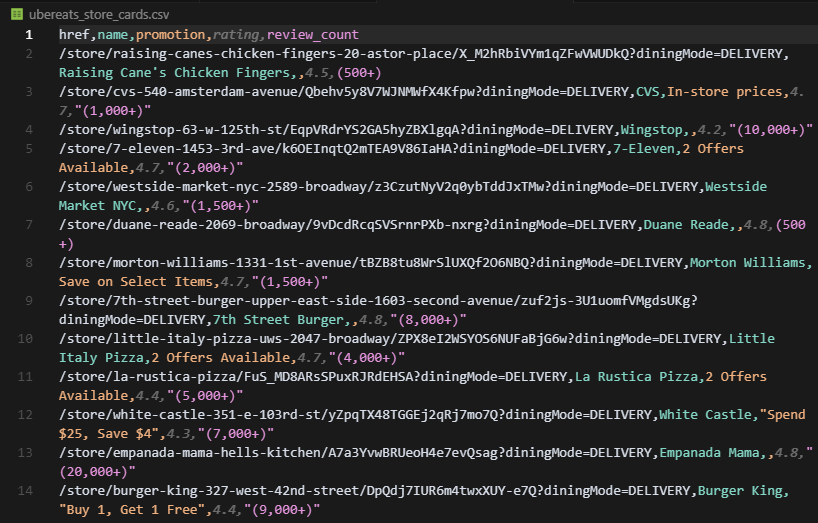
Uber Eats makes location-based scraping straightforward because the address lives in the URL, not in cookies or backend sessions.
Level 2: Walmart (Medium Difficulty)
Walmart doesn't encode your address in the URL. Instead, it stores location data in cookies.
Three cookies control what you see:
- ACID: account identifier
- locDataV3: location metadata
- locGuestData: guest session location
Without these, Walmart shows generic data or incomplete inventory.
Finding the Cookies in Your Browser
Open Walmart in Chrome, select a store from the top menu, then open Developer Tools → Application → Storage → Cookies. You'll see all active cookies for walmart.com.
The three we care about are highlighted here:
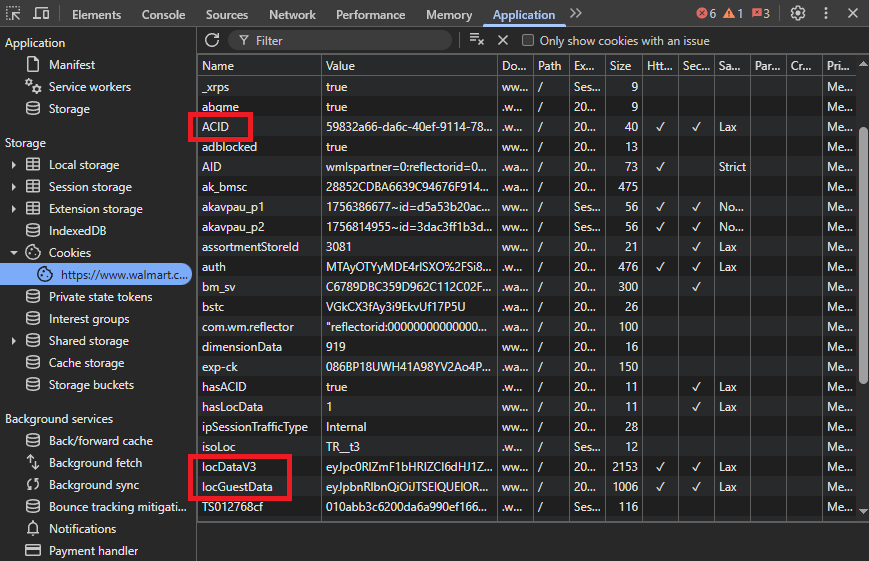
Each cookie has a long opaque value. Copy them exactly as-is, no spaces or line breaks.
Using Cookies in Requests
We'll send them via the sd-Cookie header when making Scrape.do requests. This is how Walmart knows your session is already locked to a store.
Example configuration:
headers = {
"sd-Cookie": "ACID=...; locDataV3=...; locGuestData=...",
"sd-User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)..."
}Attach these headers in every request you send to Scrape.do. If the cookies expire or if you want to get cookies for a different store, grab a new set from DevTools and replace them.
But there's an easier way.
Scrape.do makes store selection much easier with its new Walmart plugin.
