Category:Scraping Use Cases
How to Scrape Food Delivery Data with Python (Basic to Advanced)

Founder @ Scrape.do


Restaurant data drives billion-dollar decisions. DoorDash, Uber Eats, and Zomato process millions of orders daily, adjusting menus, delivery fees, and availability based on demand patterns invisible to casual observers.
If you're tracking competitor menus, analyzing pricing strategies, or building restaurant intelligence tools, you need systematic access to this data.
Food delivery platforms don't make it easy.
Geo-restrictions block non-local traffic. Cloudflare protection monitors request patterns. JavaScript rendering hides menu data. Session requirements force multi-step authentication flows.
But these platforms expose data through predictable patterns once you understand their architecture.
In this guide, we'll extract restaurant listings and complete menus from platforms with different complexity levels, handle platform-specific obstacles, and build production-ready scrapers.
Find all working code in this GitHub repository ⚙
Why Scrape Food Delivery Data?
Restaurant data reveals market dynamics that surface-level browsing misses entirely.
Competitive Intelligence
Restaurants adjust menus constantly. New items appear. Prices shift. Descriptions change. Promotional campaigns run for hours, not days.
Automated scraping captures these changes as they happen. Track when competitors launch new dishes, how they price seasonal items, and which menu sections they promote during peak hours.
This data feeds into competitive positioning. If three nearby restaurants drop breakfast prices on Tuesdays, that's a pricing signal worth investigating.
Market Research
Aggregated menu data shows cuisine trends before they saturate. When birria tacos appear on 40% of Mexican restaurants in a city within three months, that's demand acceleration.
Pricing patterns vary by region. The same burger costs $12 in Manhattan and $8 in Atlanta. Delivery fees double in low-density suburbs. Understanding these variations matters for expansion planning and pricing strategy.
Price Monitoring and Dynamic Analysis
Food delivery platforms use dynamic pricing. Delivery fees surge during storms. Popular items get priority placement. Discounts target specific customer segments.
Scraping lets you track these changes across time windows and geographic regions. Build datasets that show how prices fluctuate by day of week, time of day, and weather conditions.
Availability Tracking
Restaurant hours change. Items sell out. Delivery zones expand and contract based on driver availability.
Real-time availability tracking reveals operational patterns. Restaurants that frequently run out of popular items have supply chain issues. Delivery zones that shrink on weekends signal driver shortages.
Understanding Food Delivery Platform Architecture
Food delivery platforms handle location data in fundamentally different ways. Understanding these differences determines your scraping approach.
Region-based platforms like HungerStation and Zomato organize restaurants by predetermined locations—cities, neighborhoods, districts. You browse by selecting from a list of standard regions. Simpler to scrape because locations are static and predictable.
Dynamic location platforms like Uber Eats encode your exact address directly in the URL. More flexible but requires understanding how they encode latitude, longitude, and place identifiers into request parameters.
Session-based platforms like DoorDash require backend registration before showing any data. You can't just visit a URL and see restaurants. You must submit an address through their API, receive a session token, and attach that token to subsequent requests.
We'll tackle each type in increasing order of complexity.
Setup and Prerequisites
You don't need advanced development experience, but understanding HTTP requests, HTML structure, and JSON parsing will accelerate your progress.
Install Required Libraries
Install Python dependencies:
pip install requests beautifulsoup4requests handles HTTP communication with food delivery platforms.
beautifulsoup4 parses HTML content and extracts specific elements.
json (built-in) processes API responses and embedded data structures.
csv (built-in) exports structured data for analysis.
Get Your Scrape.do API Token
Food delivery platforms deploy multiple defense layers:
- Cloudflare protection analyzes TLS fingerprints and header patterns
- JavaScript rendering hides data until client-side code executes
- Geo-restrictions block requests from wrong countries
- Rate limiting triggers after rapid-fire requests
Scrape.do handles all of these automatically. It routes requests through premium residential proxies, executes JavaScript when needed, and maintains sticky sessions for multi-step workflows.
Sign up for Scrape.do and grab your API token:

This token authenticates every request. Parameters like super=true enable premium features. geoCode= sets geographic routing. render=true executes JavaScript.
Choose Your Data Storage Strategy
Storage requirements scale with ambition.
For exploration and testing, save to .json files or export to .csv spreadsheets.
For production systems, use databases:
- SQLite: Single-file database, perfect for local applications
- PostgreSQL: Full SQL support for complex queries and relationships
- MongoDB: Schema-less storage for nested menu structures
For analytics at scale, pipe data into Pandas for transformation or BigQuery for warehousing.
For automation, schedule scrapers with cron jobs, Apache Airflow, or AWS Lambda.
Think about storage before you scrape thousands of restaurants. Retrofitting storage logic later costs time.
Scraping Restaurant Listings: Three Complexity Levels
Level 1: Region-Based Platforms (HungerStation)
HungerStation dominates food delivery in Saudi Arabia. It organizes restaurants by city and neighborhood, making location handling straightforward.
But accessing HungerStation from outside Saudi Arabia is nearly impossible.
From heavy geo-blocking to aggressive Cloudflare defenses, most bots fail before they load a single menu.
The Geographic Barrier
HungerStation blocks all non-Saudi Arabia traffic. Even premium datacenter proxies get rejected immediately.
Unless you're browsing from a Saudi Arabian IP address, you can't view local restaurants or even load their menus.
