Category:Scraping Use Cases
2025 Guide to Scraping eBay Listings, Reviews, Search Results, Product Variants

Software Engineer


Although the recent Temu and Amazon boom slowed down some of the traffic for eBay, they remain to be a solid player for e-commerce scraping with millions of products selling out still.
This guide will help you scrape product listings (with variants), search results & categories, and of course, product reviews from eBay.
We'll use basic Python libraries like Requests to scrape the website, and level-up our scraper with Scrape.do to bypass any blocks.
Find all working code in this GitHub repository ⚙
Let's get to it!
To stay ethical and for maximum web scraping legality:
- Avoid scraping pages behind login
- Don't flood servers with high request volumes
- Don’t resell their content or present it as your own
Scraping Product Data from an eBay Listing (Simple Page)
At its core, every e-commerce site comes down to product pages, and scraping product names and prices the first task for scrapers.
So, we'll start by scraping a single eBay product page. I've been looking for a good mouse for my PC recently, so I'm picking this one.
We want to extract:
- Product Name
- Price
- ePID (eBay Product ID)
- Product Image URL
Let’s take it step by step.
1. Sending the First Request
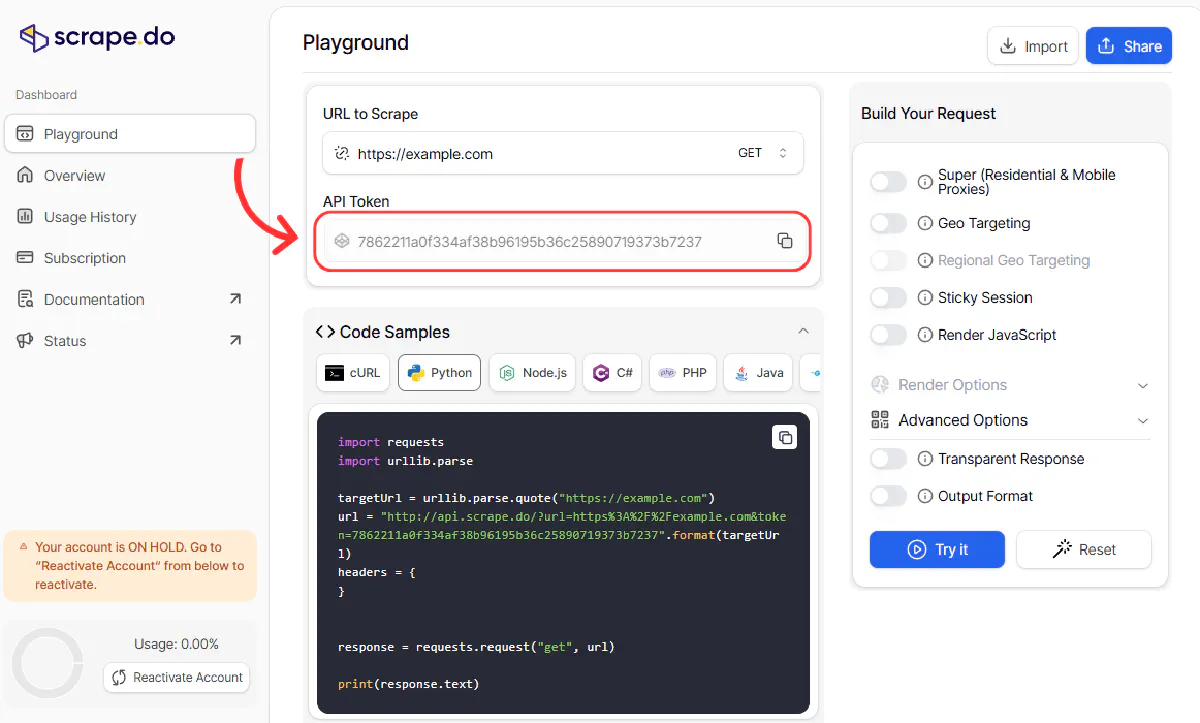
We’ll begin by sending a GET request through Scrape.do to ensure we can access the product page without getting blocked.
Don't forget to grab your Scrape.do API token from here, for free:
import requests
import urllib.parse
# Scrape.do API token
TOKEN = "<your-token>"
# Updated eBay product URL
target_url = "https://www.ebay.com/itm/125575167955"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geocode=us"
response = requests.get(api_url)
print(response.status_code)A successful response should print:
200If you're blocked or see status code 403, try these adjustments:
- Append
&render=trueto enable JavaScript rendering - Check that
super=trueis included to enable premium proxies - Make sure your token is valid and hasn’t hit the limit
2. Parsing and Extracting Product Data
To extract data from an eBay product page, you first need to understand the structure of the page.
Open the product in your browser and use the DevTools panel to inspect the elements you’re after. Right-click on any field (like the product name or price), and select “Inspect”. This will highlight the exact HTML tag and attributes you can use to locate it in your script.
In this section, we’ll extract the following fields:
- Product Name
- Price
- Product Image URL
- Product ID (we won’t scrape this since it’s already in the URL)
2.1 Parse the Page with BeautifulSoup
Once you’ve made a successful request and received the page’s HTML, you can parse it using BeautifulSoup to make it easier to navigate:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")This gives you access to all the HTML elements in a tree-like structure, which you can search by tag names, class names, and attributes.
