Category:Scraping Use Cases
Scraping Mouser: Extract Products, Prices, and Stock Availability Data

Full Stack Developer



Mouser Electronics is the leading distributor of electronic components, supplying millions of products to engineers, businesses, and hobbyists all over the world.
If you’ve tried scraping Mouser for pricing and product details, you’ve probably run into blocks.
The site uses Akamai bot protection, region-based pricing, and aggressive IP filtering, making traditional scraping methods unreliable.
But with the right approach, you can extract product data without getting blocked.
In this guide, we’ll break down why Mouser is difficult to scrape, what protections it uses, and how to bypass them using Scrape.do.
Find the fully-functioning code here. ⚙
Why Scraping Mouser Is Difficult
Mouser has built strong defenses to prevent automated data collection, making traditional scraping techniques unreliable.
Looking at the website, you'll understand that it's vastly different from your typical ecommerce site, full of tables for product listings that make scraping difficult tough on its own.
In addition to being this much different, there are active precautions Mouser is taking to prevent bot traffic:
Akamai Bot Protection
Mouser uses Akamai’s bot management system to detect and block scrapers.
It analyzes requests for signs of automation through JavaScript challenges, TLS fingerprinting, and behavior tracking. If a request doesn't mimic real user behavior—such as mouse movements and browser interactions, it gets blocked instantly.
Standard HTTP requests fail because they don’t execute the required browser-based scripts.
Region-Based Pricing & Access Controls
Pricing and product availability on Mouser depend on the user’s location, meaning the same page may display different prices depending on where the request originates.
Frequent IP switching, especially from datacenter proxies, can trigger access restrictions, leading to incomplete or blocked results.
How Scrape.do Bypasses These Challenges
Scrape.do is a web scraping API that is a swiss-knife for web scrapers.
It can confidently handle any anti-bot measures Mouser can throw at you, and more.
It enables you to scrape any website by rendering JavaScript, managing sessions, and routing requests through geo-targeted residential and ISP proxies. 🔑
This ensures stable access to product data without triggering security blocks, making it possible to extract Mouser’s pricing and product details reliably.
Let's see it in action:
Extracting Data from Mouser Without Getting Blocked
As a practice challenge, we’ll extract product names and prices from Mouser’s LED bulb category.
Prerequisites
Before making any requests, install the required dependencies if you haven’t already:
pip install requests beautifulsoup4You'll also need an API key from Scrape.do, which you can obtain by signing up for FREE.
For this guide, we’ll be working with the Mouser LED Bulbs & Modules category.
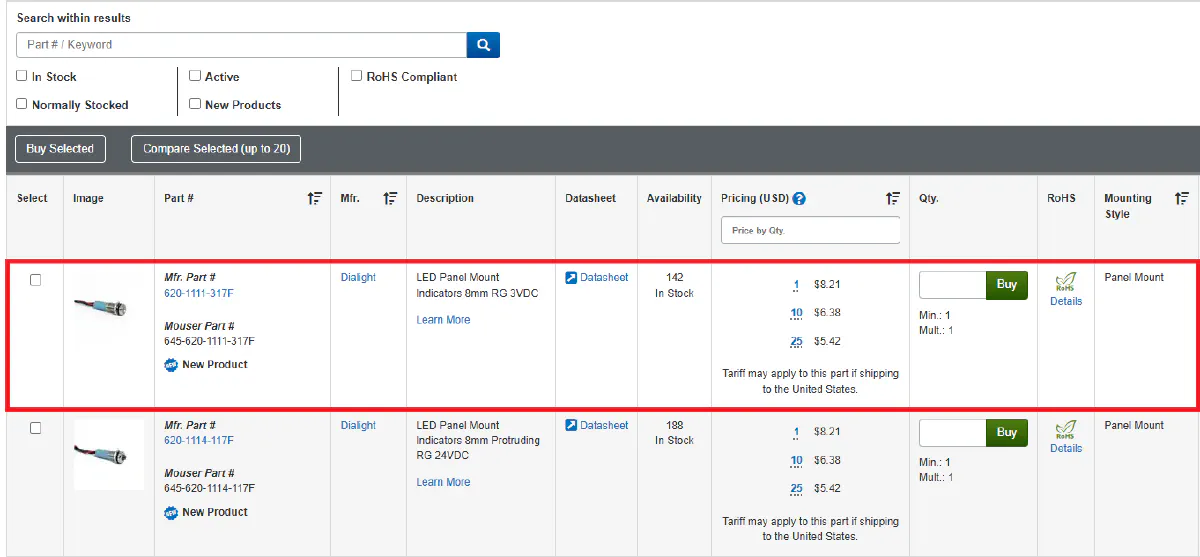
Don't be intimidated by all the rows and columns of products, it's much easier than scraping Amazon when you get used to it.
