Category:Scraping Use Cases
Uber Eats Scraping: Extract Store Listings and Menus

Founder @ Scrape.do


Uber Eats won’t show you anything unless JavaScript is enabled.
Open any restaurant page with requests and you’ll hit a blank screen asking you to turn on JS:
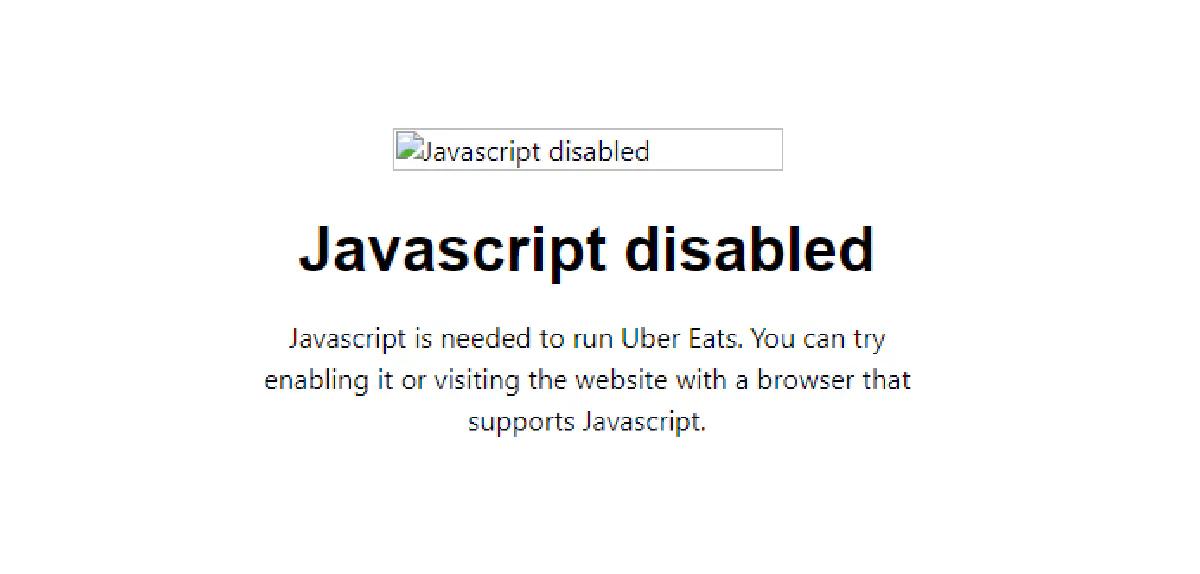
Uber Eats relies on dynamic rendering, session-bound APIs, and frontend GraphQL endpoints that don’t respond unless you're behaving like a real browser.
But once you break through, you can extract:
- Restaurant menus with item names, prices, and descriptions
- Store and restaurant listings by area
- Full category data from the backend for chain stores
In this guide, we’ll walk through each of those step-by-step.
Find all working code in this GitHub repository ⚙
We’ll use Python and Scrape.do to bypass blocks and get structured data—no browser setup, no proxy headaches.
Scrape Restaurant Menus from Uber Eats
Let's start easy.
Once you use a headless browser or Scrape.do's render parameter, all menu items along with their categories and prices are available in the DOM on restaurant pages.
No need to set an address or submit anything through the backend API.
We'll scrape the menu of this Popeyes franchise in Brooklyn for this section.
We’ll use Scrape.do’s headless browser rendering to get the full page, then parse it with BeautifulSoup just like any static HTML. Let's go:
Setup
You’ll need a few basic Python libraries:
pip install requests beautifulsoup4We’ll use:
requeststo send the API call through Scrape.doBeautifulSoupto parse the rendered HTML and extract the menucsvto save the output in a clean, structured format
Next, grab your Scrape.do API token:
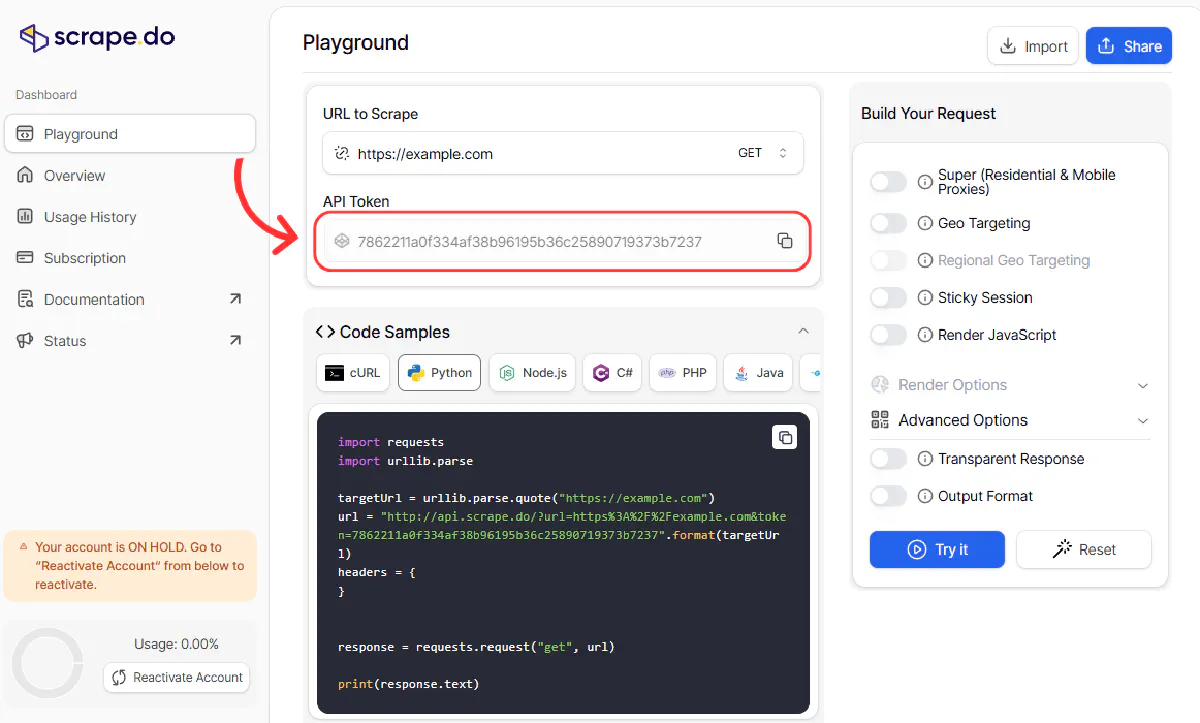
You’ll use this token to authenticate every request. The super=true and render=true parameters will make sure we bypass anti-bot checks and render JavaScript.
Parameters and Building the Request
Uber Eats won’t return any useful content unless JavaScript is rendered and some wait time is allowed for dynamic elements to load.
