Category:Scraping Basics
Rate Limit in Web Scraping: How It Works and 5 Bypass Methods

Founder @ Scrape.do


Nearly half of all internet traffic comes from bots.
And with the rise of AI tools and AI agents, it seems like it'll increase even more.
And to make sure this huge amount of bot traffic doesn't overwhelm them, websites employ one of the most basic forms of anti-bot protection: rate limiting.
In this guide, we'll explore what rate limiting is, and how you can easily bypass it:
What Is a Rate Limit in Web Scraping?
Rate limiting is a technique websites use to control how often a user (or bot) can access their server in a given time frame, like a speed limit for your web scraper.
If you’re sending too many requests too quickly, say more than 100 per minute from the same IP, the website will tell you to slow down or stop altogether. The purpose isn’t to block scraping entirely; it’s to prevent abuse and reduce server strain.
From a site’s perspective, a flood of rapid requests can look like spam, scraping abuse, or even a DDoS attack.
That’s why rate limits are not about banning bots; they’re about protecting performance.
So when you see a site responding with errors or delays after a burst of requests, that’s rate limiting in action — the website’s way of saying:
“You can scrape data… but only this much, this often.”
How Do Rate Limits Work?
Technically, a server enforces a rate limit by tracking identifiers like your IP address or user account and counting how many requests come from that ID in a given time window.
If the count exceeds the threshold, it either delays or blocks your next request. For example, if a site allows 10 requests per minute and you send an 11th, it can instantly block it (typically with an HTTP 429 Too Many Requests error).
After the time window resets, requests are allowed again.
Some servers keep it simple; others don’t.
A basic setup might just record timestamps and check how many have arrived in the past 60 seconds.
More advanced systems use something called a token bucket: the server gives you 100 tokens per minute; each request uses one. When your bucket is empty, you wait until it refills.
Another common model is the sliding window (instead of counting requests from minute to minute, it counts them over the last rolling 60 seconds at any time).
Modern CDNs and frameworks (Cloudflare, AWS, etc.) often come with this logic pre-built. They don’t just count requests; they analyze how your scraper behaves.
That includes things like TLS fingerprints, headers, and whether your traffic actually looks like a browser.
Types of Rate Limits and Errors