Sending a Request and Verifying Access
First things first.
To ensure we can access the page without being blocked, we’ll send a request through Scrape.do and check for a 200 OK response.
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Mouser LED bulb category URL
target_url = urllib.parse.quote_plus("https://www.mouser.com/c/optoelectronics/led-lighting/led-bulbs-modules/")
# Optional parameters
render = "true"
geo_code = "us"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Print response status
print(response)This is the output we're expecting:
<Response [200]>If the request is successful, we can proceed with extracting the product name.
Extracting the Product Name
With a successful response from the target page, we can now extract the product name from the HTML. The product name is stored inside a <span> tag within a <td> element that has the class "column desc-column hide-xsmall".
💡 Keep in mind that this code will extract only the item located at the top of the table in the category page, so outputs might change. But, as long as you're getting data, the code works.
Using BeautifulSoup, we’ll locate this element and retrieve the text content.
from bs4 import BeautifulSoup
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Mouser LED bulb category URL
target_url = urllib.parse.quote_plus("https://www.mouser.com/c/optoelectronics/led-lighting/led-bulbs-modules/")
# Optional parameters
render = "true"
geo_code = "us"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract product name
name = soup.find("td", class_="column desc-column hide-xsmall").find("span").text.strip()
print("Product Name:", name)If the script runs correctly, you should see the extracted product name printed in the terminal.
Product Name: LED Panel Mount Indicators 8mm RG 3VDCNow that we have the product name, we’ll proceed to extracting the most useful information on this page.
Extracting the Product Price
The next step is to retrieve the price.
On Mouser, there are different pricings based on how many of that item you're looking to buy, but for the sake of practice we'll only extract the price for buying a single item.
The price is located inside a <span> tag within a <td> element that has the ID "lblPrice_1_1".
We’ll locate this element and extract the price text.
from bs4 import BeautifulSoup
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Mouser LED bulb category URL
target_url = urllib.parse.quote_plus("https://www.mouser.com/c/optoelectronics/led-lighting/led-bulbs-modules/")
# Optional parameters
render = "true"
geo_code = "us"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract product name
name = soup.find("td", class_="column desc-column hide-xsmall").find("span").text.strip()
# Extract product price using span id
price = soup.find("span", id="lblPrice_1_1").text.strip()
print("Product Name:", name)
print("Product Price:", price)If the script runs successfully, you should see the extracted price below the product name displayed in the terminal.
Product Name: LED Panel Mount Indicators 8mm RG 3VDC
Product Price: $8.21With both the product name and price extracted, we’ve successfully scraped the key details from Mouser.
💡 To get all the items in the category, you can command BeautifulSoup to operate on every single row until the end of the page, and add additional code to check next pages of the category by manipulating URL to check "/?pg=2" extensions until you run into a 404 Not Found status.
Conclusion
Scraping Mouser is challenging due to Akamai bot protection, dynamic pricing, and strict access controls, but it’s not impossible.
By leveraging Scrape.do, we bypassed these restrictions and successfully extracted both the product name and price from the LED bulb category.
Instead of relying on tradit ional scraping methods that get blocked, we used browser-based rendering and geo-targeted IPs to ensure stable access.
If you need to scrape Mouser without dealing with blocks, Scrape.do makes it simple.
Full Stack Developer