This is what happens when you try to view restaurants without the right IP:
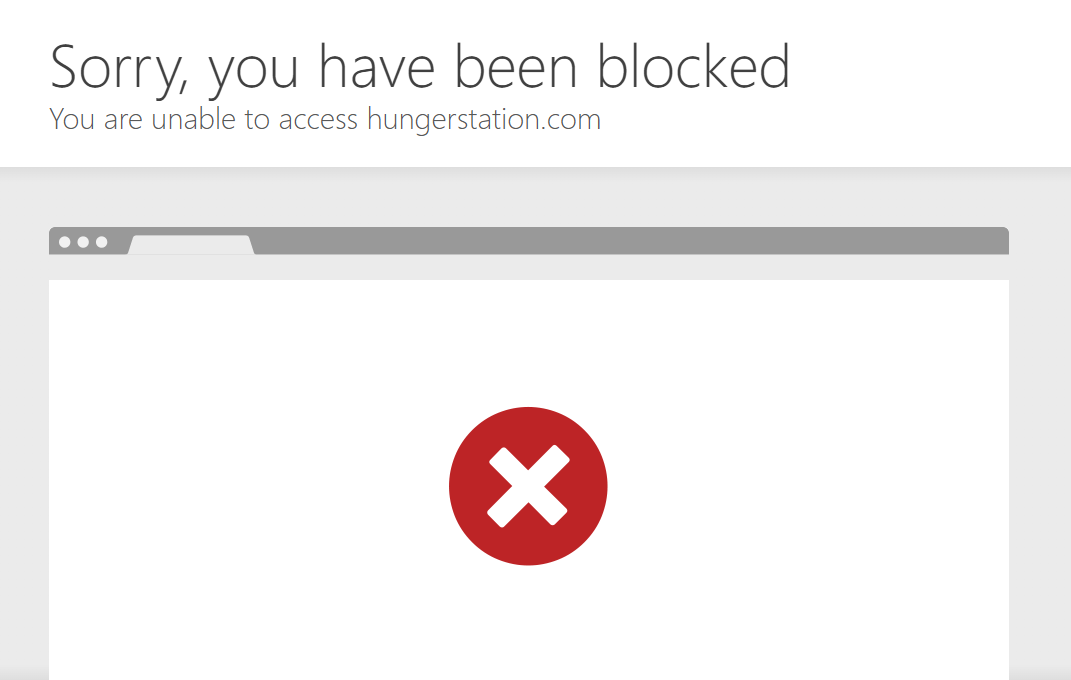
Basic proxy rotation doesn't work. Without premium Saudi IPs, you're not even accessing the site, let alone scraping it.
Cloudflare Rate Limiting
Even if you're connecting from inside Saudi Arabia, HungerStation still won't make it easy.
It uses Cloudflare to monitor how fast you're navigating even when you're just browsing manually.
Open a few pages too quickly and you'll hit a rate limit or get temporarily blocked.
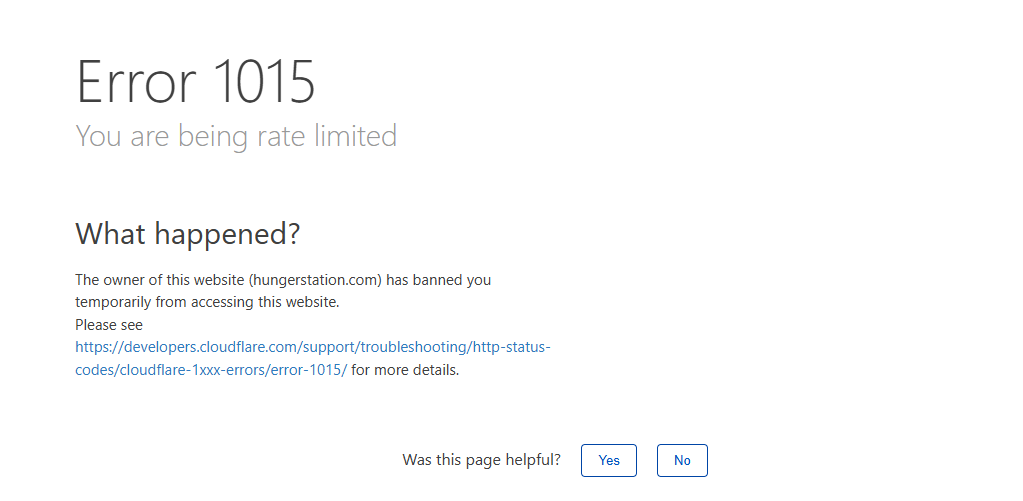
These rate limits reset in a few minutes, but when you're scraping, you'll trigger them constantly unless you handle sessions, headers, and request pacing correctly.
Setup and Configuration
You'll use three libraries:
pip install requests beautifulsoup4We'll use:
requeststo send HTTP requests through Scrape.doBeautifulSoupto parse the HTML contentcsvto store the scraped data in a structured format
You'll also need your Scrape.do API token.
Just head over to your Scrape.do Dashboard, and you'll find it right at the top.
We'll use this token in every request to route our scraping through Scrape.do's Saudi Arabia proxies, bypassing both geo-restrictions and Cloudflare protection.
Building the Request
Before we start scraping restaurant data, we need to make sure our request goes through and doesn't get blocked or redirected.
We'll send our first request using Scrape.do, which handles proxy routing, session headers, and geo-targeting for us. All we care about is whether we get a clean 200 OK response.
import requests
import urllib.parse
# Your Scrape.do token
TOKEN = "<your-token>"
# Target URL (first page of Al Jisr, Al Khobar restaurants)
target_url = "https://hungerstation.com/sa-en/restaurants/al-khobar/al-jisr"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geoCode=sa&super=true"
response = requests.get(api_url)
print(response)If everything is working correctly, you should see:
<Response [200]>This means the request reached the real content, geo-restrictions and Cloudflare both bypassed.
