Ultimate Guide to Web Scraping with Puppeteer: beginner to pro
Puppeteer, as one of the top headless browsers, is an indispensable tool for professionals scraping with Node.js.
Its ability to control a browser programmatically makes it perfect for tasks ranging from simple data extraction to handling complex, JavaScript-heavy websites.
In this guide, you’ll learn:
- How to set up Puppeteer and build your first scraper.
- Handling dynamic content and Single-Page Applications (SPAs).
- Techniques to manage sessions, cookies, and bypass anti-bot defenses.
- Advanced tricks for scaling scrapers and optimizing performance.
- How tools like Scrape.do can simplify challenges like proxies and CAPTCHA solving.
Let’s get started by setting up Puppeteer for your first scraping project.
Getting Started with Puppeteer
Puppeteer is a Node.js library that provides a high-level API for controlling Chrome or Chromium browsers. It’s widely used for scraping dynamic websites, testing user interfaces, and automating repetitive browser tasks. If you’re just getting started with scraping using Node.js, Puppeteer is an excellent tool to add to your toolkit.
Prerequisites
Before diving in, make sure you have the following:
- Node.js installed on your system (preferably the latest LTS version). You can download it from Node.js official site.
- A basic understanding of JavaScript and npm (Node.js package manager).
Installing Puppeteer
To get started with Puppeteer, install it using the following command:
npm install puppeteer
This command downloads Puppeteer and a compatible version of Chromium. Puppeteer’s Chromium version is guaranteed to work seamlessly with the library, so you don’t need to worry about compatibility issues.
Note: The installation may take some time, as it downloads a Chromium build, which is around 100MB.
Your First Puppeteer Script
Let’s kick things off with a simple “Hello World” example. This script will launch a headless browser, navigate to a website, and take a screenshot:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'example.png' });
await browser.close();
})();
Save the code to a file named index.js and run it using the following command:
node index.js
Once executed, the script will save a screenshot of the Example.com homepage as example.png in your project directory.
What Makes Puppeteer Powerful?
Here are a few features that make Puppeteer indispensable:
- Interacting with Web Pages: Puppeteer allows you to fill out forms, click buttons, and scrape content with precision.
- Handling Dynamic Content: Perfect for JavaScript-heavy pages and Single-Page Applications (SPAs).
- Capturing Screenshots and PDFs: Easily create visual outputs or export pages in PDF format.
- Network Interception: Block requests, monitor traffic, or simulate specific network conditions.
Now that you have Puppeteer set up, let’s move on to more advanced use cases.
Handling Dynamic Web Content
Many modern websites use JavaScript to load content dynamically, making scraping more challenging. Fortunately, Puppeteer can handle JavaScript-heavy pages by interacting with the DOM after the content is fully rendered.
When scraping dynamic pages, it’s important to ensure that content is fully loaded before extracting data. Here are a few methods you can use to achieve that with Puppeteer:
Using waitForNetworkIdle
The waitForNetworkIdle option is used to pause execution until there are no active network requests for a specific period. This is especially useful for websites that load additional resources dynamically.
Here’s an example:
await page.goto('https://example.com', { waitUntil: 'networkidle2' });
The networkidle2 option waits until there are no more than two active network connections for at least 500ms. This ensures that the page has finished loading all critical resources.
Using waitForSelector
waitForSelector is used to wait for a specific element to appear in the DOM before proceeding. This is critical when scraping dynamic content that doesn’t load immediately.
Example:
await page.waitForSelector('.dynamic-element');
const content = await page.$eval('.dynamic-element', el => el.textContent);
console.log('Extracted Content:', content);
This ensures that Puppeteer waits until the .dynamic-element is loaded and visible before extracting its content.
Using waitForNavigation
The waitForNavigation method is useful when you expect the page to navigate to a new URL (e.g., after clicking a button or submitting a form).
Example:
await Promise.all([
page.click('.submit-button'),
page.waitForNavigation({ waitUntil: 'domcontentloaded' })
]);
console.log('Navigation complete');
This ensures that Puppeteer waits for the navigation to complete before proceeding with further actions.
Combining waitForNetworkIdle and waitForSelector
For pages with complex loading behavior, you may need to combine multiple waiting strategies. For example:
await page.goto('https://example.com', { waitUntil: 'networkidle2' });
await page.waitForSelector('.dynamic-element');
const content = await page.$eval('.dynamic-element', el => el.textContent);
console.log('Extracted Content:', content);
This approach ensures that the page has fully loaded its network resources and that the desired element is present in the DOM before proceeding.