Instead of manually extracting cookies, you can set a store location with just two parameters: zipcode and storeid.
Here's how the plugin works:
Regular Scrape.do API call:
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&super=true&geoCode=us&render=true"With Walmart plugin and a store selected:
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}"The plugin automatically handles all the cookie management, session persistence, and store selection that you'd normally have to do manually.
Finding Your Store ID
To use the plugin, you need two pieces of information: your zip code (easy) and the store ID (requires a quick lookup).
Here's how to find the store ID:
Visit Walmart.com and click the "Pickup or delivery?" dropdown
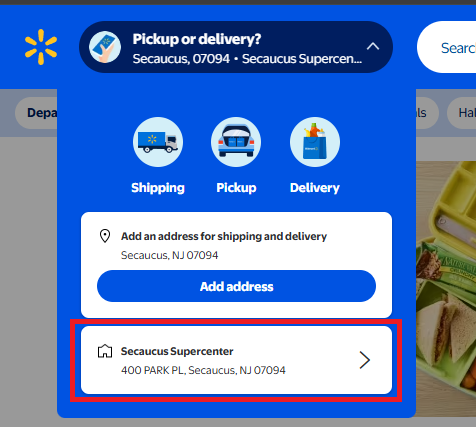
Enter your zip code and select your preferred store
Click on "Store details" for your selected store
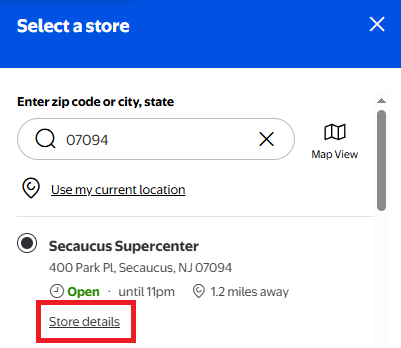
This takes you to a URL like
https://www.walmart.com/store/3520-secaucus-njThe store ID is the number at the beginning:
3520
For our examples, we'll use the Secaucus Supercenter (Store ID: 3520, Zip: 07094).
The plugin approach saves you from manually extracting cookies from DevTools, managing cookie expiration, handling session persistence, and dealing with store-specific cookie chains.
We'll use the Scrape.do Walmart plugin for all our code examples going forward.
Level 3: DoorDash (Most Complex)
DoorDash requires the most setup because address validation happens entirely through backend API calls.
