Category:Scraping Basics
6 Ways to Scrape A JavaScript-Rendered Web Page in Python

Founder @ Scrape.do


You load a webpage, see the content, and think this should be easy to scrape.
Then you run your script and get nothing.
No data.
Just empty HTML. 😓
Welcome to JavaScript-rendered websites, where traditional scrapers fail.
I'll walk you through 6 different methods to extract dynamic content using Python, from quick API calls to advanced browser automation.
Here's a quick comparison if you want to skip the fluff:
| Method | Best For | Strength | Weakness | Avg Speed* | GitHub |
|---|---|---|---|---|---|
| Requests-HTML | Simple scripts | Easy to use, no setup | Slow, not scalable | ~4.4 s | 🔗 |
| Scrape.do | Fast, scalable scraping | Fast, cloud-rendered, handles blocks | Paid for high usage | ~3.2 s | 🔗 |
| Selenium | Full browser automation | Human-like control, reliable JS support | Heavy, slow, setup required | ~5.5 s | 🔗 |
| Playwright | High-performance scraping | Fast, modern JS support, multi-browser | Heavier setup than Requests-HTML | ~3.4 s | 🔗 |
| Pyppeteer | Chromium-only automation | Lightweight, fast for Chrome | Limited browser support | ~4.0 s | 🔗 |
| Scrapy + Splash | Large-scale JS crawling | Built-in crawling, cache support | Outdated JS engine, setup needed | ~6.0 s | 🔗 |
*based on a small-scale test to load tables from this demo scraping page.
Why and How Is Scraping JavaScript-Rendered Pages Different?
Most web scraping tutorials show how to extract data using simple HTTP requests.
In many cases, this works; the server responds with a full HTML page containing all the content. You parse it, extract what you need, and you’re done.
But this approach fails completely on JavaScript-heavy websites. Instead of returning usable content, you get an empty shell; no text, no data, just a basic HTML structure.
Static vs. JavaScript-Rendered Content
Websites generally fall into two categories:
🏗️ Static Websites: The entire HTML is sent by the server and contains all the data needed. You can scrape them easily with requests and BeautifulSoup.
⚙️ JavaScript-Rendered Websites: The server sends a minimal HTML structure; JavaScript loads additional content dynamically, often fetching data through API calls.
For JavaScript-heavy sites, traditional scrapers only receive the initial HTML, which does not include the content generated after JavaScript execution. This is why scraping methods that can execute JavaScript and wait for the final content are necessary.
How JavaScript Alters the Scraping Process
When a browser loads a JavaScript-heavy website, the process works like this:
- The browser sends an initial request to the server, which responds with a basic HTML structure.
- The browser loads and executes JavaScript, which triggers additional API requests.
- The page updates dynamically, injecting new content into the DOM (Document Object Model).
- Only after JavaScript execution is complete does the page contain all the data you see.
A simple HTTP request never triggers this JavaScript execution, meaning scrapers miss most of the page’s content.
💡 Because JavaScript execution doesn't happen instantly, when scraping JS-rendered websites you'll probably also need to ask your scraper to wait for a few seconds or until the website is done loading.
Let's Give It a Try (and Fail)
Before we explore the right solutions, let's attempt the simplest scraping approach and see why it fails on JavaScript-heavy websites. This will also serve as our setup guide, ensuring you have everything ready to follow along.
Setting Up the Environment
Ensure you have Python installed (3.7+ recommended). We’ll also need a few essential libraries, which can be installed using:
pip install requests beautifulsoup4requestsallows us to send HTTP requests and retrieve raw HTML.beautifulsoup4is commonly used for parsing and extracting data from HTML documents.
Since Oscars happened just last week, we’ll be working with this example page, which lists Oscar-winning films from 2015. .