Scraping SPAs and JavaScript-Heavy Pages
Single-Page Applications (SPAs) use JavaScript frameworks like React or Vue.js to load content dynamically. These frameworks often require you to interact with the page (e.g., scrolling or clicking) to trigger loading of additional elements.
Here’s how you can handle such scenarios:
-
Simulate Scrolling:
await page.evaluate(() => { window.scrollBy(0, window.innerHeight); }); -
Click to Load More Content:
await page.click('.load-more-button'); await page.waitForSelector('.new-content');
Mix and match to combine methods and easily navigate dynamic pages.
Managing Sessions and Cookies
When scraping websites that require login, managing authentication and sessions becomes important. Logging in repeatedly for each session can slow down the process and may even trigger anti-bot mechanisms. Puppeteer offers tools to save session cookies after authentication, allowing you to reuse them for future scraping sessions without logging in again.
Save Session Cookies
By saving session cookies, you can reuse them to keep the logged-in state across multiple scraping sessions. Here’s how you can log in to Hacker News, save the session cookies, and use them later:
import puppeteer from 'puppeteer-extra';
import fs from 'fs';
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Hacker News login page
await page.goto('https://news.ycombinator.com/login', { waitUntil: 'networkidle0' });
// Enter login credentials
await page.type('input[name="acct"]', '<YOUR-USERNAME>');
await page.type('input[name="pw"]', '<YOUR-PASSWORD>');
// Submit the login form and wait for the page to load
await Promise.all([
page.click('input[value="login"]'),
page.waitForNavigation({ waitUntil: 'networkidle0' })
]);
// Save session cookies to a file for future use
const cookies = await page.cookies();
fs.writeFileSync('cookies_hackernews.json', JSON.stringify(cookies, null, 2));
console.log('Session cookies saved to cookies_hackernews.json');
await browser.close();
})();
in this code, Puppeteer navigates to the Hacker News login page, logs in, and saves the session cookies to a file (cookies_hackernews.json).
Restore Cookies for Future Sessions
Once you’ve saved the session cookies, you can load them in future scraping sessions. This bypasses the login processes.
import puppeteer from 'puppeteer-extra';
import fs from 'fs';
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Load cookies from the saved file
const cookies = JSON.parse(fs.readFileSync('cookies_hackernews.json', 'utf-8'));
