Category:Scraping Use Cases
Ultimate Guide to Scraping Bing (Extract SERPs, Images, News, Products)

R&D Engineer


Bing handles increasingly more searches than ChatGPT, yet most developers and marketers ignore it and focus completely on GEO.
That's a mistake.
With more stable search data, cleaner HTML structure, and fewer anti-bot headaches than Google, it's a gem hidden in plain sight.
Find all four working scrapers on GitHub ⚙
We'll cover four production-ready scrapers: web search results, image search, shopping products, and news articles. Each one uses simple Python scripts that work right now, not theoretical code that breaks next week.
Why You Need to Scrape Bing
Bing has become an even more desirable domain to scrape in the last few months. Here's a few reasons why:
Google Search Tracking Has Become Unreliable
Google's search rank tracking is not broken per-se, but not as powerful as it was.
In September 2024, Google removed the ability to show 100 search results per page by dropping the &num=100 parameter. Overnight, third-party rank tracking tools lost their most efficient data collection method. What used to take one request now costs ten.
The damage goes deeper.
Google Search Console's performance reports started showing significant drops in desktop impressions and sharp increases in average position. Both first-party and third-party data became unreliable at the same time.
Microsoft Is Pushing Bing and Copilot Search
Bing is especially making a comeback because Microsoft is doubling down on Search.
Bing is now integrated directly into Windows 11, embedded in Copilot, and powers ChatGPT's web search functionality.
Bing Shopping and Images Are Easier to Scrape
Bing's DOM structure is cleaner than Google's and uses less dynamic rendering to provide results.
Google Shopping requires reverse-engineering obfuscated class names and dealing with dynamic rendering.
Bing Shopping loads everything server-side with clear selectors. Same quality data, fraction of the effort.
Bing Prioritizes Content Freshness
Bing's ranking algorithm weighs freshness heavily, especially for news and time-sensitive queries.
This makes Bing ideal for scraping recent content. News articles appear faster, trending topics surface earlier, and date-sorted results actually respect the sort order.
If you're monitoring breaking news, tracking product launches, or collecting real-time data, Bing delivers fresher results than Google's increasingly cached responses.
Prerequisites
Before building the scrapers, install the required libraries:
pip install requests beautifulsoup4We'll use requests to send HTTP requests and BeautifulSoup to parse HTML. Both are standard Python libraries that handle Bing's structure without additional dependencies.
Bing monitors request patterns, throttles suspicious IPs, and occasionally throws CAPTCHAs at scrapers. Scrape.do handles all of this automatically with rotating proxies, geo-targeting, and header spoofing.
A Scrape.do API token is required for these scrapers, sign up and you'll find your token here:
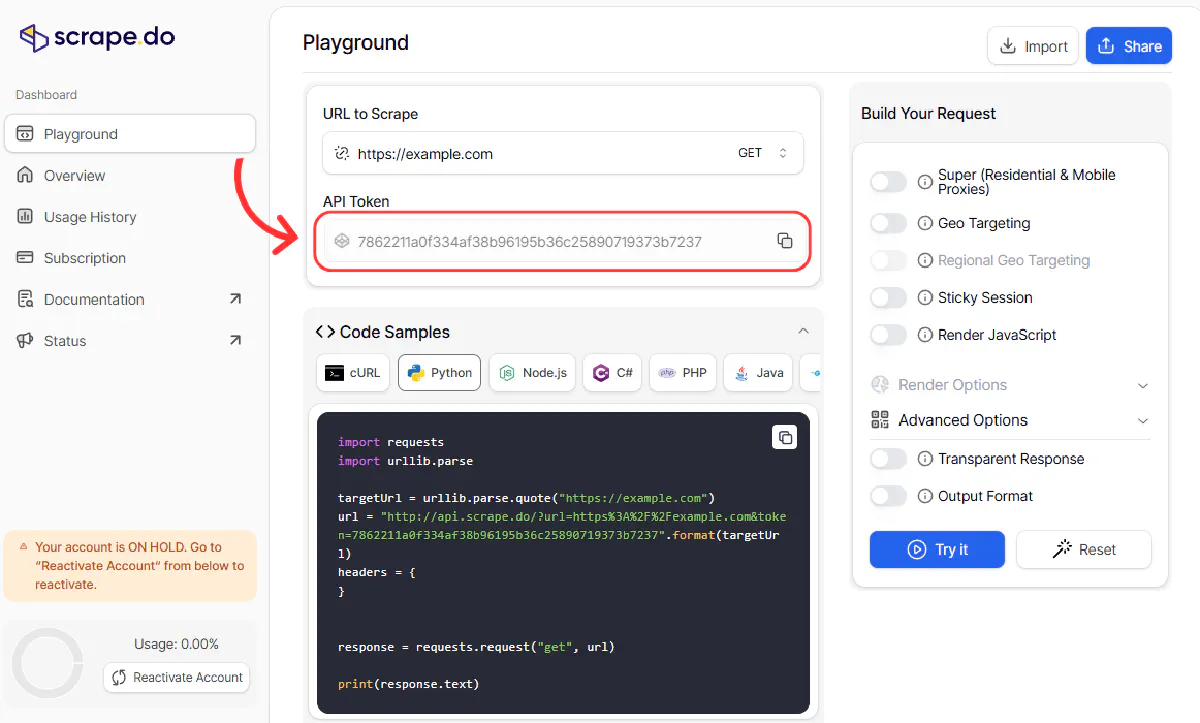
The free tier includes 1000 successful requests per month, which is enough to test all four scrapers and run them regularly for small projects.
