Category:Scraping Use Cases
Scraping Redfin: Extract Property Data and Regional Listings

R&D Engineer


Redfin is one of the largest real estate platforms in the US, with millions of property listings and valuable market data.
If you're tracking real estate markets or building property databases, you need this data.
In this guide, we'll cover both search results scraping and individual property details extraction using Python and Scrape.do to ensure reliable data collection.
Find complete working code on GitHub ⚙
Scraping Redfin Search Results
We'll start by scraping property listings from Redfin's search results pages, which contain essential property information like prices, addresses, and basic details.
Prerequisites and Setup
First, install the required libraries for HTTP requests, HTML parsing, and data export:
pip install requests beautifulsoup4You'll also need a Scrape.do API token. Sign up for free to get 1000 credits per month.
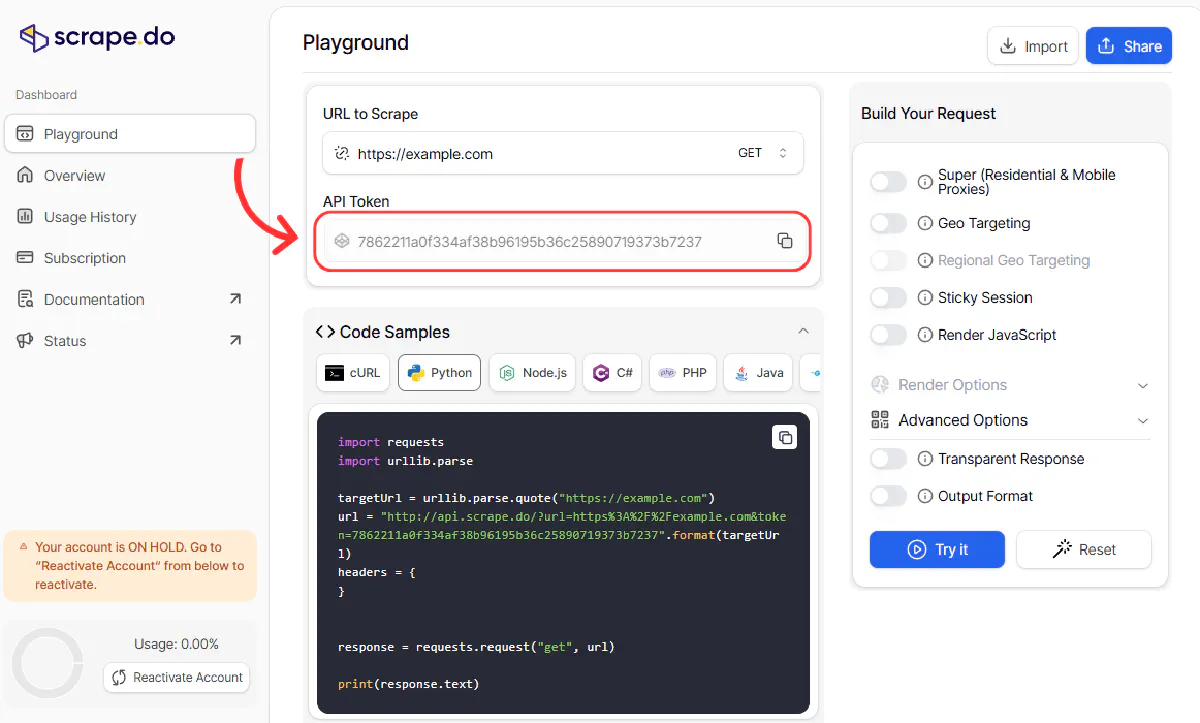
Building Search URLs
Redfin uses paginated URLs with page numbers in the format /page-{number}. We'll construct URLs for multiple pages to scrape all available properties.
The base URL structure follows this pattern: https://www.redfin.com/city/{city_id}/{state}/{city-name}.
For New York, the city ID is 30749, so our base URL becomes https://www.redfin.com/city/30749/NY/New-York.
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Configuration
TOKEN = "<your_token>"
base_url = "https://www.redfin.com/city/30749/NY/New-York"
max_pages = 9 # max pages to scrape, 9 is the max number of pages for most cities
all_properties = []Parsing Property Cards
Each property listing is contained in a div with class bp-Homecard. We'll extract the key information from each card by finding these specific elements and extracting their text content.
