Category:Scraping Use Cases
How to Scrape Complete Grocery Data from Walmart with Python

Full Stack Developer



Walmart runs America's largest grocery operation, but getting structured data from their platform is a nightmare.
The moment your scraper hits their servers, you're facing a dual-firewall setup: Akamai analyzing your TLS fingerprint while HUMAN (PerimeterX) watches for bot behavior patterns.
Survive both, and Walmart still won't show you real prices until you select a specific store location which affects discounts and stock availability.
In this guide, we'll show you how to extract clean, structured data from Walmart's product pages, variant listings, and category feeds without getting blocked.
Get fully functioning code from our GitHub repo ⚙
Why Scraping Walmart Is Brutally Difficult
Walmart isn't like scraping a basic storefront.
It's built with layered defenses that punish bots the second they identify one.
Akamai AND PerimeterX (HUMAN) Protection
Most retailers pick one major anti-bot vendor.
Walmart runs both: Akamai as a web application firewall and PerimeterX (HUMAN) as a behavioral defense layer.
That combination is rare and extremely difficult to bypass.
Akamai inspects every request at the TLS and header level. If your fingerprint doesn't look like a real browser, you'll be dropped with a hard block or pushed into endless redirects.
On top of that, PerimeterX waits in the background and forces a CAPTCHA challenge once it detects automation patterns:

Address / Store Selection
Even if you get through both defenses, Walmart still doesn't give you usable data.
Prices and stock are store-specific. A gallon of milk might be $3.98 in one store, $4.29 in another, and completely unavailable in a third.
When you first land, Walmart forces you to select a store. That choice is locked into cookies and carried through the rest of your session.