Scrape Bing Web Search Results
SERPs are straightforward. We're sending a request to each page and parsing the HTML to extract results.
For pagination, Bing uses a simple offset system.
The first page has no first parameter in the URL. Page 2 uses first=11, page 3 uses first=21, and so on. The calculation is straightforward: first = 1 + (page_number * 10).
Like this:
https://www.bing.com/search?q={query}
https://www.bing.com/search?q={query}&first=11
https://www.bing.com/search?q={query}&first=21This predictable structure makes pagination reliable. No need to parse "next page" links or deal with JavaScript-based infinite scroll.
Build the Search Scraper
We'll define the configuration first. The max_pages variable controls how many result pages to scrape.
All requests route through Scrape.do's API:
http://api.scrape.do?token={TOKEN}&url={ENCODED_URL}&geoCode=usimport requests
import csv
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "when was coffee invented"
max_pages = 10
all_results = []
page = 0
empty_count = 0
print(f"Starting scrape for: '{query}'")
print(f"Max pages: {max_pages}\n")The URL construction handles pagination through a simple calculation. Page 0 gets no first parameter, while subsequent pages calculate the offset:
while page < max_pages:
# Calculate offset (page 0 = no first param, page 1 = first=11, page 2 = first=21, etc.)
if page == 0:
page_url = f"https://www.bing.com/search?q={query}"
else:
first = 1 + (page * 10)
page_url = f"https://www.bing.com/search?q={query}&first={first}"
# URL encode the target URL for Scrape.do
encoded_url = urllib.parse.quote(page_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us&super=true"
offset_str = "first page" if page == 0 else f"first={first}"
print(f"Page {page + 1} ({offset_str})...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")The geoCode=us parameter routes requests through US-based proxies. Change this to uk, de, or any other country code to get localized results.
Parse Search Results
Bing wraps each organic result in an li tag with class b_algo. Inside each result, the h2 contains both the title and link, while p.b_lineclamp2 holds the description:
# Extract results from this page
page_results = []
for result in soup.find_all("li", class_="b_algo"):
try:
# Extract title and link
h2_tag = result.find("h2")
title = h2_tag.get_text(strip=True)
link = h2_tag.find("a")["href"]
# Extract description (may not always exist)
desc_tag = result.find("p", class_="b_lineclamp2")
description = desc_tag.get_text(strip=True) if desc_tag else ""
page_results.append({
"title": title,
"url": link,
"description": description
})
except:
continueThis selector structure has been stable for years. Unlike Google's constantly rotating class names, Bing maintains consistent HTML patterns.
Handle Empty Pages
Sometimes Bing returns empty pages before all results are returned.
This happens with pagination edge cases or when results suddenly stop. The scraper handles this by tracking consecutive empty responses:
# Check if we found results
if len(page_results) == 0:
empty_count += 1
print(f"No results (empty count: {empty_count}/2)")
# Stop if we get 2 consecutive empty pages
if empty_count >= 2:
print("No more results found (confirmed with 2 retries)")
break
else:
empty_count = 0
all_results.extend(page_results)
print(f"Found {len(page_results)} results (total: {len(all_results)})")
page += 1The retry logic prevents false stops.
One empty page might be a fluke; two consecutive empty pages means you've reached the end.
Export to CSV
Here's the full code with export logic added:
import requests
import csv
import urllib.parse
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "when was coffee invented"
max_pages = 10
all_results = []
page = 0
empty_count = 0
print(f"Starting scrape for: '{query}'")
print(f"Max pages: {max_pages}\n")
while page < max_pages:
# Calculate offset (page 0 = no first param, page 1 = first=11, page 2 = first=21, etc.)
if page == 0:
page_url = f"https://www.bing.com/search?q={query}"
else:
first = 1 + (page * 10)
page_url = f"https://www.bing.com/search?q={query}&first={first}"
# URL encode the target URL for Scrape.do
encoded_url = urllib.parse.quote(page_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us&super=true"
offset_str = "first page" if page == 0 else f"first={first}"
print(f"Page {page + 1} ({offset_str})...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract results from this page
page_results = []
for result in soup.find_all("li", class_="b_algo"):
try:
# Extract title and link
h2_tag = result.find("h2")
title = h2_tag.get_text(strip=True)
link = h2_tag.find("a")["href"]
# Extract description (may not always exist)
desc_tag = result.find("p", class_="b_lineclamp2")
description = desc_tag.get_text(strip=True) if desc_tag else ""
page_results.append({
"title": title,
"url": link,
"description": description
})
except:
continue
# Check if we found results
if len(page_results) == 0:
empty_count += 1
print(f"No results (empty count: {empty_count}/2)")
# Stop if we get 2 consecutive empty pages
if empty_count >= 2:
print("No more results found (confirmed with 2 retries)")
break
else:
empty_count = 0
all_results.extend(page_results)
print(f"Found {len(page_results)} results (total: {len(all_results)})")
page += 1
# Save all results to CSV
print(f"\nSaving {len(all_results)} results to CSV...")