You can't set an address via URL parameters or cookies. You must submit it through a GraphQL mutation that registers the address to your session.
Here's how that works.
When you enter an address on DoorDash, your browser sends a POST request to:
https://www.doordash.com/graphql/addConsumerAddressV2?operation=addConsumerAddressV2This is a POST request which means instead of just fetching data, it's sending data to the server to register your address with your session.
To view and copy the payload:
Right-click and Inspect before visiting the DoorDash homepage or any page of the website. Open the Network tab in the developer tools that pop up and make sure Preserve log option in the top toolbar is checked.
Pick an address (preferably somewhere DoorDash is available in) and then save it.
Now, your browser will send the POST request we just talked about. Once the new page loads, search for addConsumerAddress... from the top toolbar. Here's what you should be able to see:
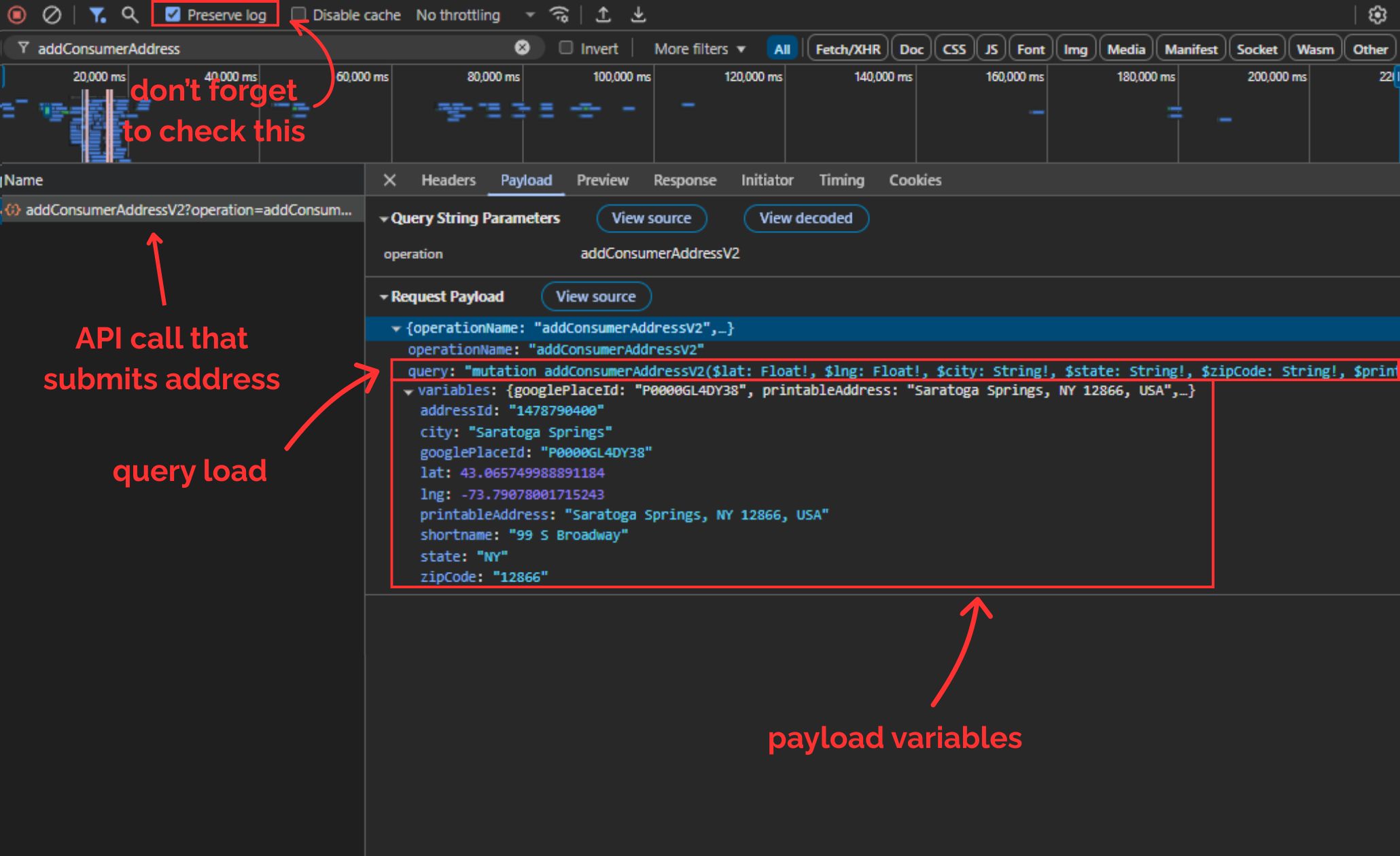
DoorDash uses a system called GraphQL, which always sends two things in the payload:
query: a big string that defines what operation to run (in this case,addConsumerAddressV2)variables: a JSON object containing all the real values (latitude, longitude, city, zip, etc.)
We'll now send the exact same POST request that the browser sends, but from Python.
Here's the full structure:
import requests
import json
# Scrape.do API token and target URL
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/addConsumerAddressV2?operation=addConsumerAddressV2"
# Scrape.do API endpoint
api_url = (
"http://api.scrape.do/?"