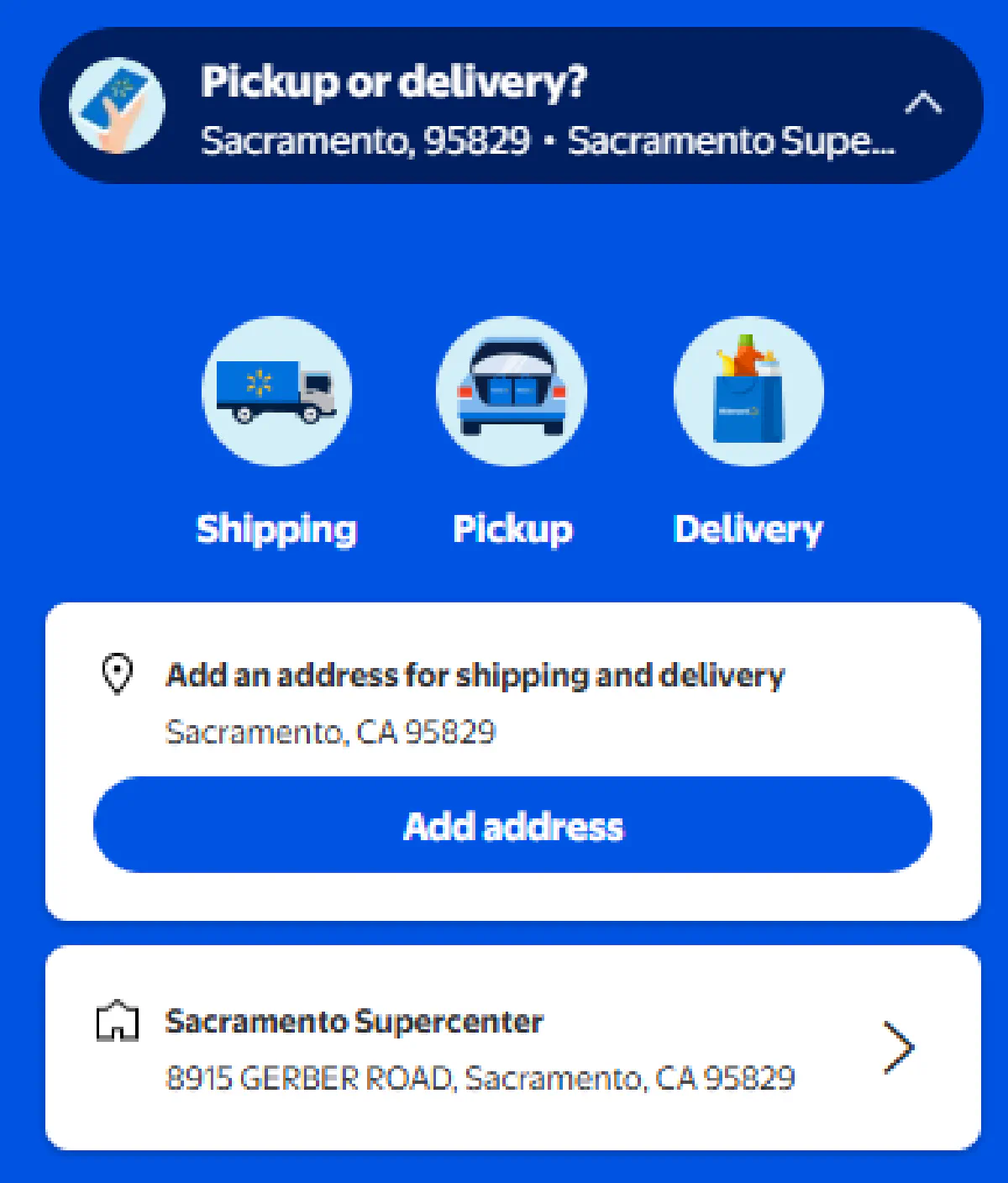
Without it, every product page you scrape will either be incomplete or misleading.
How Scrape.do Solves These
Walmart's defenses require more than headers or proxies. You need a solution that:
- Passes Akamai's TLS and header fingerprinting
- Handles HUMAN CAPTCHA challenges automatically
- Preserves cookies so a store selection sticks to your session
- Renders JavaScript for product details and dynamic pricing
- Supports referer headers for realistic pagination
Sounds too good to be in just one solution, right?
But it's real. Scrape.do provides all of these in one request layer.
By using parameters like super=true (browser fingerprinting), render=true (JavaScript rendering), and extraHeaders=true (custom cookies and referers), the scraper behaves like a real customer session tied to a valid store.
⭐ Even better: Scrape.do just launched a free Walmart plugin that handles store selection automatically. Instead of manually extracting cookies, you can simply pass a zip code and store ID to lock your session to any Walmart location instantly.
Setting Up an Address
Walmart doesn't return correct prices or stock data until your session is tied to a store. That tie happens through cookies.
We'll explore two different methods to handle store selection:
Method 1: Manual Cookie Extraction
When you pick a store in the browser, Walmart sets several cookies on your session.
Three are essential:
- ACID
- locDataV3
- locGuestData
Without these, product pages fall back to default data or show incomplete inventory.
Finding the Cookies in Your Browser
Open Walmart in Chrome, select a store from the top menu, then open Developer Tools → Application → Storage → Cookies. You'll see all active cookies for walmart.com.
