Category:Scraping Use Cases
Scraping MSC Direct: Extract Product Data Without Getting Blocked

Full Stack Developer



MSC doesn’t make scraping easy, but it’s worth the effort.
It’s one of the largest industrial suppliers in the U.S., with over 2 million products and a massive B2B customer base across manufacturing, aerospace, and maintenance.
If you’re tracking product availability or building a catalog, MSC is a goldmine, but the site uses dynamic content and heavy anti-bot protections that block simple scrapers fast.
In this mini guide, we’ll extract brand and product name, price, and stock availability all in one go, using Python and the Scrape.do API.
Find the fully working code here. ⚙
Why Is Scraping MSC Difficult?
Scraping MSC isn’t as simple as sending a few requests. The site aggressively filters traffic based on geography, browser behavior, and request signatures.
Sometimes, even real users get blocked, especially if you're browsing from outside the U.S. or if their bot detection thinks you’re suspicious.
Here’s what you’re up against:
Incapsula Imperva WAF Protection
MSC uses Incapsula Imperva to filter and inspect incoming traffic. This WAF watches for bot-like behavior, like:
- Unusual request headers
- Missing JavaScript execution
- Rapid request rates
- Suspicious IP ranges
If anything looks off, you’ll get a generic block page, or worse, an empty iframe like the one below, which returns a 200 status but no real content:
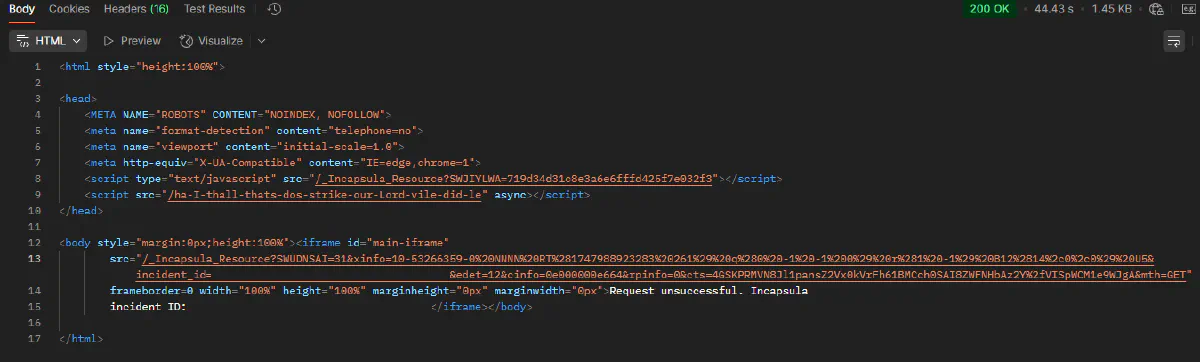
Geo-Restrictions and IP Filtering
Accessing MSC from outside the U.S.?
Good luck.
The site enforces strict geolocation filters and even U.S. users sometimes get blocked. The screenshot below shows what happens when a real browser is denied access:
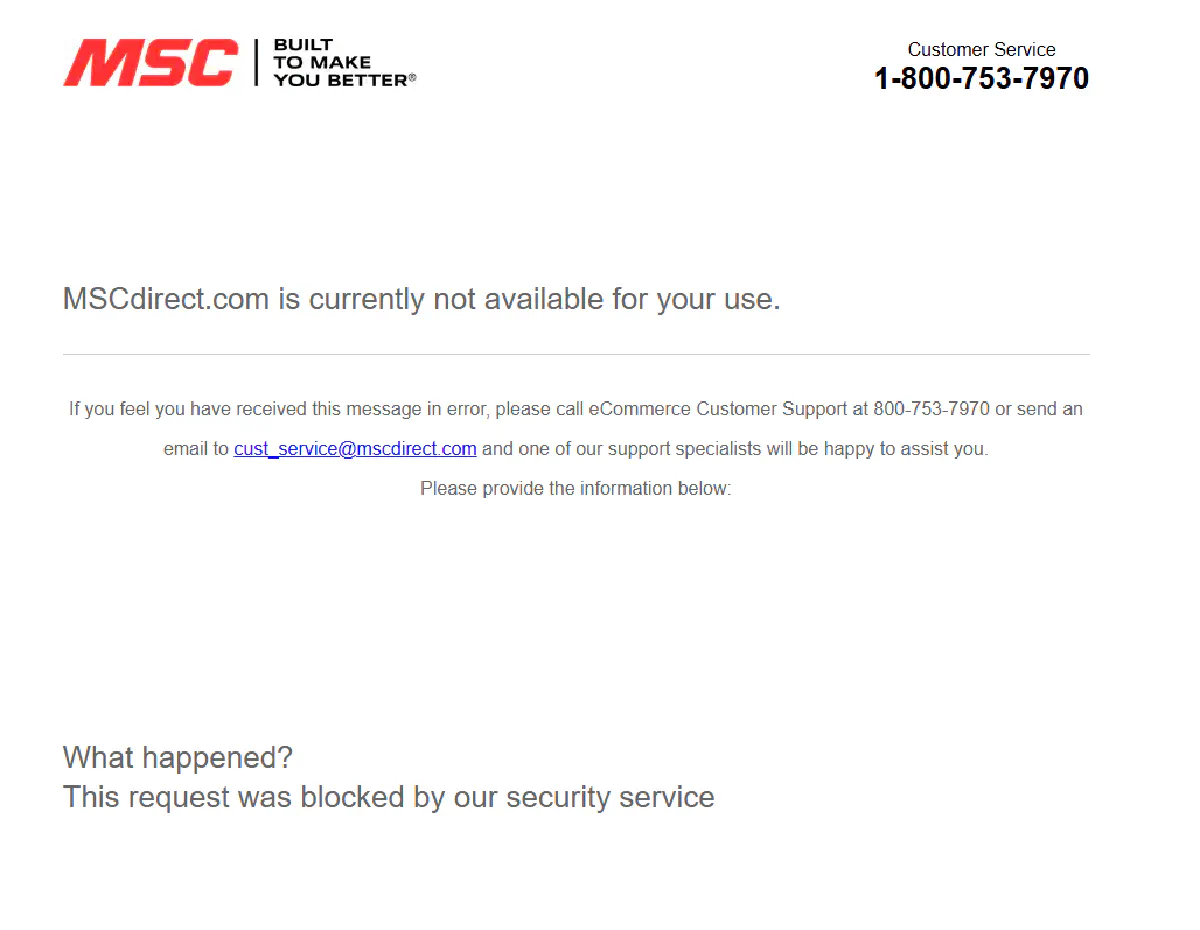
So being a real browser isn’t enough; you need the right IPs, headers, TLS fingerprint, and rendering setup.
Why You Need Scrape.do
You don’t need to fight Incapsula or spin up a headless browser.
Scrape.do gets around MSC’s protections out of the box.
Just add super=true to your API call and you’re in.
Scrape.do handles:
- U.S.-based residential IPs that pass geo checks
- TLS and header fingerprint rotation to avoid bot flags
- Full JavaScript rendering, only when needed
- Reliable HTML output, perfect for BeautifulSoup or lxml
No CAPTCHAs. No iframes. No broken responses.
Just a clean HTML page you can parse in seconds.
How to Extract Product Data from MSC Direct
To scrape MSC, we don’t need a complex setup or a headless browser—we just need the right tools:
- Python for the script
- requests to send HTTP requests
- BeautifulSoup to extract elements from HTML
- Scrape.do to bypass MSC’s bot protections and geo blocks
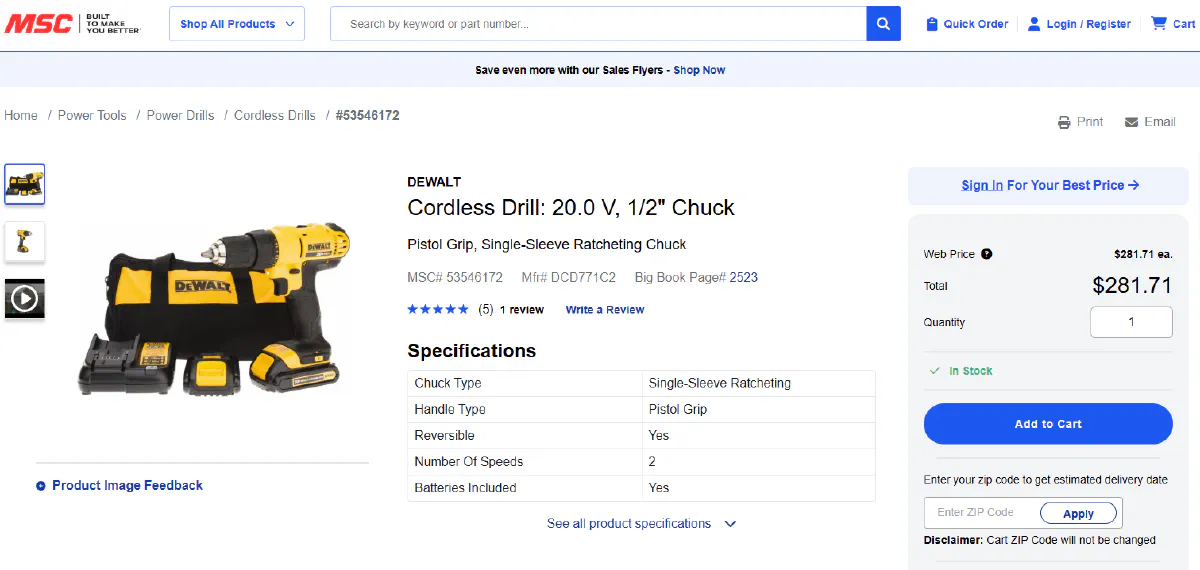
We’ll target a live product page for a DeWALT cordless drill and extract brand & product name, price, and stock status.