2.2 Get Product ID from the URL
In this case, we’re scraping a specific product, and the item ID is already part of the URL. So we don’t need to extract it from the page.
product_id = "125575167955"For large-scale scraping, you’ll likely have a list of URLs that already include the product IDs and storing them ahead of time keeps your extraction logic simpler.
2.3 Extract Product Name
Let’s inspect the product title first. In the browser, locate the title using DevTools. You should see it inside an <h1> tag with a class like x-item-title__mainTitle.

This tag contains only the title text, so it’s safe to extract it directly:
try:
title = soup.find("h1", class_="x-item-title__mainTitle").get_text(strip=True)
except Exception:
title = NoneWe use a try-except block here to prevent the script from crashing if the element is missing or renamed which is useful when scraping hundreds of items.
2.4 Extract Price
Now let’s do the same for the price. Open DevTools and inspect the price text.

You’ll usually find it inside a <div> tag with the class x-price-primary.
try:
price = soup.find("div", class_="x-price-primary").get_text(strip=True)
except Exception:
price = NoneThis will return the full price string as shown on the page (e.g., US $44.99).
2.5 Extract Product Image URL
Product images on eBay are displayed in a carousel. When the page loads, the first image in the carousel is usually marked with the class active.
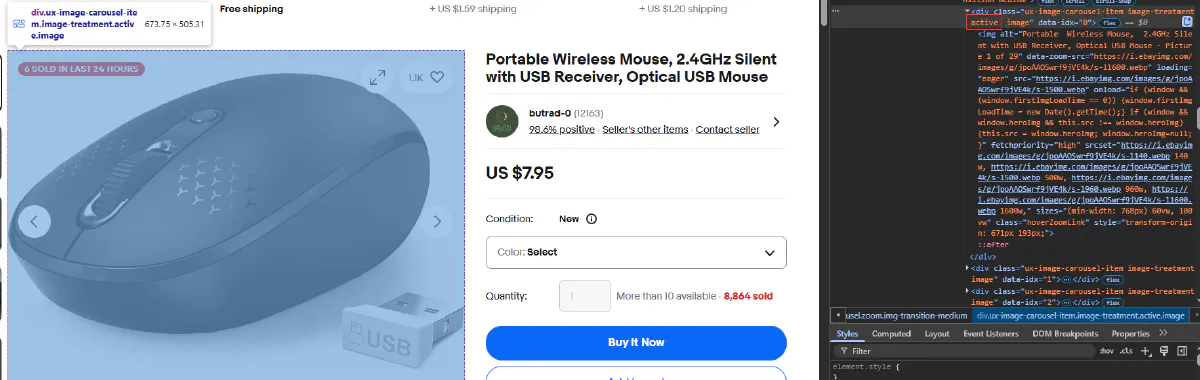
Each image is wrapped inside a <div> with the class ux-image-carousel-item, and the visible one will also have the active class.
The actual image is inside an <img> tag, so we’ll target that:
try:
image_url = soup.select_one('.ux-image-carousel-item.active').find("img")["src"]
except Exception:
image_url = NoneThis grabs the src attribute of the active image, which is a direct link to the image file.
To test the full setup, print the results:
print(title, "---", price, "---", product_id, "---", image_url)Final code should look like this:
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Scrape.do API token
TOKEN = "<your-token>"
# eBay product page
target_url = "https://www.ebay.com/itm/125575167955"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geocode=us"
response = requests.get(api_url)
product_id = "125575167955"
soup = BeautifulSoup(response.text, "html.parser")
# Product Name
try:
title = soup.find("h1", class_="x-item-title__mainTitle").get_text(strip=True)
except Exception:
title = None
# Price
try:
price = soup.find("div", class_="x-price-primary").get_text(strip=True)
except Exception:
price = None
# Product Image
try:
image_url = soup.select_one('.ux-image-carousel-item.active').find("img")["src"]
except Exception:
image_url = None
print(title, "---", price, "---", product_id, "---", image_url)And this will be your output:

3. Exporting the Data
Finally, let’s save the output into a CSV file.
We’ll create a simple CSV file with the following columns:
- Product ID
- Product Name
- Price
- Image URL
Import Python’s built-in csv module:
import csvWe’ll open a file named ebay_product.csv, write the headers, and then insert a single row with our data:
with open("ebay_product.csv", mode="w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["product_id", "title", "price", "image_url"]) # header row
writer.writerow([product_id, title, price, image_url]) # data rowThe newline="" ensures the output isn’t spaced out weirdly on Windows, and encoding="utf-8" avoids issues with special characters in product names.
Now run the final code and you should see a file named ebay_product.csv in your project directory.
Open it with any spreadsheet app or text editor and check that all fields are correctly placed.

You now have a working data extraction and export flow for a simple eBay product listing.
Scraping Product Data from an eBay Listing with Dropdown Variants
Some eBay product pages look deceptively simple like the one we just scraped.
Until you notice multiple dropdowns that create numerous variations for the same product.
Take for example this amazing St. Patrick's Day t-shirt.