The three we care about are highlighted here:
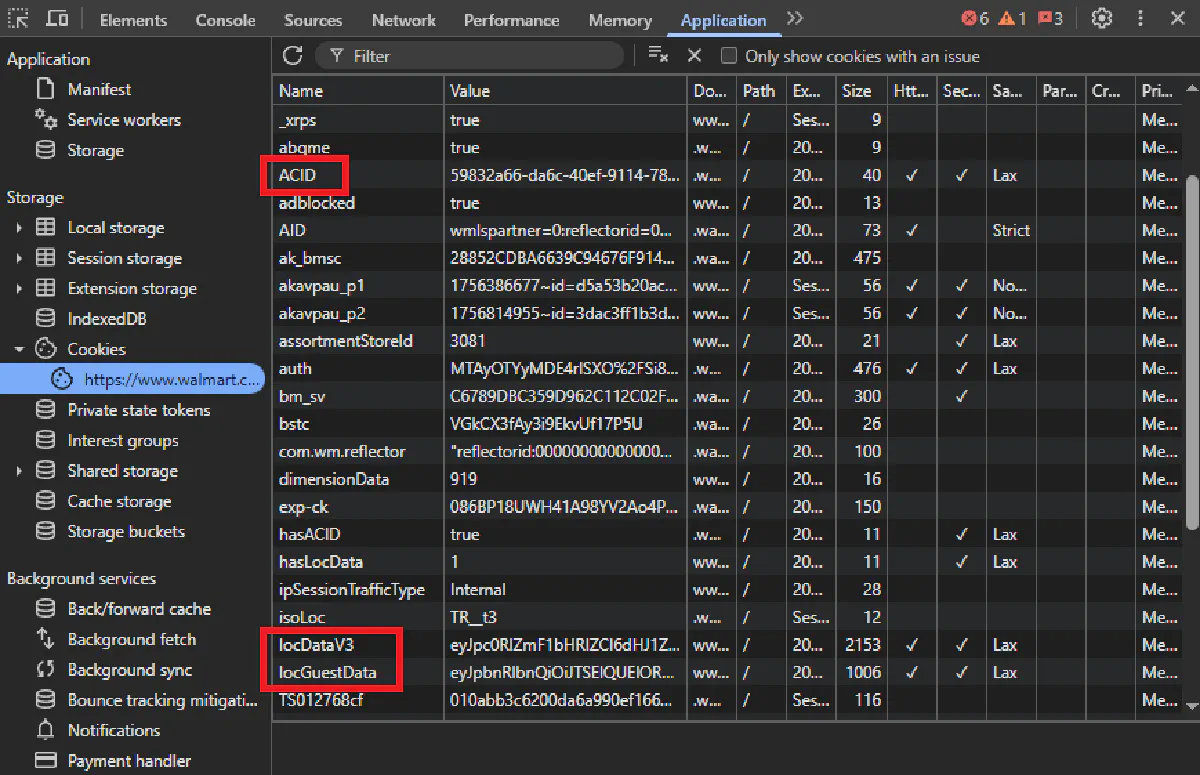
Each cookie has a long opaque value. Copy them exactly as-is, no spaces or line breaks.
Using Cookies in Requests
We'll send them via the sd-Cookie header when making Scrape.do requests. This is how Walmart knows your session is already locked to a store.
Example configuration:
headers = {
"sd-Cookie": "ACID=...; locDataV3=...; locGuestData=...",
"sd-User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)..."
}Attach these headers in every request you send to Scrape.do. If the cookies expire or if you want to get cookies for a different store, grab a new set from DevTools and replace them.
Method 2: Scrape.do Walmart Plugin (Simple)
Scrape.do makes store selection much easier with its new Walmart plugin.
Instead of manually extracting cookies, you can set a store location with just two parameters: zipcode and storeid.
Here's how the plugin works:
Regular Scrape.do API call:
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&super=true&geoCode=us&render=true"With Walmart plugin and a store selected:
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}"The plugin automatically handles all the cookie management, session persistence, and store selection that you'd normally have to do manually.
Finding Your Store ID
To use the plugin, you need two pieces of information: your zip code (easy) and the store ID (requires a quick lookup).
