Category:Scraping Errors
What Error 429 "Too Many Requests" Means and How to Fix It in 2026

Founder @ Scrape.do


Although less common than it used to be, 429 "Too many requests." is still an error encountered when web scraping, crawling, or even casual browsing in rare cases.
It's a very basic error every person on the web should be familiar with, just like 404.
This guide will help you understand and fix error 429 "Too many requests."
What Is Error 429 "Too Many Requests"?
Error 429 “Too Many Requests” is an HTTP response status code that means you’ve exceeded the allowed number of requests in a given timeframe. It’s triggered by rate limiting, and it tells the client to slow down before making more requests.
In simpler terms, the server is saying “I’m getting too many hits from you, pause before trying again.”
You might see this when:
- Refreshing a page too often
- Making rapid API calls without delays
- Running a crawler or bot too aggressively
- Visiting from an IP that’s shared with other heavy users
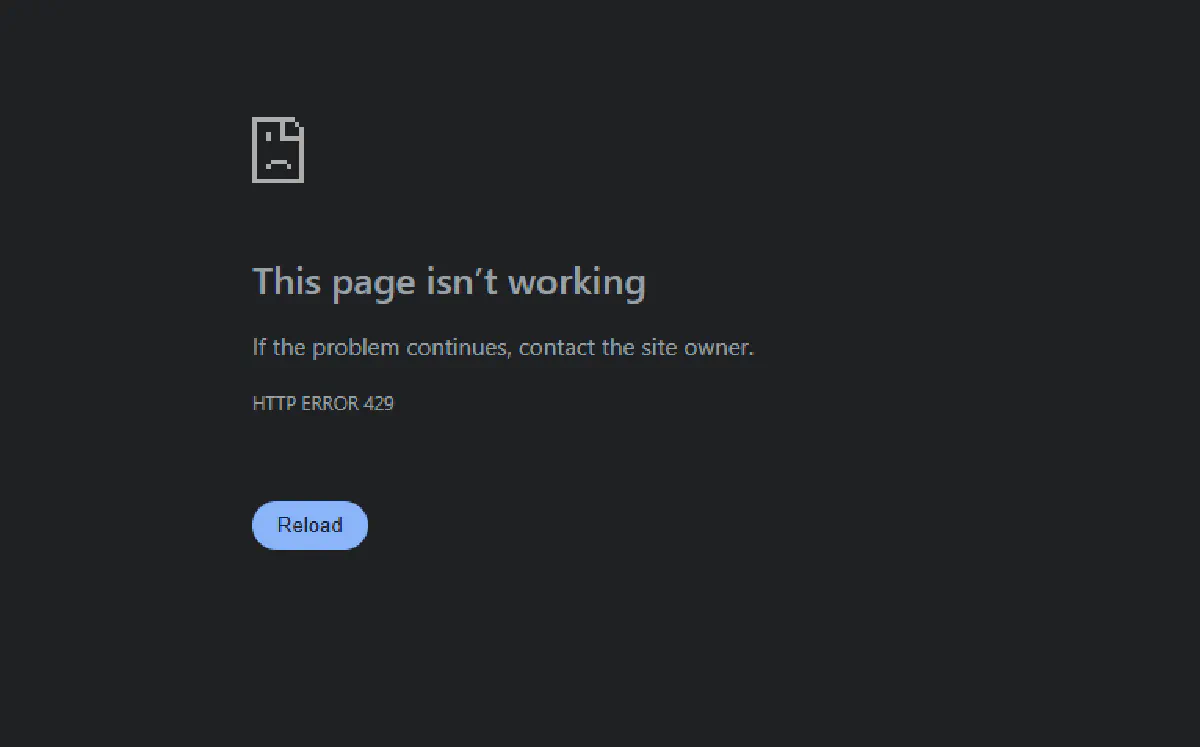
💡 Fun fact: Screenshot above is a result of 498 back-to-back requests to GitHub through a Python script with multiple threads. Unless you're using a shared IP, it's impossible to get this error.