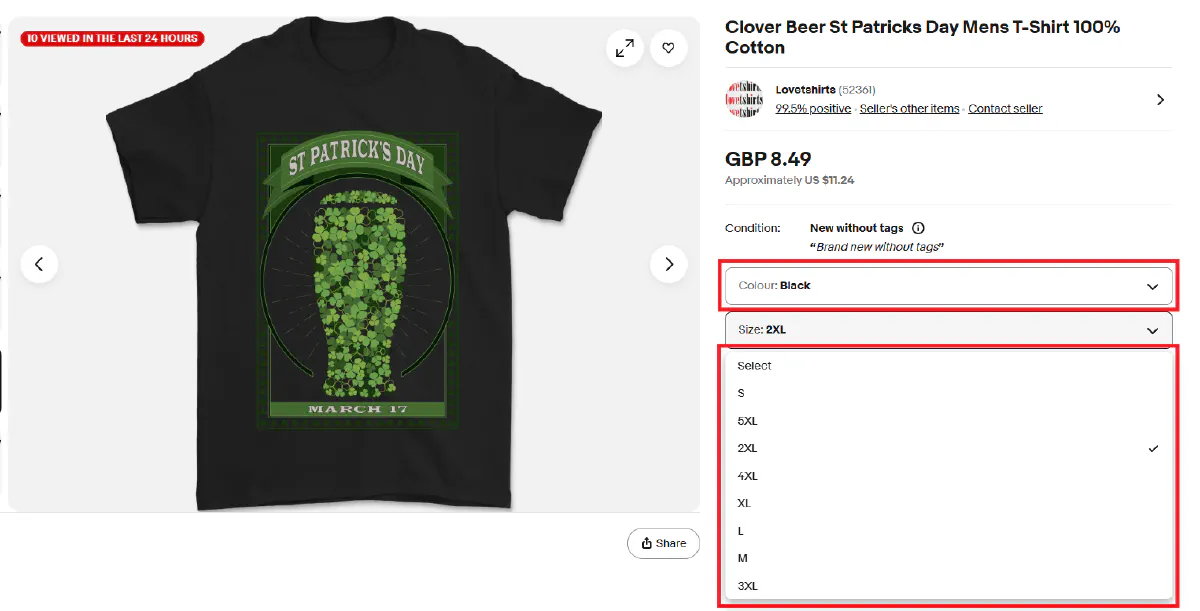
Unlike the product we scraped earlier, this one has multiple variations (size and color), and stock or price data of these variations are not visible unless you click on the dropdowns.
We could very well use the playWithBrowser feature of Scrape.do to click and select these dropdowns to find prices and stock info for each variation, but there's an easier way.
eBay hides info for every variation inside a large JavaScript object called MSKU, which contains a complete nested map of all product variants, stock status, and pricing info. That's what we'll scrape.
In this section, we’ll:
- Get the fully rendered HTML of an eBay product page
- Extract and parse the
MSKUJSON blob - Reconstruct all combinations of variations with price and availability
- Export everything into a clean CSV
1. Send Request and Extract HTML
You're familiar with everything below from the previous step.
Let's first import required libraries, send a request, and get a clean HTML:
import json
import re
import csv
import requests
import urllib.parse
# Your Scrape.do API token
TOKEN = "<your-token>"
# The eBay product page URL
TARGET_URL = "https://www.ebay.com/itm/176212861437"
# Construct the Scrape.do URL
encoded_url = urllib.parse.quote_plus(TARGET_URL)
API_URL = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&super=true"
# Send request through Scrape.do
response = requests.get(API_URL)
html_content = response.textAt this point, html_content contains the full HTML of the product page including the JavaScript variable that holds the variation data we need.
2. Extract and Parse MSKU Data
On eBay, products with dropdowns (like size or color) store all their variation logic inside a hidden JavaScript object called MSKU.
MSKU is unique to eBay, and means multi-variation SKU (SKU is pretty common, though).
This MSKU object includes:
- All variation combinations (e.g., Small + Red, Medium + Blue)
- Pricing and stock for each variation
- The structure and labels of dropdown menus
- Display names and internal IDs
You won’t find this data in the DOM, it’s buried inside a JavaScript variable somewhere in the page source, and looks like this (simplified):
"MSKU": {
"variationsMap": { ... },
"menuItemMap": { ... },
"variationCombinations": { ... },
"selectMenus": [ ... ]
}To extract it, we’ll use a regex pattern that finds the "MSKU": { ... } block, stops cleanly before the next "QUANTITY" field, and avoids overreaching (non-greedy matching).
Here’s the code that does that:
msku_data = json.loads(re.search(r'"MSKU":({.+?}),"QUANTITY"', html_content).group(1))Why we use
.+?instead of.+:
Greedy matching (.+) would capture everything until the last"QUANTITY"in the file. Non-greedy (.+?) stops at the first one, giving us a clean JSON chunk.
3. Extract Core Data Structures
Now that we’ve parsed the full MSKU object, we can extract the key substructures inside it:
variationsMap: links variation IDs to their price and stockmenuItemMap: maps menu item IDs to display namesvariationCombinations: maps menu selections (like “0_1”) to variation IDs
These are what we’ll use to reconstruct every possible product combination.