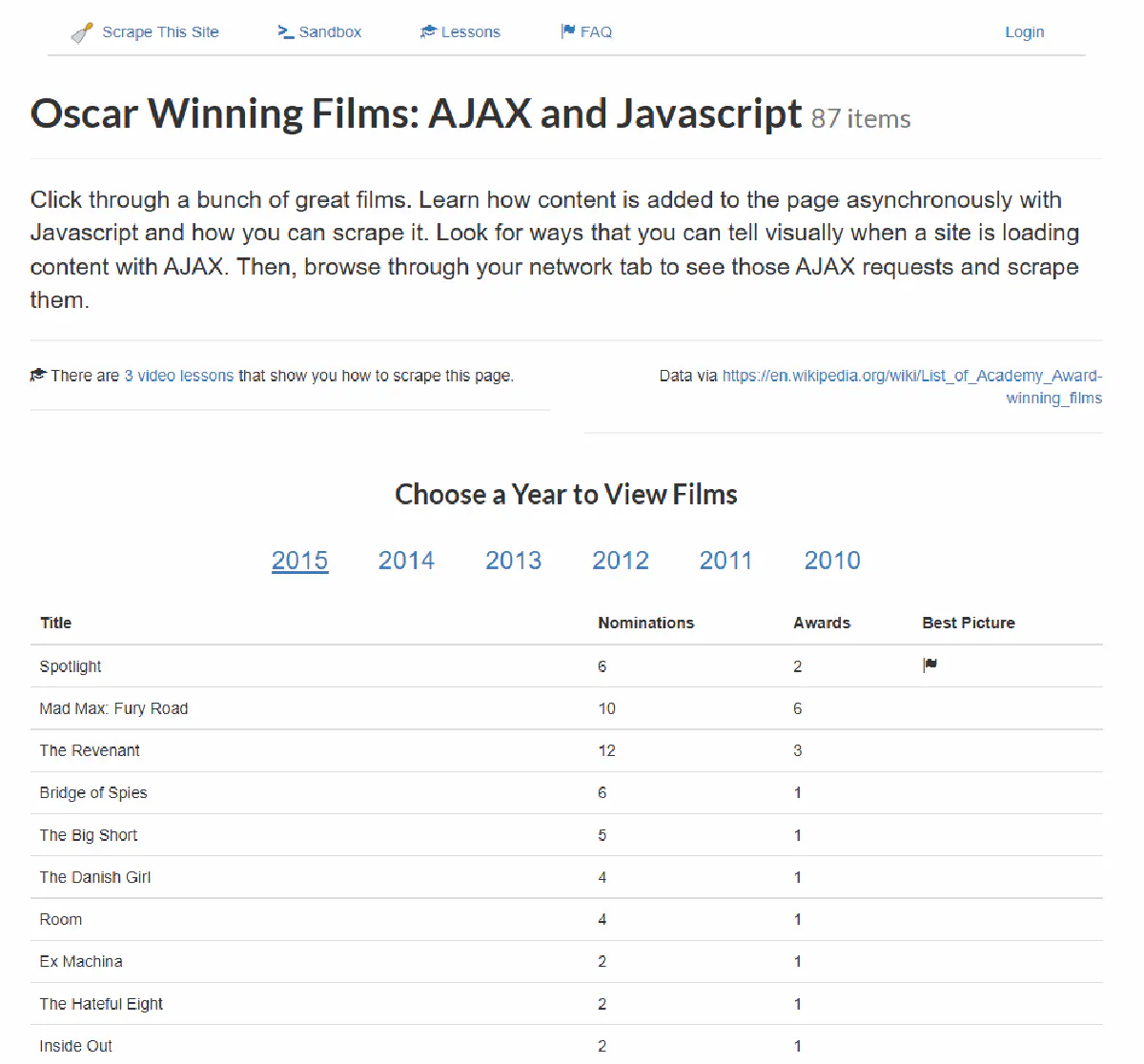
This page does not include any movie data in its initial HTML. Instead, it dynamically loads film titles, nominations, and awards when a user selects a year.
The data is fetched using JavaScript and displayed in the table after the page loads.
If we try to scrape this page using a simple request, we should expect to see movie details in the response.
But will we?
Let's find out.