This is exactly what the product page looks like in a normal browser:
Prerequisites
Before we write any code, make sure you have:
Python 3 installed on your machine
The following libraries ready to go:
pip install requests beautifulsoup4Scrape.do API token: sign up at Scrape.do, then head to the dashboard and copy your API token.
MSC# of the product you're scraping: which you can find at the end of the product URL "*https://www.mscdirect.com/product/details/**\{MSC#\}**\*"
We’ll use our Scrape.do token to authenticate and unlock MSC pages that would normally be blocked.
Once that’s done, you’re ready to send your first request:
Send the Request and Get a 200 OK
We’ll start by sending our first request to MSC using Scrape.do.
This is the part where most scrapers fail; MSC doesn’t serve full HTML to bots, and the page may look fine while actually returning an empty iframe or JavaScript error.
That’s why we’re using super=true in the Scrape.do API which routes the request through a residential U.S. IP, renders the page if needed, and sends back real, usable HTML.
Here’s how we structure the request:
import requests
import urllib.parse
# Your Scrape.do token and the MSC# of the product found in its URL
token = "<your_token>"
msc_number = "53546172"
# Structuring the API request
target_url = f"https://www.mscdirect.com/product/details/{msc_number}"
encoded_url = urllib.parse.quote_plus(target_url)
# Make sure to enable "super=true"
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true"
response = requests.get(api_url)
print(response.status_code)Now you can check the response to make sure it worked if it provides:
200If you get something else like a timeout, 403, or an empty page, double check your product URL, and if the issue still persists let the Scrape.do support know (<5min response time 🚀).
Extract Brand and Product Name
With the HTML response loaded, we can extract structured data using BeautifulSoup.
Both the product name and brand are cleanly marked on MSC’s product pages, which makes our job a lot easier.
Here’s the updated script with those two fields added:
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Your Scrape.do API token and MSC#
token = "<your_token>"
msc_number = "53546172"
# Target MSC Direct product URL
target_url = f"https://www.mscdirect.com/product/details/{msc_number}"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint - enabling "super=true" for residential proxies
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true"
# Send the request and parse the HTML with BeautifulSoup
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract brand name and product name
# Brand is inside an element with id="brand-name"
brand = soup.find(id="brand-name").text.strip()
# Product name is inside the page's <h1> tag
name = soup.find("h1").text.strip()
# Print results
print("Brand:", brand)
print("Product Name:", name)These are the two most visible identifiers for any product listing.
Example output:
Brand: DeWALT
Product Name: Cordless Drill: 20.0 V, 1/2" ChuckNext, let’s work on information a bit more trickier to extract:
Extract Price and Stock Availability
Now let’s extract the product price and availability status.
Both values exist in well-structured elements on the page, but they’re wrapped in a bit of extra text—so we’ll need to clean them up slightly.
We’ll:
- Use the
id="webPriceId"element to get the raw price - Strip the
"ea."suffix to isolate the numeric value - Use the
id="availabilityHtml"container to check if the product is actually in stock
Important note: MSC sometimes returns generic availability messages or dynamically hides the stock tag. So if "In Stock" doesn’t appear explicitly, we’ll treat it as out of stock.
Here’s the full script now:
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Your Scrape.do API token and MSC#
token = "<your_token>"
msc_number = "53546172"
# Target MSC Direct product URL
target_url = f"https://www.mscdirect.com/product/details/{msc_number}"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint - enabling "super=true" for residential proxies
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true"
# Send the request and parse the HTML with BeautifulSoup
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract brand name and product name
brand = soup.find(id="brand-name").text.strip()
name = soup.find("h1").text.strip()
# Extract product price (and remove "ea." from it's end)
price = soup.find(id="webPriceId").text.strip().replace("ea.", "").strip()
# Detect stock status; default to “Out of Stock” if not present or different
availability_tag = soup.find(id="availabilityHtml")
if availability_tag and "In Stock" in availability_tag.text:
stock_status = "In Stock"
else:
stock_status = "Out of Stock"
# Print results
print("Brand:", brand)
print("Product Name:", name)
print("Price:", price)
print("Stock Status:", stock_status)And here’s what a successful scrape should return:
Brand: DeWALT
Product Name: Cordless Drill: 20.0 V, 1/2" Chuck
Price: $281.71
Stock Status: In StockYou’ve now pulled structured product data from one of the most locked-down industrial supply websites on the web.
Conclusion
Scraping MSC Direct isn’t easy; Incapsula, geo-restrictions, and dynamic content stop most scrapers before the page even loads.
But once you route traffic through the right proxies and parse the key HTML elements, extracting product data becomes simple and scalable.
And with Scrape.do, you don’t need to handle:
- Residential proxy rotation
- TLS fingerprinting or header spoofing
- JavaScript rendering or bot challenges
Just send the request and let Scrape.do take care of the rest.
Full Stack Developer