Here’s how we load them:
variations = msku_data.get('variationsMap', {})
menu_items = msku_data.get('menuItemMap', {})
variation_combinations = msku_data.get('variationCombinations', {})We also grab the selection menu labels (like “Size” or “Color”) to use as CSV headers:
headers = [menu['displayLabel'] for menu in msku_data.get('selectMenus', [])] + ['Price', 'OutOfStock']This prepares us to loop over each variation and extract the actual data in the next step.
4. Parse Each Variation
Now that we have the raw mappings and headers, we can walk through each possible variation combination.
Every entry in variationCombinations represents a unique combo of dropdown selections (like “Small + Red”) and links to a specific variation ID.
From there, we:
- Map menu item IDs to their display names
- Extract the price from
binModel - Check availability via the
outOfStockflag
⚠ You'll need to dig deep into the JSON blob and understand exactly how it is structured to learn how we're deconstructing variant data and then re-constructing it for the right variations.
Here’s the full loop:
rows = []
for combo_key, combo_data_id in variation_combinations.items():
variation_data = variations.get(str(combo_data_id))
if not variation_data:
continue
row = {}
menu_ids = [int(i) for i in combo_key.split('_')]
for menu_id in menu_ids:
menu_item = menu_items.get(str(menu_id))
if menu_item:
for menu in msku_data.get('selectMenus', []):
if menu_item['valueId'] in menu['menuItemValueIds']:
row[menu['displayLabel']] = menu_item['displayName']
break
price_spans = variation_data.get('binModel', {}).get('price', {}).get('textSpans', [])
row['Price'] = price_spans[0].get('text') if price_spans else None
row['OutOfStock'] = variation_data.get('quantity', {}).get('outOfStock', False)
rows.append(row)At this point, rows contains every possible variation, neatly structured with dropdown labels, price, and stock info. All that’s left is writing it to a CSV.
5. Export to CSV
Once all product variations are parsed into rows, we can export everything into a structured CSV file for easy analysis.
Here's the full code with export step added at the end:
import json
import re
import csv
import requests
import urllib.parse
# Configuration
TOKEN = "<your-token>"
TARGET_URL = "https://www.ebay.com/itm/176212861437"
# Scrape the page using scrape.do
response = requests.get(f"https://api.scrape.do/?url={urllib.parse.quote_plus(TARGET_URL)}&token={TOKEN}&super=true")
html_content = response.text
# Extract and parse MSKU data from HTML
msku_data = json.loads(re.search(r'"MSKU":({.+?}),"QUANTITY"', html_content).group(1))
# Get core data structures
variations = msku_data.get('variationsMap', {})
menu_items = msku_data.get('menuItemMap', {})
variation_combinations = msku_data.get('variationCombinations', {})
# Create CSV headers
headers = [menu['displayLabel'] for menu in msku_data.get('selectMenus', [])] + ['Price', 'OutOfStock']
# Process each variation combination
rows = []
for combo_key, combo_data_id in variation_combinations.items():
variation_data = variations.get(str(combo_data_id))
if not variation_data:
continue
row = {}
menu_ids = [int(i) for i in combo_key.split('_')]
# Extract menu values (size, color, etc.)
for menu_id in menu_ids:
menu_item = menu_items.get(str(menu_id))
if menu_item:
for menu in msku_data.get('selectMenus', []):
if menu_item['valueId'] in menu['menuItemValueIds']:
row[menu['displayLabel']] = menu_item['displayName']
break
# Extract price and stock status
price_spans = variation_data.get('binModel', {}).get('price', {}).get('textSpans', [])
row['Price'] = price_spans[0].get('text') if price_spans else None
row['OutOfStock'] = variation_data.get('quantity', {}).get('outOfStock', False)
rows.append(row)
# Write to CSV
with open('product_data.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
writer.writerows(rows)
print("Written to product_data.csv")Once you run the script, it’ll create a clean CSV file like this:
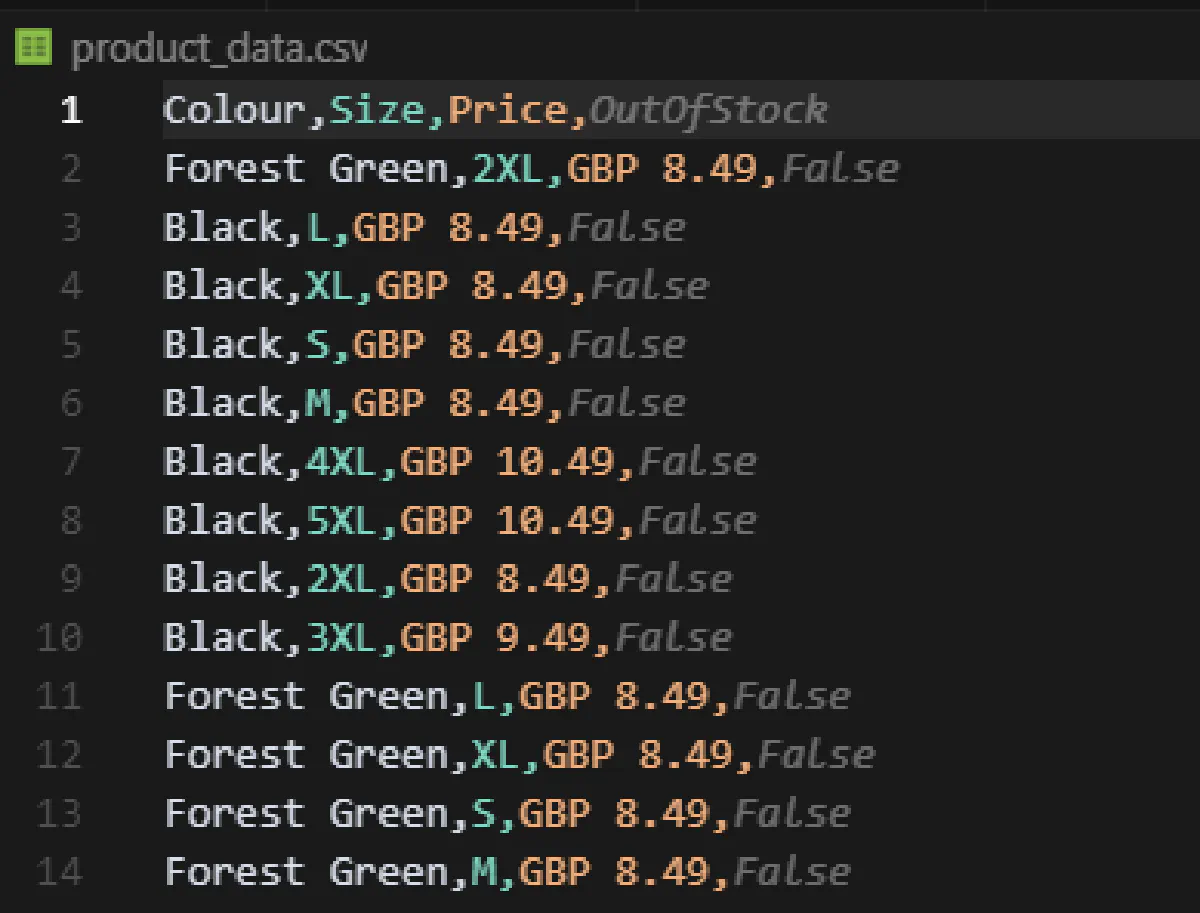
Bit complex, yes, but works!
Scraping eBay Reviews for a Product
User reviews are one of the most valuable data points on eBay.
They offer real customer sentiment, highlight recurring issues, and can reveal details that aren't obvious from product descriptions.
Rather than scraping reviews embedded in the product page, we’ll target eBay’s dedicated review pages, which are easier to parse and support full pagination. Our goal is to collect every review, not just the first few.
For this section, I'm picking a premium water bottle which has tens of reviews.
No idea why I picked this product, I was probably thirsty :)
We'll:
- Load all paginated review pages
- Extract structured data (reviewer name, rating, title, date, and comment)
- Export everything into a CSV for further analysis
1. Send a Request to the Review Page
We start from the dedicated review page instead of the listing page. It loads directly, doesn't require JavaScript interaction, and returns all visible review data.
We’ll use Scrape.do to fetch the full HTML:
import requests
import urllib.parse
from bs4 import BeautifulSoup
TOKEN = "<your-token>"
start_url = "https://www.ebay.com/urw/Hydro-Flask-FXM334-Straw-Lid-Black/product-reviews/26031753680?_itm=204914180000"
encoded_url = urllib.parse.quote_plus(start_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&super=true&geocode=us"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")2. Extract Review Fields
Each review is contained within a .ebay-review-section block. Inside it, we’ll find reviewer's name, rating, and you guessed it, review.
The star rating is stored in the data-stars attribute like data-stars="5-0", so we split and extract just the number.
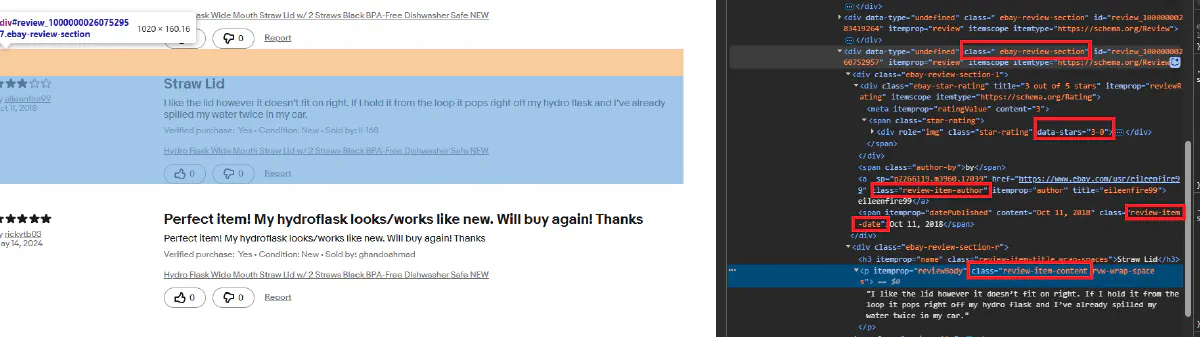
Here's the extraction logic:
def extract_reviews(soup):
reviews = soup.select(".ebay-review-section")
data = []
for r in reviews:
try:
reviewer = r.select_one(".review-item-author").get_text(strip=True)
except:
reviewer = None
try:
rating = r.select_one("div.star-rating")["data-stars"].split("-")[0]
except:
rating = None
try:
title = r.select_one(".review-item-title").get_text(strip=True)
except:
title = None
try:
date = r.select_one(".review-item-date").get_text(strip=True)
except:
date = None
try:
comment = r.select_one(".review-item-content").get_text(strip=True)
except:
comment = None
data.append({
"Reviewer": reviewer,
"Rating": rating,
"Title": title,
"Date": date,
"Comment": comment
})
return data3. Detect and Follow Pagination
Each review page includes a “Next” button that links to the next set of reviews. The easiest way to detect it is by looking for a link with rel="next".