with open("bing_search_results.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["title", "url", "description"])
writer.writeheader()
writer.writerows(all_results)
print(f"Done! Extracted {len(all_results)} results across {page} pages -> bing_search_results.csv")And you'll get all the results in the CSV:
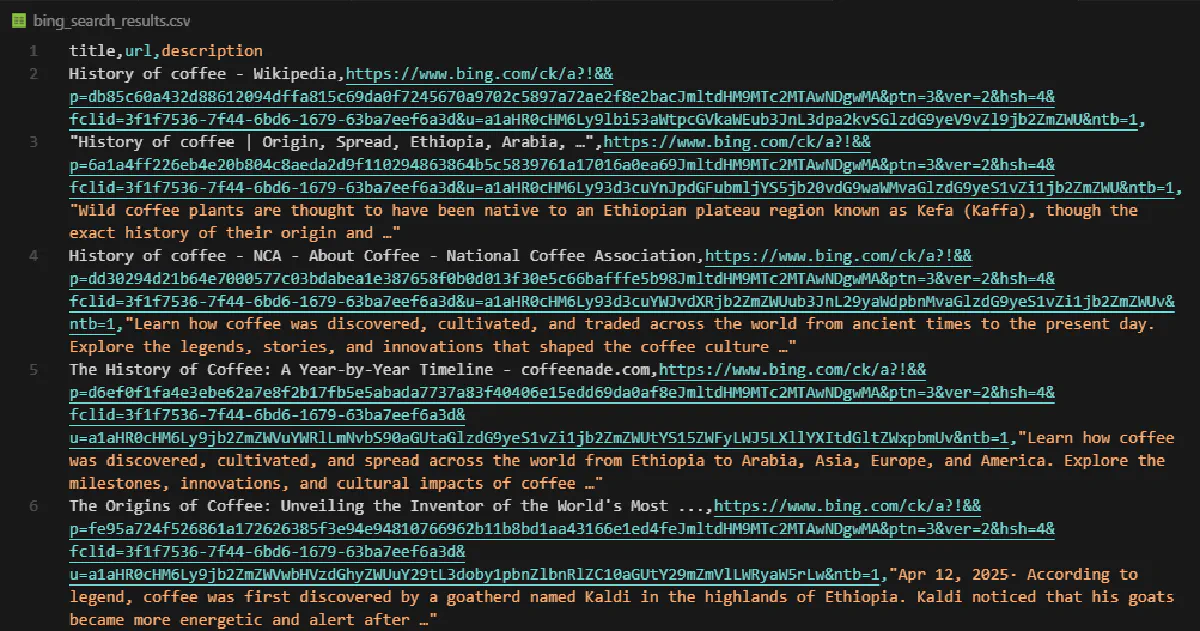
Scrape Bing Image Results
Bing Images uses an asynchronous loading endpoint (/images/async) that returns HTML chunks without full page reloads. Each image's metadata is embedded as JSON inside the m attribute of anchor tags. This makes extraction straightforward once you know where to look.
https://www.bing.com/images/async?q={query}&first=1&mmasync=1
https://www.bing.com/images/async?q={query}&first=36&mmasync=1
https://www.bing.com/images/async?q={query}&first=71&mmasync=1The pagination uses a first parameter that tracks how many images have been loaded. Unlike search results, this isn't a fixed offset—it increments by however many images were returned in the previous request.
Build the Image Scraper
The configuration sets a target count. The scraper loops until it collects max_results images.
Requests route through Scrape.do with proper URL encoding:
http://api.scrape.do?token={TOKEN}&url={ENCODED_URL}&geoCode=usimport requests
import csv
import urllib.parse
import json
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "coffee"
max_results = 100
all_images = []
first = 1
print(f"Starting image scrape for: '{query}'")
print(f"Target: {max_results} images\n")The async endpoint URL uses mmasync=1 to get the image grid without the full page wrapper:
while len(all_images) < max_results:
# Build URL
page_url = f"https://www.bing.com/images/async?q={query}&first={first}&mmasync=1"
encoded_url = urllib.parse.quote(page_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us"
print(f"Fetching images (first={first})...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")The urllib.parse.quote() with safe='' ensures the entire URL is encoded properly. Without this, the & characters in the Bing URL would be interpreted as parameter separators by Scrape.do.