If you see anything else (like <Response [403]> or a redirect page), double-check:
geoCode=sais present (to force a Saudi IP)super=trueis used (for premium proxy and header rotation)- Your token is valid and active
Now that we've confirmed access, we can start extracting restaurant data.
Parse Restaurant Information
If you inspect the page structure, each restaurant is listed inside an <li> element. Inside that, you'll find:
h1.text-base→ store namea[href]→ link to the storep→ category (e.g., Pizza, Burger)span→ review rating
Here's how we parse those details using BeautifulSoup:
from bs4 import BeautifulSoup
# ... same request code from previous step ...
soup = BeautifulSoup(response.text, "html.parser")
restaurants = []
for li in soup.select("ul > li"):
name_tag = li.find("h1", class_="text-base text-typography font-medium")
if not name_tag:
continue # skip non-restaurant items
store_name = name_tag.get_text(strip=True)
a = li.find("a", href=True)
store_link = "https://hungerstation.com" + a["href"] if a else ""
category_tag = li.find("p")
category = category_tag.get_text(strip=True) if category_tag else ""
rating_tag = li.find("span")
review_rating = rating_tag.get_text(strip=True) if rating_tag else ""
restaurants.append({
"store_link": store_link,
"store_name": store_name,
"category": category,
"review_rating": review_rating
})
print(restaurants)You should get a list of dictionaries with the 12 restaurants listed on the first page, but we need all of it.
Loop Through All Pages
HungerStation paginates its restaurant listings, so to get the full dataset, we'll need to crawl through all pages until there are no more results.
Each page URL follows the same pattern:
https://hungerstation.com/sa-en/restaurants/al-khobar/al-jisr?page=2We'll modify our code to:
- Add
?page=to the base URL - Keep requesting pages until we stop finding valid restaurant entries
Here's the complete code with pagination and CSV export:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Your Scrape.do token
TOKEN = "<your-token>"
BASE_URL = "https://hungerstation.com/sa-en/restaurants/al-khobar/al-jisr"
API_URL_BASE = f"https://api.scrape.do/?token={TOKEN}&geoCode=sa&super=true&url="
restaurants = []
page = 1
while True:
url = f"{BASE_URL}?page={page}"
encoded_url = urllib.parse.quote_plus(url)
api_url = API_URL_BASE + encoded_url
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
found = False
for li in soup.select("ul > li"):
name_tag = li.find("h1", class_="text-base text-typography font-medium")
if not name_tag:
continue
found = True
a = li.find("a", href=True)
store_link = "https://hungerstation.com" + a["href"] if a else ""
store_name = name_tag.get_text(strip=True)
category_tag = li.find("p")
category = category_tag.get_text(strip=True) if category_tag else ""
rating_tag = li.find("span")
review_rating = rating_tag.get_text(strip=True) if rating_tag else ""
restaurants.append({
"store_link": store_link,
"store_name": store_name,
"category": category,
"review_rating": review_rating
})
if not found:
break
print(f"Extracted page {page}")
page += 1
# Write to CSV
with open("hungerstation_restaurants.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["store_link", "store_name", "category", "review_rating"])
writer.writeheader()
writer.writerows(restaurants)
print(f"Extracted {len(restaurants)} restaurants to hungerstation_restaurants.csv")This will output a file named hungerstation_restaurants.csv containing all scraped listings.
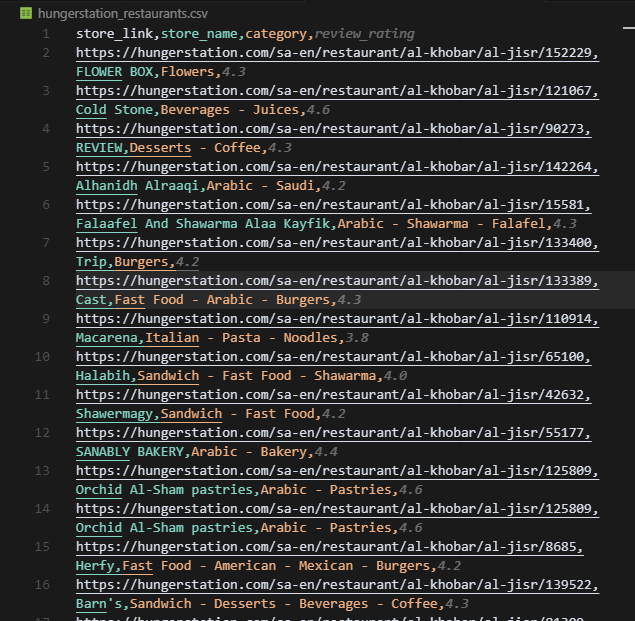
HungerStation makes region-based scraping manageable once you handle geo-restrictions properly. The address lives in the URL path, not in complex session state.
Level 2: Dynamic URL-Based Location (Uber Eats)
Uber Eats takes a different approach. Instead of organizing by predetermined regions, it encodes your exact address directly into the URL.
When you select a delivery address, Uber Eats encodes that location into the pl= parameter:
https://www.ubereats.com/feed?diningMode=DELIVERY&pl=JTdCJTIyYWRkcmVzcyUyMiUzQSUyMkNlbnRyYWwlMjBQYXJrJTIy...That pl value is a base64-encoded JSON object containing your address, latitude, longitude, and Google Maps place ID.
To scrape a different location, enter a new address on Uber Eats, refresh the page, copy the updated URL with the new pl value, and use it in your script.
No session management. No cookies. No backend calls.
But Uber Eats relies on JavaScript rendering. The page won't show anything useful until client-side code executes and populates the DOM with restaurant data.
