Category:Scraping Basics
5 Main Components of Web Scraping

Full Stack Developer



If you have a lot of websites to scrape and you want to perform a large-scale web scraping, it requires you to build a powerful and scalable web scraping infrastructure. If you want a powerful and scalable web scraping infrastructure, you will also need an advanced system and meticulous planning. If you have an idea of how you can perform web scraping, you can easily master the things we will talk about in this article, but if you do not have any experience and ideas, you will first need to get a team of experienced developers, you need to let these developers set up infrastructure for you, of course, you will also pay them.
If you've hired a web developer team and you're confident they'll set up the infrastructure for you, you shouldn't worry much, but you still need to do a rigorous round of testing just before you start extracting data no matter what. Let's talk, though, that the hardest part is actually creating the scraping infrastructure. If the infrastructure you have built for web scraping is not well thought out and tested, it can cause multiple problems and you may also face legal issues. For this reason, in this article, we will share with you how solid and well-planned web scraping should take place and what needs to be done.
Just before we begin, we want you to know that if you need a good web scraping team, we at Scrape.do will always be happy to work for you. Together with you, we will help your projects reach the destination and purpose you want, and ensure that you get all the data you need. We would like to add that we offer the best service with the lowest fees in the market. Contact us now!
Get Started By Creating Auto-scraping Spiders
If you want to scrape websites in bulk, you need to set up some kind of automated script. This script is often called a spider, and these automated scripts are critical. Each spider must be capable enough to create multiple threads. In addition, it is important that the spiders you create can act independently in order to easily crawl more than one website. Let's reinforce and understand this situation with an example.
Let's say you want to scrape data from an e-commerce-based website, let's also imagine that this website has multiple subcategories such as books, clothing, watches, and mobile phones. When you reach the root website, the e-commerce site itself, you need four different spiders. One of these spiders must search for books, another for clothes, another for watches, and the last for cell phones. If you can't program a single spider to mutate into multiple spiders, you'll need a new spider to access every category on a website, which is an irrational and time-consuming activity to continually reproduce spiders.
When you ensure that each of the spiders you have is separated within itself, you can scan the data one by one. In addition, if there is an exceptional case that is not caught and any of these spiders crash, you can continue your scraping one by one without having to interrupt your other spiders. When your spiders are divided among themselves, you also ensure that your data is always renewed, and you can scan at certain time intervals thanks to your spiders. You can also scrape the web using the spiders you have, only on certain dates and times according to your needs.
How to Manage Your Spiders
Now that you understand what spiders are and how they should work, the next thing you need to know to run a large web scraping project is how to manage your spiders. If you want to better manage your spiders you may need to create an abstraction above your spiders. When you look at the search engine results pages, it is possible to find more than one spider management platform. While which platform you choose depends entirely on the features you want and your budget, the overall purpose of these platforms is to schedule jobs, review received data, and automate spiders. By using one of the spider management platforms, it becomes possible to keep up to date with the status of your web scraping project without even having to manage your servers.
You Should Do Javascript Rendering
Although Javascript, which is widely used on modern websites and can be encountered frequently, is an extremely innovative technology, it will be a disadvantage for you if you are running a web scraping project. If the data on the website you want to scrape is data processed with the help of Javascript, you can be sure that your web scraping project will be more complex. However, if you manage to pass the data from the backend to the front end of the website with the help of AJAX calls, you can inspect the website and simulate the AJAX request your spider has to get the JSON/XML file. In this case, the data you want will be yours whether Javascript is used or not.
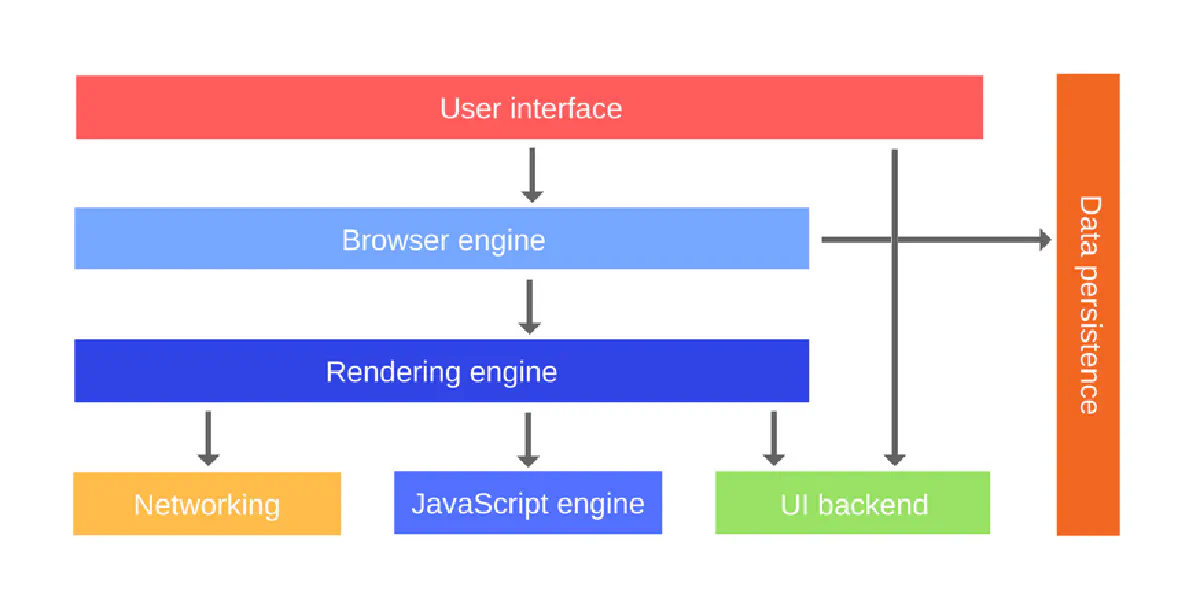
If the content on a website is created using Javascript and you have noticed this, the first thing you should do is find a headless browser like Selenium, Puppeteer, and Playwright. If you are trying to go through antibots and do web scraping despite antibots, using a headless browser will be necessary. If you use headless browsers, you can generate Javascript in the short term and get the data much faster, but you should keep in mind that using headless browsers will require much more hardware resources in the long run. If the hardware resources used are as important to you as the management time, you should first examine the website properly and find out that there are no AJAX calls or hidden API calls in the background. If there is no other way to get the data and you need to use Javascript anyway, then you can get help from a headless browser.