f"token={TOKEN}"
f"&super=true"
f"&url={requests.utils.quote(TARGET_URL)}"
)
payload = {
"query": """
mutation addConsumerAddressV2(
$lat: Float!, $lng: Float!, $city: String!, $state: String!, $zipCode: String!,
$printableAddress: String!, $shortname: String!, $googlePlaceId: String!,
$subpremise: String, $driverInstructions: String, $dropoffOptionId: String,
$manualLat: Float, $manualLng: Float, $addressLinkType: AddressLinkType,
$buildingName: String, $entryCode: String, $personalAddressLabel: PersonalAddressLabelInput,
$addressId: String
) {
addConsumerAddressV2(
lat: $lat, lng: $lng, city: $city, state: $state, zipCode: $zipCode,
printableAddress: $printableAddress, shortname: $shortname, googlePlaceId: $googlePlaceId,
subpremise: $subpremise, driverInstructions: $driverInstructions, dropoffOptionId: $dropoffOptionId,
manualLat: $manualLat, manualLng: $manualLng, addressLinkType: $addressLinkType,
buildingName: $buildingName, entryCode: $entryCode, personalAddressLabel: $personalAddressLabel,
addressId: $addressId
) {
defaultAddress {
id
addressId
street
city
subpremise
state
zipCode
country
countryCode
lat
lng
districtId
manualLat
manualLng
timezone
shortname
printableAddress
driverInstructions
buildingName
entryCode
addressLinkType
formattedAddressSegmentedList
formattedAddressSegmentedNonUserEditableFieldsList
__typename
}
availableAddresses {
id
addressId
street
city
subpremise
state
zipCode
country
countryCode
lat
lng
districtId
manualLat
manualLng
timezone
shortname
printableAddress
driverInstructions
buildingName
entryCode
addressLinkType
formattedAddressSegmentedList
formattedAddressSegmentedNonUserEditableFieldsList
__typename
}
id
userId
timezone
firstName
lastName
email
marketId
phoneNumber
defaultCountry
isGuest
scheduledDeliveryTime
__typename
}
}
""",
"variables": {
"googlePlaceId": "D000PIWKXDWA",
"printableAddress": "99 S Broadway, Saratoga Springs, NY 12866, USA",
"lat": 43.065749988891184,
"lng": -73.79078001715243,
"city": "Saratoga Springs",
"state": "NY",
"zipCode": "12866",
"shortname": "National Museum Of Dance",
"addressId": "1472738929",
"subpremise": "",
"driverInstructions": "",
"dropoffOptionId": "2",
"addressLinkType": "ADDRESS_LINK_TYPE_UNSPECIFIED",
"entryCode": ""
}
}
response = requests.post(api_url, data=json.dumps(payload))
scrape_do_rid = response.headers.get("scrape.do-rid")
print(f"scrape.do-rid: {scrape_do_rid}")scrape.do-rid value identifies your session that's created in Scrape.do's cloud, and if the post request was successful this session will have the address we sent through the payload registered, giving us access to DoorDash.
The response should look like this:
scrape.do-rid: 4f699c-40-0-459851;To keep using this session, we only need the last 6 digits (e.g. 459851) and we'll need to carry that forward in every future request.
Now you can scrape store listings for that address by sending requests to DoorDash's homePageFacetFeed endpoint using that session ID.
Here's an example showing the complete flow with pagination:
import requests
import json
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/homePageFacetFeed?operation=homePageFacetFeed"
SESSION_ID = "459851" # Last 6 digits from previous step
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={TARGET_URL}&sessionId={SESSION_ID}"
# Initial cursor from DevTools inspection
cursor = "eyJvZmZzZXQiOjAsInZlcnRpY2FsX2lkcyI6WzEwMDMzMywzLDIsMyw3MCwxMDMsMTM5LDE0NiwxMzYsMjM1LDI2OCwyNDEsMjM2LDIzOSw0LDIzOCwyNDMsMjgyXSwicm9zc192ZXJ0aWNhbF9wYWdlX3R5cGUiOiJIT01FUEFHRSIsInBhZ2Vfc3RhY2tfdHJhY2UiOltdLCJsYXlvdXRfb3ZlcnJpZGUiOiJVTlNQRUNJRklFRCIsImlzX3BhZ2luYXRpb25fZmFsbGJhY2siOm51bGwsInNvdXJjZV9wYWdlX3R5cGUiOm51bGwsInZlcnRpY2FsX25hbWVzIjp7fX0="
stores = []
while cursor:
payload = {
"query": "<full-graphql-query>", # Copy from DevTools
"variables": {
"cursor": cursor,
"filterQuery": "",
"displayHeader": True,
"isDebug": False
}
}
response = requests.post(API_URL, data=json.dumps(payload))
data = response.json()
feed = data.get("data", {}).get("homePageFacetFeed", {})
sections = feed.get("body", [])
store_feed = next((s for s in sections if s.get("id") == "store_feed"), None)
if not store_feed:
break
for entry in store_feed.get("body", []):
if not entry.get("id", "").startswith("row.store:"):
continue
text = entry.get("text", {})
name = text.get("title", "")
stores.append({"name": name})
page_info = feed.get("page", {})
next_data = page_info.get("next", {}).get("data")
cursor = json.loads(next_data).get("cursor") if next_data else None
print(f"Extracted {len(stores)} stores")This loops through every page of store listings until DoorDash stops returning a cursor.