Basic Request
This is the simplest request you can send using requests.
import requests
url = "https://www.scrapethissite.com/pages/ajax-javascript/#2015"
response = requests.get(url)
print(response.text)If we send the request like this, here's the output we get for the table section:
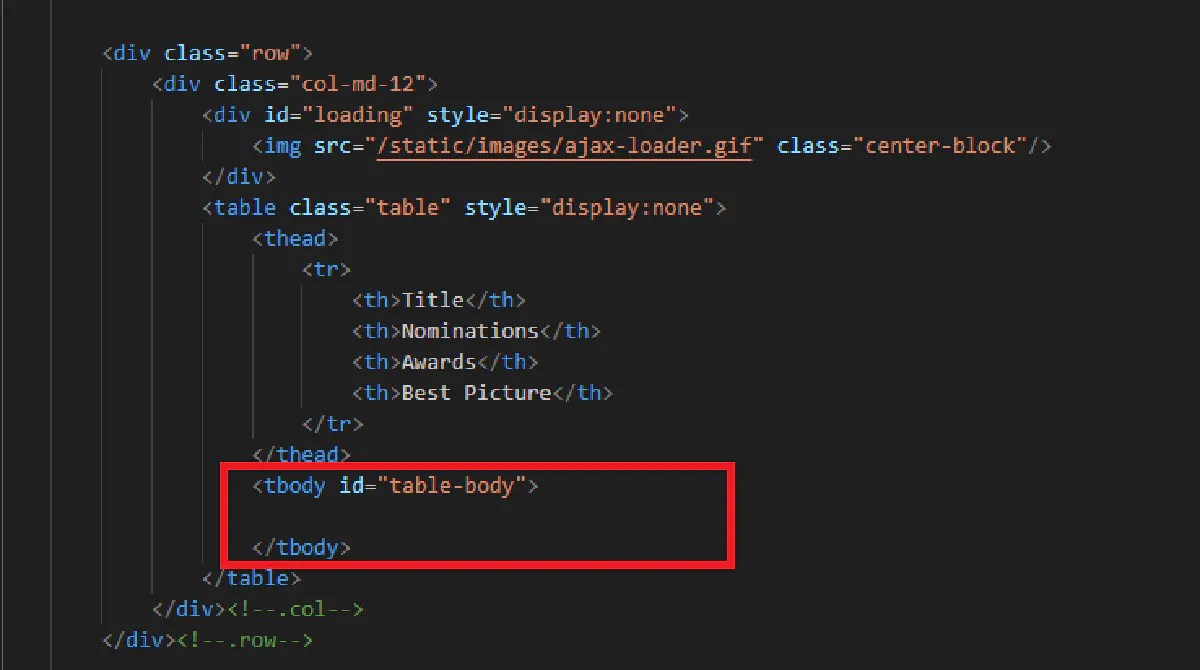
In the HTML response, the code for the table is there, but as you can see the table body is empty.
This happens because the website fetches movie details asynchronously using JavaScript, meaning a standard HTTP request won't execute the necessary JavaScript to load the data.
This confirms that we need a different approach, one that waits for JavaScript execution before extracting the data.
So let's review the top tools and methods we can use (and how to use them) to load JS-rendered pages.
1. Requests-HTML (most basic)
Now that we've confirmed a basic request doesn't work, let's start with the simplest method to execute JavaScript: Requests-HTML. This is a lightweight Python library that extends requests with a built-in headless browser for JavaScript execution.
Requests-HTML allows us to send an HTTP request and then render JavaScript within the same session. Unlike heavier browser automation tools, it provides a simple .render() method that spins up a headless Chromium instance, executes JavaScript, and waits for the page to fully load before extraction.
How It Works
- We send an HTTP request to fetch the page.
- We call
.render(wait=2), which ensures JavaScript runs before extracting content. - The fully rendered HTML is now accessible for parsing.
Pros & Cons
✅ Simple and lightweight compared to full browser automation.
✅ Works within a Python script without requiring external WebDriver setups.
❌ Not designed for large-scale scraping; it starts a new browser session each time .render() is called, making it inefficient for bulk tasks.
❌ Lacks advanced anti-bot handling, so it may not work on sites with strict protection.