The link is already absolute, so we can use it directly:
def get_next_page(soup):
try:
return soup.select_one('a[rel="next"]')["href"]
except:
return None4. Scrape All Pages in a Loop
With both review extraction and pagination detection in place, we can loop through all available pages until we reach the end.
This loop will keep scraping as long as there’s a valid next link on the page:
all_reviews = []
current_url = start_url
while current_url:
encoded = urllib.parse.quote_plus(current_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded}&super=true&geocode=us"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
all_reviews.extend(extract_reviews(soup))
current_url = get_next_page(soup)5. Export Reviews to CSV
Once all pages are scraped, we’ll write the results to a CSV.
Here’s the full code with CSV exporting added:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
TOKEN = "<your-token>"
start_url = "https://www.ebay.com/urw/Hydro-Flask-FXM334-Straw-Lid-Black/product-reviews/26031753680?_itm=204914180000"
def extract_reviews(soup):
reviews = soup.select(".ebay-review-section")
data = []
for r in reviews:
try:
reviewer = r.select_one(".review-item-author").get_text(strip=True)
except:
reviewer = None
try:
rating = r.select_one("div.star-rating")["data-stars"].split("-")[0]
except:
rating = None
try:
title = r.select_one(".review-item-title").get_text(strip=True)
except:
title = None
try:
date = r.select_one(".review-item-date").get_text(strip=True)
except:
date = None
try:
comment = r.select_one(".review-item-content").get_text(strip=True)
except:
comment = None
data.append({
"Reviewer": reviewer,
"Rating": rating,
"Title": title,
"Date": date,
"Comment": comment
})
return data
def get_next_page(soup):
try:
return soup.select_one('a[rel="next"]')["href"]
except:
return None
all_reviews = []
current_url = start_url
while current_url:
encoded = urllib.parse.quote_plus(current_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded}&super=true&geocode=us"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
all_reviews.extend(extract_reviews(soup))
current_url = get_next_page(soup)
with open("ebay_paginated_reviews.csv", mode="w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["Reviewer", "Rating", "Title", "Date", "Comment"])
writer.writeheader()
for row in all_reviews:
writer.writerow(row)
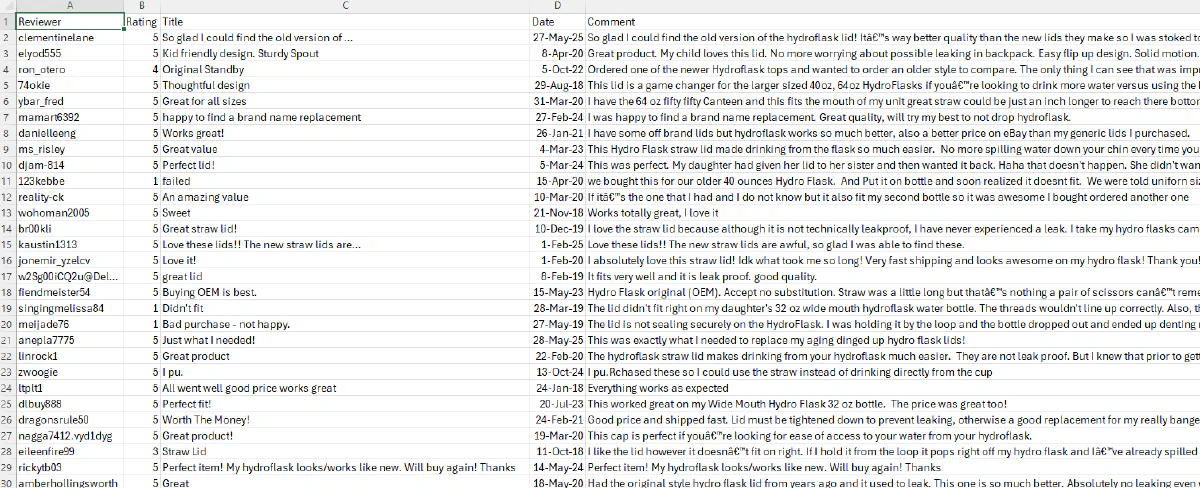
print("Saved all reviews to ebay_paginated_reviews.csv")And here's the CSV it created:
Scraping eBay Search Results
Scraping reviews and listing variants has not been a big of a deal so far.
But what if you want to scrape a full search results page?
That’s where things get interesting, you’ll need to extract a list of products, each with its own:
- Name
- Price
- Image
- Link to the product page
Let's imagine that St. Patrick's Day is right around the corner and I want to scrape all related t-shirt designs from eBay for competitive insights.