await page.setCookie(...cookies);
// Navigate to the Hacker News homepage
await page.goto('https://news.ycombinator.com', { waitUntil: 'networkidle0' });
// Check if the user is logged in by looking for the profile link
const userProfileLink = await page.$('a[href="user?id=your-username"]');
if (userProfileLink) {
console.log('Session restored. You are logged in.');
} else {
console.log('Failed to restore session.');
}
await browser.close();
})();
In this code, the cookies are loaded from the cookies_hackernews.json file and applied to the page using page.setCookie(). Then, it navigates to the content without needing to log in again. It checks for the presence of the user profile link to confirm the session was restored successfully.
The result shows that we’ve successfully logged in by loading the cookies.
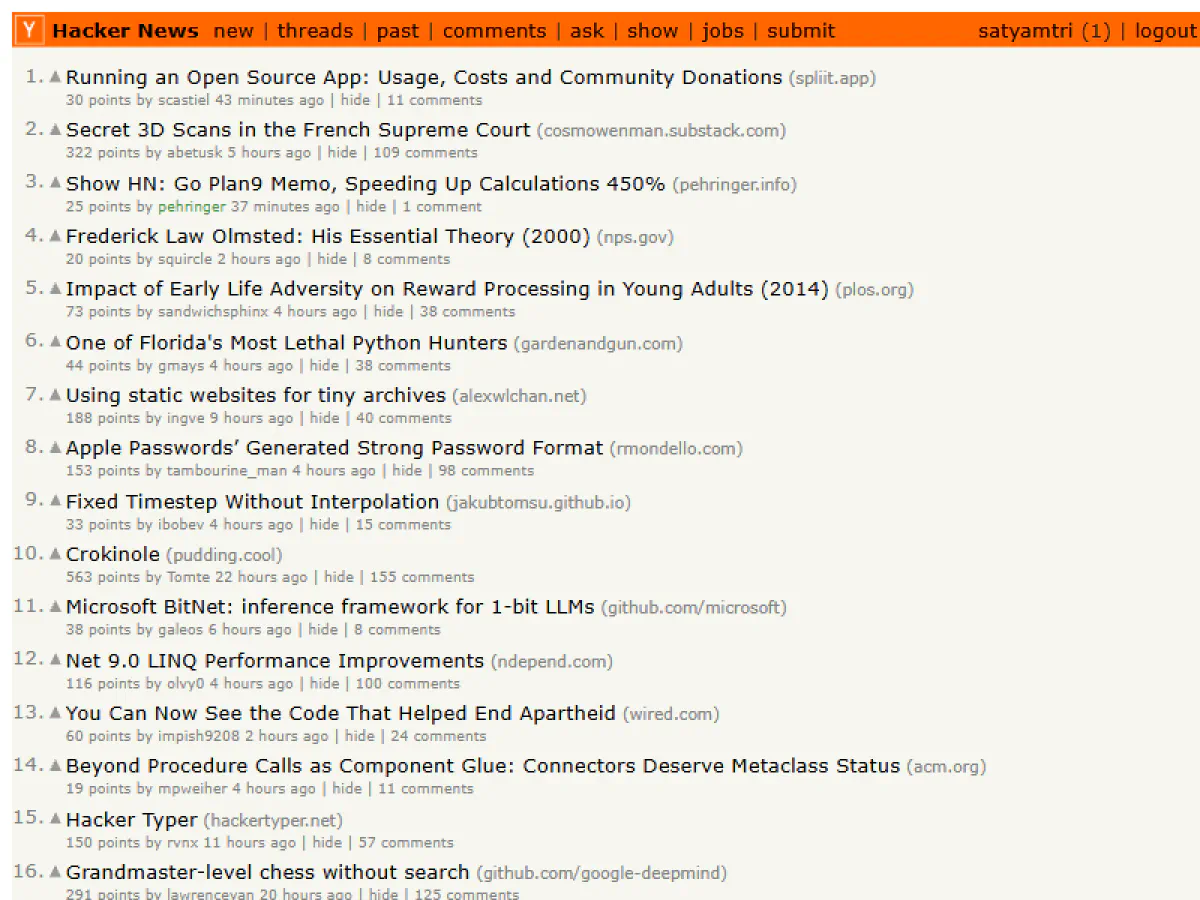
Handling Expired Sessions
Session cookies can expire after a certain time or due to server-side restrictions. It’s important to verify if the session is still valid when restoring cookies. If the session has expired, you’ll need to reauthenticate and save new cookies.
You can check the session status by monitoring the response from the page:
const response = await page.goto('https://news.ycombinator.com');
if (response.status() === 401) { // 401 Unauthorized status indicates the session has expired
console.log('Session expired, logging in again...');
// Re-login and save new session cookies here
}
In this case, if the session has expired, the script will log in again and save new session cookies.
Handling CAPTCHA and Bot Detection
CAPTCHAs are one of the biggest challenges when it comes to web scraping, and they are becoming increasingly sophisticated. But don’t worry, there are effective ways to handle them.
Can CAPTCHA Be Bypassed?
Yes, CAPTCHA challenges can be bypassed, but it’s not always easy. The best approach is to prevent CAPTCHAs from appearing in the first place by mimicking real user behavior. If you do encounter a CAPTCHA, retrying the request with appropriate measures can help.
Solving CAPTCHAs Using Third-Party Services
CAPTCHAs in Puppeteer can be solved using services like 2Captcha, which uses human workers to solve CAPTCHA challenges for you. When you send a CAPTCHA to 2Captcha, a human solves it and sends the answer back to your scraper, which can then use it to bypass the CAPTCHA.
Let’s look at how to solve an hCAPTCHA using 2Captcha on the hCaptcha demo page.