Here’s how we build the request:
import requests
import urllib.parse
scrape_token = "<your-token>"
ubereats_restaurant_url = "https://www.ubereats.com/store/popeyes-east-harlem/H6RO8zvyQ1CxgJ7VH350pA?diningMode=DELIVERY"
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(ubereats_restaurant_url)}"
f"&token={scrape_token}"
f"&super=true"
f"&render=true"
f"&customWait=5000"
)Let’s break that down:
url: the Uber Eats restaurant page you want to scrapetoken: your Scrape.do API keysuper=true: enables premium proxy and header rotation (required to bypass Uber’s bot filters)render=true: turns on headless browser rendering to load JavaScriptcustomWait=5000: waits 5 seconds after page load to make sure the menu is rendered in full
Finally, we send the request and parse the result:
response = requests.get(api_url)At this point, response.text contains the fully rendered HTML of the restaurant page.
Extracting Menu Items
Once we have the rendered HTML, we can parse it like any other static page using BeautifulSoup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")Each menu section (like “Chicken Sandwiches” or “Sides”) is wrapped in a div with:
data-testid="store-catalog-section-vertical-grid"We’ll use that to find all categories:
for section in soup.find_all('div', {'data-testid': 'store-catalog-section-vertical-grid'}):
cat_h3 = section.find('h3')
category = cat_h3.get_text(strip=True) if cat_h3 else ''Then we go deeper.
Each item in a section is inside an li tag where the data-testid starts with store-item-. We use this pattern to filter out unrelated elements:
for item in section.find_all('li', {'data-testid': True}):
if not item['data-testid'].startswith('store-item-'):
continueInside each item block, Uber Eats renders name and price using a few <span> tags with data-testid="rich-text", we're only interested in the first two:
rich_texts = item.find_all('span', {'data-testid': 'rich-text'})
if len(rich_texts) < 2:
continue
name = rich_texts[0].get_text(strip=True)
price = rich_texts[1].get_text(strip=True)Then we save each item as a dictionary, grouped under its menu category:
results.append({
'category': category,
'name': name,
'price': price
})Once this loop runs, results will hold the full structured menu from the restaurant page.
Export to CSV
With all items collected in the results list, we can write them to a CSV file using Python’s built-in csv module.
Here's the full code with the exporting section added:
import requests
import urllib.parse
import json
from bs4 import BeautifulSoup
import csv
# Scrape.do token
scrape_token = "<your-token>"
# Target UberEats restaurant URL
ubereats_restaurant_url = "https://www.ubereats.com/store/popeyes-east-harlem/H6RO8zvyQ1CxgJ7VH350pA?diningMode=DELIVERY&ps=1&surfaceName="
# Prepare scrape.do API URL (with custom wait)
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(ubereats_restaurant_url)}"
f"&token={scrape_token}"
f"&super=true"
f"&render=true"
f"&customWait=5000"
)
# Fetch the rendered UberEats restaurant page
response = requests.get(api_url)
# Parse the HTML with BeautifulSoup directly from response.text
soup = BeautifulSoup(response.text, "html.parser")
# Extract menu items: category, name, price
results = []
for section in soup.find_all('div', {'data-testid': 'store-catalog-section-vertical-grid'}):
cat_h3 = section.find('h3')
category = cat_h3.get_text(strip=True) if cat_h3 else ''
for item in section.find_all('li', {'data-testid': True}):
if not item['data-testid'].startswith('store-item-'):
continue
rich_texts = item.find_all('span', {'data-testid': 'rich-text'})
if len(rich_texts) < 2:
continue
name = rich_texts[0].get_text(strip=True)
price = rich_texts[1].get_text(strip=True)
results.append({
'category': category,
'name': name,
'price': price
})
# Write results to CSV
with open('ubereats_restaurant_menu.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['category', 'name', 'price']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in results:
writer.writerow(row)
print(f"Wrote {len(results)} menu items to ubereats_restaurant_menu.csv")And here's what this will print in the terminal:
Wrote 56 menu items to ubereats_restaurant_menu.csvFinally, this is what your CSV file will look like:
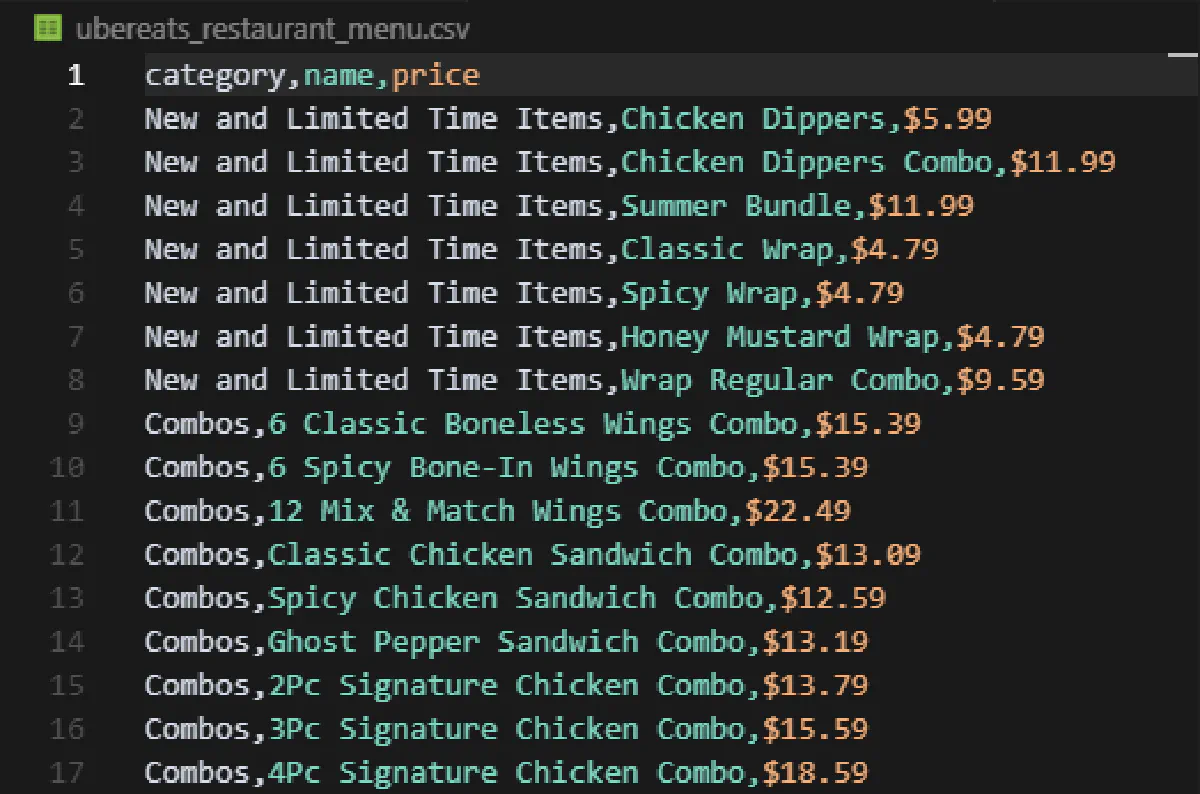
Remember, this code will only apply to restaurants that have no more than a few hundred items in their menu. For chain stores, we'll need a different approach that we'll use in later sections.