Not all rate limits are created equal.
Some are lenient and let your scraper continue at a slower pace; others shut you out completely.
And if you push too hard for too long, you might not just get blocked, you might get banned.
Understanding these different responses is key to avoiding downtime and scraping smarter.
Soft Limits (Throttling)
Soft rate limits are gentle warnings.
You’re allowed to exceed the baseline briefly; the server might slow down responses, inject artificial delays, or send back a 429 Too Many Requests with a Retry-After header, like Cloudflare's Error 1015:
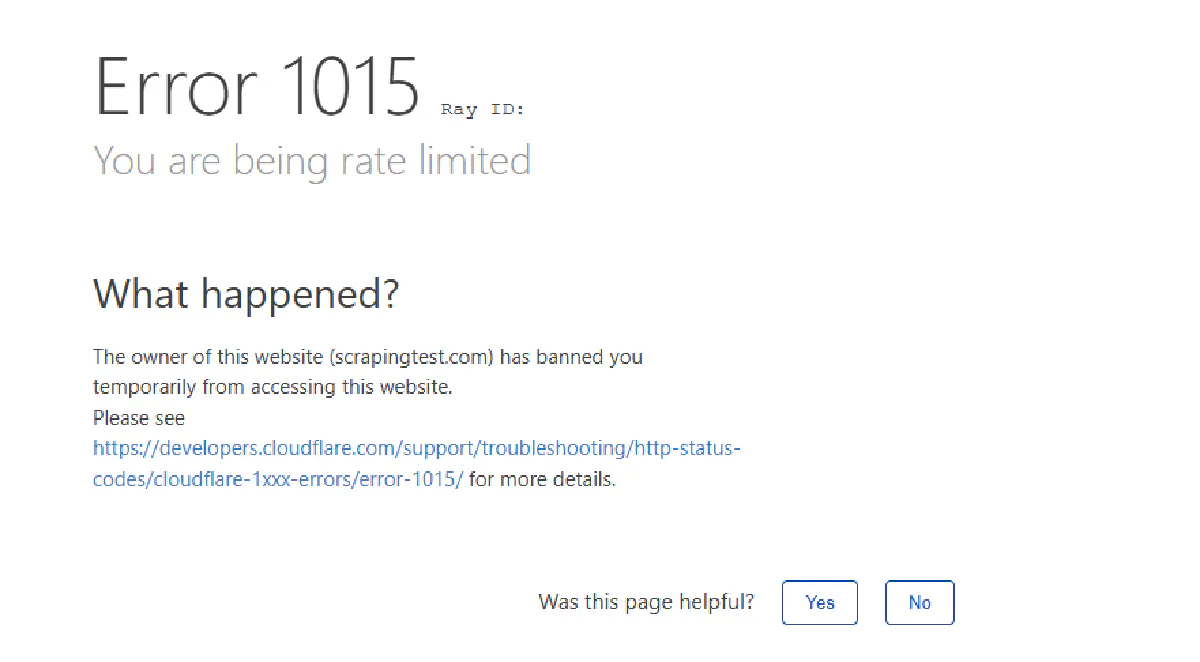
Some sites allow small bursts above the limit. For example, you might be allowed 100 requests per minute but can push to 120 before being throttled.
Other sites apply soft limits earlier; like one platform that starts throttling at 15 requests per minute, but only blocks completely at 30.
These limits are usually temporary. If you pause or reduce your request rate, you’ll often slip back under the radar and continue scraping without issues.
Hard Limits
Hard limits are strict ceilings.
Once you hit them, the server blocks all requests from your scraper for a defined period. There’s no warning or slow-down — just a hard stop.
These limits are usually tied to IP address, API key, or account. For example, an API might allow 1000 requests per hour.
Go over that, and you're locked out for the rest of the hour.
Servers often respond with HTTP 429 when enforcing hard limits. If abuse continues, they might escalate to 403 Forbidden signaling that your scraper is no longer welcome and permanently blocked.
Temporary Bans
If you continue hitting rate limits too often, many websites escalate to temporary bans. These are timeouts that last anywhere from a few minutes to several hours.
During that period, every request will fail with a 403 Forbidden that looks like this:
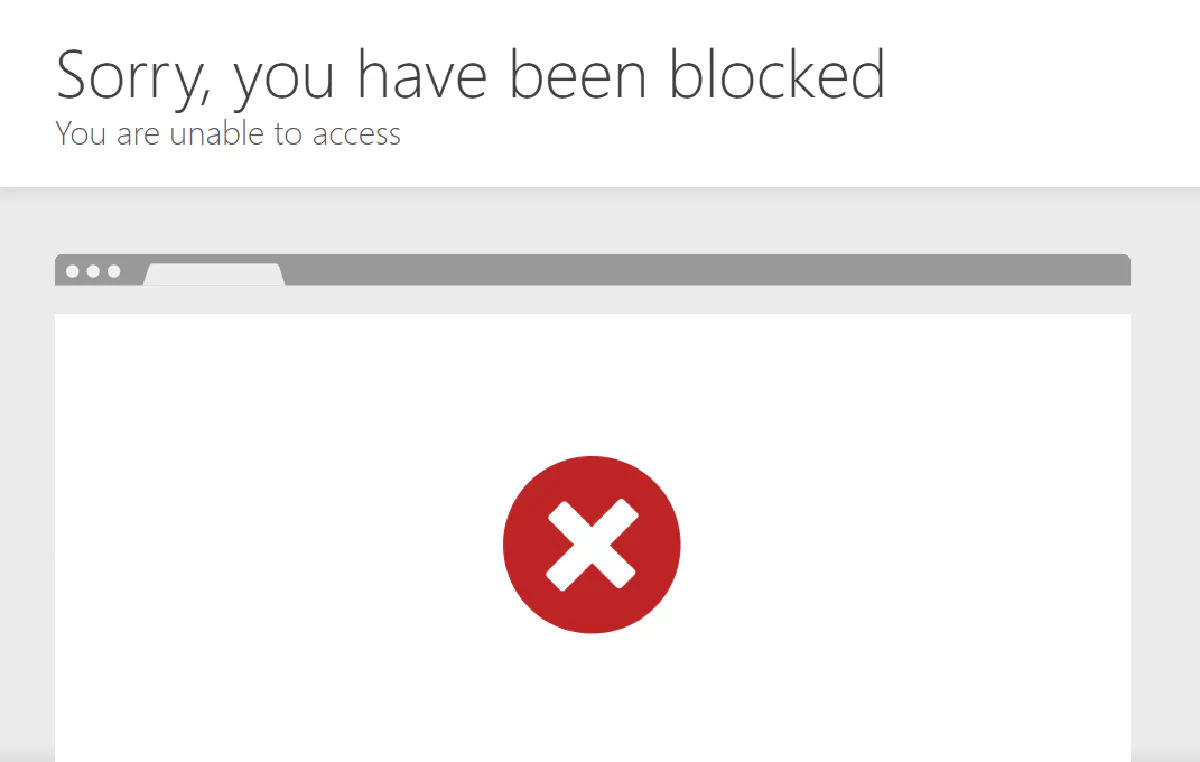
And if your scraper keeps triggering the ban, the timeout window might increase automatically.
From the outside, it feels like a sudden drop-off: one moment your scraper works fine; the next, everything returns 403s. That’s usually a temporary ban kicking in.
Permanent Bans
Permanent bans are a last resort, and they’re serious. A site might blacklist your IP address, account, or entire proxy subnet. These bans don’t lift on their own.
They usually happen when you repeatedly violate scraping policies, ignore rate limits, or try to bypass anti-bot systems aggressively.
Once enforced, every request is blocked no matter how slow, well-formed, or spaced out.
