Category:Scraping Use Cases
Scrape Zillow Listings with Python (quick guide)

R&D Engineer


Zillow is the largest real estate platform in the U.S., attracting an average of 228 million monthly users in 2024.
But scraping it for competitive insights?
That’s where things get tricky.
The site isn’t fully locked down, but basic scrapers get blocked fast. And even if you get through, the HTML is messy and hard to parse.
In this guide, we’ll show you how to extract key listing data from Zillow using Python and Scrape.do:
Why Is Scraping Zillow Difficult?
Zillow doesn’t go as far as some platforms when it comes to blocking bots, but it’s still built to shut down anything that doesn’t look human.
Most scrapers fail for two reasons, let’s look at both.
PerimeterX Protection
Zillow uses PerimeterX to detect and block bot traffic in real-time.
If your scraper has the wrong headers, comes from a datacenter IP, or sends requests too fast, you’ll get flagged.
Most of the time, that flag means one thing: CAPTCHA.
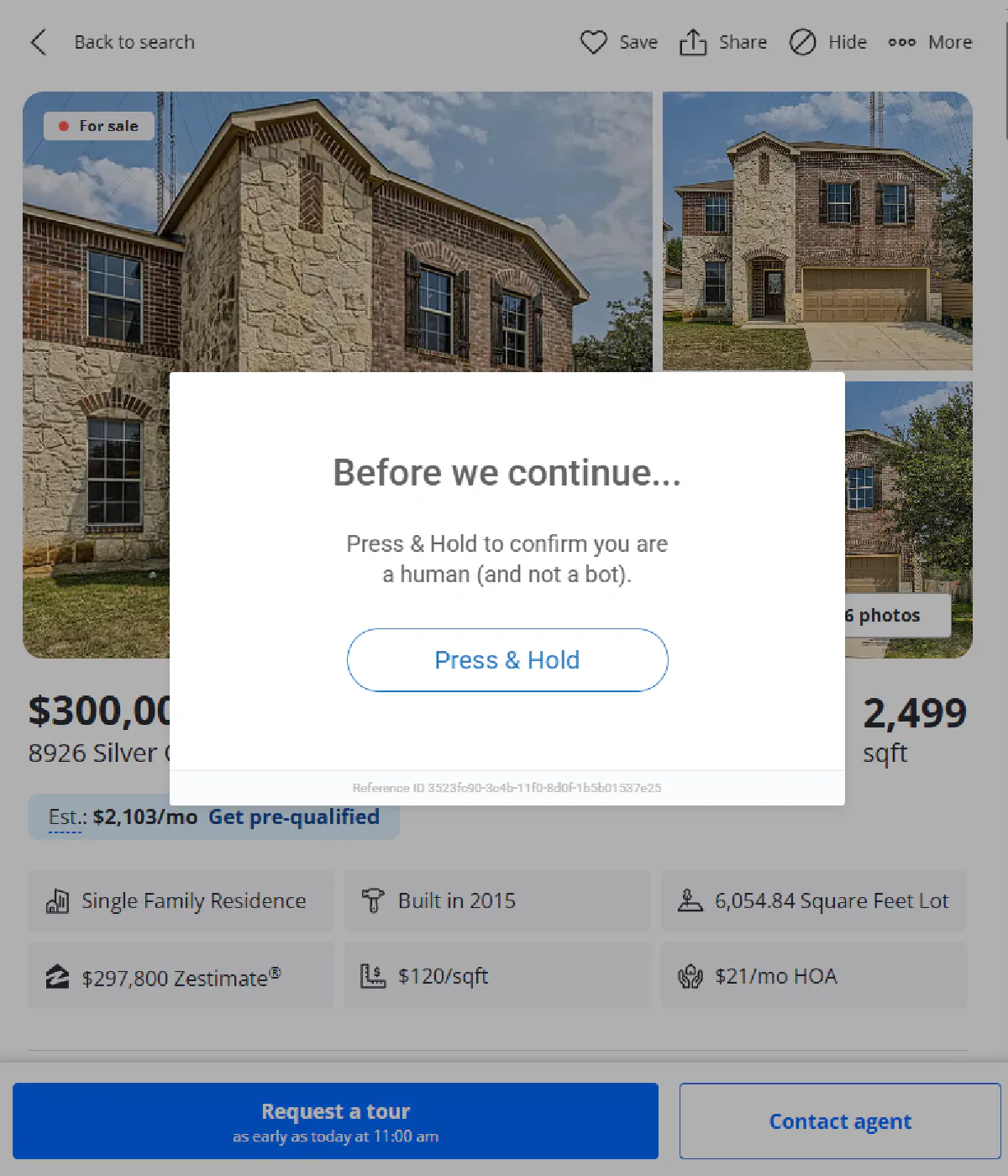
PerimeterX watches every detail; headers, TLS signatures, mouse movements, IP trust level. If anything feels automated, you're out.