Scrape Store List from Uber Eats Frontend
The setup here is exactly the same as the previous section.
We’ll send a request to a JavaScript-heavy, location-specific Uber Eats feed URL; render it using Scrape.do’s headless browser; and extract restaurant/store cards directly from the HTML.
Then, we’ll teach Scrape.do to automatically click “Show more” so we can get the full list of results just like a human would.
Let’s start with building and sending the request.
Build and Send Request
Uber Eats shows store listings based on your location, and it encodes that location inside the pl= parameter in the URL.
ubereats_url = "https://www.ubereats.com/feed?diningMode=DELIVERY&pl=..."This pl parameter is a base64 string that contains:
- Your address (as plain text)
- Latitude and longitude
- Google Maps place ID
If you want to change locations, enter a different delivery address on Uber Eats, and refresh the page. You’ll see the URL update with a new pl value, copy that entire URL and plug it into the script.
For this guide, we're using Central Park in NY as our delivery address because it's a good day for a small picnic:
import requests
import urllib.parse
scrape_token = "<your-token>"
ubereats_url = "https://www.ubereats.com/feed?diningMode=DELIVERY&pl=JTdCJTIyYWRkcmVzcyUyMiUzQSUyMkNlbnRyYWwlMjBQYXJrJTIyJTJDJTIycmVmZXJlbmNlJTIyJTNBJTIyQ2hJSjR6R0ZBWnBZd29rUkdVR3BoM01mMzdrJTIyJTJDJTIycmVmZXJlbmNlVHlwZSUyMiUzQSUyMmdvb2dsZV9wbGFjZXMlMjIlMkMlMjJsYXRpdHVkZSUyMiUzQTQwLjc4MjU1NDclMkMlMjJsb25naXR1ZGUlMjIlM0EtNzMuOTY1NTgzNCU3RA=="
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(ubereats_url)}"
f"&token={scrape_token}"
f"&super=true"
f"&render=true"
)
response = requests.get(api_url)This renders the full Uber Eats feed page in a headless browser and returns the complete HTML.
Extract Store Information
Once the rendered HTML comes back, we parse it using BeautifulSoup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
store_cards = soup.find_all('div', {'data-testid': 'store-card'})Each store is wrapped in a div with data-testid="store-card".
These blocks include:
- Store name
- Store link
- Rating and review count
- Promotions (if available)
To make parsing cleaner, we use a small helper function:
def get_first_text(element, selectors):
for sel in selectors:
found = element.select_one(sel)
if found and found.get_text(strip=True):
return found.get_text(strip=True)
return ''This lets us grab values from different possible class variations (Uber likes to change class names frequently, possibly on every few visits).
Now we extract store data from each card:
results = []
for card in store_cards:
a_tag = card.find('a', {'data-testid': 'store-card'})
href = a_tag['href'] if a_tag and a_tag.has_attr('href') else ''
h3 = a_tag.find('h3').get_text(strip=True) if a_tag and a_tag.find('h3') else ''
# Promo text
promo = ''
promo_div = card.select_one('div.ag.mv.mw.al.bh.af') or card.find('span', {'data-baseweb': 'tag'})
if promo_div:
promo = ' '.join(promo_div.stripped_strings)
# Rating
rating = get_first_text(card, [
'span.bo.ej.ds.ek.b1',
'span[title][class*=b1]'
])
# Review count
review_count = ''
for span in card.find_all('span'):
txt = span.get_text(strip=True)
if txt.startswith('(') and txt.endswith(')'):
review_count = txt
break
if not review_count:
review_count = get_first_text(card, [
'span.bo.ej.bq.dt.nq.nr',
'span[class*=nq][class*=nr]'
])
results.append({
'href': href,
'name': h3,
'promotion': promo,
'rating': rating,
'review_count': review_count
})This gives us a structured dictionary for each store.
Export to CSV
With all store data collected in the results list, we export it using Python’s csv module again:
import csv
<--- code from prev. sections --->
with open('ubereats_store_cards.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['href', 'name', 'promotion', 'rating', 'review_count']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in results:
writer.writerow(row)When we run the script at this stage, Uber Eats only return the first 100 cards.
So your terminal will output:
Wrote 100 store cards to ubereats_store_cards.csvBut for this location, there are 200+ stores.
How do we scrape all of them?
Click Show More Until Finished
Uber Eats shows the first ~100 results on first load and then adds more only when you click the “Show more” button.
To collect the full list, we use Scrape.do’s playWithBrowser feature to automate that button click repeatedly.
Here’s the full interaction sequence:
play_with_browser = [
{
"action": "WaitSelector", # Wait for buttons and spans to be present
"timeout": 30000,
"waitSelector": "button, div, span"
},
{
"action": "Execute", # Click 'Show more' button up to 20 times
"execute": """(async()=>{
let attempts = 0;
while (attempts < 20) {
let btn = Array.from(document.querySelectorAll('button, div, span'))
