Category:Scraping Errors
3 Ways to Get Rid of Cloudflare Error 1015 (You Are Being Rate Limited)

R&D Engineer


You hit Error 1015. Cloudflare says: You are being rate limited.
Congratulations, you've just ran into the most common error for web scrapers!
Error 1015 means your scraper sent too many requests, too fast, and now you’re blocked.
This guide shows you 3 actually working ways to get past it, from quick fixes to scalable solutions that won’t break under pressure.
What Is Cloudflare Error 1015?
Cloudflare Error 1015 is a rate limiting response triggered when a single IP sends too many requests in a short period. It’s part of Cloudflare’s anti-bot protection system, designed to detect aggressive traffic and block it before it can overwhelm or scrape a target site even if your requests are valid and non-malicious.
Although seeing rate limits in web scraping is pretty common, you don't have to be writing a crawling or scraping bot to encounter it, actually.
Just go to this demo page and refresh 2 times back-to-back, and you'll meet this screen:
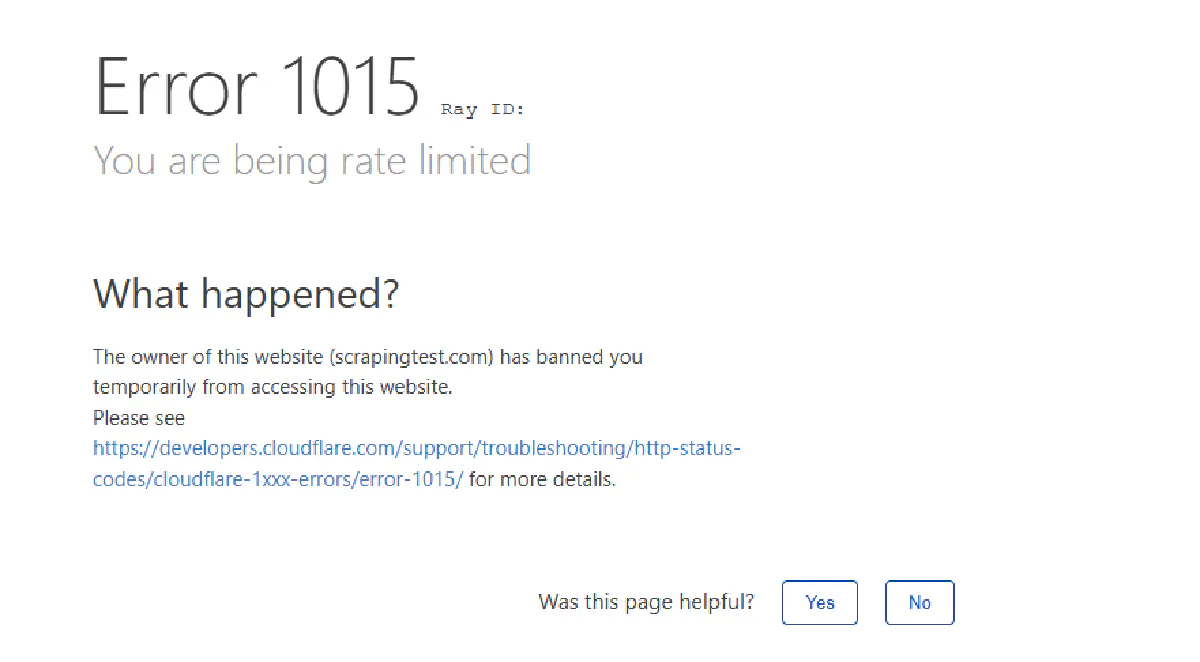
Let's try to make a bot encounter it, too.