The main loop iterates through each page, building the search URL and fetching the HTML content through Scrape.do to avoid any potential blocks.
for page in range(1, max_pages + 1):
# Build URL for current page
search_url = f"{base_url}/page-{page}"
print(f"Scraping page {page}...")
# Try to fetch page with retry logic
for attempt in range(3):
try:
response = requests.get(f"https://api.scrape.do/?token={TOKEN}&url={urllib.parse.quote(search_url)}")
soup = BeautifulSoup(response.text, "html.parser")
break
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
continue
# Find all home cards
home_cards = soup.find_all("div", class_="bp-Homecard")
if not home_cards:
breakRetry Logic
Network requests can fail for various reasons - timeouts, temporary blocks, or server issues. We implement a retry mechanism that attempts each request up to 3 times before giving up.
The retry loop catches any exceptions and prints the error message, then continues to the next attempt. If all attempts fail, the script moves to the next page.
Extracting Property Data
Now we'll extract specific data from each property card. Redfin structures their property cards with consistent CSS classes, making it easy to target specific elements.
For each property card, we look for essential elements like price and address. If either is missing, we skip that card entirely to avoid incomplete data.
page_properties = []
for card in home_cards:
# Skip empty cards - check if card has essential elements before parsing
price_elem = card.find("span", class_="bp-Homecard__Price--value")
address_elem = card.find("a", class_="bp-Homecard__Address")
if not price_elem or not address_elem:
continue
property_data = {}
# Price - extract the main price value
property_data['price'] = price_elem.get_text(strip=True)
# Square feet - look for the locked stat value (usually square footage)
sqft_elem = card.find("span", class_="bp-Homecard__LockedStat--value")
property_data['square_feet'] = sqft_elem.get_text(strip=True) + " sq ft" if sqft_elem else ""
# Address and URL - get the full address text and construct the property URL
property_data['full_address'] = address_elem.get_text(strip=True)
property_data['url'] = "https://www.redfin.com" + address_elem.get("href", "")
property_data['property_id'] = address_elem.get("href", "").split("/home/")[1]
# Main image - extract the property photo URL
img_elem = card.find("img", class_="bp-Homecard__Photo--image")
property_data['main_image'] = img_elem.get("src", "") if img_elem else ""
# Broker - extract listing agent information
broker_elem = card.find("div", class_="bp-Homecard__Attribution")
broker_text = broker_elem.get_text(strip=True) if broker_elem else ""
property_data['broker'] = broker_text.replace("Listing by ", "").replace("Listing by", "")
page_properties.append(property_data)
if not page_properties:
break
all_properties.extend(page_properties)
print(f"Found {len(page_properties)} properties on page {page}")Pagination Handling
Redfin typically shows 9 pages of results per city search. We loop through all available pages, collecting properties from each one. If a page returns no property cards, we break out of the loop as we've reached the end of available results.
The script tracks progress by printing how many properties were found on each page, giving you visibility into the scraping process.
Data Deduplication
Since properties might appear on multiple pages or the same property might be returned twice, we need to remove duplicates based on the unique property ID.
# Remove duplicates based on property_id
seen_ids = set()
unique_properties = [prop for prop in all_properties if prop['property_id'] not in seen_ids and not seen_ids.add(prop['property_id'])]This uses a Python set to track seen property IDs and a list comprehension to filter out any duplicates, ensuring each property appears only once in our final dataset.
Export to CSV
Here's the complete working script that combines all the previous steps with the CSV export logic added:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Configuration
TOKEN = "<your_token>"
base_url = "https://www.redfin.com/city/30749/NY/New-York"
max_pages = 9 # max pages to scrape, 9 is the max number of pages for most cities
all_properties = []
for page in range(1, max_pages + 1):
# Build URL for current page
search_url = f"{base_url}/page-{page}"
print(f"Scraping page {page}...")