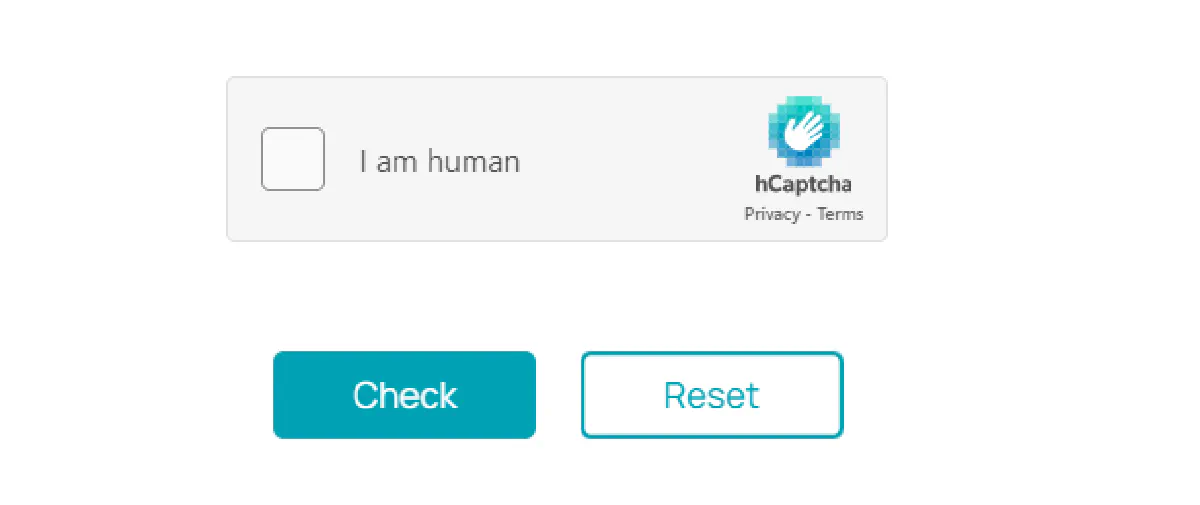
Before proceeding, make sure to install the 2Captcha library:
npm install 2captcha
To solve an hCAPTCHA, you’ll need to extract the data-sitekey property from the CAPTCHA’s HTML structure and pass it to 2Captcha’s API.
Sign up at 2Captcha to get your API key. Replace YOUR_2CAPTCHA_API_KEY in the code below with your actual API key.
import Captcha from '2captcha';
const solver = new Captcha.Solver("YOUR_2CAPTCHA_API_KEY");
solver
.hcaptcha("PUT_DATA_SITEKEY", "https://2captcha.com/demo/hcaptcha")
.then(() => {
console.log("hCAPTCHA passed successfully");
})
.catch((err) => {
console.error(err.message);
});
If successful, the output will show: hCAPTCHA passed successfully. You can use this approach for solving audio CAPTCHAs, reCAPTCHA, and other CAPTCHA types supported by 2Captcha.
Using Free CAPTCHA Solvers
Puppeteer-extra-plugin-recaptcha is a free, open-source plugin that can automate solving reCAPTCHA and hCAPTCHA challenges. You can also integrate it with 2Captcha if you need more advanced CAPTCHA-solving capabilities.
First, install the plugin:
npm install puppeteer-extra-plugin-recaptcha
Then, configure the solver with your 2Captcha API key:
import puppeteer from 'puppeteer-extra';
import RecaptchaPlugin from 'puppeteer-extra-plugin-recaptcha';
// Configure the RecaptchaPlugin with 2Captcha
puppeteer.use(
RecaptchaPlugin({
provider: {
id: '2captcha',
token: 'YOUR_2CAPTCHA_API_KEY',
},
visualFeedback: true, // Shows visual feedback when solving reCAPTCHAs
})
);
Once configured, use page.solveRecaptchas() to automatically solve CAPTCHAs on the target webpage:
puppeteer.launch({ headless: true }).then(async (browser) => {
const page = await browser.newPage();
// Navigate to a page with a reCAPTCHA challenge
await page.goto('https://2captcha.com/demo/recaptcha-v2');
// Solve the reCAPTCHA automatically
await page.solveRecaptchas();
// Submit the form and wait for navigation
await Promise.all([page.waitForNavigation(), page.click('#recaptcha-demo-submit')]);
// Capture a screenshot of the response page
await page.screenshot({ path: 'response.png', fullPage: true });
await browser.close();
});
Preventing CAPTCHA Triggers
Rather than solely relying on CAPTCHA-solving services, it’s a good idea to take steps to prevent CAPTCHAs from being triggered in the first place. Here are some techniques to help avoid bot detection:
1. Simulate Real User Interactions
Acting too quickly can often result in CAPTCHAs being triggered. Mimicking human behavior, such as moving the mouse and scrolling, may help avoid detection.
// Simulating mouse movements
await page.mouse.move(100, 200);
await page.mouse.move(300, 400);
// Simulating page scrolling
await page.evaluate(() => window.scrollBy(0, 500));
2. Rotate User Agents
Changing the user agent string for each request helps avoid detection by making every session appear unique.
const userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/602.3.12 (KHTML, like Gecko) Version/10.1.2 Safari/602.3.12',
'Mozilla/5.0 (iPhone; CPU iPhone OS 10_3 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Version/10.0 Mobile/14E5239e Safari/602.1',
];
// Set a random user agent for each session
const userAgent = userAgents[Math.floor(Math.random() * userAgents.length)];
await page.setUserAgent(userAgent);
3. Add Random Delays
Adding random delays between actions makes your bot’s behavior less predictable and more human-like.