At that point, the only solution is to switch your IP, rotate accounts, or use a more advanced scraping setup.
Common Error Codes and Signs
- HTTP 429 (Too Many Requests): The clearest sign you've hit a rate limit. Back off, wait, and try again later.
- Cloudflare Error 1015 (You Are Being Rate Limited): Typically, this is the content displayed with the error above with response rate 429.
- HTTP 403 (Forbidden): Often indicates a ban. If you're accessing a public page and still get this, your IP or session is likely flagged.
- HTTP 503 (Service Unavailable): Can be used to temporarily reject traffic or challenge bots. Common with Cloudflare protections.
- CAPTCHA pages (HTTP 200 with a challenge): A soft block; you're being asked to prove you're human. Usually triggered after crossing a certain request volume.
- Sudden timeout or blank responses: Not always an error code, but if everything was working and now it’s not, a silent block or temporary ban might be in place.
5 Ways to Bypass Rate Limits
Rate limits are there to slow you down, not stop you. But if you know how they work, you can stay under the radar and keep scraping without issues.
Here are 5 effective ways to avoid getting blocked:
1. Rotate IP Addresses
Most websites track requests by IP.
If one IP sends too many, it gets rate-limited or blocked.
The fix is simple: use a pool of proxies and rotate between them. Each proxy handles a small number of requests, so none of them get flagged.
Here's a code where I grabbed a few free proxies from a free proxy list and sent a request to a demo rate limiting site that tracks IP requests:
import requests
from bs4 import BeautifulSoup
URL = "https://scrapingtest.com/cloudflare-rate-limit"
# Proxy pool
proxies = [
{'http': 'http://14.239.189.250:8080', 'https': 'http://14.239.189.250:8080'},
{'http': 'http://103.127.252.57:3128', 'https': 'http://103.127.252.57:3128'},
{'http': 'http://59.29.182.162:8888', 'https': 'http://59.29.182.162:8888'},
{'http': 'http://77.238.103.98:8080', 'https': 'http://77.238.103.98:8080'}
]
for i in range(10):
print(f"--- Request {i + 1} ---")
# Rotate through proxies
current_proxy = proxies[i % len(proxies)]
print(f"Using proxy: {current_proxy['http']}")
try:
response = requests.get(URL, proxies=current_proxy, timeout=10)
soup = BeautifulSoup(response.content, 'html.parser')
# Extract response indicators
h1 = soup.find('h1')
h2 = soup.find('h2')
print(f"H1: {h1.get_text(strip=True)}")
print(f"H2: {h2.get_text(strip=True)}")
except Exception as e:
print(f"Request failed: {e}")With a small proxy pool, we're able to get full clearance.