.find(e => e.textContent.trim() === 'Show more');
if (!btn) break;
btn.scrollIntoView({behavior: 'smooth'});
btn.click();
await new Promise(r => setTimeout(r, 1800));
window.scrollTo(0, document.body.scrollHeight);
await new Promise(r => setTimeout(r, 1200));
attempts++;
}
})();"""
},
{
"action": "Wait", # Wait one last time for content to finish loading
"timeout": 3000
}
]This logic:
- Waits for the page to load
- Finds the "Show more" button
- Scrolls to it and clicks
- Waits for new results to load
- Repeats up to 20 times or until the button disappears
Here's the full code with playWithBrowser= implemented perfectly:
import requests
import urllib.parse
import csv
import json
from bs4 import BeautifulSoup
# Scrape.do token
scrape_token = "<your-token>"
# Target UberEats feed URL
ubereats_url = "https://www.ubereats.com/feed?diningMode=DELIVERY&pl=JTdCJTIyYWRkcmVzcyUyMiUzQSUyMkNlbnRyYWwlMjBQYXJrJTIyJTJDJTIycmVmZXJlbmNlJTIyJTNBJTIyQ2hJSjR6R0ZBWnBZd29rUkdVR3BoM01mMzdrJTIyJTJDJTIycmVmZXJlbmNlVHlwZSUyMiUzQSUyMmdvb2dsZV9wbGFjZXMlMjIlMkMlMjJsYXRpdHVkZSUyMiUzQTQwLjc4MjU1NDclMkMlMjJsb25naXR1ZGUlMjIlM0EtNzMuOTY1NTgzNCU3RA=="
# Browser automation sequence for scrape.do (clicks 'Show more' repeatedly)
play_with_browser = [
{"action": "WaitSelector", "timeout": 30000, "waitSelector": "button, div, span"},
{"action": "Execute", "execute": "(async()=>{let attempts=0;while(attempts<20){let btn=Array.from(document.querySelectorAll('button, div, span')).filter(e=>e.textContent.trim()==='Show more')[0];if(!btn)break;btn.scrollIntoView({behavior:'smooth'});btn.click();await new Promise(r=>setTimeout(r,1800));window.scrollTo(0,document.body.scrollHeight);await new Promise(r=>setTimeout(r,1200));attempts++;}})();"},
{"action": "Wait", "timeout": 3000}
]
# Prepare scrape.do API URL
jsonData = urllib.parse.quote_plus(json.dumps(play_with_browser))
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(ubereats_url)}"
f"&token={scrape_token}"
f"&super=true"
f"&render=true"
f"&playWithBrowser={jsonData}"
)
# Fetch the rendered UberEats page
response = requests.get(api_url)
# Parse the HTML with BeautifulSoup directly from response.text
soup = BeautifulSoup(response.text, "html.parser")
store_cards = soup.find_all('div', {'data-testid': 'store-card'})
# Helper to get first text from selectors
def get_first_text(element, selectors):
for sel in selectors:
found = element.select_one(sel)
if found and found.get_text(strip=True):
return found.get_text(strip=True)
return ''
# Extract store data
results = []
for card in store_cards:
a_tag = card.find('a', {'data-testid': 'store-card'})
href = a_tag['href'] if a_tag and a_tag.has_attr('href') else ''
h3 = a_tag.find('h3').get_text(strip=True) if a_tag and a_tag.find('h3') else ''
promo = ''
promo_div = card.select_one('div.ag.mv.mw.al.bh.af')
if not promo_div:
promo_div = card.find('span', {'data-baseweb': 'tag'})
if promo_div:
promo = ' '.join(promo_div.stripped_strings)
rating = get_first_text(card, [
'span.bo.ej.ds.ek.b1',
'span[title][class*=b1]'
])
review_count = ''
for span in card.find_all('span'):
txt = span.get_text(strip=True)
if txt.startswith('(') and txt.endswith(')'):
review_count = txt
break
if not review_count:
review_count = get_first_text(card, [
'span.bo.ej.bq.dt.nq.nr',
'span[class*=nq][class*=nr]'
])
results.append({
'href': href,
'name': h3,
'promotion': promo,
'rating': rating,
'review_count': review_count
})
# Write results to CSV
with open('ubereats_store_cards.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['href', 'name', 'promotion', 'rating', 'review_count']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in results:
writer.writerow(row)
print(f"Wrote {len(results)} store cards to ubereats_store_cards.csv")And when we run this script, the terminal should print...
Wrote 223 store cards to ubereats_store_cards.csv... while the CSV output looks like this:
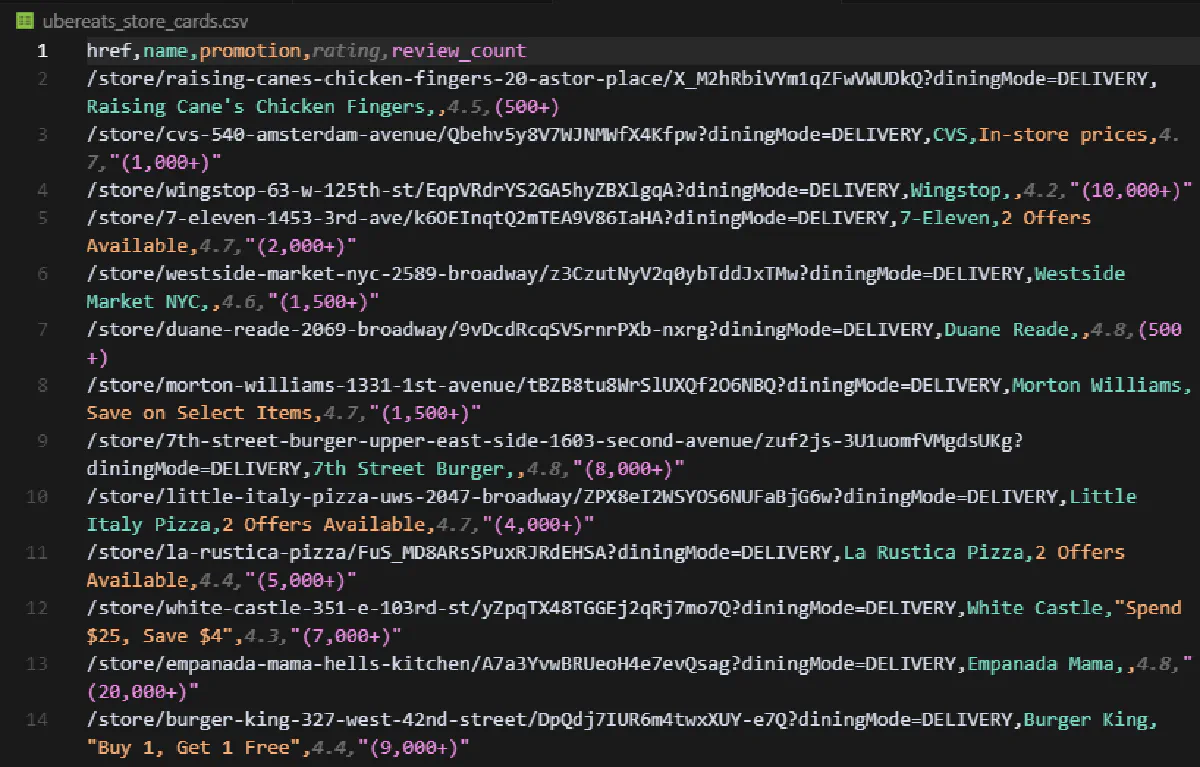
And you get the full list of restaurants and stores for a location! 📑
Scrape Store List from Uber Eats Backend
This method skips frontend rendering entirely.
Instead of simulating user behavior or clicking buttons, we go straight to the internal getFeedV1 API endpoint used by Uber Eats to load store data behind the scenes.
It’s faster, cheaper, and ideal for structured extraction—if you send the right headers and payload.
Let’s walk through it.
Extract Cookie Headers and Right Payload
When you enter an address on Uber Eats, the site sends a POST request to:
https://www.ubereats.com/_p/api/getFeedV1To access the details of this request, from the Uber Eats homepage, pick an address, scroll all the way down, open Developer Tools and switch to Network tab and click Show more which will prompt this request to show up on your network requests.