Parse Image Data
Each image link contains a JSON object in its m attribute. This JSON holds the full-size image URL (murl), source page (purl), thumbnail (turl), and title (t):
# Extract images from this page
page_images = []
for img_link in soup.find_all("a"):
m_data = img_link.get("m", "")
try:
data = json.loads(m_data)
page_images.append({
"title": data.get("t", ""),
"image_url": data.get("murl", ""),
"source_url": data.get("purl", ""),
"thumbnail_url": data.get("turl", "")
})
except:
continueThe try-except block handles anchor tags without m attributes (navigation links, filters, etc.). Only valid image links contain parseable JSON.
After extracting images from the current page, we check if any were found and update the offset:
# Stop if no images found
if not page_images:
print("No more images found")
break
all_images.extend(page_images)
print(f"Found {len(page_images)} images (total: {len(all_images)})")
# Next page
first += len(page_images)The first parameter increments by the actual number of images returned, not a fixed amount. Bing typically returns 35 images per request, but this can vary.
Download Images (Optional)
The scraper includes a commented-out section for downloading images directly to disk. This is useful for cases that need the actual image files, not just their URLs:
# ===== DOWNLOAD IMAGES SECTION (Comment/Uncomment this entire block) =====
# import os
# download_folder = "downloaded_images"
#
# # Create download folder
# if not os.path.exists(download_folder):
# os.makedirs(download_folder)
#
# # Download all images
# print(f"\nDownloading {len(all_images)} images...")
# for idx, img in enumerate(all_images):
# try:
# img_url = img["image_url"]
# img_response = requests.get(img_url, timeout=10)
#
# # Get file extension from URL
# ext = img_url.split(".")[-1].split("?")[0]
# if ext not in ["jpg", "jpeg", "png", "gif", "webp"]:
# ext = "jpg"
#
# # Save image
# filename = f"{download_folder}/{query}_{idx + 1}.{ext}"
# with open(filename, "wb") as f:
# f.write(img_response.content)
#
# if (idx + 1) % 10 == 0:
# print(f"Downloaded {idx + 1}/{len(all_images)} images...")
# except:
# continue
#
# print(f"Download complete! Images saved to {download_folder}/")
# ===== END DOWNLOAD SECTION =====Uncomment this entire block to enable image downloads.
The scraper extracts the file extension from the URL and falls back to .jpg if the extension is unrecognized. Images are named sequentially: coffee_1.jpg, coffee_2.jpg, etc.
The 10-second timeout prevents the scraper from hanging on slow-loading images.
Export Results
Here's the full code with export logic added:
import requests
import csv
import urllib.parse
import json
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "coffee"
max_results = 100
all_images = []
first = 1
print(f"Starting image scrape for: '{query}'")
print(f"Target: {max_results} images\n")
while len(all_images) < max_results:
# Build URL
page_url = f"https://www.bing.com/images/async?q={query}&first={first}&mmasync=1"
encoded_url = urllib.parse.quote(page_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us"
print(f"Fetching images (first={first})...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract images from this page
page_images = []
for img_link in soup.find_all("a"):
m_data = img_link.get("m", "")
try:
data = json.loads(m_data)
page_images.append({
"title": data.get("t", ""),
"image_url": data.get("murl", ""),
"source_url": data.get("purl", ""),
"thumbnail_url": data.get("turl", "")
})
except:
continue
# Stop if no images found
if not page_images:
print("No more images found")
break
all_images.extend(page_images)
print(f"Found {len(page_images)} images (total: {len(all_images)})")
# Next page
first += len(page_images)
# Trim to max_results
all_images = all_images[:max_results]
# Save to CSV
print(f"\nSaving {len(all_images)} images to CSV...")
with open("bing_image_results.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["title", "image_url", "source_url", "thumbnail_url"])
writer.writeheader()
writer.writerows(all_images)
print(f"Done! Extracted {len(all_images)} images -> bing_image_results.csv")
# ===== DOWNLOAD IMAGES SECTION (Comment/Uncomment this entire block) =====
# import os
# download_folder = "downloaded_images"
#
# # Create download folder
# if not os.path.exists(download_folder):
# os.makedirs(download_folder)
#
# # Download all images
# print(f"\nDownloading {len(all_images)} images...")
# for idx, img in enumerate(all_images):
# try:
# img_url = img["image_url"]
# img_response = requests.get(img_url, timeout=10)
#
# # Get file extension from URL
# ext = img_url.split(".")[-1].split("?")[0]
# if ext not in ["jpg", "jpeg", "png", "gif", "webp"]:
# ext = "jpg"
#
# # Save image
# filename = f"{download_folder}/{query}_{idx + 1}.{ext}"
# with open(filename, "wb") as f:
# f.write(img_response.content)
#
# if (idx + 1) % 10 == 0:
# print(f"Downloaded {idx + 1}/{len(all_images)} images...")
# except:
# continue
#
# print(f"Download complete! Images saved to {download_folder}/")
# ===== END DOWNLOAD SECTION =====The scraper trims results to exactly max_results at the end, since the last request might overshoot the target.