This is what you get with a simple HTTP request:
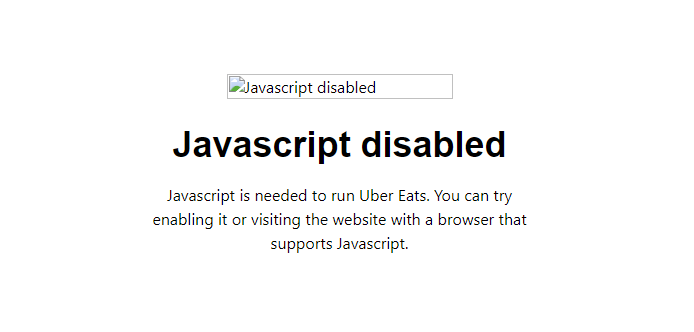
Open any restaurant page with requests and you'll hit a blank screen asking you to turn on JS.
Uber Eats relies on dynamic rendering, session-bound APIs, and frontend GraphQL endpoints that don't respond unless you're behaving like a real browser.
The setup is exactly the same as any other frontend scraping task, but we need JavaScript execution.
We'll send a request to a JavaScript-heavy, location-specific Uber Eats feed URL, render it using Scrape.do's headless browser, and extract restaurant/store cards directly from the HTML.
Then, we'll teach Scrape.do to automatically click "Show more" so we can get the full list of results.
Uber Eats shows the first ~100 results on first load and then adds more only when you click the "Show more" button.
To collect the full list, we use Scrape.do's playWithBrowser feature to automate that button click repeatedly.
Here's the full code:
import requests
import urllib.parse
import csv
import json
from bs4 import BeautifulSoup
# Scrape.do token
scrape_token = "<your-token>"
# Target UberEats feed URL (Central Park, NY)
ubereats_url = "https://www.ubereats.com/feed?diningMode=DELIVERY&pl=JTdCJTIyYWRkcmVzcyUyMiUzQSUyMkNlbnRyYWwlMjBQYXJrJTIyJTJDJTIycmVmZXJlbmNlJTIyJTNBJTIyQ2hJSjR6R0ZBWnBZd29rUkdVR3BoM01mMzdrJTIyJTJDJTIycmVmZXJlbmNlVHlwZSUyMiUzQSUyMmdvb2dsZV9wbGFjZXMlMjIlMkMlMjJsYXRpdHVkZSUyMiUzQTQwLjc4MjU1NDclMkMlMjJsb25naXR1ZGUlMjIlM0EtNzMuOTY1NTgzNCU3RA=="
# Browser automation sequence for scrape.do (clicks 'Show more' repeatedly)
play_with_browser = [
{"action": "WaitSelector", "timeout": 30000, "waitSelector": "button, div, span"},
{"action": "Execute", "execute": "(async()=>{let attempts=0;while(attempts<20){let btn=Array.from(document.querySelectorAll('button, div, span')).filter(e=>e.textContent.trim()==='Show more')[0];if(!btn)break;btn.scrollIntoView({behavior:'smooth'});btn.click();await new Promise(r=>setTimeout(r,1800));window.scrollTo(0,document.body.scrollHeight);await new Promise(r=>setTimeout(r,1200));attempts++;}})();"},
{"action": "Wait", "timeout": 3000}
]
# Prepare scrape.do API URL
jsonData = urllib.parse.quote_plus(json.dumps(play_with_browser))
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(ubereats_url)}"
f"&token={scrape_token}"
f"&super=true"
f"&render=true"
f"&playWithBrowser={jsonData}"
)
# Fetch the rendered UberEats page
response = requests.get(api_url)
# Parse the HTML with BeautifulSoup directly from response.text
soup = BeautifulSoup(response.text, "html.parser")
store_cards = soup.find_all('div', {'data-testid': 'store-card'})
# Helper to get first text from selectors
def get_first_text(element, selectors):
for sel in selectors:
found = element.select_one(sel)
if found and found.get_text(strip=True):
return found.get_text(strip=True)
return ''
# Extract store data
results = []
for card in store_cards:
a_tag = card.find('a', {'data-testid': 'store-card'})
href = a_tag['href'] if a_tag and a_tag.has_attr('href') else ''
h3 = a_tag.find('h3').get_text(strip=True) if a_tag and a_tag.find('h3') else ''
promo = ''
promo_div = card.select_one('div.ag.mv.mw.al.bh.af')
if not promo_div:
promo_div = card.find('span', {'data-baseweb': 'tag'})
if promo_div:
promo = ' '.join(promo_div.stripped_strings)
rating = get_first_text(card, [
'span.bo.ej.ds.ek.b1',
'span[title][class*=b1]'
])
review_count = ''
for span in card.find_all('span'):
txt = span.get_text(strip=True)
if txt.startswith('(') and txt.endswith(')'):
review_count = txt
break
if not review_count:
review_count = get_first_text(card, [
'span.bo.ej.bq.dt.nq.nr',
'span[class*=nq][class*=nr]'
])
results.append({
'href': href,
'name': h3,
'promotion': promo,
'rating': rating,
'review_count': review_count
})
# Write results to CSV
with open('ubereats_store_cards.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['href', 'name', 'promotion', 'rating', 'review_count']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in results:
writer.writerow(row)
print(f"Wrote {len(results)} store cards to ubereats_store_cards.csv")When we run this script, the terminal should print:
Wrote 223 store cards to ubereats_store_cards.csvAnd the CSV output looks like this:
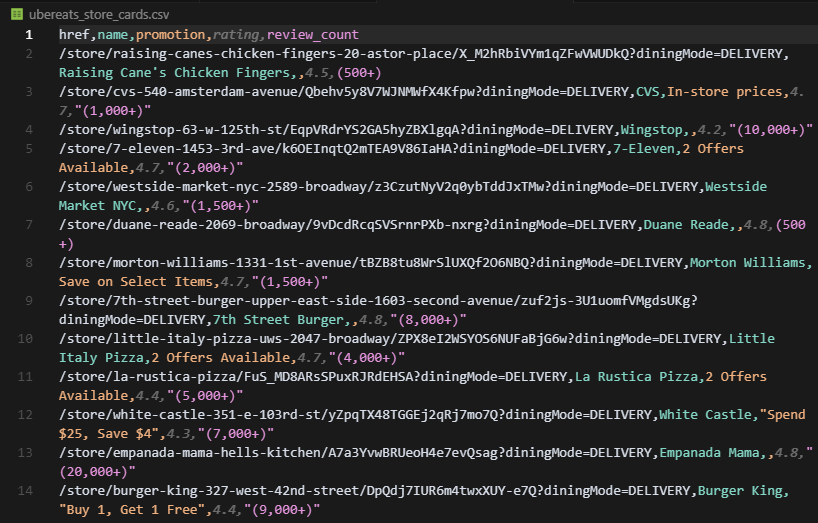
Uber Eats requires JavaScript execution but rewards you with precise location control. Change the address in your browser, copy the new URL, and you're scraping a different delivery zone instantly.