Here's how to find the store ID:
Visit Walmart.com and click the "Pickup or delivery?" dropdown
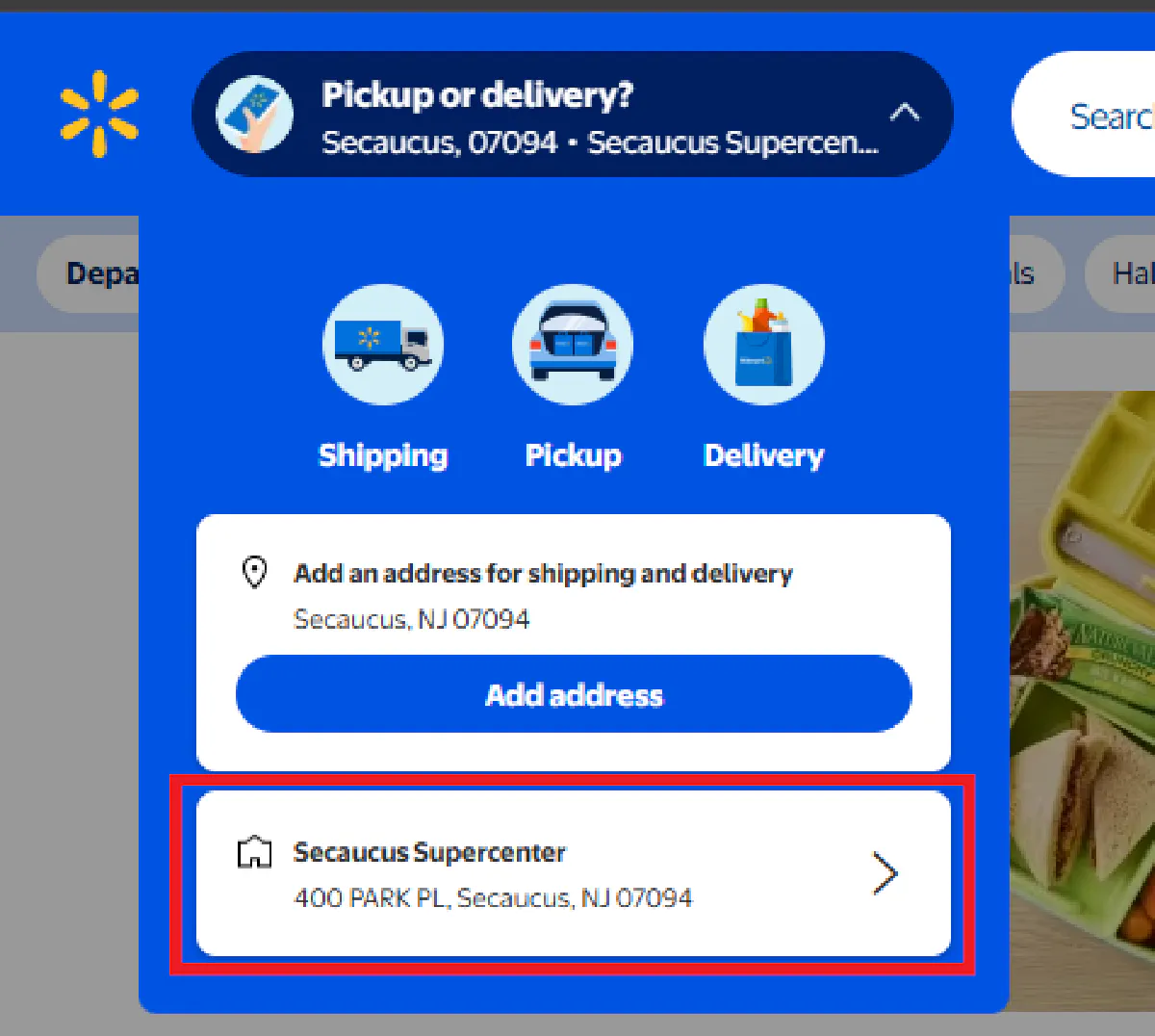
Enter your zip code and select your preferred store
Click on "Store details" for your selected store