The CSV contains all image metadata:
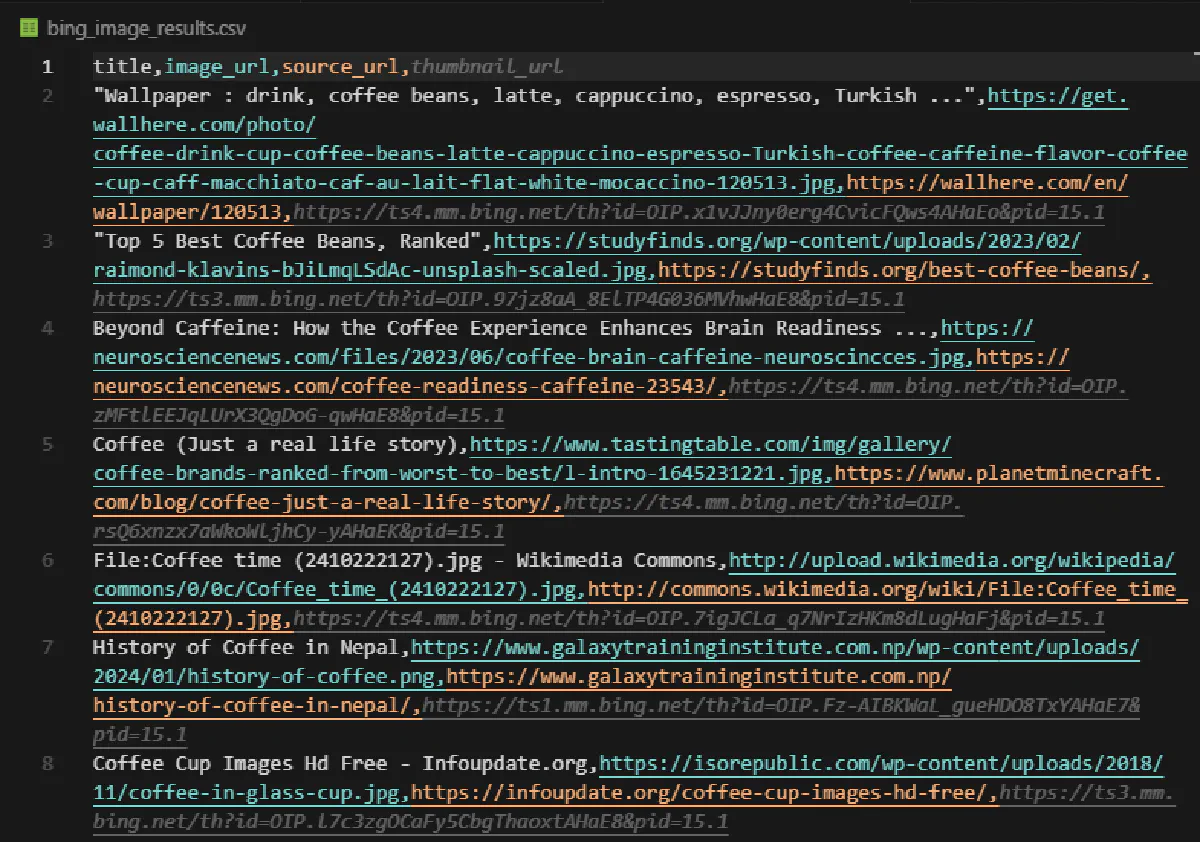
And if you enable downloading, it will create a new folder and download all the images scraped.
Scrape Bing Shopping Results
Bing Shopping loads product cards server-side with clean, consistent class names. The URL structure uses simple pagination with a page parameter.
https://www.bing.com/shop?q={query}&FORM=SHOPTB
https://www.bing.com/shop?q={query}&FORM=SHOPTB&page=2
https://www.bing.com/shop?q={query}&FORM=SHOPTB&page=3The FORM=SHOPTB parameter tells Bing to show the shopping-specific interface.
This scraper uses super=true in the Scrape.do parameters. This enables premium residential proxies and better JavaScript handling, which helps with shopping pages that occasionally load dynamic content.
Build the Shopping Scraper
The configuration sets a page limit. The scraper loops through multiple pages until it reaches max_pages.
This uses Scrape.do's super=true parameter for premium proxies:
http://api.scrape.do?token={TOKEN}&url={ENCODED_URL}&geoCode=us&super=trueimport requests
import csv
import urllib.parse
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "iphone"
max_pages = 5
all_products = []
page = 1
print(f"Starting Bing Shopping scrape for: '{query}'")
print(f"Max pages: {max_pages}\n")
while page <= max_pages:
# Build URL
if page == 1:
target_url = f"https://www.bing.com/shop?q={query}&FORM=SHOPTB"
else:
target_url = f"https://www.bing.com/shop?q={query}&FORM=SHOPTB&page={page}"
encoded_url = urllib.parse.quote(target_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us&super=true"
print(f"Page {page}...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")The super=true parameter routes the request through Scrape.do's premium proxy pool. This increases the success rate for shopping pages, which tend to have stricter bot detection than standard search.