Level 3: Backend Session Registration (DoorDash)
DoorDash requires the most complex setup because address validation happens entirely through backend API calls.
You can't set an address via URL parameters. You must submit it through a GraphQL mutation that registers the address to your session.
When you enter an address on DoorDash, your browser sends a POST request to:
https://www.doordash.com/graphql/addConsumerAddressV2?operation=addConsumerAddressV2This is a POST request which means instead of just fetching data, it's sending data to the server to register your address with your session.
To view and copy the payload:
Right-click and Inspect before visiting the DoorDash homepage or any page of the website. Open the Network tab in the developer tools that pop up and make sure Preserve log option in the top toolbar is checked.
Pick an address (preferably somewhere DoorDash is available in) and then save it.
Now, your browser will send the POST request we just talked about. Once the new page loads, search for addConsumerAddress... from the top toolbar. Here's what you should be able to see:
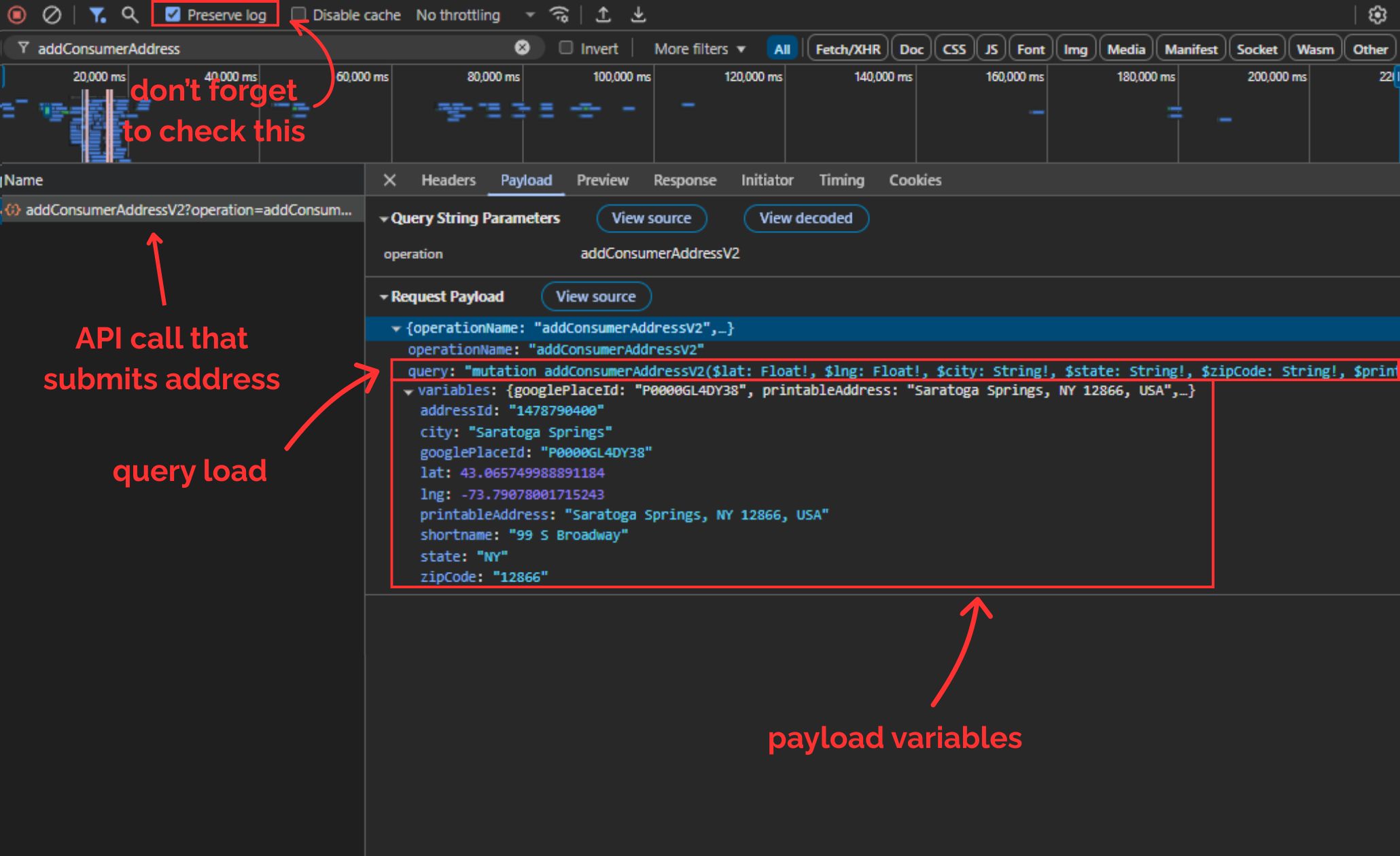
DoorDash uses a system called GraphQL, which always sends two things in the payload:
query: a big string that defines what operation to run (in this case,addConsumerAddressV2)variables: a JSON object containing all the real values (latitude, longitude, city, zip, etc.)