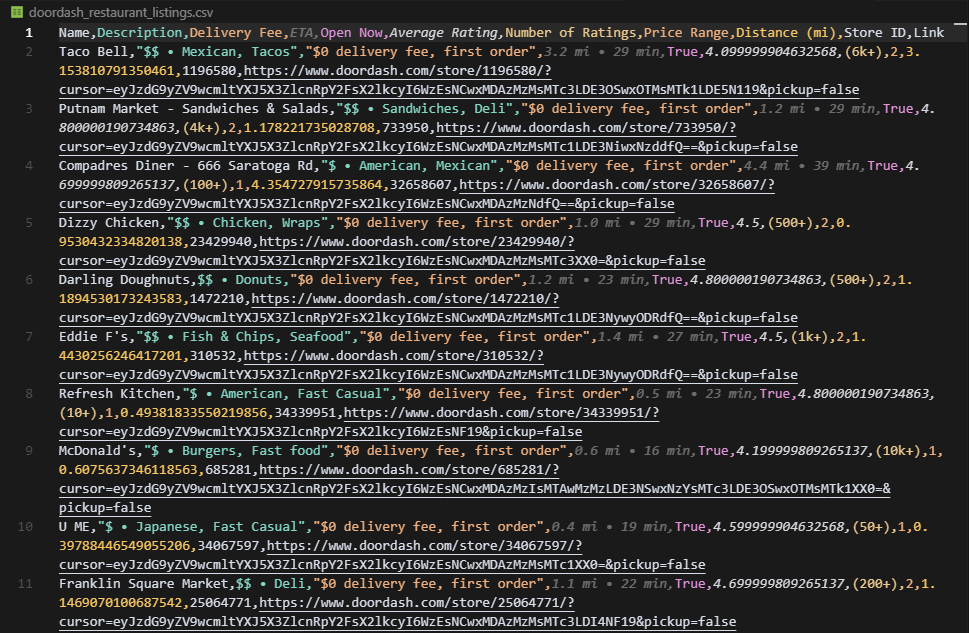
DoorDash is the most complex platform because it requires backend address submission via GraphQL, session ID extraction and persistence, and cursor-based pagination through API responses.
But once you understand the flow, you can scrape any location by changing the address variables in the initial mutation.
Scraping All Products from a Store
Store listings tell you what's available. Product catalogs tell you what's inside.
Most platforms organize inventory by category. To scrape a complete catalog, you fetch each category individually and stitch them together.
We'll show two approaches: scraping the frontend (Walmart) and hitting the backend API (Uber Eats).
Frontend Approach: Walmart
Walmart renders product tiles directly in the HTML, making it scrapable without API calls.
Each category page lists products in a grid. Pagination happens via URL parameters like ?page=2.
When scraping Walmart categories, pagination can trigger bot defenses.
If you try to hit ?page=2 directly without context, Walmart treats it as suspicious traffic. The workaround is to always send a referer header that points to the previous page.
Here's the complete setup:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
import time
# Scrape.do token
TOKEN = "<your-token>"
# Walmart category page (example: deli meats & cheeses)
target_url = "https://www.walmart.com/browse/food/shop-all-deli-sliced-meats-cheeses/976759_976789_5428795_9084734"
# Store info for Secaucus Supercenter
ZIPCODE = "07094"
STORE_ID = "3520"
def fetch_page(url, previous_url):
headers = {
"sd-User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"sd-Referer": previous_url
}
encoded_url = urllib.parse.quote(url)
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode={ZIPCODE}&storeid={STORE_ID}&url={encoded_url}&super=true&geoCode=us&extraHeaders=true&render=true&customWait=5000&blockResources=false"
response = requests.get(api_url, headers=headers)
response.raise_for_status()
return response.text
def parse_products(html):
soup = BeautifulSoup(html, "html.parser")
products = []
for tile in soup.select("[data-dca-name='ui_product_tile:vertical_index']"):
product = {}
# Name
name_tag = tile.select_one("span", {"data-automation-id": "product-title"}).get_text(strip=True)
product["Name"] = name_tag.split("$")[0] if "$" in name_tag else name_tag
# Link
link_tag = tile.select_one("a", href=True)
if link_tag:
href = link_tag["href"]
if href.startswith("/"):
href = "https://www.walmart.com" + href
product["Link"] = href
else:
product["Link"] = ""
# Image
img_tag = tile.select_one("img", {"data-testid": "productTileImage"})
product["Image"] = img_tag["src"] if img_tag and img_tag.has_attr("src") else ""
# Price
price_tag = tile.find("div", {"data-automation-id": "product-price"})
price_section = price_tag.find("span", {"class": "w_iUH7"}) if price_tag else None
product["Price"] = "$" + price_section.get_text(strip=True).split("$")[1].split(" ")[0] if price_section else ""
# Reviews & rating
review_count_tag = tile.select_one('span[data-testid="product-reviews"]')
product["ReviewCount"] = review_count_tag.get("data-value") if review_count_tag else None
product["Rating"] = ""
if review_count_tag:
next_span = review_count_tag.find_next_sibling("span")
if next_span:
product["Rating"] = next_span.get_text(strip=True).split(" ")[0]
products.append(product)
return products
def scrape_category(base_url, max_pages=50, delay=1.5):
all_products = []
seen_images = set() # track unique product images across pages
page = 1
while page <= max_pages:
if page == 1:
html = fetch_page(base_url, base_url)
elif page == 2:
html = fetch_page(f"{base_url}?page=2", base_url)
else:
html = fetch_page(f"{base_url}?page={page}", f"{base_url}?page={page-1}")
products = parse_products(html)
if not products:
print(f"No products found on page {page}. Stopping.")