Code Example and Output
Let's try scraping the Oscar-winning films page using Requests-HTML.
from requests_html import HTMLSession
session = HTMLSession()
response = session.get("https://www.scrapethissite.com/pages/ajax-javascript/#2015")
response.html.render(wait=2) # Ensures JavaScript execution before extraction
print(response.html.html[:500]) # Print first 500 characters of the rendered HTMLThis will successfully fetch the data inside the table:
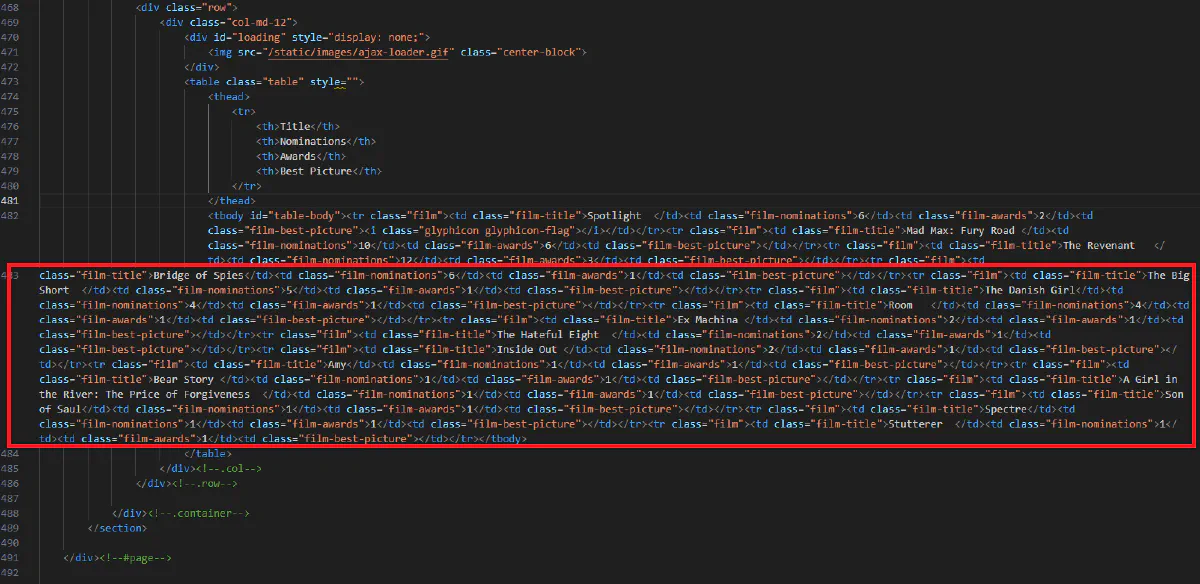
(I know the code is structured horribly here, which will be the case for most JavaScript rendered content. That's why we're parsing 🙂)
This method works well for small-scale tasks where JavaScript execution is necessary.
However, since it launches a new browser instance each time, it is not the most efficient choice for scraping multiple pages.
2. Scrape.do (simple, fast, reliable)
While Requests-HTML allows us to execute JavaScript locally, web scraping APIs offer a faster and more scalable alternative. These APIs handle JavaScript rendering, proxy rotation, and CAPTCHA solving on their own servers, returning fully rendered HTML with a simple HTTP request.
Among them, Scrape.do is the most efficient, offering high-speed JavaScript execution, IP management, and effortless scraping without the need for setting up a browser.
How It Works
We send an API request with render=true, telling Scrape.do to load the page like a real browser.
Scrape.do executes JavaScript on its cloud servers, ensuring that all dynamic content is fully loaded.
The final HTML is returned, ready for parsing.
To ensure that JavaScript execution is completed before extracting data, we use the waitUntil parameter. Scrape.do defaults to domcontentloaded, but for JavaScript-heavy pages, we use waitUntil=networkidle0. This makes Scrape.do wait until all network activity has stopped, ensuring that no content is missing.
Pros & Cons
✅ Fast – Offloads JavaScript execution to optimized cloud infrastructure, making it significantly faster than local headless browsers.
✅ Scalable – Supports multiple parallel requests, making it efficient for bulk scraping.
✅ Bypasses Anti-Scraping – Built-in proxy rotation and CAPTCHA solving help prevent blocks.
❌ Paid Solution – Free tier is available but requires an API key for large-scale scraping.
❌ Network Latency – API requests introduce slight overhead compared to local scraping, but they are still faster than running a headless browser manually.