We'll now send the exact same POST request that the browser sends, but from Python.
Here's the full structure:
import requests
import json
# Scrape.do API token and target URL
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/addConsumerAddressV2?operation=addConsumerAddressV2"
# Scrape.do API endpoint
api_url = (
"http://api.scrape.do/?"
f"token={TOKEN}"
f"&super=true"
f"&url={requests.utils.quote(TARGET_URL)}"
)
payload = {
"query": """
mutation addConsumerAddressV2(
$lat: Float!, $lng: Float!, $city: String!, $state: String!, $zipCode: String!,
$printableAddress: String!, $shortname: String!, $googlePlaceId: String!,
$subpremise: String, $driverInstructions: String, $dropoffOptionId: String,
$manualLat: Float, $manualLng: Float, $addressLinkType: AddressLinkType,
$buildingName: String, $entryCode: String, $personalAddressLabel: PersonalAddressLabelInput,
$addressId: String
) {
addConsumerAddressV2(
lat: $lat, lng: $lng, city: $city, state: $state, zipCode: $zipCode,
printableAddress: $printableAddress, shortname: $shortname, googlePlaceId: $googlePlaceId,
subpremise: $subpremise, driverInstructions: $driverInstructions, dropoffOptionId: $dropoffOptionId,
manualLat: $manualLat, manualLng: $manualLng, addressLinkType: $addressLinkType,
buildingName: $buildingName, entryCode: $entryCode, personalAddressLabel: $personalAddressLabel,
addressId: $addressId
) {
defaultAddress {
id
addressId
street
city
subpremise
state
zipCode
country
countryCode
lat
lng
districtId
manualLat
manualLng
timezone
shortname
printableAddress
driverInstructions
buildingName
entryCode
addressLinkType
formattedAddressSegmentedList
formattedAddressSegmentedNonUserEditableFieldsList
__typename
}
availableAddresses {
id
addressId
street
city
subpremise
state
zipCode
country
countryCode
lat
lng
districtId
manualLat
manualLng
timezone
shortname
printableAddress
driverInstructions
buildingName
entryCode
addressLinkType
formattedAddressSegmentedList
formattedAddressSegmentedNonUserEditableFieldsList
__typename
}
id
userId
timezone
firstName
lastName
email
marketId
phoneNumber
defaultCountry
isGuest
scheduledDeliveryTime
__typename
}
}
""",
"variables": {
"googlePlaceId": "D000PIWKXDWA",
"printableAddress": "99 S Broadway, Saratoga Springs, NY 12866, USA",
"lat": 43.065749988891184,
"lng": -73.79078001715243,
"city": "Saratoga Springs",
"state": "NY",
"zipCode": "12866",
"shortname": "National Museum Of Dance",
"addressId": "1472738929",
"subpremise": "",
"driverInstructions": "",
"dropoffOptionId": "2",
"addressLinkType": "ADDRESS_LINK_TYPE_UNSPECIFIED",
"entryCode": ""
}
}
response = requests.post(api_url, data=json.dumps(payload))
scrape_do_rid = response.headers.get("scrape.do-rid")
print(f"scrape.do-rid: {scrape_do_rid}")scrape.do-rid value identifies your session that's created in Scrape.do's cloud, and if the post request was successful this session will have the address we sent through the payload registered, giving us access to DoorDash.
The response should look like this:
scrape.do-rid: 4f699c-40-0-459851;To keep using this session, we only need the last 6 digits (e.g. 459851) and we'll need to carry that forward in every future request.
Now you can scrape store listings for that address by sending requests to DoorDash's homePageFacetFeed endpoint using that session ID.
DoorDash is the most complex platform because it requires backend address submission via GraphQL, session ID extraction and persistence, and cursor-based pagination through API responses.
Scraping Restaurant Menus
Restaurant listings show you what's available in an area. Menus show you what each restaurant actually sells.
Menu extraction varies more than listing extraction. Platforms deliver menu data through different mechanisms: embedded JavaScript objects, rendered HTML, or backend APIs.
Zomato Menus: Parsing Embedded JavaScript State
Zomato embeds complete menu data inside a JavaScript variable called window.__PRELOADED_STATE__. This appears in the initial HTML response, meaning you don't need JavaScript rendering to access it.
Let's start easy.
We'll scrape the menu of this McDonald's franchise in New Delhi for this section.
We'll use Scrape.do to bypass Cloudflare, then parse the embedded JavaScript from the HTML.
Setup
You'll need a few basic Python libraries:
pip install requests beautifulsoup4We'll use:
requeststo send the API call through Scrape.doBeautifulSoupto find the script tag with embedded datajsonto parse the extracted JavaScript object
Next, grab your Scrape.do API token.
Extract the JavaScript State Object
Zomato uses a JavaScript variable named window.__PRELOADED_STATE__ to fill the frontend with embedded JSON. Inside that structure lives everything we care about: menus, categories, item names, images, prices, and more.
