Category:Scraping Use Cases
How to Scrape Zoro.com Without Getting Blocked (Step-by-Step Guide)

Lead Software Engineer



Scraping Zoro.com is tricky.
It’s one of the big success stories for DataDome, a major anti-bot provider, which means its defenses are tight.
They block scrapers fast; detecting automated traffic, flagging proxies, and throwing up CAPTCHAs before you even get started.
But that doesn’t mean it’s impossible.
In this guide, we’ll break down why Zoro is hard to scrape and how to get past its defenses using Scrape.do to extract product data without getting blocked.
Find fully functioning code here. ⚙
Why Scraping Zoro Is Difficult
Zoro doesn’t just block scrapers; it shuts them down fast.
It runs DataDome’s anti-bot protection, which means scraping with basic requests, datacenter proxies, or high-frequency automation gets you blocked almost instantly.
1. Advanced Bot Detection
DataDome analyzes browsing behavior, request headers, and IP reputation to spot automation. If your request doesn’t look like a real user’s, you’re out.
2. IP and Session Tracking
It doesn’t just block one request and move on. Zoro tracks sessions, correlates multiple requests, and flags unusual patterns.
Switching IPs isn’t enough; the system keeps an eye on browsing behavior and interaction timing.
3. Dynamic Content Loading
Prices and product details don’t always load with the initial HTML.
Some of it comes in later through JavaScript, making traditional scrapers miss key data unless they can handle dynamic rendering.
This combination makes Zoro one of the tougher sites to scrape, but not impossible.
With the right approach, you can get past these barriers without triggering blocks.
How Scrape.do Bypasses These Challenges
Scrape.do makes scraping Zoro easy by handling all the anti-bot defenses for you.
✅ Mimics real users: Rotates headers, user agents, and TLS fingerprints to avoid detection.
✅ Bypasses IP tracking: Uses real residential and ISP-based IPs with sticky sessions.
✅ Handles JavaScript: Loads dynamic content so you don’t miss key data.
✅ Avoids CAPTCHAs: Automatically retries and adjusts requests to stay unblocked.
With Scrape.do, you don’t have to worry about blocks. Send your request and get clean data, every time.
Extracting Data from Zoro Without Getting Blocked
Let's try to scrape a product page from Zoro.com so I can show how easy it is.
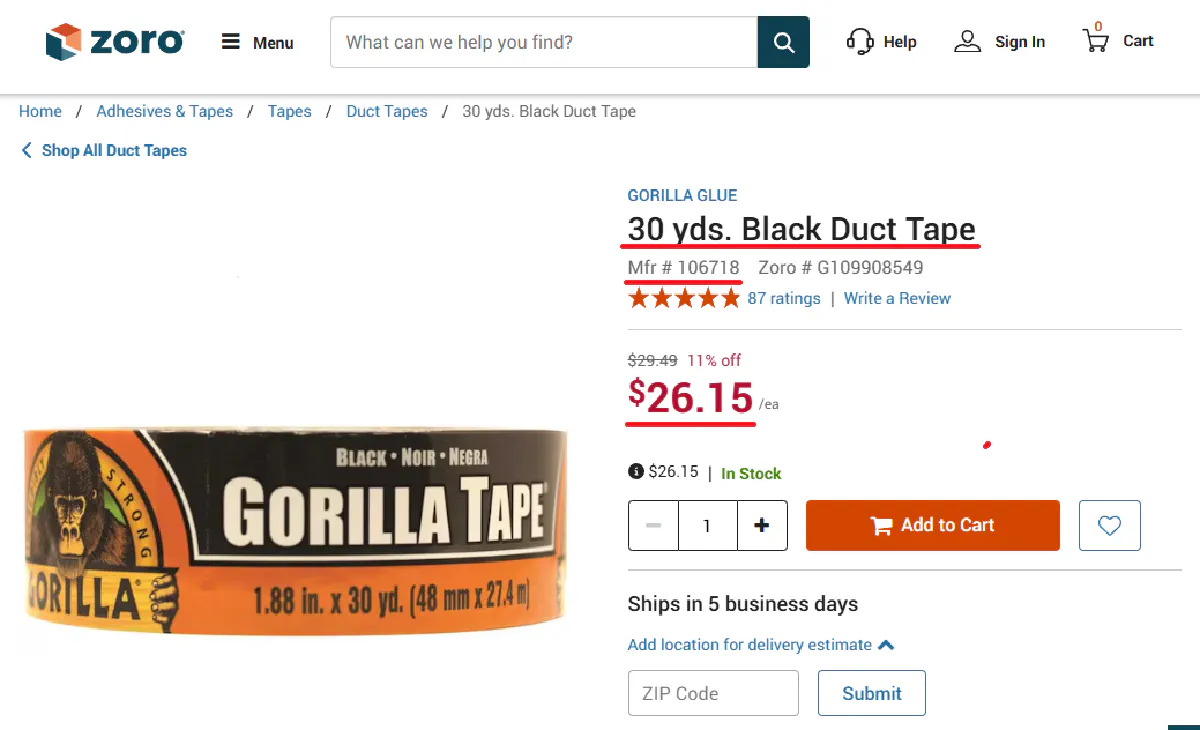
We’ll scrape a Gorilla Glue Duct Tape product page (I've chosen it purely based on the gorilla image they have on the packaging) and extract three key details:
- Product Name (from the
<h1>tag) - MFR Number (from the product-identifiers container)
- Price (from the span with class
"currency text-h2")
1. Prerequisites
First, install the required dependencies:
pip install requests beautifulsoup4You'll also need an API key from Scrape.do, which you can get for free here.
