Category:Scraping Use Cases
Scraping AutoScout24: How to Extract Car Listings Without Getting Blocked

Full Stack Developer



As of February 2025, AutoScout24 hosts over 150,000 car listings and partners with 43,000+ dealerships, making it one of the most valuable platforms for vehicle pricing and market analysis in Europe.
Whether you're tracking price trends, comparing offers, or analyzing dealership data, scraping AutoScout24 can unlock huge business opportunities.
And if you’ve tried scraping AutoScout24, you’ve probably hit a wall.
The site actively prevents automated data collection using Akamai bot protection and IP-based restrictions, making traditional scraping techniques ineffective.
That doesn’t mean it’s impossible.
With the right approach, you can bypass these roadblocks and access the data you need without getting blocked.
In this guide, we’ll break down why AutoScout24 is difficult to scrape, what protections it uses, and how to extract car listings efficiently using Scrape.do.
Why Scraping AutoScout24 Is Difficult
AutoScout24 has implemented multiple layers of security to prevent automated data extraction. These protections make traditional scraping techniques unreliable and often result in blocked requests.
1. Akamai Bot Protection
AutoScout24 relies on Akamai’s bot detection system, which is designed to identify and block scrapers before they can access valuable data.
- It uses browser fingerprinting to detect non-human requests.
- JavaScript challenges verify if a page is being accessed by a real user.
- Behavior tracking monitors scrolling, mouse movements, and interactions.
If your scraper doesn’t mimic real user behavior, it will likely be blocked within a few requests.
2. IP-Based Restrictions
AutoScout24 tracks IP addresses to detect suspicious activity and enforce geo-restrictions.
- Requests from datacenter proxies are often blocked immediately.
- High-frequency requests from the same IP trigger rate limits.
- Some listings are region-locked, meaning certain data is only accessible from specific countries.
These security measures make it difficult to scrape AutoScout24 using basic requests or simple proxy rotation.
How Scrape.do Bypasses These Challenges
Scrape.do is designed to handle Akamai bot detection, IP tracking, and geo-restrictions, allowing uninterrupted access to AutoScout24’s listings.
Akamai Bypass
AutoScout24’s bot protection relies on browser fingerprinting, behavior tracking, and JavaScript challenges. Scrape.do automatically handles these by:
✅ Executing JavaScript to pass browser verification.
✅ Mimicking real user behavior by rotating headers, cookies, and TLS fingerprints.
✅ Preventing detection by dynamically adjusting request timing and patterns.
Geo-Targeted IPs
AutoScout24 enforces region-based access and blocks requests from datacenter proxies. Scrape.do ensures access by:
✅ Routing requests through Switzerland-based residential and ISP proxies.
✅ Maintaining session persistence to avoid tracking inconsistencies.
✅ Bypassing rate limits with smart request pacing.
With these optimizations, Scrape.do ensures smooth, unblocked access to AutoScout24’s data even at scale.
Extracting Data from AutoScout24 Without Getting Blocked
Now that we have bypassed AutoScout24’s protections, we’ll extract the car name and price from a real listing.
Prerequisites
Before making any requests, install the necessary dependencies if you haven’t already.
We’ll be using requests to send HTTP requests and BeautifulSoup to parse the HTML. Install them using:
pip install requests beautifulsoup4You’ll also need an API key from Scrape.do, which you can get by signing up at Scrape.do for free.
Next, we need a target page to scrape.
For this guide, we'll be working with a listing for the perhaps most classic sportscar, Porsche 911 Coupé 3.8 Turbo PDK.
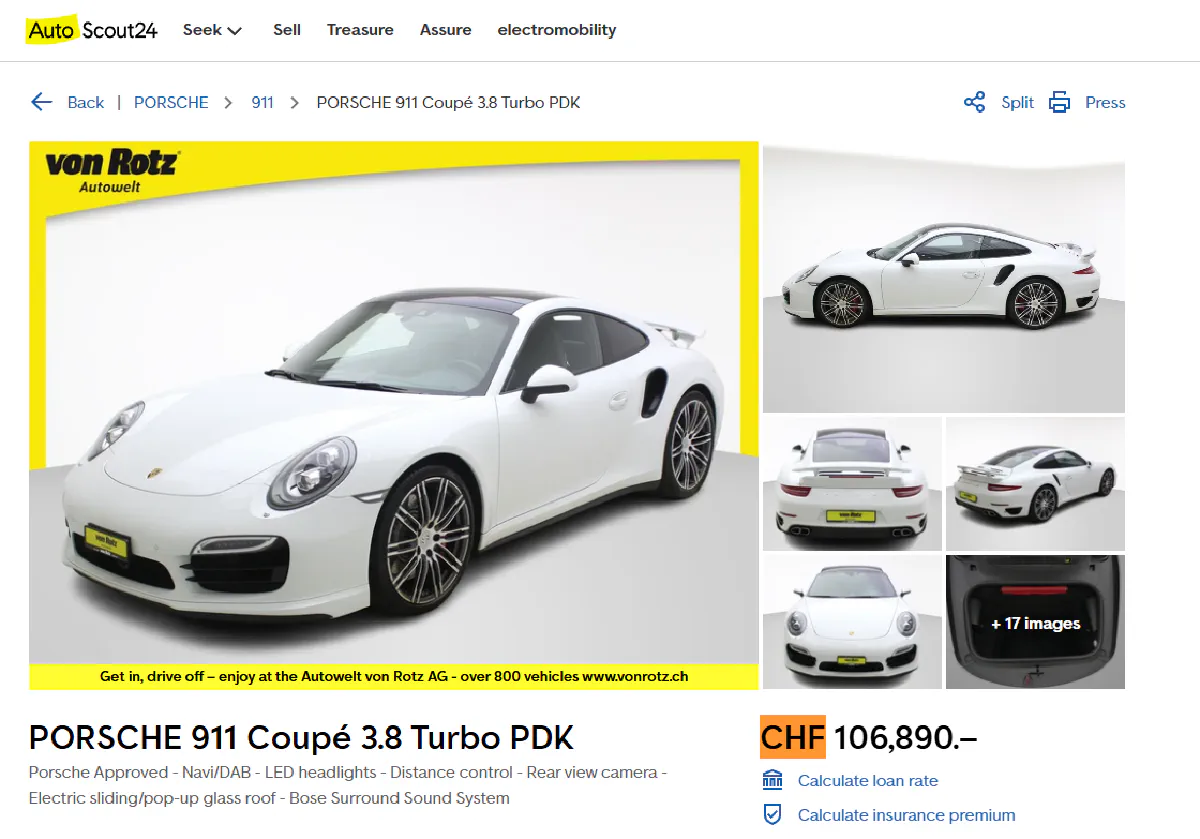
Sending a Request and Verifying Access
First, we’ll send a request through Scrape.do to ensure we can access the page without getting blocked.