break
new_count = 0
for prod in products:
img = prod.get("Image")
if img and img not in seen_images:
seen_images.add(img)
all_products.append(prod)
new_count += 1
else:
print(f"Duplicate skipped: {prod.get('Name')}")
print(f"Page {page}: extracted {new_count} new products (total {len(all_products)})")
page += 1
time.sleep(delay) # polite delay
return all_products
# Run scraper and save output
rows = scrape_category(target_url, max_pages=20)
with open("walmart_category.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["Name", "Price", "Link", "Image", "Rating", "ReviewCount"])
writer.writeheader()
writer.writerows(rows)
print(f"Extracted {len(rows)} products to walmart_category.csv")This will successfully extract all items from the category without duplicates:
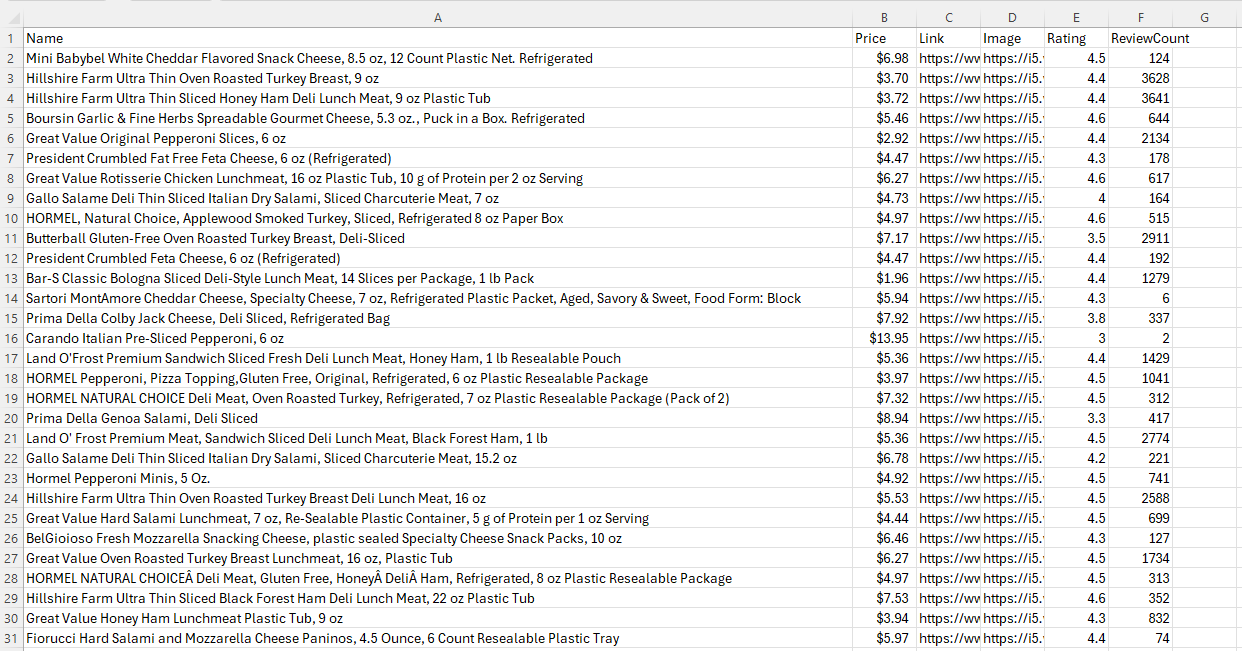
The customWait=5000 parameter gives Walmart time to load dynamic elements before Scrape.do captures the page.