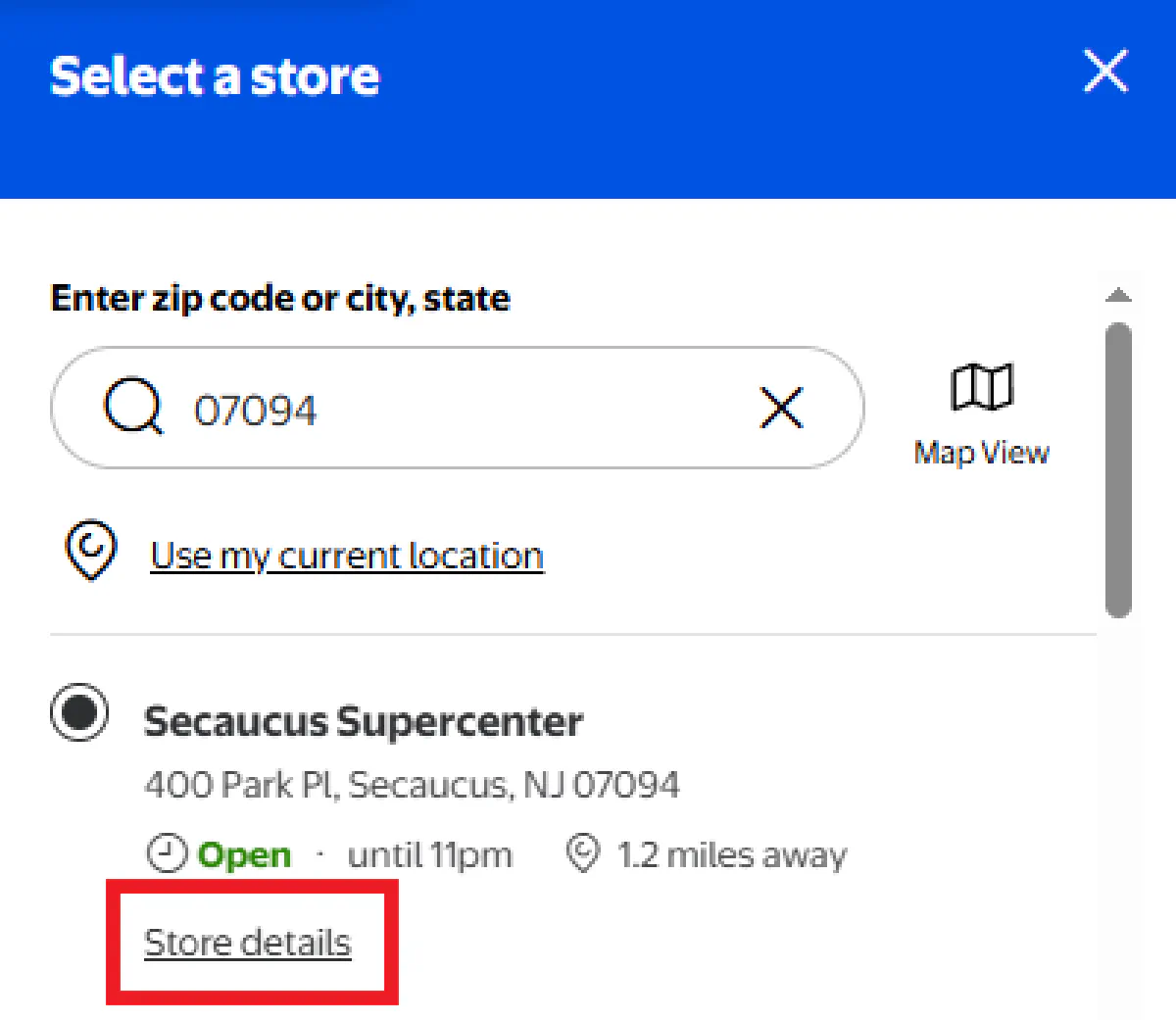
This takes you to a URL like
https://www.walmart.com/store/3520-secaucus-njThe store ID is the number at the beginning:
3520
For our examples, we'll use the Secaucus Supercenter (Store ID: 3520, Zip: 07094).