If you inspect the request, you'll see that it includes:
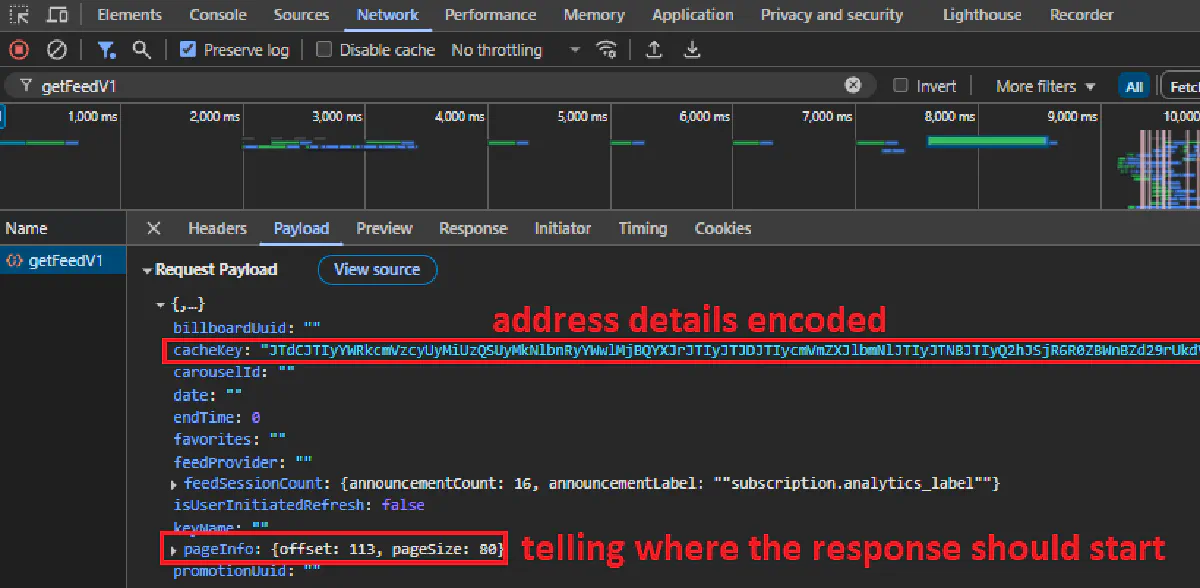
- A payload that contains your address details such as placeId (Google Places reference) encoded, pagination offset, and other location data
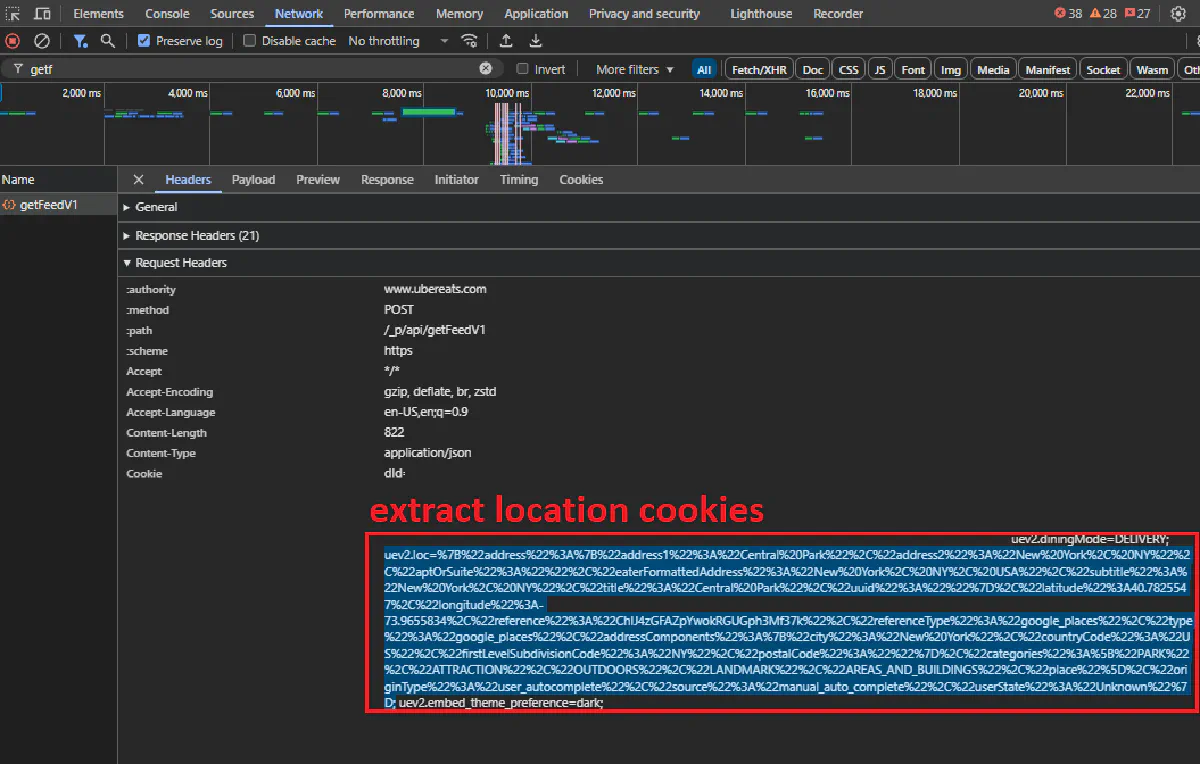
- A Cookie header containing
uev2.loc=value that stores your current address and coordinates - A few extra headers that we need:
content-type,x-csrf-token, andx-uber-client-gitref
These values authenticate our request and tell the server what kind of output we need, so they're important.
But you don’t need to fully understand any of this to scrape Uber Eats backend.
For each new address, you only need the Cookie value to be added as an extra header and the Google place ID to include inside the payload of the code we'll build together.
Here’s how we build the request in Python with headers, we'll add the payload later:
import requests
import urllib.parse
import json
import csv
TOKEN = "<your-token>"
TARGET_URL = "https://www.ubereats.com/_p/api/getFeedV1"
api_url = (
"https://api.scrape.do/?"
f"url={urllib.parse.quote_plus(TARGET_URL)}"
f"&token={TOKEN}"
f"&extraHeaders=true"
f"&super=true"
f"&geoCode=us"
)
headers = {
"sd-cookie": "...", # Full cookie string from DevTools
"sd-content-type": "application/json",
"sd-x-csrf-token": "x",
"sd-x-uber-client-gitref": "x"
}Scrape.do already manipulates your request's headers to make sure it's not flagged as a bot, so in order to add our authentication and location headers, we'll need to enable the
extraHeaders=trueparameter and add "sd-" to the start of every header we want to inject into our session.
This sets up the POST call with exactly what Uber Eats expects, but still lacks the payload, which we'll use in the next section:
Loop Until No More Restaurants Left
Let’s now build the payload and pagination loop.
The request body for getFeedV1 includes four important fields:
payload = {
"placeId": "ChIJ4zGFAZpYwokRGUGph3Mf37k",
"provider": "google_places",
"source": "manual_auto_complete",
"pageInfo": {
"offset": 0,
"pageSize": 80
}
}placeIdis your address location from Google Places (you already copied this from the original request).providershould stay as"google_places".sourcetells Uber how the location was selected;"manual_auto_complete"works in almost all cases.pageInfocontrols pagination. This is where we tell Uber where to start and how many results to return.