// Adding random delays between actions
await page.waitForTimeout(Math.random() * 1000 + 500); // 500ms to 1500ms delay
4. Use Non-Headless Mode
Some websites can detect when Puppeteer is running in headless mode. Running it in non-headless mode can sometimes bypass detection.
// Launch Puppeteer in non-headless mode
const browser = await puppeteer.launch({ headless: false });
5. Rotate Proxies
Using the same IP address for multiple requests can trigger anti-bot systems. Rotating proxies helps you avoid this by making requests appear to come from different locations.
const proxies = [
'http://username:[email protected]:8080',
'http://username:[email protected]:8080',
'http://username:[email protected]:8080',
];
// Launch browser with a proxy
const browser = await puppeteer.launch({
headless: true,
args: [`--proxy-server=${proxies[Math.floor(Math.random() * proxies.length)]}`],
});
While 2Captcha is great for solving individual CAPTCHAs, it can become expensive for large-scale projects. For a more robust solution, consider using Scrape.do.
Scrape.do offers rotating proxies along with an all-in-one web scraping API that automatically handles CAPTCHAs and anti-bot measures. This allows you to focus on your scraping tasks without the concern of overcoming anti-bot systems.
Here’s how to integrate Scrape.do API:
import axios from 'axios';
import { stringify as querystringStringify } from 'querystring';
// Define API token and target URL
const token = 'YOUR_API_TOKEN';
const targetUrl = 'https://www.g2.com/products/mysql/reviews';
// Base URL for the API
const baseUrl = 'http://api.scrape.do/';
// Construct the query parameters
const queryParams = querystringStringify({
token: token,
url: targetUrl, // The target URL to scrape
render: 'true', // Render the page
waitUntil: 'domcontentloaded', // Wait until the DOM is fully loaded
blockResources: 'true', // Block unnecessary resources from loading
geoCode: 'us', // Set the geolocation for the request
super: 'true' // Use Residential & Mobile Proxy Networks
});
// Full URL with query parameters
const apiUrl = `${baseUrl}?${queryParams}`;
// Send GET request to the API
try {
const response = await axios.get(apiUrl);
// Print the response status code and content
console.log('Status Code:', response.status);
console.log(response.data);
} catch (error) {
console.error('Error:', error.response ? error.response.status : error.message);
}
When you execute this code, it bypasses CAPTCHAs and retrieves the HTML content from G2’s review page.
The result would be:
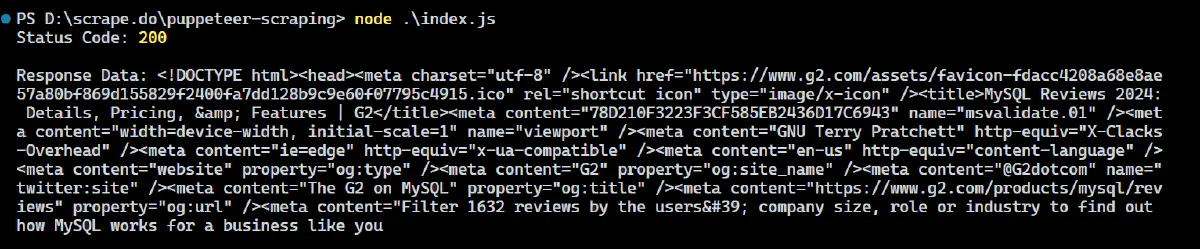
Amazing! You’ve successfully bypassed a Cloudflare-protected website and scraped its full-page HTML using Scrape.do 🚀
Optimizing Performance for Large-Scale Scraping
When scraping a large number of pages, optimizing memory usage and managing multiple browser contexts efficiently becomes critical. Let’s see some techniques for reducing memory overhead and scaling scraping operations in Puppeteer.
Reducing Memory Footprint
Puppeteer can consume a lot of memory, especially when scraping multiple pages at once. Here are some key strategies to optimize memory usage:
- Limit Concurrent Pages: Opening too many pages at once can quickly increase memory consumption. Make sure to open only the necessary number of pages and close them immediately after completing their tasks.
- Reuse a Single Browser Instance: Instead of launching a new browser for each task, reuse a single instance to reduce memory overhead.