Here’s a simple Python script that sends 10 back-to-back requests to the same demo page:
import requests
from bs4 import BeautifulSoup
URL = "https://scrapingtest.com/cloudflare-rate-limit"
for i in range(10):
print(f"--- Request {i + 1} ---")
# Send a request to the target URL
response = requests.get(URL)
# Parse the response with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Look for the <h1> and <h2> tags that show success or block message
h1 = soup.find('h1')
h2 = soup.find('h2')
print(f"H1: {h1.get_text(strip=True)}")
print(f"H2: {h2.get_text(strip=True)}")And here’s the output:
--- Request 1 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
--- Request 2 ---
H1: Error1015
H2: You are being rate limited
--- Request 3 ---
H1: Error1015
H2: You are being rate limited
--- Request 4 ---
H1: Error1015
H2: You are being rate limited
--- Request 5 ---
H1: Error1015
H2: You are being rate limited
--- Request 6 ---
H1: Error1015
H2: You are being rate limited
--- Request 7 ---
H1: Error1015
H2: You are being rate limited
--- Request 8 ---
H1: Error1015
H2: You are being rate limited
--- Request 9 ---
H1: Error1015
H2: You are being rate limited
--- Request 10 ---
H1: Error1015
H2: You are being rate limitedThe first request goes through, but every request after that hits Error 1015 almost instantly, and the response code in the terminal will print 429 "too many requests".
You basically have two options to overcome this, either slow down and act the way Cloudflare wants you to, or keep changing your IP to not look like you're sending requests from the same device.
We'll explore both.
💡 For the demo page we're targeting, if you send more than 2 requests in 10 seconds, you're rate limited. However, Cloudflare offers a lot of flexibility in determining what gets Error 1015, so a website admin can block from 2 requests in 10 seconds to 20 requests in an hour.
Fix #1: Add Random Delays
Error 1015 happens when you make requests too quickly from the same IP.
So let's just not do that.
We'll add delays between requests. But not just any delay; we use random intervals to avoid predictable patterns that Cloudflare or other WAFs might detect.
Here are the changes:
- Import
timeandrandommodules - After each request, pause between 8 and 14 seconds, randomly
- Skip the delay after the final request
Here’s the full updated script:
import requests
from bs4 import BeautifulSoup
import time
import random
URL = "https://scrapingtest.com/cloudflare-rate-limit"
for i in range(10):
print(f"--- Request {i + 1} ---")
# Send a GET request to the test page
response = requests.get(URL)
# Parse the HTML content with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract <h1> and <h2> to see if the request was accepted or blocked
h1 = soup.find('h1')
h2 = soup.find('h2')
print(f"H1: {h1.get_text(strip=True)}")
print(f"H2: {h2.get_text(strip=True)}")
# Add a random delay before the next request
if i < 9: # Don’t sleep after the last request
sleep_time = random.uniform(8, 14)
print(f"Sleeping for {sleep_time:.1f} seconds...")
time.sleep(sleep_time)Here's my output:
--- Request 1 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 10.5 seconds...
--- Request 2 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 10.7 seconds...
--- Request 3 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 8.7 seconds...
--- Request 4 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 13.5 seconds...
--- Request 5 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 12.5 seconds...
--- Request 6 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 13.2 seconds...
--- Request 7 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 8.7 seconds...
--- Request 8 ---
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 10.1 seconds...
--- Request 9 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]
Sleeping for 10.6 seconds...
--- Request 10 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge Passed Your IP: [ my real IP :) ]Easy as that!
But this might not cut it for more advanced protection or for websites that track IP usage over a longer period of time and block for a much longer time.
Fix #2: Rotate Proxies
If you're using the same IP all the way, Cloudflare will eventually catch on.
That’s why we rotate IPs.
Every IP has its own rate limit window.
Once you hit the cap, switching to a new IP resets the clock.
I'll grab a few free public proxies from a public proxy pool and cycle through them, sending each request from a different IP.
It’s a basic form of proxy rotation, but it works. Especially on endpoints that don’t fingerprint aggressively or require session persistence.