Here's how we extract it:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import json
# Your Scrape.do token
token = "<your_token>"
# Target Zomato URL (McDonald's Janpath, New Delhi)
target_url = urllib.parse.quote_plus("https://www.zomato.com/ncr/mcdonalds-janpath-new-delhi/order")
api_url = f"http://api.scrape.do/?token={token}&url={target_url}"
# Fetch and parse
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract the JavaScript state object
script = soup.find("script", string=lambda s: s and "window.__PRELOADED_STATE__" in s)
json_text = script.string.split('JSON.parse("')[1].split('")')[0]
data = json.loads(json_text.encode().decode('unicode_escape'))The data structure contains everything. We need to navigate to the right section.
Extract Restaurant Info and Menu Structure
The menu lives deep in the data structure. Let's extract basic restaurant info first:
restaurant = data["pages"]["restaurant"]["182"]
info = restaurant["sections"]["SECTION_BASIC_INFO"]
contact = restaurant["sections"]["SECTION_RES_CONTACT"]
name = info["name"]
location = contact["address"]
rating_data = info["rating_new"]["ratings"]["DELIVERY"]
rating = rating_data["rating"]
review_count = rating_data["reviewCount"]
print(f"Restaurant: {name}")
print(f"Address : {location}")
print(f"Delivery Rating: {rating} ({review_count} reviews)\n")Now extract the menu items:
menus = restaurant["order"]["menuList"]["menus"]
menu_items = []
for menu in menus:
category = menu["menu"]["name"]
for cat in menu["menu"]["categories"]:
for item in cat["category"]["items"]:
item_name = item["item"]["name"]
item_price = item["item"]["price"]
menu_items.append({
"category": category,
"name": item_name,
"price": f"₹{item_price}"
})
print(f"Found {len(menu_items)} menu items")The result is a fully structured list of every menu item, matched with its category and price:
Restaurant: McDonald's
Address : 42, Atul Grove Road, Janpath, New Delhi
Delivery Rating: 4.3 (9,903 reviews)
What's New. - Veg Supreme McMuffin: ₹102
What's New. - Veg Supreme McMuffin With Beverage: ₹154
...
Happy Meal. - HappyMeal McAloo Tikki Burger®: ₹257
Happy Meal. - HappyMeal Chicken McGrill®: ₹300Clean, hierarchical, and immediately usable.
This structure is stable across Zomato delivery URLs, which means once you get this flow working, you can apply it to any delivery restaurant link.
Uber Eats Menus: JavaScript Rendering Required
Unlike Zomato, Uber Eats won't show you anything unless JavaScript is enabled.
Open any restaurant page with requests and you'll hit a blank screen.
Uber Eats relies on dynamic rendering. Menu data doesn't exist in the initial HTML. It gets injected by JavaScript after the page loads.
Let's start with a simple example.
Once you use a headless browser or Scrape.do's render parameter, all menu items along with their categories and prices are available in the DOM on restaurant pages.
No need to set an address or submit anything through the backend API.
We'll scrape the menu of this Popeyes franchise in Brooklyn for this section.
Setup
You'll need:
pip install requests beautifulsoup4We'll use:
requeststo send the API call through Scrape.doBeautifulSoupto parse the rendered HTML and extract the menucsvto save the output in a clean, structured format
Next, grab your Scrape.do API token.
You'll use this token to authenticate every request. The super=true and render=true parameters will make sure we bypass anti-bot checks and render JavaScript.
Build the Request with Rendering
Uber Eats won't return any useful content unless JavaScript is rendered and some wait time is allowed for dynamic elements to load.
Here's how we build the request:
import requests
import urllib.parse
scrape_token = "<your-token>"
ubereats_restaurant_url = "https://www.ubereats.com/store/popeyes-east-harlem/H6RO8zvyQ1CxgJ7VH350pA?diningMode=DELIVERY"
api_url = (
f"https://api.scrape.do/?url={urllib.parse.quote_plus(ubereats_restaurant_url)}"
f"&token={scrape_token}"
f"&super=true"
f"&render=true"
f"&customWait=5000"
)
response = requests.get(api_url)Let's break that down:
url: the Uber Eats restaurant page you want to scrapetoken: your Scrape.do API keysuper=true: enables premium proxy and header rotation (required to bypass Uber's bot filters)render=true: turns on headless browser rendering to load JavaScriptcustomWait=5000: waits 5 seconds after page load to make sure the menu is rendered in full
At this point, response.text contains the fully rendered HTML of the restaurant page.
Extract Menu Items
Once we have the rendered HTML, we can parse it like any other static page using BeautifulSoup:
from bs4 import BeautifulSoup
import csv
soup = BeautifulSoup(response.text, "html.parser")
results = []
for section in soup.find_all('div', {'data-testid': 'store-catalog-section-vertical-grid'}):
cat_h3 = section.find('h3')
category = cat_h3.get_text(strip=True) if cat_h3 else ''
for item in section.find_all('li', {'data-testid': True}):
if not item['data-testid'].startswith('store-item-'):
continue
rich_texts = item.find_all('span', {'data-testid': 'rich-text'})
if len(rich_texts) < 2:
continue
name = rich_texts[0].get_text(strip=True)
price = rich_texts[1].get_text(strip=True)
results.append({
'category': category,
'name': name,
'price': price
})
# Write results to CSV
with open('ubereats_restaurant_menu.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['category', 'name', 'price']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in results:
writer.writerow(row)
print(f"Wrote {len(results)} menu items to ubereats_restaurant_menu.csv")And here's what this will print in the terminal:
Wrote 56 menu items to ubereats_restaurant_menu.csvFinally, this is what your CSV file will look like:
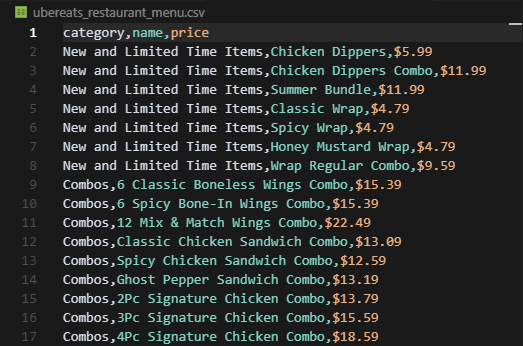
This code will only apply to restaurants that have no more than a few hundred items in their menu. For chain stores, we'll need a different approach.