2. Sending a Request and Verifying Access
Before scraping, we need to make sure we can access the page without getting blocked.
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Zoro product URL
target_url = urllib.parse.quote_plus("https://www.zoro.com/gorilla-glue-30-yds-black-duct-tape-106718/i/G109908549/")
# Optional parameters
render = "false"
geo_code = "us"
super_mode = "true"
# Scrape.do API endpoint
url = f"http://api.scrape.do/?token={token}&url={target_url}&render={render}&geoCode={geo_code}&super={super_mode}"
# Send the request
response = requests.request("GET", url)
# Print response status
print(response)Here's the output we need to move forward:
<Response [200]>If you see 200 OK, that means Scrape.do successfully bypassed Zoro’s defenses, and we can move on to extracting product details.
If not, double-check your token and parameters to see if you can make things work. You can also try to enable render=true parameter of Scrape.do to bypass JS rendering.
3. Extracting the Product Name
The product name is stored inside an <h1> tag, making it easy to locate and extract.
from bs4 import BeautifulSoup
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract product name
product_name = soup.find("h1").text.strip()
print("Product Name:", product_name)Expected output:
Product Name: Gorilla Glue 30 Yds Black Duct Tape4. Extracting the MFR Number
We have the product name, but it's not the safest way to identify products, simply because it can be changed all the time.
Instead, we need the identifying number for the product, the MFR.
The MFR number is inside a div with the class "product-identifiers".
Instead of relying on class names, we extract the text after "Mfr #". For this, we'll import re.
import re
# Extract the product identifiers section
identifiers_div = soup.find("div", class_="product-identifiers")
# Get all text inside the div
identifiers_text = identifiers_div.get_text(" ", strip=True) if identifiers_div else ""
# Use regex to find the MFR number
mfr_match = re.search(r"Mfr\s*#\s*([\w\-/]+)", identifiers_text)
mfr_number = mfr_match.group(1) if mfr_match else "Not found"
print("MFR #:", mfr_number)Expected output:
MFR #: 1067185. Extracting the Product Price
And of course, to make sure this data is actionable, we'll need the price information.
The price is inside a <span> tag with class "currency text-h2", which makes it easy to target.
# Extract product price
price_span = soup.find("span", class_="currency text-h2")
product_price = price_span.text.strip() if price_span else "Not found"
print("Product Price:", product_price)And here's the expected output:
Product Price: $9.99Now that we have everything, let’s put it all together.
Final Code
import requests
from bs4 import BeautifulSoup
import re
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Zoro product URL
target_url = urllib.parse.quote_plus("https://www.zoro.com/gorilla-glue-30-yds-black-duct-tape-106718/i/G109908549/")
# Scrape.do API endpoint
url = f"http://api.scrape.do/?token={token}&url={target_url}&render=false&geoCode=us&super=true"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract product name
product_name = soup.find("h1").text.strip()
# Extract MFR number
identifiers_div = soup.find("div", class_="product-identifiers")
identifiers_text = identifiers_div.get_text(" ", strip=True) if identifiers_div else ""
mfr_match = re.search(r"Mfr\s*#\s*([\w\-/]+)", identifiers_text)
mfr_number = mfr_match.group(1) if mfr_match else "Not found"
# Extract product price
price_span = soup.find("span", class_="currency text-h2")
product_price = price_span.text.strip() if price_span else "Not found"
# Print results
print("Product Name:", product_name)
print("MFR #:", mfr_number)
print("Product Price:", product_price)And ta-da! You've just extracted your first data set from Zoro 🎉
Conclusion
Scraping Zoro is tough.
DataDome will block most scrapers before they even start, but not Scrape.do.
With Scrape.do, you don’t have to worry about getting flagged, dealing with CAPTCHAs, or missing data.
✅ Bypasses bot detection
✅ Uses real residential and ISP-based IPs
✅ Handles JavaScript-loaded content
✅ Keeps requests unblocked and clean
If you need to scrape thousands of Zoro product pages without interruptions, Scrape.do is the easiest way to do it.
Lead Software Engineer