Here's how I would do it:
1. Sending the First Request
Let’s start by making a request to the eBay search results page using Scrape.do.
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Your Scrape.do token
TOKEN = "<your-token>"
query_url = "https://www.ebay.com/sch/i.html?_nkw=saint+patricks+tshirt"
encoded_url = urllib.parse.quote_plus(query_url)
# Scrape.do endpoint
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")2. Extracting Product Listings
eBay uses multiple layouts for search results, which makes our job slightly more difficult.
While some pages follow the older .s-item structure, others use a newer .s-card layout. Instead of hardcoding for one or the other, we’ll detect which layout is present and use the correct selectors accordingly.
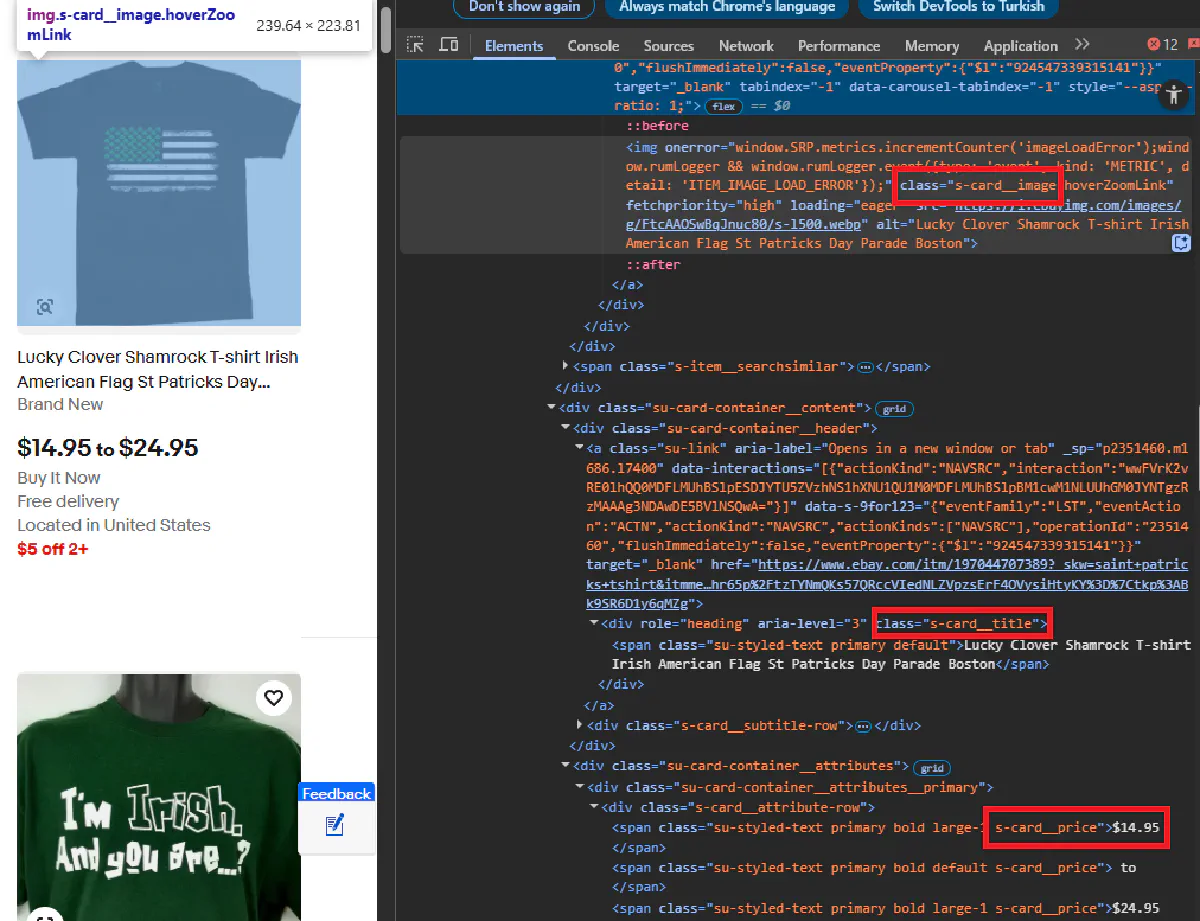
From each listing we'll extract name, price, image URL, and link to the actual product.
Here’s the layout-aware extraction logic:
if soup.select("li.s-card"):
items = soup.select("li.s-card")
layout = "s-card"
elif soup.select("li.s-item"):
items = soup.select("li.s-item")
layout = "s-item"
else:
items = []
layout = None
for item in items:
try:
title = item.select_one(".s-card__title" if layout == "s-card" else ".s-item__title").get_text(strip=True)
except:
title = None
try:
price_spans = item.select(".s-card__price" if layout == "s-card" else ".s-item__price")
if len(price_spans) > 1:
price = " ".join([span.get_text(strip=True) for span in price_spans])
elif price_spans:
price = price_spans[0].get_text(strip=True)
else:
price = None
except:
price = None
try:
image_url = item.select_one(".s-card__image" if layout == "s-card" else ".s-item__image-img")["src"]
except:
image_url = None
try:
link = item.select_one("a.su-link" if layout == "s-card" else "a.s-item__link")["href"]
except:
link = None
results.append({
"title": title,
"price": price,
"image_url": image_url,
"link": link
})3. Navigating Pagination
To scrape beyond the first page, we need to follow the “Next” button and repeat the extraction process.
eBay includes pagination links at the bottom of the page, and the “Next” button is usually marked with the class pagination__next.