Here are the changes to our code:
- Defines a list of working proxies (I've tested a good number of before I decided on the 4 in the code, you'll have to do the same if you're using free proxies)
- Rotates through them using the current loop index
- Sends each request through a different proxy
- Also adding some try-except error handling because proxies might expire or go bad
Here’s the full example:
import requests
from bs4 import BeautifulSoup
URL = "https://scrapingtest.com/cloudflare-rate-limit"
# Proxy pool
proxies = [
{'http': 'http://14.239.189.250:8080', 'https': 'http://14.239.189.250:8080'},
{'http': 'http://103.127.252.57:3128', 'https': 'http://103.127.252.57:3128'},
{'http': 'http://59.29.182.162:8888', 'https': 'http://59.29.182.162:8888'},
{'http': 'http://77.238.103.98:8080', 'https': 'http://77.238.103.98:8080'}
]
for i in range(10):
print(f"--- Request {i + 1} ---")
# Rotate through proxies
current_proxy = proxies[i % len(proxies)]
print(f"Using proxy: {current_proxy['http']}")
try:
response = requests.get(URL, proxies=current_proxy, timeout=10)
soup = BeautifulSoup(response.content, 'html.parser')
# Extract response indicators
h1 = soup.find('h1')
h2 = soup.find('h2')
print(f"H1: {h1.get_text(strip=True)}")
print(f"H2: {h2.get_text(strip=True)}")
except Exception as e:
print(f"Request failed: {e}")Here's what your output should look like:
--- Request 1 ---
Using proxy: http://14.239.189.250:8080
Request failed: HTTPSConnectionPool(host='scrapingtest.com', port=443): Max retries exceeded with url: /cloudflare-rate-limit (Caused by ProxyError('Unable to connect to proxy', ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x00000253E417BB60>, 'Connection to 14.239.189.250 timed out. (connect timeout=10)')))
--- Request 2 ---
Using proxy: http://103.127.252.57:3128
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:182.78.254.158
--- Request 3 ---
Using proxy: http://59.29.182.162:8888
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:59.29.182.162
--- Request 4 ---
Using proxy: http://77.238.103.98:8080
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:77.238.103.98
--- Request 5 ---
Using proxy: http://14.239.189.250:8080
Request failed: HTTPSConnectionPool(host='scrapingtest.com', port=443): Max retries exceeded with url: /cloudflare-rate-limit (Caused by ProxyError('Unable to connect to proxy', ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x00000253E41EEFF0>, 'Connection to 14.239.189.250 timed out. (connect timeout=10)')))
--- Request 6 ---
Using proxy: http://103.127.252.57:3128
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:182.78.254.158
--- Request 7 ---
Using proxy: http://59.29.182.162:8888
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:59.29.182.162
--- Request 8 ---
Using proxy: http://77.238.103.98:8080
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:77.238.103.98
--- Request 9 ---
Using proxy: http://14.239.189.250:8080
Request failed: HTTPSConnectionPool(host='scrapingtest.com', port=443): Max retries exceeded with url: /cloudflare-rate-limit (Caused by ProxyError('Unable to connect to proxy', ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x00000253E41EF9B0>, 'Connection to 14.239.189.250 timed out. (connect timeout=10)')))
--- Request 10 ---
Using proxy: http://103.127.252.57:3128
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:182.78.254.158💡 One of the proxies were working fine until it didn't :) Left it in because you'll constantly fail in web scraping but will be saved by error handling and retry logics.
Even though we didn't get perfect results due to the low quality of free proxies, we sent 10 requests without waiting and got access.
You can also increase your success rate significantly with a small budget using cheap rotating proxies.
Fix #3: Use a Web Scraping API
Rotating proxies manually works but it’s unreliable, slow, and breaks easily.
You’ll spend more time fixing your scraping infrastructure than actually extracting data.
Let’s skip all of that.
If you're tired of babysitting proxies, handling delays, and praying Cloudflare lets your request through, the cleanest solution is to use a scraping API built to do all that for you, which is where Scrape.do comes in.
It handles everything we just walked through, and does a whole a lot more for countless web scraping use cases.
Before we talk about everything else, let's see Scrape.do in action.
First, sign up here in <30 seconds for FREE and get your API token.