You Should Validate Your Data and Control the Quality of Data
Although web scraping may seem like it means collecting data and dumping it into another document, this is definitely not the case. If you don't want dirty data to be in your datasets and don't want to waste your time getting useless data, you need validations and controls to make sure your data is of good quality. If certain data points have gaps and you need to scrape data to fill those gaps, you must set constraints for each data point. For example, you can specify only a certain number of digits for phone numbers, and specify only as a difference whether it contains numbers or not. For nouns, you can check if they are made up of one or more words and do not qualify as nouns that are not separated by spaces. With just a few steps like this, you can prevent dirty, corrupt, and useless data from leaking into your data column.
If you have decided to complete your web scraping framework, as a first step you need to research which websites have the maximum data accuracy, after doing very important research in this area you will be able to get better results and not need manual intervention in the long run. In addition, one of the biggest problems with scraped datasets is the large number and abundance of duplicate data. If you want to obtain a large amount of data, it is also essential to check if your data is duplicated. In addition, this way you not only keep your dataset clean but also reduce the storage requirement of your data. In this way, you will both have quality data and spend less money.
If you want to keep your scraping data cleaner and more accurate, you have to choose a more difficult and effective way. This is scanning data from more than one source and testing the similarity of the data to each other. You should also keep in mind that this method may take more time and may be difficult to set up for each data set you fill out. However, if you want to have a clean web scraping, this is the best method you can choose.
You Should Find and Use A Scalable Server for Web Scraping
If there is mention of spiders and automated scripts, it is also mentioned somewhere that these automated scripts and spiders usually need to be deployed on a cloud-based server. So if you have spiders and automated scripts it's extremely important to find a scalable server where you can store them. Let us recommend AWS-EC2 from Amazon, one of the most widely used and cheapest solutions. This server is managed by teams at AWS and is routinely maintained at regular intervals. So you can run code on a Linux or Windows server.
There are 275 different types of services that Amazon will offer you, and which of these servers you choose depends on the type of operating system, how you want your server to be managed, and what type of CPU and RAM it will use. Since you are only charged for the time you run the server, you will not be charged extra even if you stop using it completely after a certain time. By setting up your scraping infrastructure on a cloud server, you will be managing an effective web scraping project for much less money in the long run. But keep in mind that you may also need the architects managing your instance to set up things for your server and upgrade or make changes as needed.
You Should Keep the Data You Have Obtained and Store it for Later Use
If you are managing a web scraping project, in addition to the infrastructure and code required to extract the data, you also need a storage area where you can access the data you have obtained at any time. When you manage this storage properly, you will also be able to store your data in a format or location for use together. If you're scraping large images and videos that require almost GBs of storage and want to store this high-resolution data, you can take advantage of AWS-S3, the cheapest data storage solution on the market today. In addition to this system, which is also a solution of Amazon, you can also take advantage of more expensive solutions that you can choose depending on how often you want to access the data.
You Should Use Proxy Management and IP Rotation Service
While if you want to scrape a single web page it is possible to get the job done by running the script from your laptop, if you are trying to crawl data from thousands of web pages of a website every second, your IP address will be blacklisted or blocked from the website altogether. If you scan too much and manage to automatically recognize and fill CAPTCHA services, the website may block your IP address and you will also be blocked from encountering CAPTCHA. You can use a VPN or Proxy service to constantly change your IP address. You can also set the intervals at which your IP address will change and in which locations your IP address will be located.
The user-agent is an important tool that not only tells you which browser to use but also tells you which operating system that browser is running on. If the information in this tool stays with you for a long time, the website will easily detect that you are trying to scrape your data and will block you. For this reason, you will need to keep rotating your user agent and the IP address from time to time. You should consider creating a list of your user agents and randomly selecting one after a fixed time interval.
If you want to avoid being blacklisted, you should take advantage of tools like Selenium and use a headless browser. The most important thing to keep in mind is that running a headless browser is almost the same as using a regular browser, except you don't see the pages visually, but using a headless browser will still extremely resource intensive. Using a headless browser will be resource intensive, so if you are using cloud systems your process will be slower and you will run a more expensive web scraping project.
See our proxy services in detail.
If you do not want to deal with web scraping components and want to get a web scraping service where you have almost everything you need, you should contact scrape.do, that is, us. You will be able to carry out a web scraping project without dealing with any technical knowledge, with prices suitable for every budget we can offer you.
Full Stack Developer