Backend Approach: Uber Eats
Uber Eats doesn't render full product catalogs in the frontend. Instead, it loads category data through a backend API: getCatalogPresentationV2.
This endpoint returns paginated JSON with product details, prices, and availability.
Chain stores in Uber Eats will hold thousands of items in tens of different categories, which can provide a lot of valuable data for your data project.
However, this abundance makes it impossible to scrape all items in one go like we did with restaurants.
Instead, we have to scrape every category one by one and stitch outputs together to create the entire catalog.
For this, we're calling getCatalogPresentationV2, the same internal API Uber Eats uses to load all menu items when a user opens a category inside a store.
For this, we're not passing a place ID. Instead, the payload now includes:
- The
storeUuid(Uber's internal ID for the restaurant or merchant) - One or more
sectionUuids(which represent categories like "Drinks", "Home Care", "Food")
Your cookie still matters; Uber tailors the catalog data (prices, stock, promos) to your location. So we reuse the exact same uev2.loc=... cookie and headers from the previous section.
We start by importing the necessary libraries as always and creating a few inputs:
import requests
import urllib.parse
import json
import csv
# Scrape.do token
scrape_token = "<your-token>"
store_uuid = "41b7a1bf-9cbc-57b5-8934-c59f5f829fa7"
section_uuids = ["63eaa833-9345-41dd-9af5-2d7da547f6da"]The inputs we defined are the store UUID and the section UUIDs. These two values control which restaurant and which category we're scraping from.
You don't need to dig into DevTools to find them, Uber Eats includes both directly in the URL when you open a category.
This is the URL of the Drinks category of a 7-Eleven in Brooklyn for example:
https://www.ubereats.com/store/7-eleven-1453-3rd-ave/k6OEInqtQ2mTEA9V86IaHA/41b7a1bf-9cbc-57b5-8934-c59f5f829fa7/63eaa833-9345-41dd-9af5-2d7da547f6daIn the URL:
41b7a1bf-9cbc-57b5-8934-c59f5f829fa7is thestoreUuid63eaa833-9345-41dd-9af5-2d7da547f6dais thesectionUuid
Copy and paste those into your script, and you're ready to go.
Next, we set up the request:
catalog_url = "https://www.ubereats.com/_p/api/getCatalogPresentationV2"
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(catalog_url)}"
f"&token={scrape_token}"
f"&extraHeaders=true"
f"&super=true"
f"&geoCode=us"
)Just like earlier sections, we're using extraHeaders=true and prefixing each custom header with sd- so Scrape.do injects them directly into the session.
headers = {
"sd-cookie": "uev2.loc={%22address%22:{%22address1%22:%22Central%20Park%22...}",
"sd-content-type": "application/json",
"sd-x-csrf-token": "x",
"sd-x-uber-client-gitref": "x"
}Now for pagination setup and the complete code:
# Pagination logic
all_results = []
offset = 0
has_more = True
first = True
while has_more:
# Variant 1: with sectionTypes
payload_with_section_types = json.dumps({
"sortAndFilters": None,
"storeFilters": {
"storeUuid": store_uuid,
"sectionUuids": section_uuids,
"subsectionUuids": None,
"sectionTypes": ["COLLECTION"]
},
"pagingInfo": {"enabled": True, "offset": offset},
"source": "NV_L2_CATALOG"
})
# Variant 2: without sectionTypes
payload_without_section_types = json.dumps({
"sortAndFilters": None,
"storeFilters": {
"storeUuid": store_uuid,
"sectionUuids": section_uuids,