Uber Eats responds with two things that make pagination easy:
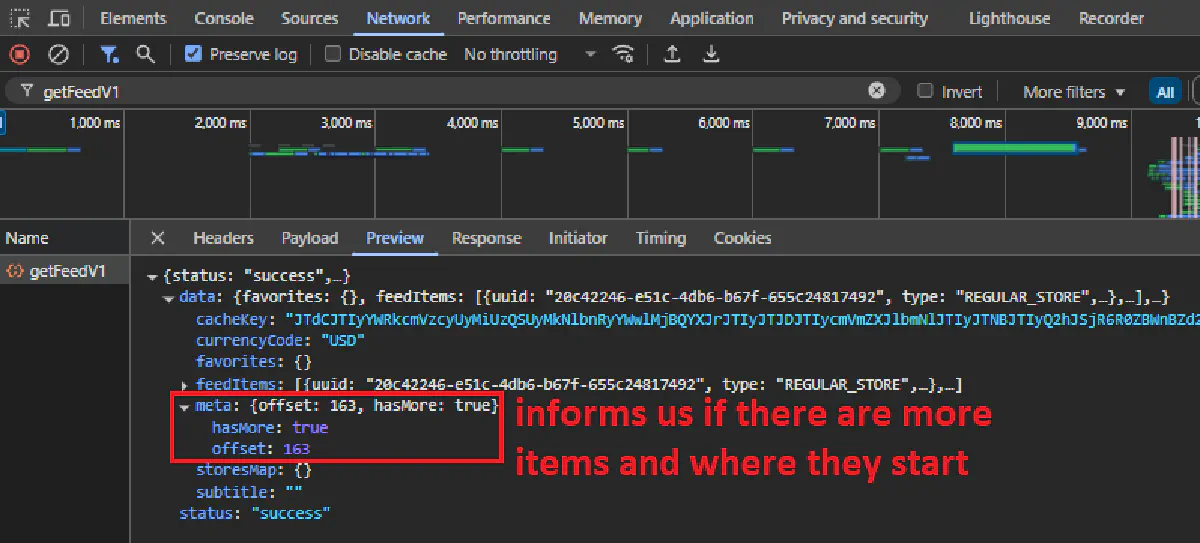
- A list of feed items at
data.feedItems - A flag at
data.meta.hasMorethat tells us whether more stores are available
So we just keep fetching until hasMore becomes false, which makes our job very convenient.
Here’s the full loop in action with the payload added:
all_feed_items = []
offset = 0
page_size = 80
has_more = True
while has_more:
payload = json.dumps({
"placeId": "ChIJ4zGFAZpYwokRGUGph3Mf37k",
"provider": "google_places",
"source": "manual_auto_complete",
"pageInfo": {
"offset": offset,
"pageSize": page_size
}
})
response = requests.post(api_url, data=payload, headers=headers)
data = response.json()
feed_items = data.get("data", {}).get("feedItems", [])
all_feed_items.extend(feed_items)
has_more = data.get("data", {}).get("meta", {}).get("hasMore", False)
offset += page_size
print(f"Fetched {len(feed_items)} items, total so far: {len(all_feed_items)}")
with open("feed_response.json", "w", encoding="utf-8") as f:
json.dump(all_feed_items, f, ensure_ascii=False, indent=2)Notice that we increment
offsetbypage_sizeon each loop. This ensures we never pull duplicates and never miss entries.
With just a few requests, you’ll usually pull hundreds of store listings cleanly and fast.
It's definitely more structured than a regular HTML, but could use a bit more structuring:
Parse the JSON and Export
We will extract just the useful store details and save them in the same structure as our frontend scraper.
Each feedItem may contain a carousel with one or more stores. That’s where most of the data lives.
We'll extract:
- The store name and link
- Promotions (from either
signpostsorofferMetadata) - Ratings and review counts (including hidden review totals from accessibility labels)
Here’s the full parsing logic:
results = []
for section in all_feed_items:
stores = section.get("carousel", {}).get("stores")
if not stores:
continue
for store in stores:
href = store.get("actionUrl", "")
name = store.get("title", {}).get("text", "")
# Promotion from signposts or offerMetadata
promo = ""
signposts = store.get("signposts")
if signposts:
promo = signposts[0].get("text", "")
elif store.get("tracking", {}).get("storePayload", {}).get("offerMetadata", {}).get("offerTypeCount"):
count = store["tracking"]["storePayload"]["offerMetadata"]["offerTypeCount"]
promo = f"{count} Offers Available" if count else ""
# Rating and review count
rating = store.get("rating", {}).get("text", "")
review_count = ""
rating_access = store.get("rating", {}).get("accessibilityText", "")
if "based on more than " in rating_access:
after = rating_access.split("based on more than ")[-1]
num = after.split(" reviews", 1)[0].strip()
review_count = f"({num})" if num else ""
results.append({
'href': href,
'name': name,
'promotion': promo,
'rating': rating,
'review_count': review_count
})And finally, export everything to CSV:
with open('ubereats_store_cards.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['href', 'name', 'promotion', 'rating', 'review_count']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(results)
print(f"Wrote {len(results)} store cards to ubereats_store_cards.csv")
print(f"Total stores collected: {len(all_feed_items)}")This is what the terminal output will look like:
Fetched 125 items, total so far: 125
Fetched 50 items, total so far: 175
Fetched 50 items, total so far: 225
Total items collected: 225 - valid stores: 167
Wrote 167 store cards to ubereats_store_cards.csvAnd our stores will be stored in ubereats_store_cards.csv:
This will work much faster than the frontend method, and is a lot more variable.
Scrape All Products in a Category from Uber Eats Backend
Chain stores in Uber Eats will hold thousands of items in tens of different categories, which can provide a lot of valuable data for your data project.
However, this abundance makes it impossible to scrape all items in one go like we did with restaurants.
Instead, we have to scrape every category one by one and stitch outputs together to create the entire catalog.
For this, we’re calling getCatalogPresentationV2, the same internal API Uber Eats uses to load all menu items when a user opens a category inside a store.
For this, we’re not passing a place ID. Instead, the payload now includes:
- The
storeUuid(Uber’s internal ID for the restaurant or merchant) - One or more
sectionUuids(which represent categories like “Drinks”, “Home Care”, “Food”)
Your cookie still matters; Uber tailors the catalog data (prices, stock, promos) to your location. So we reuse the exact same uev2.loc=... cookie and headers from the previous section.
Let’s walk through the setup.
Extract and Implement storeUuid and sectionUuids
We start by importing the necessary libraries as always and creating a few inputs:
import requests
import urllib.parse
import json
import csv
store_uuid = "41b7a1bf-9cbc-57b5-8934-c59f5f829fa7"
section_uuids = ["63eaa833-9345-41dd-9af5-2d7da547f6da"]The inputs we defined are the store UUID and the section UUIDs. These two values control which restaurant and which category we’re scraping from.
You don’t need to dig into DevTools to find them, Uber Eats includes both directly in the URL when you open a category.
This is the URL of the Drinks category of a 7-Eleven in Brooklyn for example:
https://www.ubereats.com/store/7-eleven-1453-3rd-ave/k6OEInqtQ2mTEA9V86IaHA/41b7a1bf-9cbc-57b5-8934-c59f5f829fa7/63eaa833-9345-41dd-9af5-2d7da547f6daIn the URL:
93a38422-7aad-4369-9310-0f55f3a21a1cis thestoreUuid4f4c2a68-32e2-5bb0-b10d-453b13bdf48dis thesectionUuid
Copy and paste those into your script, and you’re ready to go.