If successful, we should receive a 200 OK response, confirming that we’ve bypassed AutoScout24’s protections.
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target AutoScout24 listing URL
target_url = urllib.parse.quote_plus("https://www.autoscout24.ch/de/d/porsche-911-coupe-38-turbo-pdk-12188643")
# Optional parameters
render = "true"
geo_code = "ch"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Print response status
print(response)Expected Output:
<Response [200]>If the request is successful, we can move on to extracting the car name.
💡 If you're not getting 200 OK, try adding &super=true paramater to the end of your Scrape.do API call, which will enable residential and mobile proxies that can usually bypass any WAF with ease but will cost more credits.
Extracting the Car Name
Now that we have confirmed access to the page, we can extract the car name from the listing.
The product name is stored inside an <h1> tag, making it easy to locate and extract using BeautifulSoup.
from bs4 import BeautifulSoup
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target AutoScout24 listing URL
target_url = urllib.parse.quote_plus("https://www.autoscout24.ch/de/d/porsche-911-coupe-38-turbo-pdk-12188643")
# Optional parameters
render = "true"
geo_code = "ch"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract car name
title = soup.find("h1").text.strip()
print("Car Name:", title)Expected Output:
Car Name: PORSCHE 911 Coupé 3.8 Turbo PDKBy targeting the first <h1> tag, we efficiently extract the car model name without needing to specify class attributes.
Extracting the Car Price
With the car name successfully extracted, the next step is to retrieve the listing price, which is the most important information on this page.
Initially, I've attempted to locate the price using a specific <p> tag with a predefined class. However, AutoScout24 dynamically assigns class names, which can change over time, making class-based extraction unreliable.
Instead, I've taken a more flexible approach by searching for the price text directly. Since all car prices on AutoScout24 include "CHF" followed by a number, we can use regular expressions (re module) to locate and extract it anywhere in the page content.
from bs4 import BeautifulSoup
import requests
import urllib.parse
import re
# Our token provided by Scrape.do
token = "<your_token>"
# Target AutoScout24 listing URL
target_url = urllib.parse.quote_plus("https://www.autoscout24.ch/de/d/porsche-911-coupe-38-turbo-pdk-12188643")
# Optional parameters
render = "true"
geo_code = "ch"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract car name
title = soup.find("h1").text.strip()
# Search for the first occurrence of "CHF" followed by a number
match = re.search(r"CHF\s([\d'.,]+)", soup.get_text())
# Extract and clean the price if found
price = match.group(0).replace("\xa0", " ") if match else "Price not found"
print("Car Name:", title)
print("Car Price:", price)Why does this work?
✅ Avoids dependency on class names that might change dynamically.
✅ Searches the entire page text, ensuring the price is found even if the structure varies.
✅ Uses regular expressions (re) to precisely extract numbers that follow "CHF".
And here's the expected output:
Car Name: PORSCHE 911 Coupé 3.8 Turbo PDK
Car Price: CHF 106,890.-This approach ensures that even if AutoScout24 updates its HTML structure, the price extraction will continue working reliably.
Conclusion
Scraping AutoScout24 is difficult due to Akamai bot protection and dynamic HTML structures, which block traditional scrapers and make extracting data unreliable.
We successfully extracted the car name and price by bypassing these obstacles with Scrape.do. Instead of relying on unstable class names, we used regular expressions to locate the price anywhere on the page, ensuring a more flexible and robust approach.
If you need to scrape AutoScout24 without getting blocked, Scrape.do makes it simple.
Full Stack Developer