Use more proxies for larger jobs. Or plug into a cheap rotating proxy API that rotates IPs for you. If you're also hitting 403 errors, that's a different issue—check your headers.
2. Rotate User-Agents
Some websites also check your User-Agent to see what kind of browser is making the request.
If it says “Python/3.x” or always shows the same browser version, you’ll get flagged.
Rotate your User-Agent string to look like real users from different devices.
import requests
import random
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/122.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Version/15.1 Safari/605.1.15",
"Mozilla/5.0 (Linux; Android 10) AppleWebKit/537.36 Chrome/119.0.0.0 Mobile Safari/537.36"
]
headers = {
"User-Agent": random.choice(user_agents)
}
url = "https://example.com"
response = requests.get(url, headers=headers)
print(response.status_code)You don’t need dozens. Three to five solid, up-to-date User-Agents is usually enough.
3. Add Random Delays
Bots are fast.
Humans are not.
If your scraper hits a website with perfect timing between requests, you’ll stand out.
Add a short, random delay between each request to look more human. Here's a working code that uses random delays:
import requests
from bs4 import BeautifulSoup
import time
import random
URL = "https://scrapingtest.com/cloudflare-rate-limit"
for i in range(10):
print(f"--- Request {i + 1} ---")
response = requests.get(URL)
soup = BeautifulSoup(response.content, 'html.parser')
h1 = soup.find('h1')
h2 = soup.find('h2')
print(f"H1: {h1.get_text(strip=True) if h1 else 'Not Found'}")
print(f"H2: {h2.get_text(strip=True) if h2 else 'Not Found'}")
if i < 9: # Don't sleep after the last request
sleep_time = random.uniform(8, 14)
print(f"Sleeping for {sleep_time:.1f} seconds...")
time.sleep(sleep_time)This script gets 10 back-to-back successful requests without getting rate limited.
You can also increase the delay if you start getting 429s. This is often enough to avoid rate limits entirely.
4. Keep IP and Headers Consistent
If your IP address and headers don’t match, you can get flagged fast.
For example, if you rotate through 20 proxies but always send the exact same User-Agent, it doesn’t make sense. Real users on different networks don’t all use the same browser version.
Same goes the other way: if your User-Agent says “Safari on macOS” but your IP geolocates to a mobile carrier in Brazil, that’s suspicious too.
To avoid this, group your headers and proxies logically. A mobile IP should send a mobile User-Agent. A European IP should probably use headers in a European language. Small mismatches add up, and that’s how rate limiters spot bots.
5. Distribute Requests Across Multiple Environments
Instead of running one scraper fast, run several slower ones in parallel each with its own session, headers, and IP.
You can do this across threads, machines, or serverless functions.
Each one stays under the limit, but together they cover more ground, fast.
One Line to Bypass Everything
Scraping at scale means dealing with rate limits, and more.
WAFs and anti-bot measures do everything in their power to protect websites against bots, so you'll eventually run into blocks.