Parse Product Cards
Each product sits inside a div with class br-gOffCard. The structure is consistent: title in br-offTtl, price in br-price or l2vh_pr, seller in br-offSlrTxt, and product URL in br-offLink:
# Extract products
page_products = []
# Find all product cards
for product_card in soup.find_all("div", class_="br-gOffCard"):
try:
# Extract product name
name_tag = product_card.find("div", class_="br-offTtl")
product_name = name_tag.get_text(strip=True)
# Extract price (can be in different formats)
price_tag = product_card.find("div", class_="l2vh_pr") or product_card.find("div", class_="br-price")
product_price = price_tag.get_text(strip=True) if price_tag else ""
# Extract seller
seller_tag = product_card.find("span", class_="br-offSlrTxt")
seller_name = seller_tag.get_text(strip=True) if seller_tag else ""
# Extract product URL
link_tag = product_card.find("a", class_="br-offLink")
product_url = link_tag["href"] if link_tag and link_tag.get("href") else ""
page_products.append({
"product_name": product_name,
"price": product_price,
"seller": seller_name,
"url": product_url
})
except:
continue
if not page_products:
print("No products found")
break
all_products.extend(page_products)
print(f"Found {len(page_products)} products (total: {len(all_products)})")
page += 1The try-except wrapper handles cards with missing elements. Some products might not have visible prices (out of stock, requires login, etc.), and we don't want parsing failures to stop the scraper.
The price extraction includes a fallback between l2vh_pr and br-price classes, as Bing uses different class names depending on the product type.
Export Shopping Data
Here's the full code with export logic added:
import requests
import csv
import urllib.parse
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "iphone"
max_pages = 5
all_products = []
page = 1
print(f"Starting Bing Shopping scrape for: '{query}'")
print(f"Max pages: {max_pages}\n")
while page <= max_pages:
# Build URL
if page == 1:
target_url = f"https://www.bing.com/shop?q={query}&FORM=SHOPTB"
else:
target_url = f"https://www.bing.com/shop?q={query}&FORM=SHOPTB&page={page}"
encoded_url = urllib.parse.quote(target_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us&super=true"
print(f"Page {page}...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract products
page_products = []
# Find all product cards
for product_card in soup.find_all("div", class_="br-gOffCard"):
try:
# Extract product name
name_tag = product_card.find("div", class_="br-offTtl")
product_name = name_tag.get_text(strip=True)
# Extract price (can be in different formats)
price_tag = product_card.find("div", class_="l2vh_pr") or product_card.find("div", class_="br-price")
product_price = price_tag.get_text(strip=True) if price_tag else ""
# Extract seller
seller_tag = product_card.find("span", class_="br-offSlrTxt")
seller_name = seller_tag.get_text(strip=True) if seller_tag else ""
# Extract product URL
link_tag = product_card.find("a", class_="br-offLink")
product_url = link_tag["href"] if link_tag and link_tag.get("href") else ""
page_products.append({
"product_name": product_name,
"price": product_price,
"seller": seller_name,
"url": product_url
})
except:
continue
if not page_products:
print("No products found")
break
all_products.extend(page_products)
print(f"Found {len(page_products)} products (total: {len(all_products)})")
page += 1
# Save to CSV
print(f"\nSaving {len(all_products)} products to CSV...")
with open("bing_shopping_results.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["product_name", "price", "seller", "url"])
writer.writeheader()
writer.writerows(all_products)
print(f"Done! Extracted {len(all_products)} products across {page - 1} pages -> bing_shopping_results.csv")The CSV contains all product details:
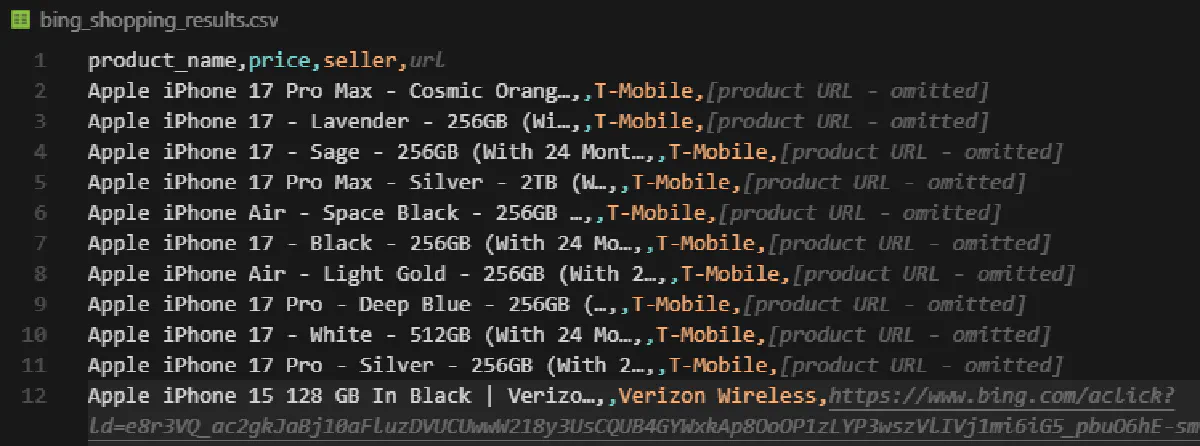
Scrape Bing News Articles
Bing News uses an infinite scroll AJAX endpoint (/news/infinitescrollajax) that loads articles in batches without full page refreshes.