We’ll loop through pages by following that link until no more pages are available. The scraper also adapts to layout changes between pages.
Before showing you the full code, let's make the final addition:
4. Exporting the Data
We also need to export this data to CSV, so we'll use the same method as before.
With pagination and CSV writing added, here's the full working code:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Your Scrape.do token
TOKEN = "<your-token>"
results = []
current_url = "https://www.ebay.com/sch/i.html?_nkw=saint+patricks+tshirt"
while current_url:
encoded_url = urllib.parse.quote_plus(current_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geocode=us&super=true&render=true"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Detect which layout is being used
if soup.select("li.s-card"):
items = soup.select("li.s-card")
layout = "s-card"
elif soup.select("li.s-item"):
items = soup.select("li.s-item")
layout = "s-item"
else:
break
for item in items:
try:
title = item.select_one(".s-card__title" if layout == "s-card" else ".s-item__title").get_text(strip=True)
except:
title = None
try:
price_spans = item.select(".s-card__price" if layout == "s-card" else ".s-item__price")
if len(price_spans) > 1:
price = " ".join([span.get_text(strip=True) for span in price_spans])
elif price_spans:
price = price_spans[0].get_text(strip=True)
else:
price = None
except:
price = None
try:
image_url = item.select_one(".s-card__image" if layout == "s-card" else ".s-item__image-img")["src"]
except:
image_url = None
try:
link = item.select_one("a.su-link" if layout == "s-card" else "a.s-item__link")["href"]
except:
link = None
results.append({
"title": title,
"price": price,
"image_url": image_url,
"link": link
})
try:
next_link = soup.select_one("a.pagination__next")["href"]
current_url = next_link
except:
current_url = None
# Export to CSV
with open("ebay_search_results.csv", mode="w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["title", "price", "image_url", "link"])
writer.writeheader()
for row in results:
writer.writerow(row)
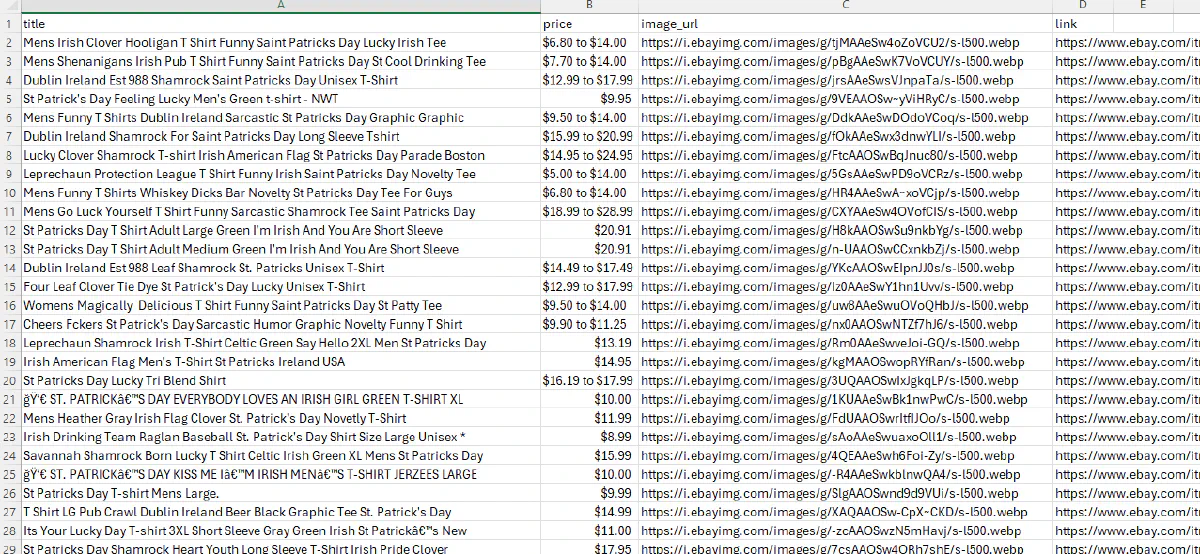
print("Scraping completed. Results saved to ebay_search_results.csv.")And this is going to be our large CSV file:
You're now able to scrape any and all data from eBay.
Conclusion
You're now able to scrape the entirety of eBay, including:
- Static product pages using simple HTML parsing
- Search results that span multiple layouts and pages
- Variant-based listings by extracting hidden MSKU data from the HTML source
- All reviews of any product
To make this process reliable, we used Scrape.do, which handled anti-bot detection and proxy management for us, enabling us to bypass geo-restrictions and blocks.
If you want to skip the hard parts of scraping, especially on JavaScript-heavy sites like eBay, Scrape.do is built for it.
👉 Try Scrape.do today and start scraping faster, cleaner, and without the constant breakage.
Software Engineer