- Close Unnecessary Tabs: Closing tabs as soon as they finish scraping is crucial for managing memory efficiently. This reduces the overall memory footprint of the script.
Here’s an example of how to optimize memory usage when scraping multiple pages with Puppeteer:
import puppeteer from 'puppeteer-extra';
(async () => {
const browser = await puppeteer.launch({ headless: true });
try {
// Task 1: Scrape product title from Nike new arrivals page
const page1 = await browser.newPage();
await page1.goto('https://www.nike.com/w/new-arrivals', { waitUntil: 'domcontentloaded' });
const productTitle1 = await page1.$eval('.product-card__title', el => el.innerText);
console.log('Product 1 Title:', productTitle1);
await page1.close(); // Close the page to free memory
// Task 2: Scrape product title from Nike best sellers page
const page2 = await browser.newPage();
await page2.goto('https://www.nike.com/w/best-76m50', { waitUntil: 'domcontentloaded' });
const productTitle2 = await page2.$eval('.product-card__title', el => el.innerText);
console.log('Product 2 Title:', productTitle2);
await page2.close(); // Close the page to free memory
} catch (error) {
console.error('Error during scraping:', error);
} finally {
await browser.close();
}
})();
In this code, we reuse a single browser instance to scrape multiple pages and each page is closed immediately after the data is scraped to free up memory and avoid leaving unnecessary tabs open.
Handling Large-Scale Scraping with Puppeteer Cluster
When dealing with large-scale scraping, Puppeteer Cluster is an ideal solution. It allows you to manage multiple browser instances and distribute scraping tasks in parallel, improving both speed and resource efficiency.
To get started with Puppeteer Cluster, install it using npm:
npm install puppeteer-cluster
Here’s an example of how to use Puppeteer Cluster to scrape multiple pages concurrently:
import { Cluster } from 'puppeteer-cluster';
(async () => {
// Create a cluster with a limited number of workers (browsers)
const cluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_BROWSER,
maxConcurrency: 3, // Limit to 3 concurrent browsers
puppeteerOptions: { headless: true }
});
// Define a task to scrape product titles from Nike pages
await cluster.task(async ({ page, data: url }) => {
await page.goto(url, { waitUntil: 'networkidle0' });
const productTitle = await page.evaluate(() => {
const element = document.querySelector('.product-card__title');
return element ? element.innerText : 'No title found';
});
console.log(`Scraped from ${url}: ${productTitle}`);
});
// Queue multiple Nike URLs for scraping
cluster.queue('https://www.nike.com/w/new-arrivals');
cluster.queue('https://www.nike.com/w/mens-new-shoes-3n82yznik1zy7ok');
cluster.queue('https://www.nike.com/w/womens-new-shoes-5e1x6zy7ok');
cluster.queue('https://www.nike.com/w/kids-new-shoes-3upxznik1zy7ok');
cluster.queue('https://www.nike.com/w/new-backpacks-bags-3rauvznik1');
// Wait for the cluster to finish all tasks
await cluster.idle();
await cluster.close();
})();
In this code:
- We create a cluster with a maximum of 3 concurrent headless browsers using
maxConcurrency: 3. This ensures that only 3 pages are scraped at the same time. - The
cluster.task()method defines the logic for scraping the product title from each Nike page. - URLs are queued using
cluster.queue(), and each page is scraped concurrently.
The result might look like:
Scraped from https://www.nike.com/w/new-3n82y: Nike C1TY “Surplus”
Scraped from https://www.nike.com/w/blazer-shoes-9gw3azy7ok: Nike Blazer Mid '77 Vintage
Scraped from https://www.nike.com/w/best-76m50: Nike Air Force 1 '07
Scraped from https://www.nike.com/w/zoom-vomero-shoes-7gee1zy7ok: Nike Zoom Vomero 5
Scraped from https://www.nike.com/w/air-max-shoes-a6d8hzy7ok: Nike Air Max Dn
Advanced Error Handling and Debugging
When scraping dynamic websites, you’re likely to encounter issues like timeouts, failed navigation, and delayed content loading. To make scraping more reliable, it’s important to implement robust error handling, custom retry logic, and use Puppeteer’s debugging tools.
Common Challenges in Web Scraping
Scraping modern websites comes with a variety of challenges:
- Timeouts: Dynamic content can take longer to load, causing timeouts.
- Navigation Failures: Pages may not load properly due to network issues or errors.