Even rendering the page in a headless browser doesn’t guarantee success. You’ll still need solid proxy routing and realistic fingerprints just to reach the actual data.
Unstructured HTML and No Stable Selectors
Parsing Zillow is just as frustrating as getting past its defenses.
There are almost no consistent class names, IDs, or data attributes in the page source.
Elements that look simple like the price or address are wrapped in generic <div> tags or have no identifiers at all.
Even worse, class names change often and don’t follow any pattern.
So you have to use flexible matching (like keyword-based find() or even regex) to pull data from raw text nodes.
This makes Zillow one of the most unstable sites to scrape if you’re relying on static selectors.
Extract Listing Information from Zillow with Python
For this guide, we’ll target a real Zillow listing, a beautiful two-story house in San Antonio, Texas:
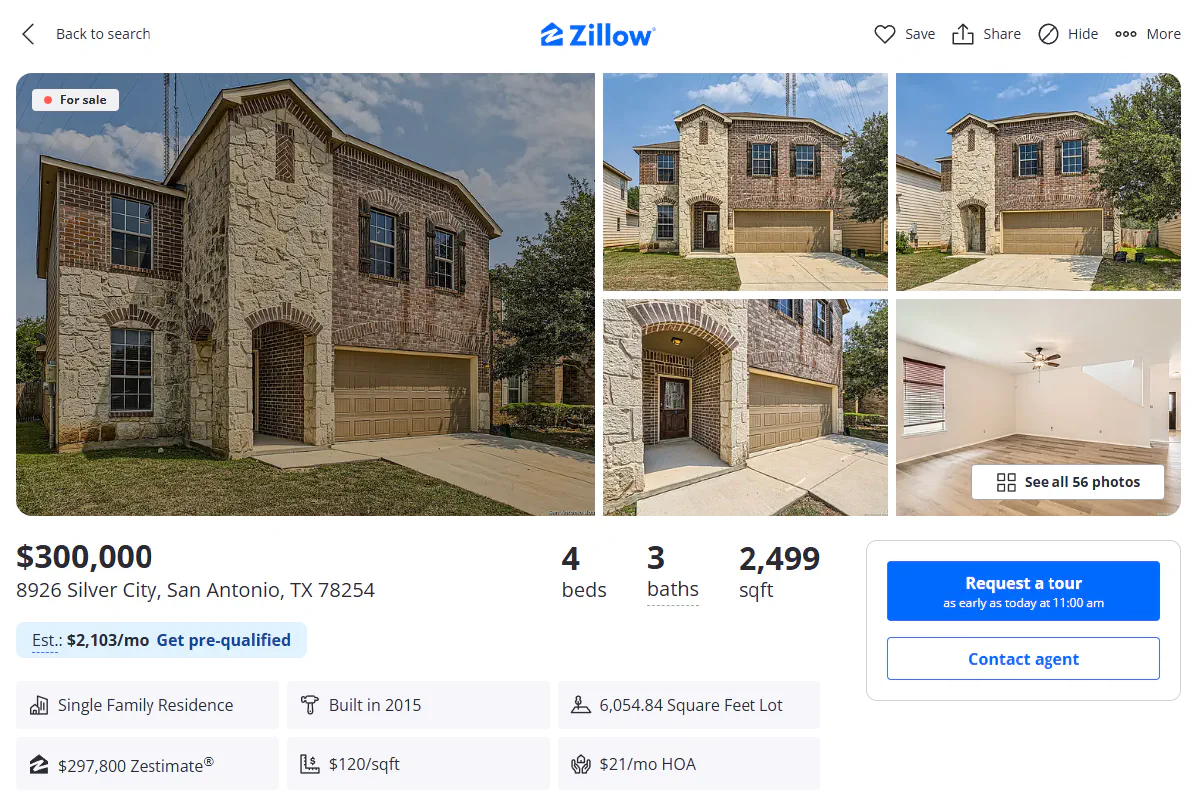
💡 This listing might not be available at the time of your reading, so I'll suggest you go to Zillow and find your listing URL and replace in the following code.
We'll pull out:
- The price of the home
- Full address (street, city, state)
- How many days it’s been listed on Zillow
- The Zestimate (Zillow’s estimated market value)
Let’s start with the setup:
Prerequisites
We’ll be using requests to make the API call and BeautifulSoup + re to parse the HTML and extract values from raw text.
If you haven’t already, install the dependencies:
pip install requests beautifulsoup4🔑 We will also be using Scrape.do to bypass PerimeterX and avoid CAPTCHA.
Sign up here for free and get your 1000 credits/month.
Sending the First Request
Let's send a request to the listing page using Scrape.do.
Zillow doesn’t fully block international traffic, but it does care about IP reputation and browser behavior, that’s where super=true parameter of Scrape.do comes in to enable premium proxies.
