Category:Scraping Tools
Scrape.do v2 Is Now Live! Here's What's New

Founder @ Scrape.do


A few years ago, I built the first version of Scrape.do alone.
The API, the dashboard, the website, everything.
Scrape.do has come a long way since then.
We've grown fast both in size and people, and the infrastructure we built now handles more than 1 billion requests every single day.
So it was time to upgrade our product and our website.
We've rebuilt our dashboard, website, documentation, and infrastructure to match what Scrape.do has become and where it's headed.
Here's what changed.
Product Changes
The core of Scrape.do has always been the same: build the most powerful and fastest web scraping API available.
That hasn't changed. But we've added the tooling around it that our users actually need to scrape at scale.
Analytics and Usage History
You can now see detailed analytics and usage history directly in your dashboard.
No more guessing how many credits you burned through yesterday or which requests failed. You get full visibility into every request, success rates, response times, and credit usage over any date range.
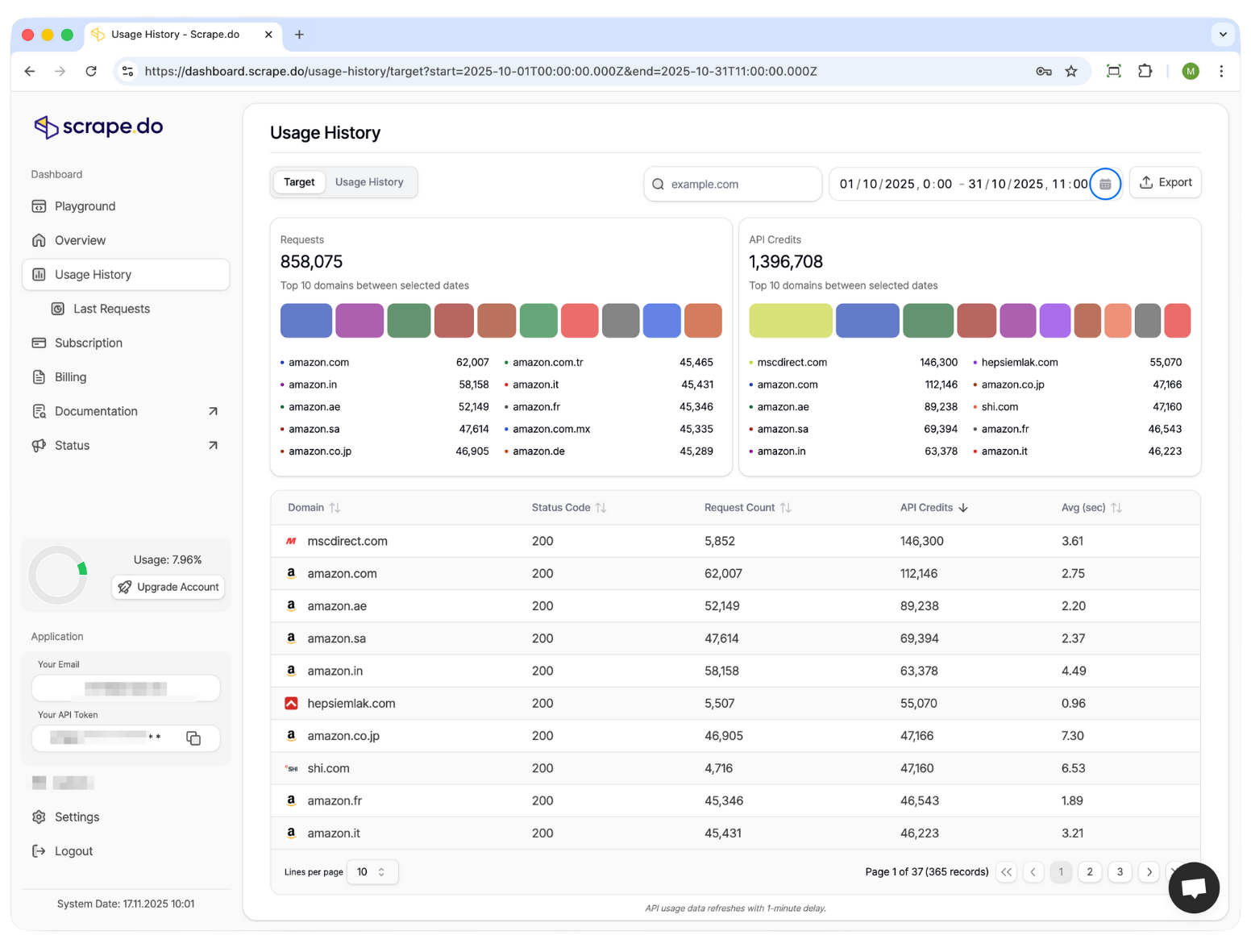
This was one of the most requested features, and it's live now for everyone.