The limit isn’t fixed; each server decides its own thresholds. Some use per-minute rules, others use rolling windows, and some block entirely after too many violations.
Understanding why 429 happens is the first step to avoiding it; whether you're browsing casually or running automation at scale.
Let's look at fixes:
How to Fix 429 When Browsing Casually
429 errors are mostly intended to stop bots and DDoS attacks, but you can hit them during normal use too.
Especially on developer-heavy sites, APIs, or apps with strict limits its much more common.
The good news? It’s usually easy to recover. Try one (or more) of the fixes below.
1. Wait and Refresh
Most 429 errors are temporary. Servers often use short cooldowns; 30 seconds, 1 minute, maybe a bit more.
Just wait and try again later.
Don’t spam the refresh button; that’ll only make things worse.
2. Switch Networks or Use a VPN
If you're on a shared IP (like at work, school, or via a public Wi-Fi), someone else might’ve triggered the limit, or worse, your network could be exposed and being used as proxy for bots 😟
Switching to a different network or enabling a VPN will give you a new IP, often enough to get past the block.
3. Close Background Tabs or Extensions
Some browser extensions or open tabs make repeated background requests. These can silently push you over the limit.
Close unnecessary tabs, pause extensions, and retry.
4. Use Incognito Mode or Clear Cookies
Sites can rate-limit based on session cookies or browser fingerprints.
Open the site in incognito mode, or clear your cookies and cache. It’s a clean slate that might bypass the throttle.
5. Check Site-Specific Limits
Platforms like GitHub or Reddit have public rate limits for unauthenticated users.
It's only fair, nobody likes anonymous users browsing 100 pages in a minute.
If you’re hitting those, the only fix might be to log in or wait.
Fix 429 "Too Many Requests" in Web Crawling & Scraping
For a deeper dive into how rate limiting works under the hood, see our complete guide to rate limits in web scraping.
When you're scraping, you're not behaving like a normal user.
You're sending dozens, hundreds, sometimes thousands of requests, often in seconds. That volume is exactly what triggers HTTP 429 “Too Many Requests.”
In fact, when scraping modern websites, most people encounter this error not as a plain 429, but through Cloudflare’s rate-limiting page: Error 1015.
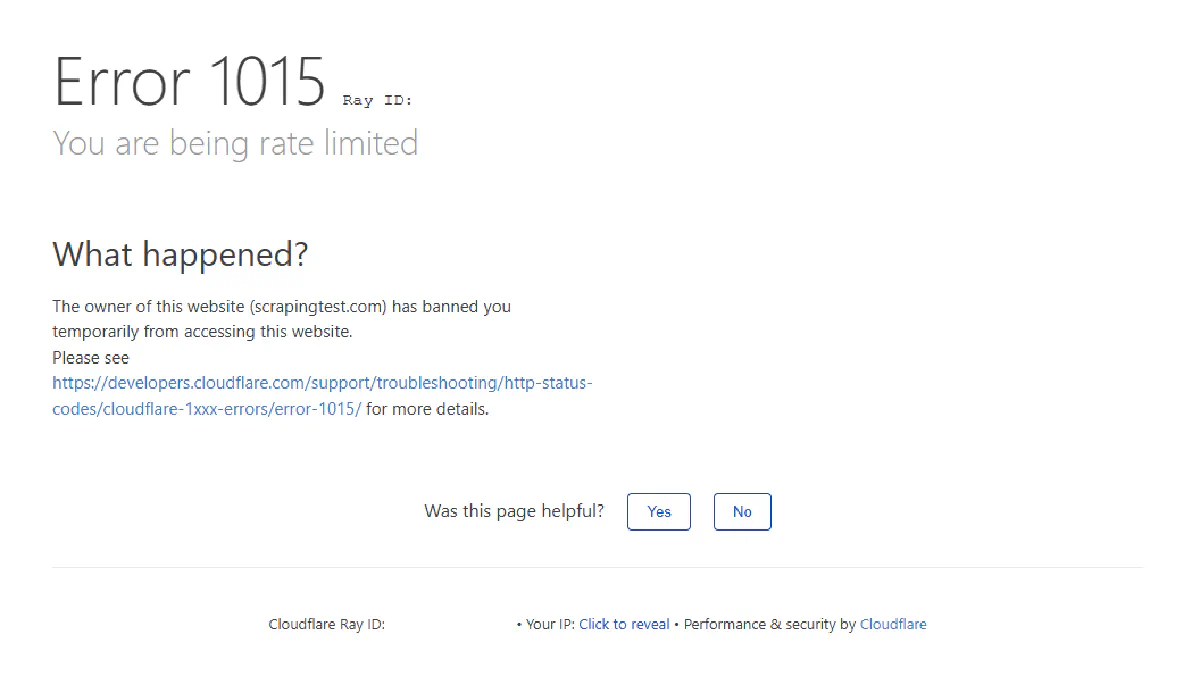
Let’s quickly recreate this in Python by sending 5 fast back-to-back requests to a test site designed to trigger rate limits.