Or you won't, if you're using Scrape.do. 🔑
Scrape.do handles rate limits and everything else for you, in two simple steps:
1. Sign-up to Scrape.do for FREE and get your API token:
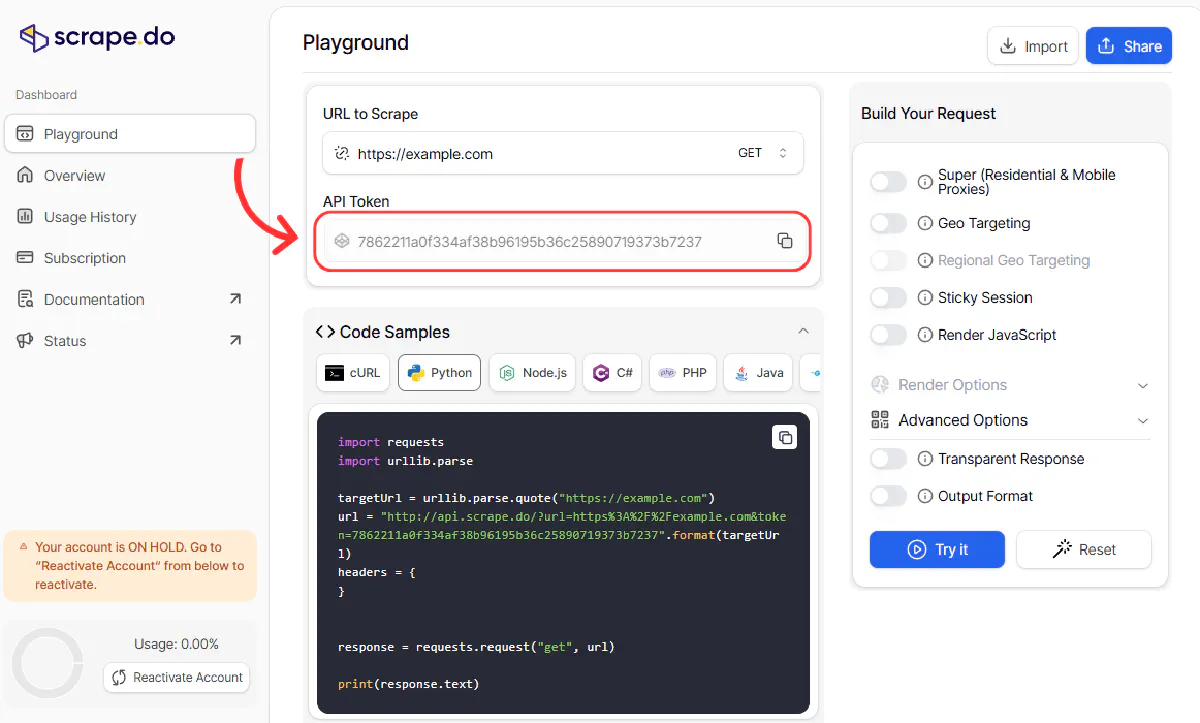
2. Send 10, 100, or 1000 requests to a site and never get blocked, again:
import requests
import urllib.parse
from bs4 import BeautifulSoup
token = "<your-token>"
target_url = "https://scrapingtest.com/cloudflare-rate-limit"
encoded_url = urllib.parse.quote(target_url)
for i in range(10):
print(f"--- Request {i + 1} ---")
url = f"http://api.scrape.do/?url={encoded_url}&token={token}"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
h1 = soup.find('h1')
h2 = soup.find('h2')
print(f"H1: {h1.get_text(strip=True) if h1 else 'Not Found'}")
print(f"H2: {h2.get_text(strip=True) if h2 else 'Not Found'}")Beautifully working, just like that:
--- Request 1 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:145.223.59.141
--- Request 2 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:185.88.36.172
--- Request 3 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:212.119.43.107
--- Request 4 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:162.220.246.251
--- Request 5 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:31.56.137.182
--- Request 6 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:168.199.247.221
--- Request 7 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:84.33.57.65
--- Request 8 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:193.163.89.210
--- Request 9 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:171.22.249.240
--- Request 10 ---
H1: Cloudflare Rate Limit
H2: ✅ Challenge PassedYour IP:193.151.191.42You just send the request and let Scrape.do take care of the rest:
- Residential proxy rotation
- Smart delays and header spoofing
- Real browser sessions
- CAPTCHA handling
- IP and fingerprint consistency
No blocks, no bans, no wasted time.
Founder @ Scrape.do