Scrape.do Playground
Before v2, testing a scraper meant writing the code first, running it, and hoping it worked.
Now you can test your requests directly in the dashboard using our new Playground feature. Build your request with different parameters, tweak headers or geo-targeting, enable rendering, and see the results in real time before you write a single line of code.
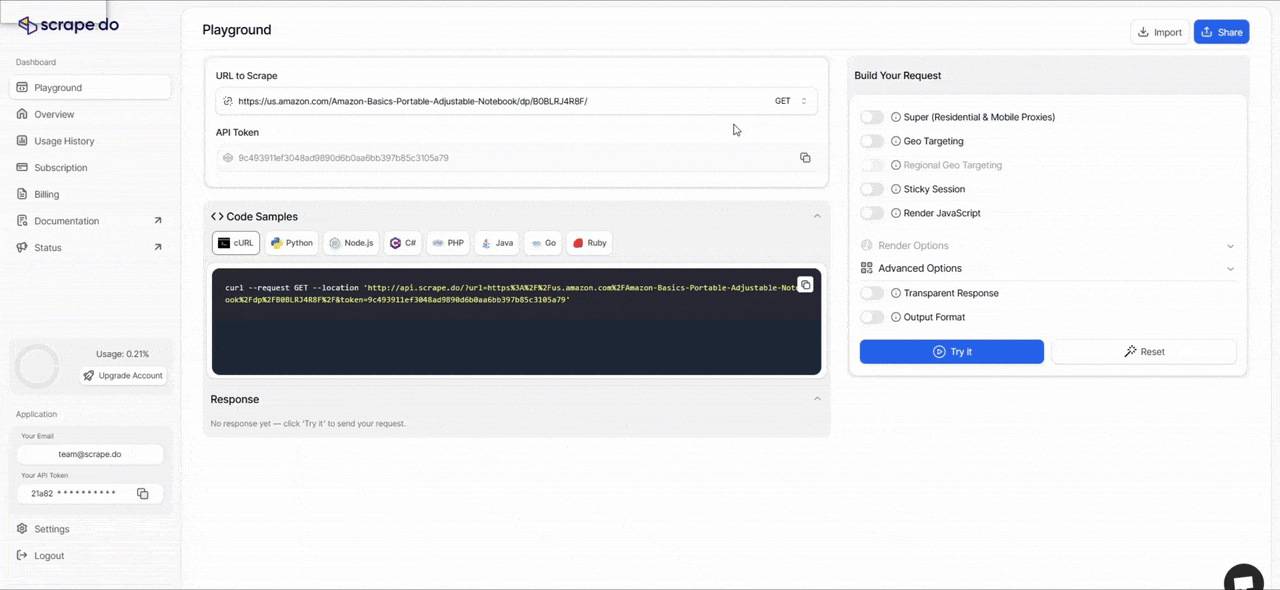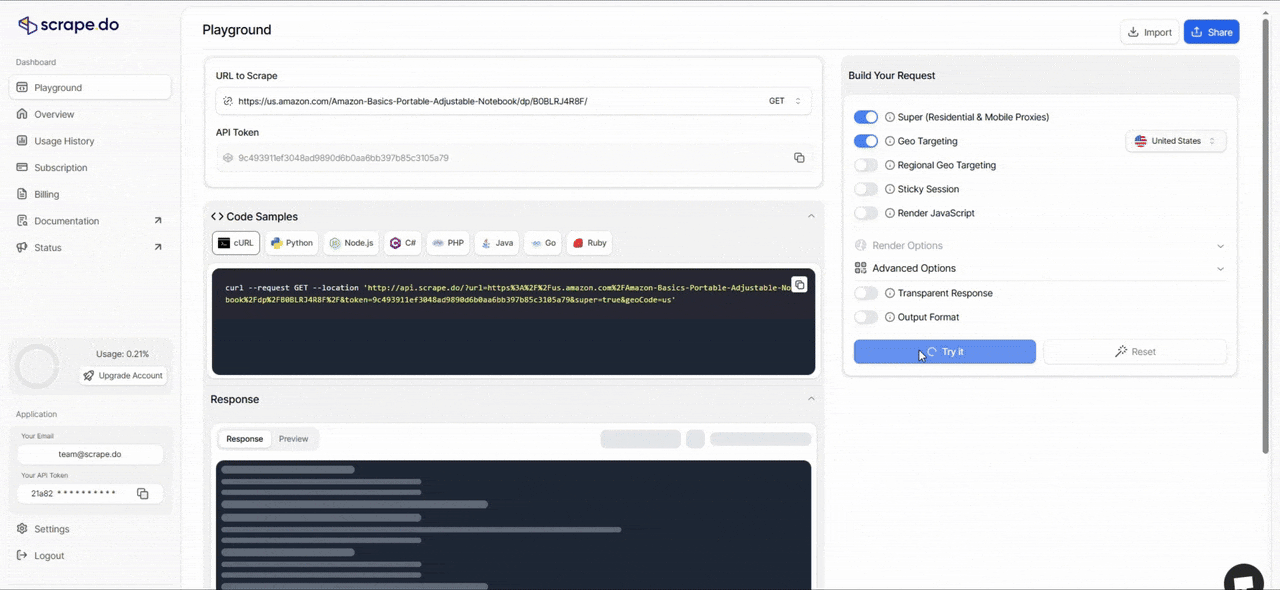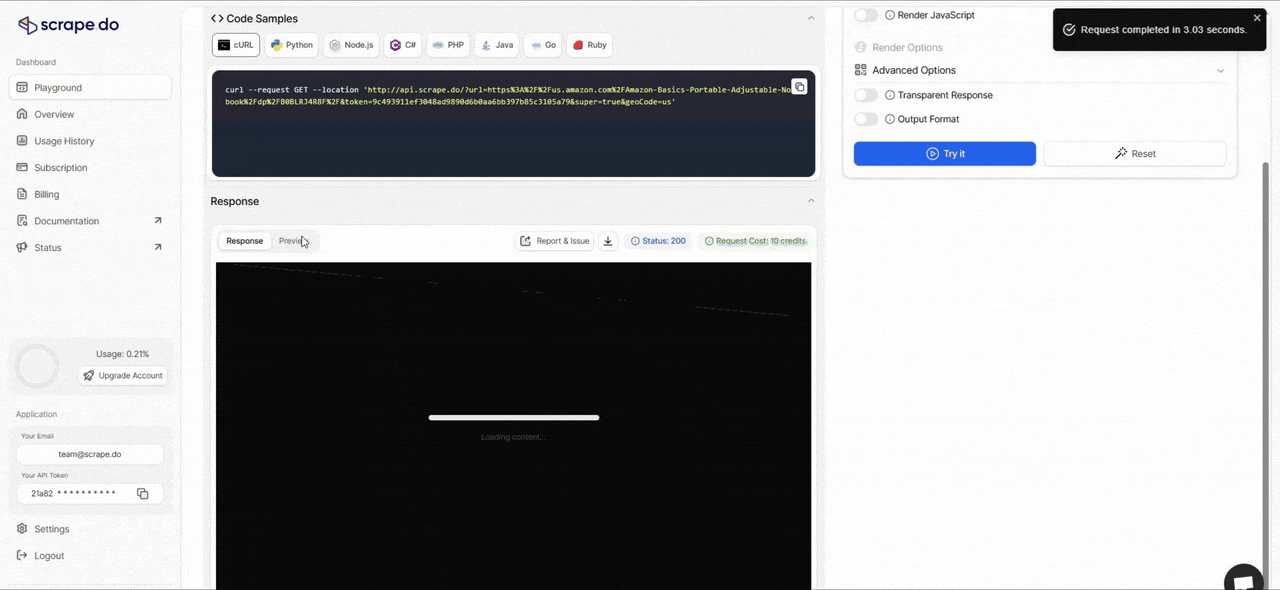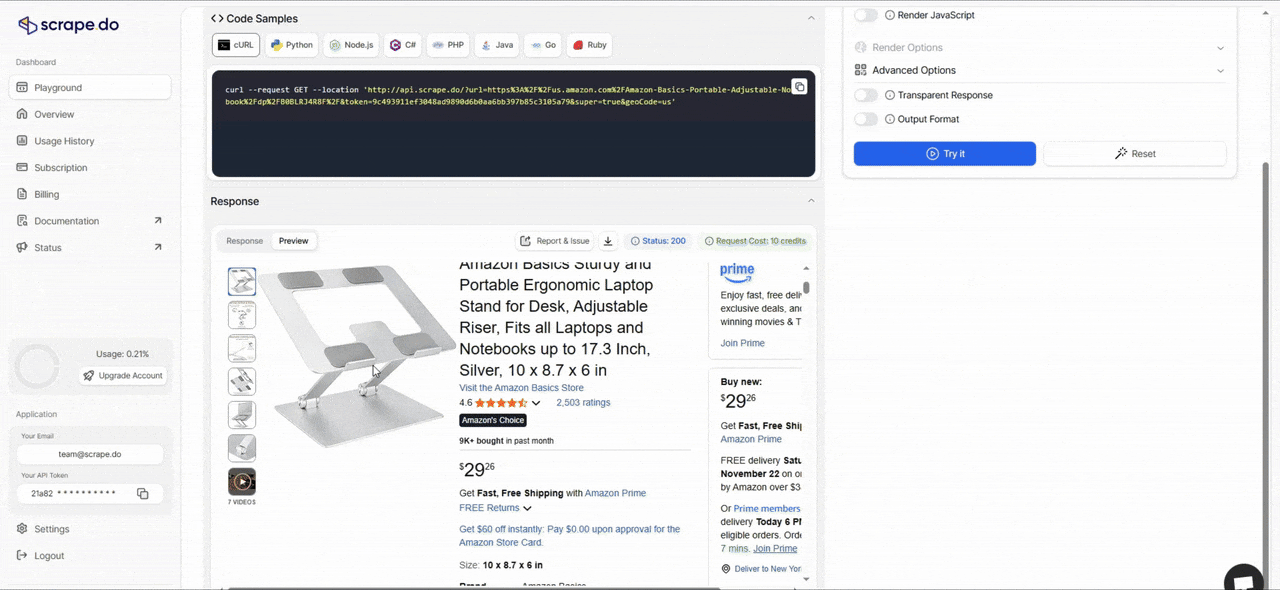
This cuts down setup time from hours to minutes, especially when you're figuring out which parameters work for a specific site.
Asynchronous Scrape.do
For large-scale scraping jobs, waiting for synchronous responses doesn't make sense.
We've implemented asynchronous scraping so you can schedule jobs on our servers, let us find the right bypass parameters, and get your results delivered when they're ready.
This works for bulk operations where you're scraping thousands of URLs and don't want to manage retries, rate limits, or session handling yourself.