Here’s a basic script that sends 5 requests and prints the status code and reason:
import requests
import time
url = "https://scrapingtest.com/cloudflare-rate-limit"
for i in range(5):
response = requests.get(url)
print(f"{i+1}: {response.status_code} {response.reason}")
time.sleep(0.5)And here's what the output will look like:
1: 200 OK
2: 429 Too Many Requests
3: 429 Too Many Requests
4: 429 Too Many Requests
5: 429 Too Many RequestsYour scraper's blocked before it even started walking, how about that?
Let's make it run:
1. Add Throttling or Delays
The first and most overlooked solution to 429 errors is simply slowing down.
When scraping, we tend to send requests as fast as the machine allows, milliseconds apart.
But real users don’t do that. They pause, scroll, read.
Adding delays between requests makes your script feel more human and gives the server time to breathe while improving your success rates.
And if you look at it from operational perspective, yes it will take longer to scrape all the date but your success rate will be high and if you set solid automations it will just run while you're doing something else.
There are two main approaches to this approach:
Option A: Random Delays (Human-Like)
This approach introduces a random pause between each request.
It’s useful when scraping public pages with mild protection.
Here’s how to add it to your scraper:
import requests
import time
import random
url = "https://scrapingtest.com/cloudflare-rate-limit"
for i in range(5):
response = requests.get(url)
print(f"{i+1}: {response.status_code} {response.reason}")
delay = random.uniform(5, 10)
print(f"Sleeping for {delay:.2f} seconds...")
time.sleep(delay)It's getting good results on the demo page:
1: 200 OK
Sleeping for 5.81 seconds...
2: 200 OK
Sleeping for 7.44 seconds...
3: 200 OK
Sleeping for 6.67 seconds...
4: 200 OK
Sleeping for 8.17 seconds...
5: 200 OKThis adds unpredictability to your request timing, which is a good thing. But it still runs as fast as your fastest delay.
Option B: Throttle to a Fixed Rate (e.g. 1 Request Every 5 Seconds)
Throttling is stricter.
You define the maximum number of requests per second (or per minute), and enforce it. Think of it like a metronome: tick, request, wait, repeat.
It’s especially useful when:
- You’re scraping APIs with documented rate limits
- You want predictable behavior for long-running scrapers
- You’re running across multiple threads and want global control
Here’s how to do it:
import requests
import time
url = "https://scrapingtest.com/cloudflare-rate-limit"
interval = 10 # seconds between requests
last_request_time = 0
for i in range(5):
now = time.time()
wait = max(0, interval - (now - last_request_time))
if wait > 0:
print(f"Throttling: waiting {wait:.2f} seconds...")
time.sleep(wait)
response = requests.get(url)
last_request_time = time.time()
print(f"{i+1}: {response.status_code} {response.reason}")And yep, it succeeds too:
Throttling: waiting 10.00 seconds...