The URL includes a qft=sortbydate%3d%221%22 parameter that sorts results by date, giving you the most recent articles first.
https://www.bing.com/news/infinitescrollajax?qft=sortbydate%3d%221%22&InfiniteScroll=1&q={query}&first=1
https://www.bing.com/news/infinitescrollajax?qft=sortbydate%3d%221%22&InfiniteScroll=1&q={query}&first=11
https://www.bing.com/news/infinitescrollajax?qft=sortbydate%3d%221%22&InfiniteScroll=1&q={query}&first=21Pagination works through the first parameter, which increments by 10 for each request. This is different from image search (which increments by actual count) and web search (which increments by offset calculation).
Build the News Scraper
The configuration sets a collection target. The scraper collects up to max_results articles.
Requests route through Scrape.do's API:
http://api.scrape.do?token={TOKEN}&url={ENCODED_URL}&geoCode=usimport requests
import csv
import urllib.parse
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "tesla"
max_results = 100
all_news = []
first = 1 # Pagination starts at 1, increments by 10
print(f"Starting Bing News scrape for: '{query}'")
print(f"Target: {max_results} articles\n")The infinite scroll URL uses InfiniteScroll=1 to get raw article HTML without the page wrapper:
while len(all_news) < max_results:
# Build URL for infinite scroll
page_url = f"https://www.bing.com/news/infinitescrollajax?qft=sortbydate%3d%221%22&InfiniteScroll=1&q={urllib.parse.quote(query)}&first={first}"
encoded_url = urllib.parse.quote(page_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us"
print(f"Fetching articles (first={first})...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")The query gets encoded twice: once with urllib.parse.quote(query) for the Bing URL, and again with urllib.parse.quote(page_url, safe='') for the Scrape.do wrapper.
Parse News Articles
News articles are wrapped in div elements with class news-card. Each card contains structured data attributes (data-url, data-author) alongside standard HTML elements:
# Extract news articles
page_articles = []
# News articles are in divs with class "news-card newsitem cardcommon"
for article in soup.find_all("div", class_="news-card"):
try:
# Extract title
title_tag = article.find("a", class_="title")
title = title_tag.get_text(strip=True) if title_tag else ""
# Extract URL
url = article.get("data-url", "") or article.get("url", "")
# Extract snippet/description
snippet_tag = article.find("div", class_="snippet")
snippet = snippet_tag.get_text(strip=True) if snippet_tag else ""
# Extract source (data-author attribute)
source = article.get("data-author", "")
# Extract time (look for span with tabindex="0")
time_tag = article.find("span", {"tabindex": "0"})
published_time = time_tag.get_text(strip=True) if time_tag else ""
if title:
page_articles.append({
"title": title,
"url": url,
"snippet": snippet,
"source": source,
"published_time": published_time
})
except:
continueThe data-url attribute holds the article URL, but some cards use a plain url attribute instead. The or fallback handles both cases.
Published time appears in relative format ("2h ago", "1d ago") from a span with tabindex="0". This isn't semantic, but it's consistent across the news feed.
After extracting articles, we check if any were found and update the pagination offset:
# Stop if no articles found
if not page_articles:
print("No more articles found")
break
all_news.extend(page_articles)
print(f"Found {len(page_articles)} articles (total: {len(all_news)})")
# Next page - increment by 10
first += 10The first parameter always increments by 10, regardless of how many articles were returned. This is different from the image scraper's dynamic increment.