Read the async documentation for implementation details.
New and Improved Website
We changed our approach to the brand and aligned it with what Scrape.do actually is: a technical tool built for developers who need reliable data extraction.
Our vision is now more cleanly projected on our website.
Complete Content Overhaul
The old website was functional but vague. It told you what Scrape.do did, but not how it worked or who it was for.
The new site breaks down our products, features, and use cases by industry.
If you're scraping e-commerce data, we show you exactly how Scrape.do handles it. If you're dealing with geo-restricted sites, we explain the proxy infrastructure.

Better Blog Experience
Our content should do more than explain how to use Scrape.do.
We want it to help you solve everyday scraping problems—domain-specific guides, anti-bot bypass techniques, working code examples for complex sites.
That's why we invested heavily in redesigning the blog for better readability and publishing industry-leading content.
You're experiencing the new blog right now 👀
Advanced Plan, for Advanced Users
We added a new tier for teams and developers running large-scale operations.
In the Advanced plan for $699/month, you'll find:
- 10 million successful API credits
- 200 concurrent requests
- Custom SLA
- Dedicated Slack support channel
If you're scraping at enterprise scale and need guaranteed uptime with direct engineering support, this plan gives you that.
Improved Documentation
At Scrape.do, we believe that a strong documentation is the most important factor behind the success of our users. That's why we've leveled-up our documentation to turn it into a living and breathing space.
Updated UX & UI
We reorganized the docs so you can find what you need in seconds, not minutes.
Whether you're looking for a specific parameter, troubleshooting an error, or implementing a feature, the path to the answer is clearer now.
Integrate Scrape.do with AI and Automation Tools
We added integration guides for platforms our users actually use such as Zapier, n8n, with more coming soon.