Code Example
Let's use Scrape.do to scrape the target page and ensure that JavaScript executes properly.
import requests
import urllib.parse
token = "<YOUR_SCRAPEDO_TOKEN>" # Replace with your Scrape.do API token
target_url = urllib.parse.quote_plus("https://www.scrapethissite.com/pages/ajax-javascript/#2015")
api_url = f"http://api.scrape.do/?token={token}&url={target_url}&render=true&waitUntil=networkidle0"
response = requests.get(api_url)
print(response.text) # Prints all content of rendered HTMLThis will successfully fetch the data inside the table.
Scrape.do provides a fast, scalable, and maintenance-free solution for JavaScript-heavy websites.
Instead of setting up headless browsers and managing proxies, you just make an API request and get the full page.
And it's FREE with 1000 monthly successful API requests!
3. Selenium (popular solution)
While web scraping APIs like Scrape.do provide a server-side solution for JavaScript execution, some use cases require full browser control. Selenium allows us to interact with web pages just like a human—loading content, clicking buttons, and even scrolling dynamically rendered pages.
Selenium is widely used for browser automation and testing, but it is also an effective tool for scraping JavaScript-heavy websites when simpler methods fail.
How It Works
We launch a real browser (Chrome, Firefox, or Edge) using Selenium’s WebDriver.
The browser loads the target page and executes all JavaScript before returning the fully rendered HTML.
We extract the page content using driver.page_source, ensuring we capture the data after JavaScript execution.
Since JavaScript execution takes time, we use Selenium’s waiting methods to ensure content is fully loaded before extraction.
Pros & Cons
✅ Full browser control – Allows interaction with JavaScript-heavy pages, including clicking, scrolling, and form submissions.
✅ Handles dynamic content – Ensures JavaScript has executed before scraping data.
❌ Slow – Running a real browser introduces significant overhead, making it slower than API-based solutions.
❌ Requires setup – Needs WebDriver installation and more system resources compared to other methods.
Code Example
Here's the Python code that uses Selenium to render and scrape our target website.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True # Run in headless mode (no UI)
options.add_argument("--disable-gpu") # Prevents GPU-related issues
options.add_argument("--no-sandbox") # Required for some environments
driver = webdriver.Chrome(options=options)
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/#2015")
# Wait for JavaScript execution (implicit wait)
driver.implicitly_wait(5)
print(driver.page_source[:500]) # Print first 500 characters of the rendered HTML
driver.quit()Once executed, this should print out the table.
Selenium is powerful for interacting with JavaScript-heavy pages, but its speed limitations make it less efficient for bulk scraping.
4. Playwright
Selenium allows us to control a real browser, but it comes with performance limitations.
Playwright, a modern browser automation tool from Microsoft, offers a faster and more efficient alternative by directly communicating with browsers using the DevTools Protocol.
Unlike Selenium, Playwright supports multiple browsers (Chromium, Firefox, WebKit) and parallel scraping, making it an excellent choice for JavaScript-heavy websites.
How It Works
We launch a headless browser (Chromium, Firefox, or WebKit) using Playwright’s automation API.
Playwright waits for JavaScript execution to complete before extracting content.
We retrieve the fully rendered HTML using page.content(), ensuring all elements are present before scraping.
Since JavaScript-heavy sites load content dynamically, we use Playwright’s built-in waiting mechanisms (wait_for_selector(), networkidle) to ensure the page is fully loaded.
Pros & Cons
✅ Faster than Selenium – Uses the DevTools Protocol for direct browser communication, reducing execution time.
✅ Multi-browser support – Works with Chromium, Firefox, and WebKit, making it more versatile.
✅ Handles dynamic content – Supports scrolling, waiting for elements, and intercepting network requests.
❌ Requires installation – Needs the Playwright package and browser binaries before use.
❌ More complex setup – Requires a slightly more advanced understanding compared to Selenium.
Code Example
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True) # Run headless browser
page = browser.new_page()
page.goto("https://www.scrapethissite.com/pages/ajax-javascript/#2015", wait_until="networkidle")
print(page.content()[:500]) # Print first 500 characters of the rendered HTML
browser.close()The page should return full content with this code.
Playwright provides high-speed JavaScript execution with better performance than Selenium, making it a strong choice for scraping JavaScript-heavy websites.
5. Pyppeteer
Playwright is a multi-browser automation tool, but if you only need Chromium-based browsers, Puppeteer (or its Python port, Pyppeteer) is a lightweight and optimized alternative.