"subsectionUuids": None
},
"pagingInfo": {"enabled": True, "offset": offset},
"source": "NV_L2_CATALOG"
})
if first:
print("Requesting first items")
first = False
else:
print(f"Requesting next items (offset={offset})")
# Try with sectionTypes
response = requests.post(api_url, data=payload_with_section_types, headers=headers)
data = response.json()
catalogs = data.get("data", {}).get("catalog", [])
results = []
for section in catalogs:
items = section.get("payload", {}).get("standardItemsPayload", {}).get("catalogItems", [])
for item in items:
price_cents = item.get("price")
price = f"{price_cents / 100:.2f}" if price_cents is not None else ""
results.append({
"uuid": item.get("uuid"),
"title": item.get("title"),
"description": item.get("titleBadge", {}).get("text", ""),
"price": price,
"imageUrl": item.get("imageUrl"),
"isAvailable": item.get("isAvailable"),
"isSoldOut": item.get("isSoldOut"),
"sectionUuid": item.get("sectionUuid"),
"productUuid": item.get("productInfo", {}).get("productUuid", "")
})
if results:
variant_used = "with sectionTypes"
else:
# Try without sectionTypes
response = requests.post(api_url, data=payload_without_section_types, headers=headers)
data = response.json()
catalogs = data.get("data", {}).get("catalog", [])
results = []
for section in catalogs:
items = section.get("payload", {}).get("standardItemsPayload", {}).get("catalogItems", [])
for item in items:
price_cents = item.get("price")
price = f"{price_cents / 100:.2f}" if price_cents is not None else ""
results.append({
"uuid": item.get("uuid"),
"title": item.get("title"),
"description": item.get("titleBadge", {}).get("text", ""),
"price": price,
"imageUrl": item.get("imageUrl"),
"isAvailable": item.get("isAvailable"),
"isSoldOut": item.get("isSoldOut"),
"sectionUuid": item.get("sectionUuid"),
"productUuid": item.get("productInfo", {}).get("productUuid", "")
})
variant_used = "without sectionTypes" if results else None
all_results.extend(results)
has_more = data.get("data", {}).get("meta", {}).get("hasMore", False)
if variant_used:
print(f"Fetched {len(results)} items using {variant_used}, total so far: {len(all_results)}")
else:
print("No more items returned, breaking loop.")
break
offset += len(results)
# Write results to CSV
with open("catalog_items.csv", "w", newline='', encoding="utf-8") as csvfile:
fieldnames = ["uuid", "title", "description", "price", "imageUrl", "isAvailable", "isSoldOut", "sectionUuid", "productUuid"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in all_results:
writer.writerow(row)
print(f"Wrote {len(all_results)} items to catalog_items.csv")The output will look like this:
Wrote 277 items to catalog_items.csvAnd this is the final result:
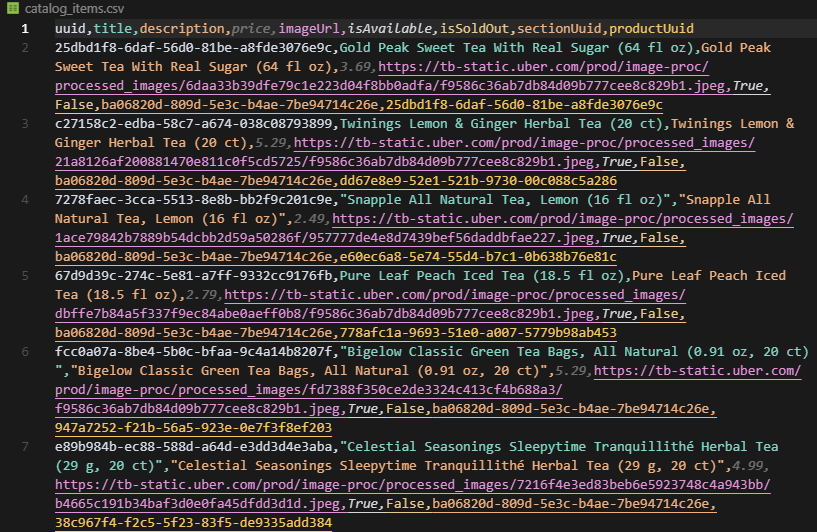
The backend approach is clean, fast, and avoids all the rendering issues from scraping the frontend.
Conclusion
Grocery delivery platforms don't advertise their data, but it's accessible if you understand how they structure sessions, validate addresses, and paginate results.
Uber Eats is the easiest because location data lives in the URL. Walmart requires cookies but offers a plugin for automatic store selection. DoorDash demands backend GraphQL calls and session persistence.
With Scrape.do handling proxies, rendering, and anti-bot defenses, you can fetch store lists, menus, and full catalog data reliably.
Full Stack Developer