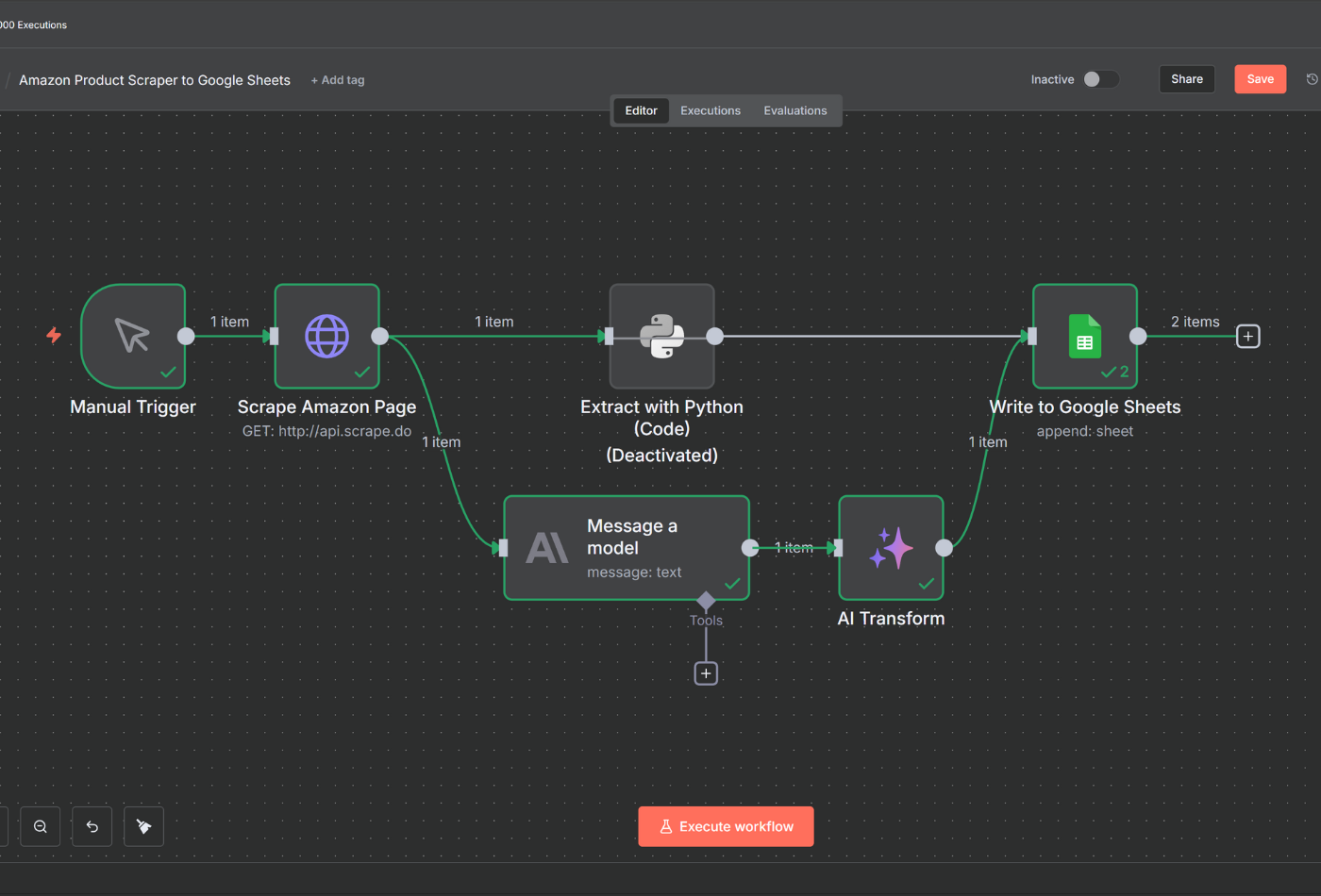
If you're building workflows that pull data from the web and feed it into AI models or automation pipelines, these guides will save you hours of setup time.
What's Next
We're constantly working on products that will make web scraping less of a headache and turn Scrape.do into something much more powerful than it is today.
New Products
We have two new products that are in development:
Proxies: We already run an extensive proxy network for Scrape.do users with over 110M+ IPs. We're turning this into a standalone product with per-GB pricing for developers who want premium proxies without the API layer.
Scraping Browser: We're hosting popular scraping browsers in the cloud—Puppeteer, Playwright, Selenium—so you can run automated data collection through the best headless browsers and libraries without managing infrastructure yourself.

Both products are close and we'll announce launch dates soon.
Dedicated APIs
Scrape.do outperforms competing web scraping APIs on many domains including Amazon, Google, and more from every industry.
We're building dedicated APIs for these domains that output structured data automatically. Faster extraction, lower cost, no parsing logic on your end.
This unlocks new opportunities for developers building with AI tools, especially those who need clean, structured datasets at scale for AI workflows. And this won't be our only investment in AI 😉
Whether you've been with us since the early days or you're just starting out, your feedback and support drive what we build.
We're just getting started, and what's coming next is going to be worth the wait.
Stay tuned and thank you for using Scrape.do.
Founder @ Scrape.do