The plugin approach saves you from:
- Manually extracting cookies from DevTools
- Managing cookie expiration
- Handling session persistence
- Dealing with store-specific cookie chains
We'll use the Scrape.do Walmart plugin for all our code examples going forward.
Scrape Individual Product Pages
Now we'll extract data from single products, including name, brand, price, stock state, discounts, and details.
We'll cover all price variations you might encounter too, whether in stock at regular price, out of stock, or with discounts applied.
Setup and Prerequisites
Start with the essential imports and configuration:
We'll need requests for HTTP calls, BeautifulSoup for HTML parsing, and urllib.parse for URL encoding. We'll use Scrape.do's Walmart plugin to automatically handle store selection.
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Scrape.do API token
TOKEN = "<your-token>"
# Target Walmart product URL
target_url = "https://www.walmart.com/ip/17221971947"
encoded_url = urllib.parse.quote(target_url)
# Scrape.do Walmart plugin API endpoint with Secaucus Supercenter
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}&super=true&geoCode=us&render=true"
response = requests.get(api_url)Scrape Product Name and Brand
We'll parse the HTML response with BeautifulSoup. The product name is usually inside an h1 element with itemprop="name".
For the brand, Walmart doesn't always use a consistent structure, so we check two possible locations:
- An anchor tag with the class
prod-brandName - An anchor tag with the attribute
data-seo-id="brand-name"
By checking both, we reduce the chance of missing brand information when Walmart changes its frontend.
if response.status_code != requests.codes.ok:
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# Product name
name_tag = soup.find("h1", {"itemprop": "name"})
name = name_tag.get_text(strip=True) if name_tag else "N/A"
# Brand (two different possible selectors)
brand_tag = soup.find("a", {"class": "prod-brandName"})
if not brand_tag:
brand_tag = soup.find("a", {"data-seo-id": "brand-name"})
brand = brand_tag.get_text(strip=True) if brand_tag else "N/A"Scrape Stock Availability, Product Price and Discount
Walmart product pages expose stock, pricing, and discount information in multiple elements depending on context.
To handle this, we'll target the most stable attributes available.
- Price: usually found inside a
spanwithdata-seo-id="hero-price". If the text includes "Now", we split and take the second dollar value to isolate the actual price. - Stock availability: if the "Add to Cart" button exists (
buttonwithdata-dca-name="ItemBuyBoxAddToCartButton"), the item is in stock. If not, we mark it as out of stock. - Discount: when a product is on sale, a
divwithdata-testid="dollar-saving"shows the savings amount.
# Price
price_tag = soup.find("span", {"data-seo-id": "hero-price"})
if price_tag:
price = price_tag.get_text(strip=True)
if "Now" in price:
price = "$" + price.split("$")[1]
else:
price = "N/A"
# Stock availability
stock = soup.find("button", {"data-dca-name": "ItemBuyBoxAddToCartButton"})
stock = "In stock" if stock else "Out of stock"
# Discount
discount = soup.find("div", {"data-testid": "dollar-saving"})
discount = "$" + discount.get_text(strip=True).split("$")[1] if discount else "N/A"Scrape Product Details
Walmart product pages may expose details in two different formats.
Some products use AI-generated summaries, while others use the traditional description list. We'll handle both of these cases:
div#product-smart-summary div.mt0 li→ usually AI-generated detailsspan#product-description-atf li→ fallback for regular details
We'll also capture the main product image. This is stored in an img tag with the attribute data-seo-id="hero-image".
additional_info = []
# First attempt: AI generated details
for li in soup.select("div#product-smart-summary div.mt0 li"):
additional_info.append(li.get_text(strip=True))
# Fallback: regular details
if not len(additional_info):
for li in soup.select("span#product-description-atf li"):
additional_info.append(li.get_text(strip=True))
# Image URL
img_tag = soup.find("img", {"data-seo-id": "hero-image"})
image = img_tag["src"] if img_tag and img_tag.has_attr("src") else "N/A"Full Code for Single Product Scraping
Here's the complete working script.