Export News Data
Here's the full code with export logic added:
import requests
import csv
import urllib.parse
from bs4 import BeautifulSoup
# Configuration
token = "<your-token>"
query = "tesla"
max_results = 100
all_news = []
first = 1 # Pagination starts at 1, increments by 10
print(f"Starting Bing News scrape for: '{query}'")
print(f"Target: {max_results} articles\n")
while len(all_news) < max_results:
# Build URL for infinite scroll
page_url = f"https://www.bing.com/news/infinitescrollajax?qft=sortbydate%3d%221%22&InfiniteScroll=1&q={urllib.parse.quote(query)}&first={first}"
encoded_url = urllib.parse.quote(page_url, safe='')
api_url = f"http://api.scrape.do?token={token}&url={encoded_url}&geoCode=us"
print(f"Fetching articles (first={first})...", end=" ")
# Send request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract news articles
page_articles = []
# News articles are in divs with class "news-card newsitem cardcommon"
for article in soup.find_all("div", class_="news-card"):
try:
# Extract title
title_tag = article.find("a", class_="title")
title = title_tag.get_text(strip=True) if title_tag else ""
# Extract URL
url = article.get("data-url", "") or article.get("url", "")
# Extract snippet/description
snippet_tag = article.find("div", class_="snippet")
snippet = snippet_tag.get_text(strip=True) if snippet_tag else ""
# Extract source (data-author attribute)
source = article.get("data-author", "")
# Extract time (look for span with tabindex="0")
time_tag = article.find("span", {"tabindex": "0"})
published_time = time_tag.get_text(strip=True) if time_tag else ""
if title:
page_articles.append({
"title": title,
"url": url,
"snippet": snippet,
"source": source,
"published_time": published_time
})
except:
continue
# Stop if no articles found
if not page_articles:
print("No more articles found")
break
all_news.extend(page_articles)
print(f"Found {len(page_articles)} articles (total: {len(all_news)})")
# Next page - increment by 10
first += 10
# Trim to max_results
all_news = all_news[:max_results]
# Save to CSV
print(f"\nSaving {len(all_news)} articles to CSV...")
with open("bing_news_results.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["title", "url", "snippet", "source", "published_time"])
writer.writeheader()
writer.writerows(all_news)
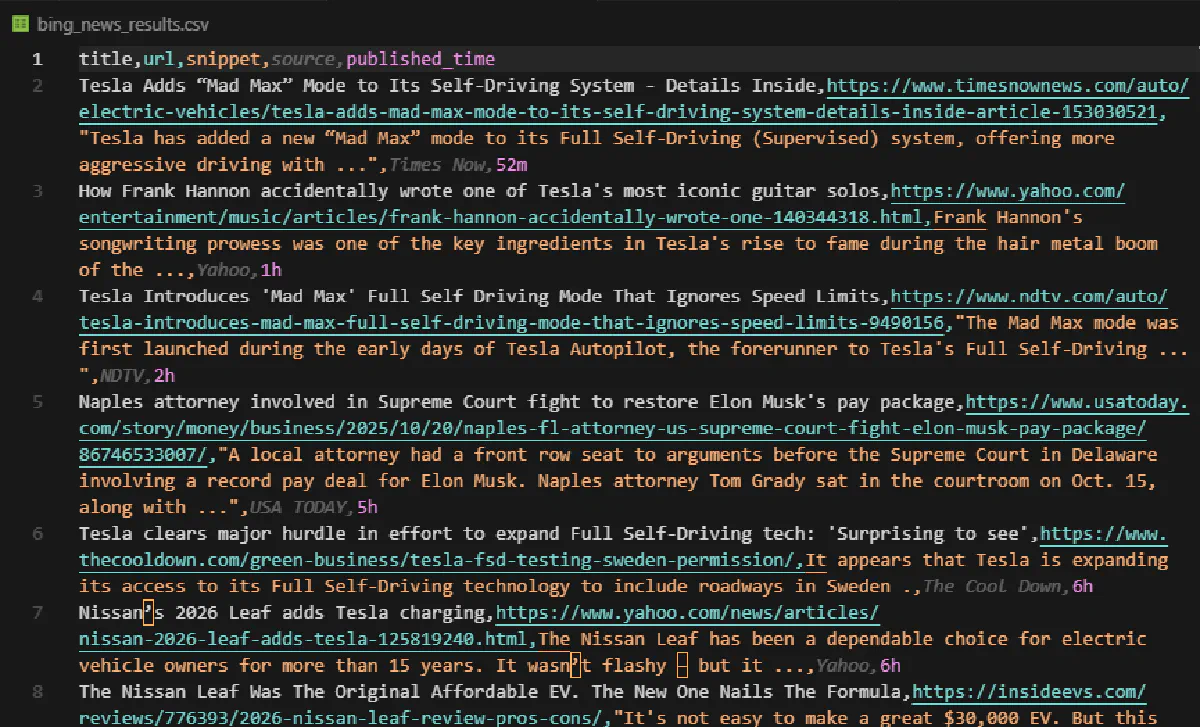
print(f"Done! Extracted {len(all_news)} articles -> bing_news_results.csv")The CSV contains all article metadata sorted by date:
Conclusion
Bing isn't a backup plan anymore.
These four scrapers provide production-ready access to web search results, image collections, shopping products, and news articles.
Each one handles pagination, error cases, and data export without requiring constant maintenance or workarounds.
Scrape.do handles the proxy rotation, geo-targeting, and anti-bot mechanisms, letting you focus on using the data instead of collecting it.
Get 1000 free credits and start scraping Bing with Scrape.do
R&D Engineer