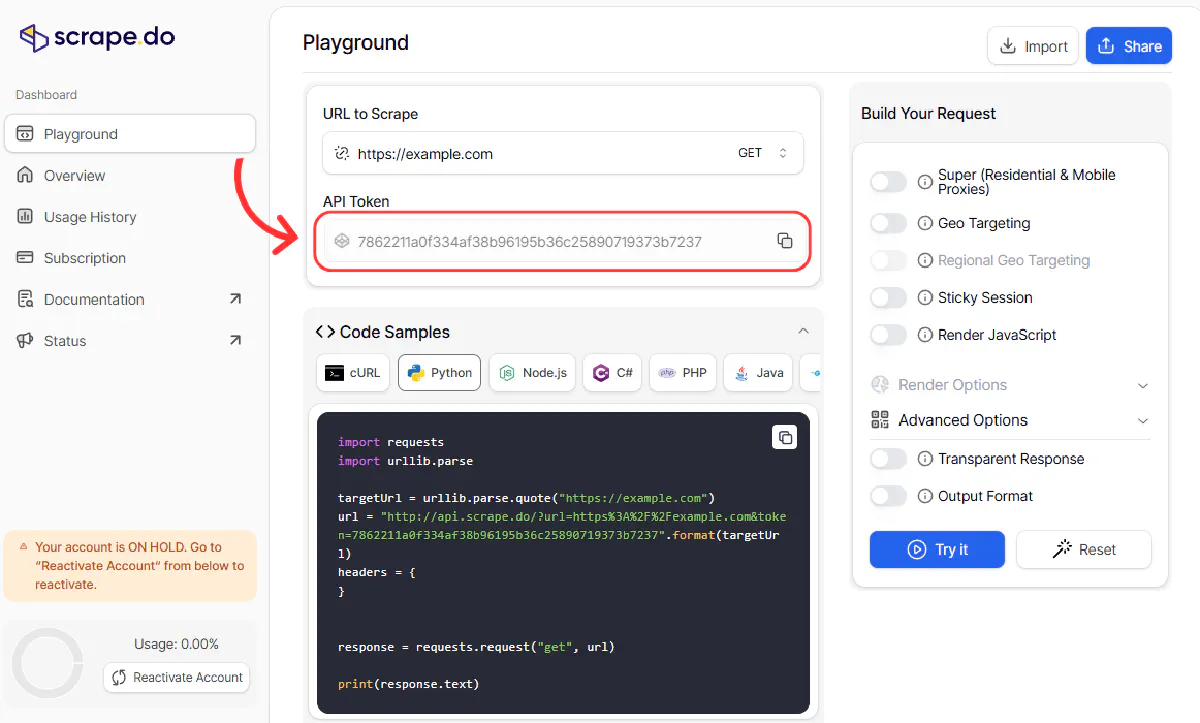
Then, paste the token in the code below and run it:
import requests
import urllib.parse
from bs4 import BeautifulSoup
token = "<your-token>"
target_url = "https://scrapingtest.com/cloudflare-rate-limit"
encoded_url = urllib.parse.quote(target_url)
for i in range(10):
print(f"--- Request {i + 1} ---")
url = f"http://api.scrape.do/?url={encoded_url}&token={token}"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
h1 = soup.find('h1')
h2 = soup.find('h2')
print(f"H1: {h1.get_text(strip=True)}")
print(f"H2: {h2.get_text(strip=True)}")Here's what your output will look like:
--- Request 1 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:145.223.59.141
--- Request 2 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:185.88.36.172
--- Request 3 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:212.119.43.107
--- Request 4 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:162.220.246.251
--- Request 5 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:31.56.137.182
--- Request 6 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:168.199.247.221
--- Request 7 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:84.33.57.65
--- Request 8 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:193.163.89.210
--- Request 9 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:171.22.249.240
--- Request 10 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:193.151.191.42And that’s it. 10 requests. No blocks. No headaches. Fast as lightning ⚡
To Sum Up
Making your scraper behave less aggressive or rotating IPs can definitely help you overcome Cloudflare Error 1015, however, it's not the definite solution.
You'll run into many more errors, CAPTCHAs, and challenges.
All of which become irrelevant with Scrape.do:
- Tens of millions of rotating residential and mobile proxies, so you're never rate-limited
- Fully managed scraping pipeline so ** ** you just send a URL, and get clean HTML or rendered output
- Automaticly bypass Cloudflare, CAPTCHAs, and other WAFs
- 99.98% success rate, even on heavily protected sites
- Extremely scalable and cost-effective for serious scraping operations
With Scrape.do, you don’t have to think about rate limits ever again :)
Frequently Asked Questions
How do you fix Error 1015?
Error 1015 happens because you've sent too many back-to-back requests through the same IP to a Cloudflare-protected website. To fix, you either need to wait and add some time between your requests or change your IP, regularly.
Is Error 1015 Permanent?
The duration of Error 1015 is around 10 seconds for basic Cloudflare protection, however on professional plans Cloudflare offers full customization to this so you can see Error 1015 "You are being rate limited." screen for hours or even days, depending on the preferance of the website admin.
R&D Engineer