It establishes a store-locked session, fetches the product page through Scrape.do's proxy network, and extracts all available product data.
The output shows structured information ready for analysis or storage.
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Scrape.do API token
TOKEN = "<your-token>"
# Target Walmart product URL
target_url = "https://www.walmart.com/ip/17221971947"
encoded_url = urllib.parse.quote(target_url)
# Scrape.do Walmart plugin API endpoint with Secaucus Supercenter
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}&super=true&geoCode=us&render=true"
response = requests.get(api_url)
if response.status_code != requests.codes.ok:
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# Product name
name_tag = soup.find("h1", {"itemprop": "name"})
name = name_tag.get_text(strip=True) if name_tag else "N/A"
# Brand (two different possible selectors)
brand_tag = soup.find("a", {"class": "prod-brandName"})
if not brand_tag:
brand_tag = soup.find("a", {"data-seo-id": "brand-name"})
brand = brand_tag.get_text(strip=True) if brand_tag else "N/A"
# Price
price_tag = soup.find("span", {"data-seo-id": "hero-price"})
if price_tag:
price = price_tag.get_text(strip=True)
if "Now" in price:
price = "$" + price.split("$")[1]
else:
price = "N/A"
# Stock availability
stock = soup.find("button", {"data-dca-name": "ItemBuyBoxAddToCartButton"})
stock = "In stock" if stock else "Out of stock"
# Discount
discount = soup.find("div", {"data-testid": "dollar-saving"})
discount = "$" + discount.get_text(strip=True).split("$")[1] if discount else "N/A"
# Additional product details (AI or regular)
additional_info = []
for li in soup.select("div#product-smart-summary div.mt0 li"):
additional_info.append(li.get_text(strip=True))
if not len(additional_info):
for li in soup.select("span#product-description-atf li"):
additional_info.append(li.get_text(strip=True))
# Image URL
img_tag = soup.find("img", {"data-seo-id": "hero-image"})
image = img_tag["src"] if img_tag and img_tag.has_attr("src") else "N/A"
# Print results
print("Product Name:", name)
print("Brand:", brand)
print("Price:", price)
print("Stock:", stock)
print("Discount:", discount)