- Dynamic Content: Asynchronous loading can cause elements to appear late, affecting your scraping logic.
- Network Errors: Unstable network conditions may interrupt API calls or page loads.
Handling Timeouts and Navigation Errors
Timeouts and navigation errors are common when dealing with slow-loading pages or unstable networks. Puppeteer’s try/catch block can help you handle these issues gracefully and retry actions if needed.
Let’s see how to handle timeouts and errors while navigating to the Nike page.
import puppeteer from 'puppeteer-extra';
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
try {
// Navigate to the Nike page with error handling for potential timeouts
await page.goto('https://www.nike.com/w/new-arrivals', { waitUntil: 'networkidle0', timeout: 10000 });
console.log('Page loaded successfully.');
} catch (error) {
if (error.name === 'TimeoutError') {
console.error('Page load timed out after 10 seconds:', error.message);
} else {
console.error('Navigation error occurred:', error.message);
}
} finally {
await browser.close();
}
})();
In this code, we load the page and wait for the network to be idle. If the page takes longer than 10 seconds, a TimeoutError is triggered. The script catches this error and prevent it from crashing.
Waiting for Dynamic Content to Load
As discussed earlier, websites like Nike load products dynamically, often through AJAX calls. Puppeteer’s page.waitForSelector() method helps you wait for specific elements to load before scraping the content.
In the code below, we wait for product cards to appear on the Nike page before extracting product information.
import puppeteer from 'puppeteer';
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
try {
// Navigate to the page
await page.goto('https://www.nike.com/w/new-arrivals', { waitUntil: 'networkidle0' });
// Wait for product cards to appear
await page.waitForSelector('.product-card__body', { timeout: 5000 });
// Extract product information from each card
const products = await page.$$eval('.product-card__body', items => {
return items.map(item => ({
name: item.querySelector('.product-card__title')?.innerText || 'No Name',
price: item.querySelector('.product-price')?.innerText || 'No Price',
link: item.querySelector('a.product-card__link-overlay')?.href || 'No Link'
}));
});
console.log('Extracted Products:', products);
} catch (error) {
console.error('Error occurred while fetching product data:', error);
} finally {
await browser.close();
}
})();
In this code, page.waitForSelector() ensures that the product listings are fully loaded before we attempt to scrape the data. If the elements don’t load within 5 seconds, an error is thrown and handled in the catch block.
Implementing Retry Logic
Sometimes, even after handling timeouts, actions may still fail due to temporary issues, such as slow network responses. To make your scraping script more robust, you can implement retry logic that retries an action multiple times before giving up.
Below is an example of a custom retry() function that attempts the page navigation up to 3 times with a delay between each try.
import puppeteer from 'puppeteer';
// Custom retry function to retry an action up to a specified number of times
const retry = async (fn, retries = 3, delay = 2000) => {
for (let i = 0; i < retries; i++) {
try {
return await fn(); // Try to execute the function
} catch (error) {
console.error(`Attempt ${i + 1} failed: ${error.message}`);
if (i < retries - 1) {
console.log(`Retrying in ${delay}ms...`);
await new Promise(res => setTimeout(res, delay)); // Wait before retrying
} else {
console.error('All retry attempts failed.');
throw error;
}
}
}
};
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
try {
// Retry navigation with up to 3 attempts
await retry(() => page.goto('https://www.nike.com/w/new-arrivals', { waitUntil: 'networkidle0', timeout: 10000 }), 3, 2000);
// Wait for product cards to load
await page.waitForSelector('.product-card__body', { timeout: 5000 });
// Scrape product data
const products = await page.$$eval('.product-card__body', items => {
return items.map(item => ({
name: item.querySelector('.product-card__title')?.innerText || 'No Name',
price: item.querySelector('.product-price')?.innerText || 'No Price',
link: item.querySelector('a.product-card__link-overlay')?.href || 'No Link'
}));
});
console.log('Extracted Products:', products);
} catch (error) {
console.error('Error occurred during scraping:', error);
} finally {
await browser.close();
}
})();
Debugging Techniques in Puppeteer
Puppeteer offers several debugging tools to help you diagnose issues like missing elements, JavaScript errors, or unexpected behavior.
-
Browser Logs: Capture browser logs using
page.on('console')to debug issues happening in the browser.page.on('console', msg => { console.log(`Browser log: ${msg.text()}`); }); await page.goto('https://www.nike.com/w/new-arrivals'); -
Verbose Logging: Enable detailed logging for Puppeteer’s actions by setting the
DEBUGenvironment variable. This helps track navigation events, network requests, and errors.DEBUG="puppeteer:*" node your-script.jsThis prints detailed logs of Puppeteer’s internal actions, which is useful for diagnosing navigation and selection issues.