Next, we set up the request:
catalog_url = "https://www.ubereats.com/_p/api/getCatalogPresentationV2"
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(catalog_url)}"
f"&token={scrape_token}"
f"&extraHeaders=true"
f"&super=true"
f"&geoCode=us"
)Just like earlier sections, we’re using extraHeaders=true and prefixing each custom header with sd- so Scrape.do injects them directly into the session.
headers = {
"sd-cookie": "...", # your full uev2.loc cookie for localization
"sd-content-type": "application/json",
"sd-x-csrf-token": "x",
"sd-x-uber-client-gitref": "x"
}Now for pagination setup:
all_results = []
offset = 0
has_more = True
first = TrueHere’s where it gets interesting: we define two payload variants.
Some requests work only if you include "sectionTypes": ["COLLECTION"] in the payload. Others return nothing if you include it.
I've tried to understand but believe me, there is no obvious pattern. 😅
To handle this uncertainty, we prepare both:
payload_with_section_types = json.dumps({
"sortAndFilters": None,
"storeFilters": {
"storeUuid": store_uuid,
"sectionUuids": section_uuids,
"subsectionUuids": None,
"sectionTypes": ["COLLECTION"]
},
"pagingInfo": {"enabled": True, "offset": offset},
"source": "NV_L2_CATALOG"
})
payload_without_section_types = json.dumps({
"sortAndFilters": None,
"storeFilters": {
"storeUuid": store_uuid,
"sectionUuids": section_uuids,
"subsectionUuids": None
},
"pagingInfo": {"enabled": True, "offset": offset},
"source": "NV_L2_CATALOG"
})This fallback system ensures the scraper keeps working even when Uber’s backend behaves inconsistently.
Loop Through and Parse Results
With both payload variants ready, we now send the request.
We always try the version with sectionTypes first. If it returns no results, we immediately retry the same request without that field.
This flexible logic ensures we don’t miss data due to inconsistencies in Uber Eats' backend behavior.
Here’s the loop:
while has_more:
if first:
print("Requesting first items")
first = False
else:
print(f"Requesting next items (offset={offset})")
# Try with sectionTypes first
response = requests.post(api_url, data=payload_with_section_types, headers=headers)
data = response.json()
catalogs = data.get("data", {}).get("catalog", [])
results = []
for section in catalogs:
items = section.get("payload", {}).get("standardItemsPayload", {}).get("catalogItems", [])
for item in items:
price_cents = item.get("price")
price = f"{price_cents / 100:.2f}" if price_cents is not None else ""
results.append({
"uuid": item.get("uuid"),
"title": item.get("title"),
"description": item.get("titleBadge", {}).get("text", ""),
"price": price,
"imageUrl": item.get("imageUrl"),
"isAvailable": item.get("isAvailable"),
"isSoldOut": item.get("isSoldOut"),
"sectionUuid": item.get("sectionUuid"),
"productUuid": item.get("productInfo", {}).get("productUuid", "")
})If this first attempt returns results, we continue using this variant and mark it as successful.
Otherwise, we retry immediately using the stripped-down version:
if results:
variant_used = "with sectionTypes"
else:
response = requests.post(api_url, data=payload_without_section_types, headers=headers)
data = response.json()
catalogs = data.get("data", {}).get("catalog", [])
results = []
for section in catalogs:
items = section.get("payload", {}).get("standardItemsPayload", {}).get("catalogItems", [])
for item in items:
price_cents = item.get("price")
price = f"{price_cents / 100:.2f}" if price_cents is not None else ""
results.append({
"uuid": item.get("uuid"),
"title": item.get("title"),
"description": item.get("titleBadge", {}).get("text", ""),
"price": price,
"imageUrl": item.get("imageUrl"),
"isAvailable": item.get("isAvailable"),
"isSoldOut": item.get("isSoldOut"),
"sectionUuid": item.get("sectionUuid"),
"productUuid": item.get("productInfo", {}).get("productUuid", "")
})
variant_used = "without sectionTypes" if results else NoneOnce results are collected:
- We append them to
all_results - Check if
hasMoreis true in the response - Print how many items were found and with which payload variant
- Increment the offset by the number of items just received
all_results.extend(results)
has_more = data.get("data", {}).get("meta", {}).get("hasMore", False)
if variant_used:
print(f"Fetched {len(results)} items using {variant_used}, total so far: {len(all_results)}")
else:
print("No more items returned, breaking loop.")
break
offset += len(results)This loop continues until Uber Eats stops returning additional items, usually just 1 to 2 pages for a single category.
Export and Full Code
Once we’ve collected and parsed all the items, exporting is straightforward.
Here's the full code with the CSV export logic added and completed:
import requests
import urllib.parse
import json
import csv
# Scrape.do token
scrape_token = "<your-token>"
# Store and section configuration (edit these as needed)
store_uuid = "41b7a1bf-9cbc-57b5-8934-c59f5f829fa7"
section_uuids = ["63eaa833-9345-41dd-9af5-2d7da547f6da"]
# Target UberEats CatalogPresentationV2 URL
catalog_url = "https://www.ubereats.com/_p/api/getCatalogPresentationV2"
# Prepare scrape.do API URL
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(catalog_url)}"
f"&token={scrape_token}"
f"&extraHeaders=true"
f"&super=true"
f"&geoCode=us"
)
# Headers for scrape.do
headers = {