DoorDash: Extracting from Embedded Next.js Data
DoorDash uses a JavaScript variable named self.__next_f.push(...) to fill the frontend with embedded JSON. Inside that structure lives everything we care about; menus, categories, item names, images, prices, and more.
Unlike Zomato (which has one clear variable) or Uber Eats (which requires rendering), DoorDash embeds data in multiple push calls that you need to parse manually.
We locate that script with:
import requests
import re
import csv
import json
from bs4 import BeautifulSoup
TOKEN = "<your-token>"
STORE_URL = "https://www.doordash.com/store/denny's-saratoga-springs-800933/28870947/"
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={STORE_URL}"
response = requests.get(API_URL)
soup = BeautifulSoup(response.text, 'html.parser')
menu_script = next(
script.string for script in soup.find_all('script')
if script.string and 'self.__next_f.push' in script.string and 'itemLists' in script.string
)We then extract the raw embedded string using a regex:
embedded_str = re.search(
r'self\.__next_f\.push\(\[1,"(.*?)"\]\)',
menu_script,
re.DOTALL
).group(1).encode('utf-8').decode('unicode_escape')This gives us a huge string of JSON-like content, but not in a form we can parse directly.
So we manually locate the "itemLists" array inside that string by finding where it starts with [ and where the matching ] ends:
start_idx = embedded_str.find('"itemLists":')
array_start = embedded_str.find('[', start_idx)
bracket_count = 0
for i in range(array_start, len(embedded_str)):
if embedded_str[i] == '[':
bracket_count += 1
elif embedded_str[i] == ']':
bracket_count -= 1
if bracket_count == 0:
array_end = i + 1
break
itemlists_json = embedded_str[array_start:array_end].replace('\\u0026', '&')
itemlists = json.loads(itemlists_json)Now we've got a proper list of categories, each with a list of menu items.
Let's loop through them and collect everything:
all_items = []
for category in itemlists:
for item in category.get('items', []):
name = item.get('name')
desc = item.get('description', '').strip() or None
price = item.get('displayPrice')
img = item.get('imageUrl')
rating = review_count = None
rds = item.get('ratingDisplayString')
if rds:
m2 = re.match(r'(\d+)%\s*\((\d+)\)', rds)
if m2:
rating = int(m2.group(1))
review_count = int(m2.group(2))
all_items.append({
'name': name,
'description': desc,
'price': price,
'rating_%': rating,
'review_count': review_count,
'image_url': img
})
with open('menu_items.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile,
fieldnames=['name','description','price','rating_%','review_count','image_url'])
writer.writeheader()
writer.writerows(all_items)
print(f"Extracted {len(all_items)} items to menu_items.csv")And here's what your output should look like:
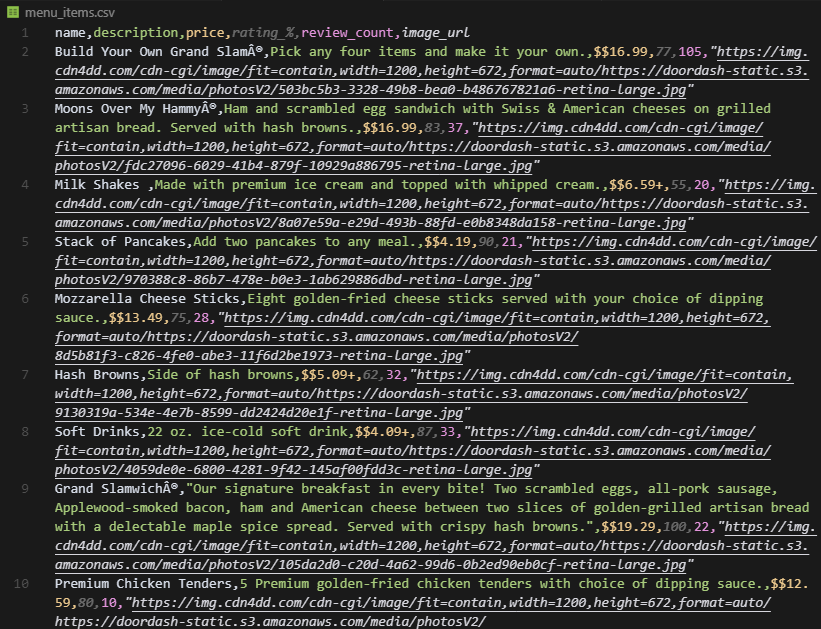
DoorDash's approach requires more manual parsing, but the data structure is consistent once you understand the pattern.
Conclusion
Food delivery platforms vary wildly in complexity—from simple region-based browsing (HungerStation) to dynamic URL encoding (Uber Eats) to full session management (DoorDash).
Menu data extraction also differs: static HTML with embedded JavaScript (Zomato) vs dynamic client-side rendering (Uber Eats) vs Next.js embedded data (DoorDash).
But the underlying pattern remains consistent: understand how the platform delivers data, replicate the requests, parse the responses, and handle platform-specific quirks.
With Scrape.do handling Cloudflare protection, JavaScript rendering, geo-restrictions, and session management, you can focus entirely on extracting and analyzing the data that matters.
Whether you're monitoring competitor menus, analyzing cuisine trends, or building restaurant aggregation tools, you now have the complete toolkit to scrape any food delivery platform.
Founder @ Scrape.do