Originally built for Node.js, Puppeteer provides high-performance JavaScript execution using Chrome DevTools Protocol, making it faster than Selenium for JavaScript-heavy sites.
How It Works
We launch a headless Chromium browser using Puppeteer/Pyppeteer.
The browser loads and executes JavaScript, just like a real user.
We extract the fully rendered HTML using page.content(), ensuring that all JavaScript has been processed before scraping.
For pages that load content dynamically, we use networkidle0 to ensure all JavaScript execution is complete before extracting data.
Pros & Cons
✅ Faster than Selenium – Uses Chrome’s native DevTools Protocol for low-latency execution.
✅ Optimized for Chromium – Ideal for scraping Chrome-based sites without unnecessary multi-browser support.
✅ Handles JavaScript-heavy content – Supports waiting for elements, intercepting requests, and running custom JavaScript.
❌ Limited to Chromium – Unlike Playwright, it does not support Firefox or WebKit.
❌ More setup required – Pyppeteer needs to download and manage a headless Chromium binary.
Code Example
import asyncio
from pyppeteer import launch
async def scrape():
browser = await launch(headless=True) # Launch headless Chromium
page = await browser.newPage()
await page.goto("https://www.scrapethissite.com/pages/ajax-javascript/#2015", waitUntil="networkidle0")
print(await page.content()) # Print first 500 characters of the rendered HTML
await browser.close()
asyncio.run(scrape())This should return the rendered page correctly.
Puppeteer/Pyppeteer offers fast JavaScript execution and low-overhead scraping, making it a great choice for Chromium-based automation.
6. Scrapy + Splash
Puppeteer and Playwright are great for single-page scraping, but they lack built-in crawling capabilities.
If you need to scrape multiple pages efficiently, Scrapy + Splash is a better option.
Scrapy is a high-performance web crawling framework, while Splash is a lightweight JavaScript rendering engine that allows Scrapy to handle JavaScript-heavy pages.
How It Works
Scrapy sends requests to Splash, which loads the page and executes JavaScript.
Splash waits for JavaScript execution to complete, then returns the fully rendered HTML to Scrapy.
Scrapy extracts and processes the data, making it an efficient solution for scraping multiple pages at scale.
To ensure all JavaScript execution is complete before extracting data, we use Splash’s built-in waiting mechanisms to pause until the page is fully loaded.
Pros & Cons
✅ Optimized for large-scale scraping – Scrapy is built for crawling multiple pages efficiently.
✅ More lightweight than full browsers – Splash is faster and less resource-intensive than Selenium, Puppeteer, or Playwright.
✅ Built-in caching – Avoids unnecessary page loads, improving performance.
❌ Limited JavaScript support – Splash uses an older WebKit engine, which may not support modern JavaScript frameworks.
❌ Requires separate setup – Needs a Splash server (Docker installation recommended).
Code Example
import scrapy
from scrapy_splash import SplashRequest
class OscarSpider(scrapy.Spider):
name = "oscar_spider"
start_urls = ["https://www.scrapethissite.com/pages/ajax-javascript/#2015"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, self.parse, args={"wait": 2})
def parse(self, response):
print(response.text[:500]) # Print first 500 characters of the rendered HTMLScrapy + Splash is a great option for large-scale scraping, especially when handling multiple pages with JavaScript rendering.
However, if anti-scraping measures are in place, you might need something that can bypass basic protection.
Which Method to Use
Scraping JavaScript-rendered pages requires a method that executes JavaScript before extracting data.
- For simple cases: Requests-HTML works but is slow and inefficient.
- For speed and scalability: Scrape.do is the fastest and easiest, handling JavaScript execution and anti-bot measures.
- For full browser control: Playwright and Puppeteer automate browsers but require more setup.
- For large-scale crawling: Scrapy + Splash is efficient for bulk scraping but has JavaScript limitations.
- For bypassing detection: Undetected ChromeDriver helps with bot protection but is slower than API solutions.
For the fastest and most reliable scraping, Scrape.do is the best option.
No browsers, no proxies, no CAPTCHAs—just a simple API call.
Founder @ Scrape.do