"sd-cookie": "uev2.loc={%22address%22:{%22address1%22:%22Central%20Park%22,%22address2%22:%22New%20York,%20NY%22,%22aptOrSuite%22:%22%22,%22eaterFormattedAddress%22:%22New%20York,%20NY,%20USA%22,%22subtitle%22:%22New%20York,%20NY%22,%22title%22:%22Central%20Park%22,%22uuid%22:%22%22},%22latitude%22:40.7825547,%22longitude%22:-73.9655834,%22reference%22:%22ChIJ4zGFAZpYwokRGUGph3Mf37k%22,%22referenceType%22:%22google_places%22,%22type%22:%22google_places%22,%22addressComponents%22:{%22city%22:%22New%20York%22,%22countryCode%22:%22US%22,%22firstLevelSubdivisionCode%22:%22NY%22,%22postalCode%22:%22%22},%22categories%22:[%22PARK%22,%22ATTRACTION%22,%22OUTDOORS%22,%22LANDMARK%22,%22AREAS_AND_BUILDINGS%22,%22place%22],%22originType%22:%22user_autocomplete%22,%22source%22:%22manual_auto_complete%22,%22userState%22:%22Unknown%22};",
"sd-content-type": "application/json",
"sd-x-csrf-token": "x",
"sd-x-uber-client-gitref": "x"
}
# Pagination logic
all_results = []
offset = 0
has_more = True
first = True
while has_more:
# Variant 1: with sectionTypes
payload_with_section_types = json.dumps({
"sortAndFilters": None,
"storeFilters": {
"storeUuid": store_uuid,
"sectionUuids": section_uuids,
"subsectionUuids": None,
"sectionTypes": ["COLLECTION"]
},
"pagingInfo": {"enabled": True, "offset": offset},
"source": "NV_L2_CATALOG"
})
# Variant 2: without sectionTypes
payload_without_section_types = json.dumps({
"sortAndFilters": None,
"storeFilters": {
"storeUuid": store_uuid,
"sectionUuids": section_uuids,
"subsectionUuids": None
},
"pagingInfo": {"enabled": True, "offset": offset},
"source": "NV_L2_CATALOG"
})
if first:
print("Requesting first items")
first = False
else:
print(f"Requesting next items (offset={offset})")
# Try with sectionTypes
response = requests.post(api_url, data=payload_with_section_types, headers=headers)
data = response.json()
catalogs = data.get("data", {}).get("catalog", [])
results = []
for section in catalogs:
items = section.get("payload", {}).get("standardItemsPayload", {}).get("catalogItems", [])
for item in items:
price_cents = item.get("price")
price = f"{price_cents / 100:.2f}" if price_cents is not None else ""
results.append({
"uuid": item.get("uuid"),
"title": item.get("title"),
"description": item.get("titleBadge", {}).get("text", ""),
"price": price,
"imageUrl": item.get("imageUrl"),
"isAvailable": item.get("isAvailable"),
"isSoldOut": item.get("isSoldOut"),
"sectionUuid": item.get("sectionUuid"),
"productUuid": item.get("productInfo", {}).get("productUuid", "")
})
if results:
variant_used = "with sectionTypes"
else:
# Try without sectionTypes
response = requests.post(api_url, data=payload_without_section_types, headers=headers)
data = response.json()
catalogs = data.get("data", {}).get("catalog", [])
results = []
for section in catalogs:
items = section.get("payload", {}).get("standardItemsPayload", {}).get("catalogItems", [])
for item in items:
price_cents = item.get("price")
price = f"{price_cents / 100:.2f}" if price_cents is not None else ""
results.append({
"uuid": item.get("uuid"),
"title": item.get("title"),
"description": item.get("titleBadge", {}).get("text", ""),
"price": price,
"imageUrl": item.get("imageUrl"),
"isAvailable": item.get("isAvailable"),
"isSoldOut": item.get("isSoldOut"),
"sectionUuid": item.get("sectionUuid"),
"productUuid": item.get("productInfo", {}).get("productUuid", "")
})
variant_used = "without sectionTypes" if results else None
all_results.extend(results)
has_more = data.get("data", {}).get("meta", {}).get("hasMore", False)
if variant_used:
print(f"Fetched {len(results)} items using {variant_used}, total so far: {len(all_results)}")
else:
print("No more items returned, breaking loop.")
break
offset += len(results)
# Write results to CSV
with open("catalog_items.csv", "w", newline='', encoding="utf-8") as csvfile:
fieldnames = ["uuid", "title", "description", "price", "imageUrl", "isAvailable", "isSoldOut", "sectionUuid", "productUuid"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in all_results:
writer.writerow(row)
print(f"Wrote {len(all_results)} items to catalog_items.csv")The output will look like this:
Wrote 277 items to catalog_items.csvAnd this is the final result:
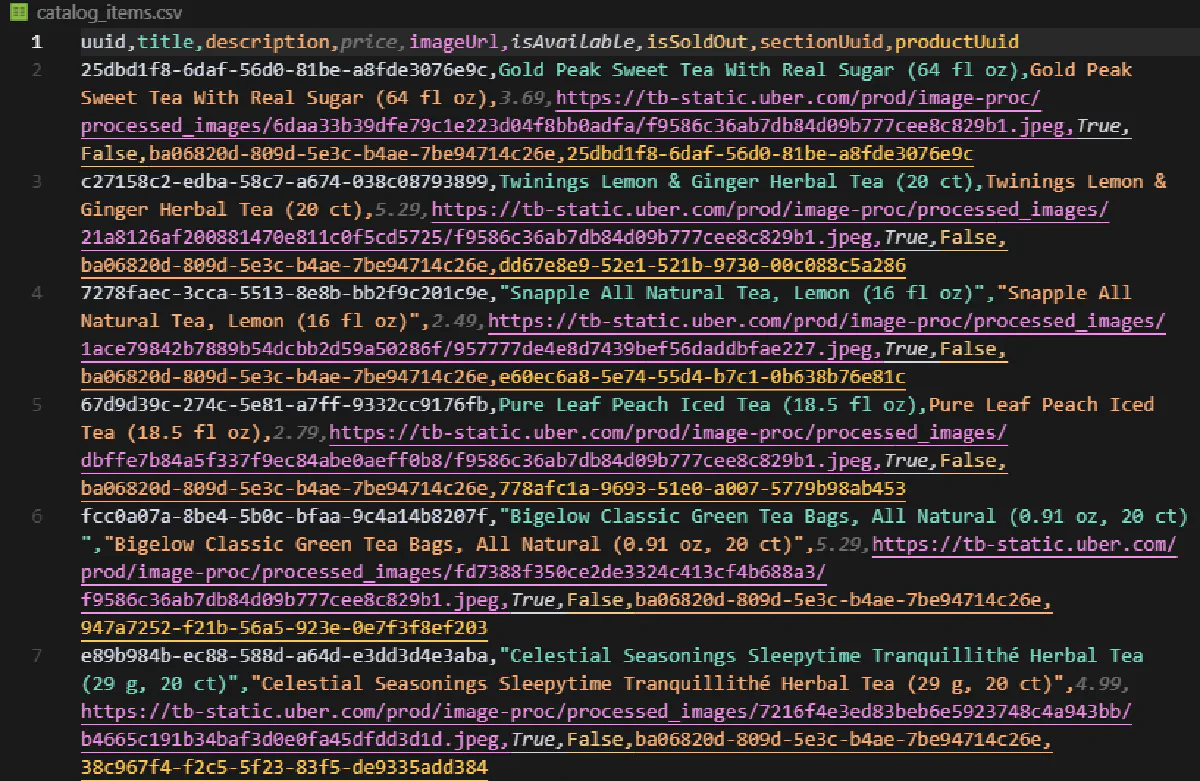
Each row in the file includes detailed metadata:
uuid: internal Uber Eats ID for the itemtitle: item namedescription: short badge/label if presentprice: formatted in dollarsimageUrl: direct link to item imageisAvailable: whether it's currently availableisSoldOut: true if out of stocksectionUuidandproductUuid: useful if cross-referencing with other data
This backend method is clean, fast, and avoids all the rendering issues from scraping the frontend. However, category uuids are not the same for each store, making it harder to scrape at scale, but not impossible.
Last Words
Uber Eats is tough to scrape, but not if you have a few tools in your bag that will help you go straight to the right APIs.
With Scrape.do handling location headers, rendering, and anti-bot defenses, you can fetch store lists, menus, and full catalog data reliably.
Whether you're scraping food delivery data from multiple platforms or building a grocery delivery data scraping pipeline, the same principles apply: understand the platform's data structure, bypass anti-bot defenses, and extract what matters.
Founder @ Scrape.do