Handling Specific Errors
It’s important to handle specific errors when scraping. For example, if an element you expect to scrape doesn’t appear on the page, you can catch and log the error without crashing the script.
try {
const element = await page.$('.non-existent-class');
if (!element) {
console.error('Element not found.');
} else {
const text = await element.evaluate(el => el.innerText);
console.log('Element Text:', text);
}
} catch (error) {
console.error('Error fetching element:', error.message);
}
Capturing Network Errors
Network failures, such as an API returning an error, can also be captured using Puppeteer’s page.on('response') event.
page.on('response', response => {
if (!response.ok()) {
console.error(`Network error: ${response.url()}`);
}
});
This logs network errors that occur during API calls or page loads, helping you troubleshoot connection issues.
Exporting Scraped Data
Once you’ve successfully scraped your target data, the next step is to save it in a format that suits your needs. Common formats for exporting data include CSV, JSON, and databases. Puppeteer provides the flexibility to extract and save data easily.
Saving Data to JSON
JSON is a lightweight format that’s widely used for storing and transmitting structured data. Here’s how to save scraped data to a JSON file:
const fs = require('fs');
(async () => {
const data = [
{ name: 'Product 1', price: '$10' },
{ name: 'Product 2', price: '$20' }
];
fs.writeFileSync('data.json', JSON.stringify(data, null, 2));
console.log('Data saved to data.json');
})();
The JSON.stringify function converts the data into JSON format, and the fs.writeFileSync method writes it to a file.
Saving Data to CSV
CSV is ideal for working with data in spreadsheet software like Excel or Google Sheets. Here’s how to save data in CSV format:
const fs = require('fs');
const { parse } = require('json2csv');
(async () => {
const data = [
{ name: 'Product 1', price: '$10' },
{ name: 'Product 2', price: '$20' }
];
const csv = parse(data);
fs.writeFileSync('data.csv', csv);
console.log('Data saved to data.csv');
})();
The json2csv library converts the JSON object into a CSV string, which can then be written to a file using fs.writeFileSync.
Exporting to a Database
For large-scale scraping projects, exporting data directly into a database can be more efficient. Here’s an example using MySQL:
-
Install MySQL Package:
npm install mysql2 -
Insert Data into the Database:
const mysql = require('mysql2/promise'); (async () => { const connection = await mysql.createConnection({ host: 'localhost', user: 'root', password: '', database: 'scraped_data' }); const data = [ ['Product 1', '$10'], ['Product 2', '$20'] ]; await connection.query( 'CREATE TABLE IF NOT EXISTS products (name VARCHAR(255), price VARCHAR(255))' ); await connection.query( 'INSERT INTO products (name, price) VALUES ?', [data] ); console.log('Data saved to database'); await connection.end(); })();
This example creates a table (if it doesn’t already exist) and inserts the scraped data into the products table.
Best Practices for Exporting Data
-
Validate Your Data: Always clean and validate your data before saving to ensure accuracy and consistency.
-
Handle Errors Gracefully: Implement error handling to ensure the export process doesn’t fail:
try { fs.writeFileSync('data.json', JSON.stringify(data)); } catch (error) { console.error('Error saving data:', error); } -
Choose the Right Format: Pick a format that aligns with how the data will be used (e.g., JSON for APIs, CSV for spreadsheets, databases for scalability).
To Sum Up
From managing dynamic content and sessions to bypassing anti-bot mechanisms and optimizing performance for large-scale projects, Puppeteer offers unmatched flexibility and control.
However, even with the best tools, certain challenges like proxy management, CAPTCHA solving, and rate-limiting can slow you down.
That’s where Scrape.do becomes a game-changer.
With its reliable rotating proxies, built-in CAPTCHA-solving features, and infrastructure designed for scalable scraping, Scrape.do seamlessly integrates with Puppeteer to simplify complex tasks and accelerate your workflows.
By combining Puppeteer’s capabilities with Scrape.do’s powerful infrastructure, you can take your scraping projects to the next level, saving time and ensuring efficiency.
Unlock the web’s full potential with Scrape.do, start with 1000 FREE credits.


Lead Software Engineer
I am a software engineer and live in Spain. I use JavaScript and python. Dealing with hard to crawl websites is my hobby :)