# Try to fetch page with retry logic
for attempt in range(3):
try:
response = requests.get(f"https://api.scrape.do/?token={TOKEN}&url={urllib.parse.quote(search_url)}")
soup = BeautifulSoup(response.text, "html.parser")
break
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
continue
# Find all home cards
home_cards = soup.find_all("div", class_="bp-Homecard")
if not home_cards:
break
page_properties = []
for card in home_cards:
# Skip empty cards - check if card has essential elements before parsing
price_elem = card.find("span", class_="bp-Homecard__Price--value")
address_elem = card.find("a", class_="bp-Homecard__Address")
if not price_elem or not address_elem:
continue
property_data = {}
# Price
property_data['price'] = price_elem.get_text(strip=True)
# Square feet
sqft_elem = card.find("span", class_="bp-Homecard__LockedStat--value")
property_data['square_feet'] = sqft_elem.get_text(strip=True) + " sq ft" if sqft_elem else ""
# Address and URL
property_data['full_address'] = address_elem.get_text(strip=True)
property_data['url'] = "https://www.redfin.com" + address_elem.get("href", "")
property_data['property_id'] = address_elem.get("href", "").split("/home/")[1]
# Main image
img_elem = card.find("img", class_="bp-Homecard__Photo--image")
property_data['main_image'] = img_elem.get("src", "") if img_elem else ""
# Broker
broker_elem = card.find("div", class_="bp-Homecard__Attribution")
broker_text = broker_elem.get_text(strip=True) if broker_elem else ""
property_data['broker'] = broker_text.replace("Listing by ", "").replace("Listing by", "")
page_properties.append(property_data)
if not page_properties:
break
all_properties.extend(page_properties)
print(f"Found {len(page_properties)} properties on page {page}")
# Remove duplicates based on property_id
seen_ids = set()
unique_properties = [prop for prop in all_properties if prop['property_id'] not in seen_ids and not seen_ids.add(prop['property_id'])]
# Save CSV
with open("redfin_search_results.csv", "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=unique_properties[0].keys())
writer.writeheader()
writer.writerows(unique_properties)
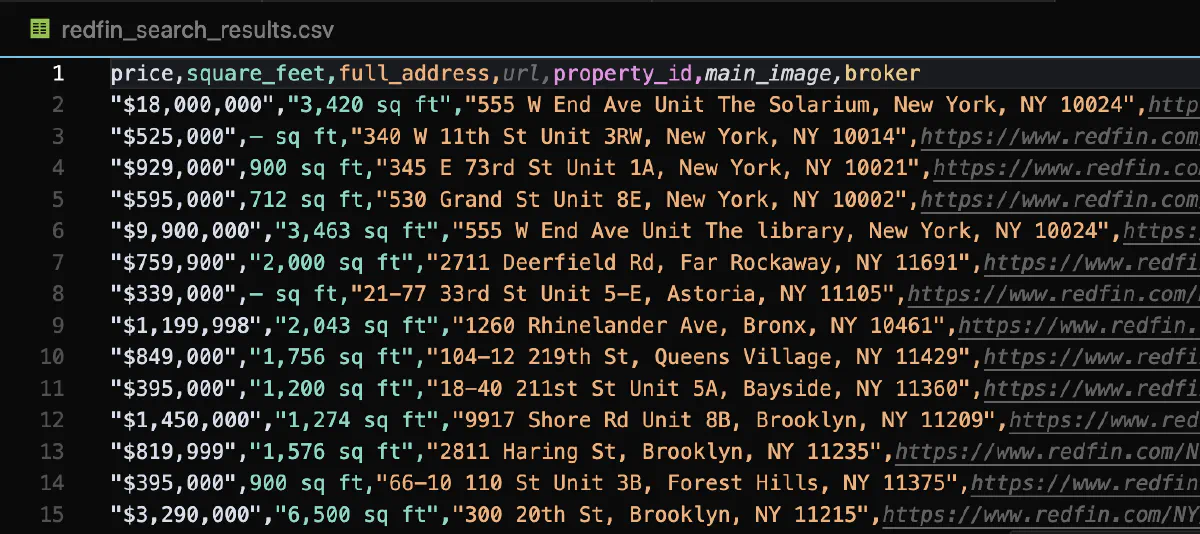
print(f"✓ {len(unique_properties)} unique properties saved to redfin_search_results.csv")This script will generate a CSV file with all the scraped property data.
Here's what the CSV file looks like:
Scraping Individual Property Details
For more comprehensive property information, we'll scrape individual property detail pages that contain additional data like property specifications and listing details.