Here’s how to send the request and verify that it works:
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Your Scrape.do API token
token = "<your_token>"
# Target URL
target_url = "https://www.zillow.com/homedetails/8926-Silver-City-San-Antonio-TX-78254/124393863_zpid/"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint - enabling super=true for premium proxies
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true"
# Get and parse HTML
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
print(response)If everything goes right, you’ll see:
<Response [200]>Which means we’ve bypassed PerimeterX and received a clean, rendered page.
Scraping the Price
This is the easiest part of the entire scrape.
Zillow displays the listing price inside a <span> with the attribute data-testid="price", which makes it one of the few stable elements on the page.
We start by checking for that span, and if it’s not found (due to small layout differences), we fall back to regex to catch any large dollar amount in the raw text.
Here’s how:
# Extract price
price = (soup.find("span", {"data-testid": "price"})).get_text().strip()
print("Price:", price)This gets us a clean output like:
price: $300, 000;Just a straightforward field pulled from the page. Can't promise this simplicity for the next section :)
Scraping Address, City, and State
Unlike the price, Zillow’s address block isn’t marked with helpful selectors.
It appears in plain text, buried inside a complex header structure without stable classes or IDs.
So instead of relying on CSS selectors, we search the raw HTML text using regex.
It’s more reliable for patterns like addresses that don’t change visually, even when the page structure does.
Here’s the code:
# Extract address, city, and state
address_match = re.search(r'(\d+\s+[^,]+),\s*([^,]+),\s*(\w{2})\s+\d{5}', html_text)
street, city, state = address_match.groups()
print("Address:", street)
print("City:", city)
print("State:", state)- The regex looks for patterns like:
8926 Silver City, San Antonio, TX 78254 - It captures the street, city, and state separately
- Then we unpack those three parts into individual variables
This method isn’t tied to any DOM structure, so it keeps working even if Zillow shuffles its layout. We'll keep using this method for the rest of the information:
Scraping Zestimate and Days on Zillow
These two values don’t have consistent tags or attributes, so the cleanest approach is to use regex again, this time matching key phrases in the raw HTML.
For the Zestimate, we look for a dollar value that appears just before the word “Zestimate.” For days on Zillow, we match patterns like “5 days on Zillow.”
Here’s the code:
# Extract "days on Zillow"
days_match = re.search(r'(\d+)\s+days?\s*on\s+Zillow', html_text, re.IGNORECASE)
days_on = days_match.group(1) if days_match else "N/A"
# Extract Zestimate
zestimate_match = re.search(r'\$[\d,]+(?=\s*Zestimate)', html_text)
zestimate = zestimate_match.group() if zestimate_match else "N/A"
print("Days on Zillow:", days_on)
print("Zestimate:", zestimate)This approach avoids the unstable layout and targets the actual text content, making it much more resilient across different listings.
Final Code and Output
Below is the complete Python scraper for Zillow. It uses Scrape.do to bypass PerimeterX, parses the page with BeautifulSoup, and extracts key fields with a mix of DOM parsing and regex:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import re
# Your Scrape.do API token
token = "<your_token>"
# Target URL
target_url = "https://www.zillow.com/homedetails/8926-Silver-City-San-Antonio-TX-78254/124393863_zpid/"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint - enabling super=true for premium proxies
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true"
# Get and parse HTML
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
html_text = soup.get_text()
# Extract price
price = (soup.find("span", {"data-testid": "price"})).get_text().strip()
# Extract address, city, and state
address_match = re.search(r'(\d+\s+[^,]+),\s*([^,]+),\s*(\w{2})\s+\d{5}', html_text)
street, city, state = address_match.groups()
# Extract "days on Zillow" - look for exact phrase with flexible spacing
days_match = re.search(r'(\d+)\s+days?\s*on\s+Zillow', html_text, re.IGNORECASE)
days_on = days_match.group(1)
# Extract Zestimate
zestimate_match = re.search(r'\$[\d,]+(?=\s*Zestimate)', html_text)
zestimate = zestimate_match.group()
# Print results
print("Price:", price)
print("Address:", street)
print("City:", city)
print("State:", state)
print("Days on Zillow:", days_on)
print("Zestimate:", zestimate)And here’s the expected output:
Price: $300,000
Address: 8926 Silver City
City: San Antonio
State: TX
Days on Zillow: 5
Zestimate: $297,800Which means that you're now able to scrape key info from any Zillow listing 🎉
Conclusion
Zillow doesn’t look like a high-security site, but that's mischievously misleading :)
PerimeterX will let you in if you have proper IP and headers, let you browse. But start acting suspicious and your bot will be flagged from Zillow indefinitely.
That's where Scrape.do comes in:
- Premium rotating residential proxies
- Rotating headers and TLS fingerprinting
- Clean, fully loaded HTML every time
- Only pay for successful responses
Unblocked access with only 1 line of code.
R&D Engineer