1: 200 OK
Throttling: waiting 10.00 seconds...
2: 200 OK
Throttling: waiting 10.00 seconds...
3: 200 OK
Throttling: waiting 10.00 seconds...
4: 200 OK
Throttling: waiting 10.00 seconds...
5: 200 OKThis method doesn’t try to look human, it just respects limits.
And for many sites, that’s all you need.
2. Rotate Proxies (and Headers If Necessary)
Sometimes slowing down isn’t enough.
You’re still getting blocked because your IP address is now flagged.
That’s when you need to rotate proxies.
Using a pool of proxies lets you spread your requests across multiple IPs, making each one look less aggressive.
⚠️ Some websites also track headers, especially
User-Agent,Accept, andReferer. If your headers look fake or too consistent, you may get rate-limited even with proxies. We'll skip that here since it’s less common, but keep it in mind for more protected sites.
Let’s update our script to rotate proxies with free proxies I found from a random pool:
import requests
# Proxy pool
proxies = [
{'http': 'http://14.239.189.250:8080', 'https': 'http://14.239.189.250:8080'},
{'http': 'http://103.127.252.57:3128', 'https': 'http://103.127.252.57:3128'},
{'http': 'http://59.29.182.162:8888', 'https': 'http://59.29.182.162:8888'},
{'http': 'http://77.238.103.98:8080', 'https': 'http://77.238.103.98:8080'}
]
url = "https://scrapingtest.com/cloudflare-rate-limit"
for i in range(5):
proxy = proxies[i % len(proxies)]
print(f"Using proxy: {proxy['http']}")
try:
response = requests.get(url, proxies=proxy, timeout=10)
print(f"{i+1}: {response.status_code} {response.reason}")
except Exception as e:
print(f"{i+1}: Request failed with error → {e}")And it succeeds too:
Using proxy: http://14.239.189.250:8080
1: 200 OK
Using proxy: http://103.127.252.57:3128
2: 200 OK
Using proxy: http://59.29.182.162:8888
3: 200 OK
Using proxy: http://77.238.103.98:8080
4: 200 OK
Using proxy: http://14.239.189.250:8080
5: 200 OKEvery request uses a different IP, and since each one is making only a single call, none of them hit the rate limit.
This is the simplest version of proxy rotation.
It won’t bypass Cloudflare or other WAFs, but for lightweight targets or open APIs, it’s often enough to bypass 429 entirely.
3. Let Scrape.do Handle Proxy and Header Rotation
If you're dealing with serious rate limiting or you just don’t want to manage proxies, headers, or delays, Scrape.do handles it all for you.
Behind the scenes, it rotates:
- Proxies from a 100M+ IP pool (residential, mobile, datacenter)
- Headers and User-Agents with real device/browser fingerprints
- TLS fingerprints, session tokens, and more
- With solid success-aware retry-logic making you pay only for pages you actually scrape
Here’s how to use it with the same test URL we’ve been hitting (you'll need a FREE API key from Scrape.do):
import requests
import urllib.parse
# Your Scrape.do API token
token = "<your_token>"
# Target URL
target_url = "https://scrapingtest.com/cloudflare-rate-limit"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint - enabling super=true for premium proxies
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true"
# Send 5 requests through Scrape.do
for i in range(5):
response = requests.get(api_url)
print(f"{i+1}: {response.status_code} {response.reason}")All successful:
1: 200 OK
2: 200 OK
3: 200 OK
4: 200 OK
5: 200 OKNo delays. No proxy setup. No 429s.
And if you're scraping something more complex (like JavaScript-heavy pages or protected APIs), Scrape.do can even render full pages or reuse sessions with simple parameters.
This is the most reliable way to get around rate limiting, especially at scale.
Conclusion
429 errors are inevitable when scraping aggressively or using an exposed network, but they’re not unbeatable.
Add delays, rotate proxies, or just let Scrape.do handle everything for you.
Founder @ Scrape.do