Property URL Construction
We'll use specific property URLs to scrape detailed information from individual property pages. These URLs follow the pattern: https://www.redfin.com/{state}/{city}/{address}/home/{property_id}.
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Configuration
TOKEN = "<your_token>"
target_urls = [
"https://www.redfin.com/TX/Austin/7646-Elkhorn-Mountain-Trl-78729/home/32851263",
"https://www.redfin.com/TX/Austin/6000-Shepherd-Mountain-Cv-78730/unit-2103/home/31123552",
"https://www.redfin.com/NY/Queens/34-24-82nd-St-11372/unit-2/home/175087110"
]
all_properties = []Property Address and Location Data
We'll extract and parse detailed address information from the property pages. The address is displayed in a large header with class full-address addressBannerRevamp street-address.
We'll split this full address into its components: street, city, state, and zip code for better data organization.
for target_url in target_urls:
# Fetch page
response = requests.get(f"https://api.scrape.do/?token={TOKEN}&url={urllib.parse.quote(target_url)}")
soup = BeautifulSoup(response.text, "html.parser")
# Extract data
property_data = {}
# Basic info
address_header = soup.find("h1", class_="full-address addressBannerRevamp street-address").get_text(strip=True)
property_data['full_address'] = address_header
property_data['price'] = soup.find("div", class_="statsValue price").get_text(strip=True)
property_data['property_id'] = target_url.split('/home/')[1]
# Address parsing - split the full address into components
address_parts = address_header.split(',')
property_data['city'] = address_parts[1]
state_zip = address_parts[2].split(' ')
property_data['state'] = state_zip[1]
property_data['zip_code'] = state_zip[2]Property Details and Specifications
We'll extract property specifications like type, square footage, and other key details from the property detail page.
The property type is found in a section called "keyDetails-row" where we look for rows containing "Property Type" and extract the corresponding value.
# Property type - search through key details rows
key_details_rows = soup.find_all("div", class_="keyDetails-row")
property_data['property_type'] = "Unknown"
for row in key_details_rows:
if "Property Type" in row.find("span", class_="valueType").get_text():
property_data['property_type'] = row.find("span", class_="valueText").get_text(strip=True)
break
# Square feet - extract from stats value
property_data['square_feet'] = soup.find("span", class_="statsValue").get_text(strip=True) + " sq ft"
# Image - get the main property photo
property_data['main_image_link'] = soup.find("img").get("src")Agent and Contact Information
Redfin property pages also contain listing agent details and contact information. We can extract the agent's name, broker information, and phone number from specific sections of the page.
# Agent info - extract listing agent details
agent_content = soup.find("div", class_="agent-info-content")
property_data['listed_by'] = agent_content.find("span", class_="agent-basic-details--heading").find("span").get_text(strip=True)
broker_text = agent_content.find("span", class_="agent-basic-details--broker").get_text(strip=True)
property_data['broker'] = broker_text.replace('•', '').strip()
# Contact - extract phone number
contact_text = soup.find("div", class_="listingContactSection").get_text(strip=True)
property_data['contact_number'] = contact_text.split(':')[1]⚠️ Important Legal Notice: It is not legal to commercially scrape personal information such as phone numbers and names from real estate websites. We will comment this code out in the full implementation, but if you're only using this for personal projects and research purposes, you can uncomment these lines.
Property Listing Information
We'll extract listing-specific information while respecting privacy boundaries. We avoid scraping personal agent information as it may be illegal and unethical.
Instead, we focus on publicly available information like listing dates and set empty values for personal fields.
# Last updated - extract when the listing was last updated
property_data['listing_last_updated'] = soup.find("div", class_="listingInfoSection").find("time").get_text(strip=True)
all_properties.append(property_data)Export to CSV
Here's the complete working script that combines all the previous steps with the CSV export logic added:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Configuration
TOKEN = "<your_token>"
target_urls = [
"https://www.redfin.com/TX/Austin/7646-Elkhorn-Mountain-Trl-78729/home/32851263",
"https://www.redfin.com/TX/Austin/6000-Shepherd-Mountain-Cv-78730/unit-2103/home/31123552",
"https://www.redfin.com/NY/Queens/34-24-82nd-St-11372/unit-2/home/175087110"
]
all_properties = []
for target_url in target_urls:
# Fetch page
response = requests.get(f"https://api.scrape.do/?token={TOKEN}&url={urllib.parse.quote(target_url)}")
soup = BeautifulSoup(response.text, "html.parser")
# Extract data
property_data = {}
# Basic info
address_header = soup.find("h1", class_="full-address addressBannerRevamp street-address").get_text(strip=True)
property_data['full_address'] = address_header
property_data['price'] = soup.find("div", class_="statsValue price").get_text(strip=True)
property_data['property_id'] = target_url.split('/home/')[1]
# Address parsing
address_parts = address_header.split(',')
property_data['city'] = address_parts[1]
state_zip = address_parts[2].split(' ')
property_data['state'] = state_zip[1]
property_data['zip_code'] = state_zip[2]
# Property type
key_details_rows = soup.find_all("div", class_="keyDetails-row")
property_data['property_type'] = "Unknown"
for row in key_details_rows:
if "Property Type" in row.find("span", class_="valueType").get_text():
property_data['property_type'] = row.find("span", class_="valueText").get_text(strip=True)
break
# Square feet
property_data['square_feet'] = soup.find("span", class_="statsValue").get_text(strip=True) + " sq ft"
# Image
property_data['main_image_link'] = soup.find("img").get("src")
# Set empty values for personal information fields
property_data['listed_by'] = ""
property_data['broker'] = ""
property_data['contact_number'] = ""
# Last updated
property_data['listing_last_updated'] = soup.find("div", class_="listingInfoSection").find("time").get_text(strip=True)
all_properties.append(property_data)
# Save CSV
with open("redfin_property_details.csv", "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=all_properties[0].keys())
writer.writeheader()
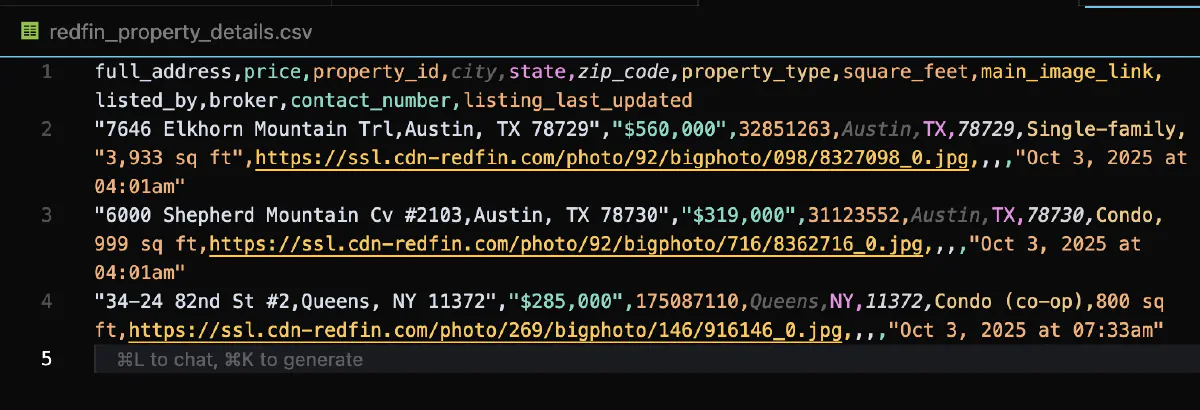
writer.writerows(all_properties)
print(f"✓ {len(all_properties)} properties saved to redfin_property_details.csv")This script will generate a CSV file with detailed property information. Here's what the CSV file looks like:
Conclusion
Scraping Redfin property data is straightforward with the right approach and tools. By using Scrape.do, you can reliably extract both search results and detailed property information without worrying about blocks or rate limiting.
Scrape.do handles:
- Automatic proxy rotation and IP management
- JavaScript rendering for dynamic content
- Rate limiting and retry logic
- Geographic targeting for US-based requests
Whether you're analyzing market trends, building property databases, or conducting real estate research, these scripts provide a solid foundation for collecting Redfin data at scale.
Get 1000 free credits and start scraping Redfin with Scrape.do
R&D Engineer