print("Additional Info:", additional_info)
print("Image:", image)When you run the script, it prints structured information for the target product. Here's a sample console output:

Scrape Products with Variants
Many Walmart items aren't static.
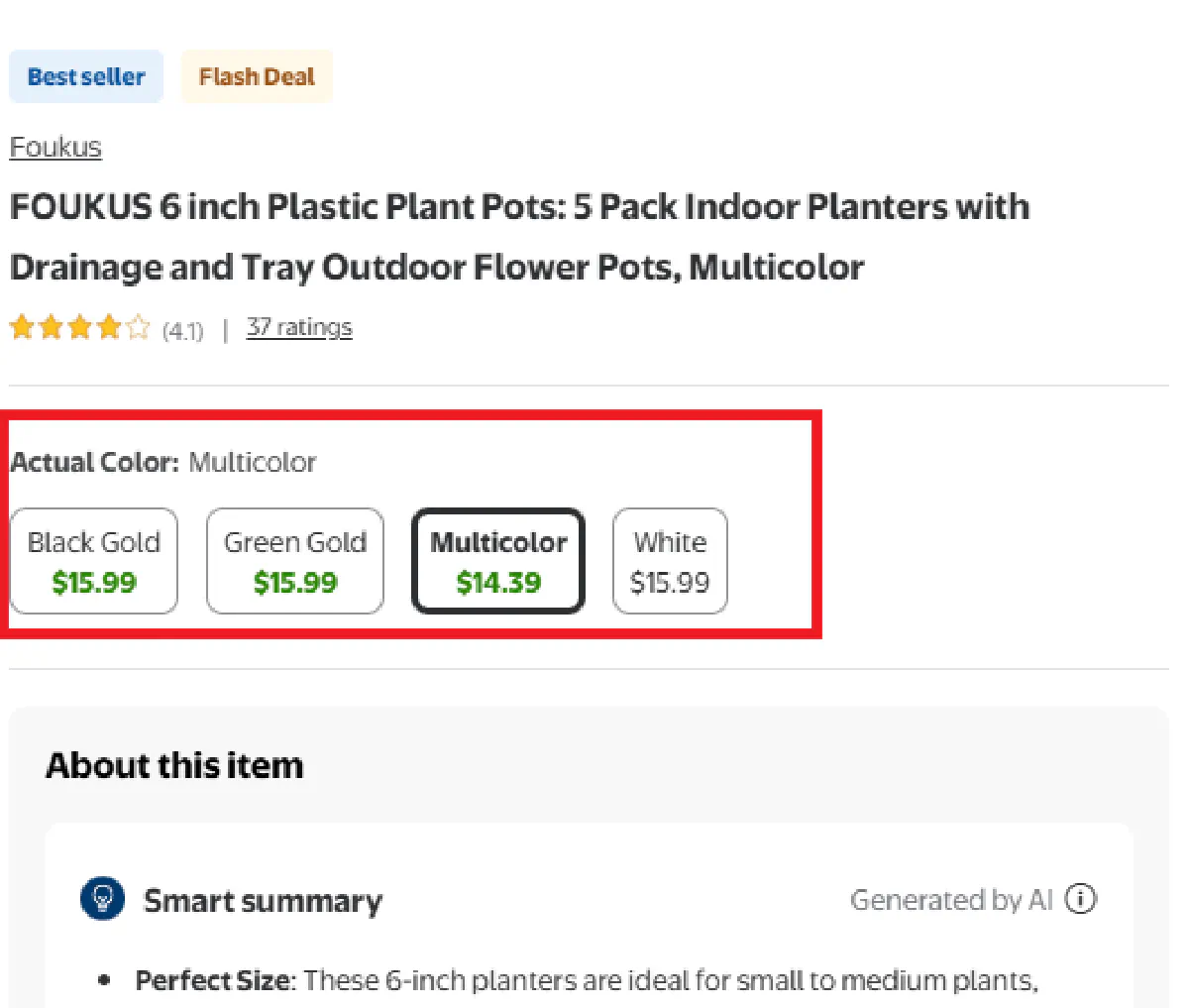
A single listing can contain multiple variants such as different sizes, pack counts, or colors.
Each variant may have its own price, stock state, and discount, which means scraping only the base product page will miss most of the catalog.
To handle this, we'll collect all variant URLs from the product page, then loop through them one by one to capture details. We'll save the output in a CSV where each row represents one variant.
Setup and Prerequisites
Variant scraping requires the same foundation as single products, but we'll add CSV handling since we're collecting multiple items.
The Scrape.do plugin ensures each variant shows pricing for your selected store location.
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Scrape.do API token
TOKEN = "<your-token>"
# Walmart product page with variants
target_url = "https://www.walmart.com/ip/17221971947"
encoded_url = urllib.parse.quote(target_url)
# Scrape.do Walmart plugin API endpoint with Secaucus Supercenter
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}&super=true&geoCode=us&render=true"Scraping Variant URLs
Walmart lists different options for a product (colors, pack sizes, etc.) inside a variant group container hidden within the HTML.
Each variant is represented by an anchor element within div#item-page-variant-group-bg-div:

We'll extract every link, append to Walmart's base domain, and then remove duplicates to avoid hitting the same variant twice.
response = requests.get(api_url)
if response.status_code != requests.codes.ok:
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
variant_urls = []
for variant in soup.select("div#item-page-variant-group-bg-div a"):
variant_urls.append("https://www.walmart.com/" + variant.get("href"))
# Remove duplicates
variant_urls = list(set(variant_urls))Looping Through Variants and Parsing Data
With the list of variant URLs ready, we'll fetch each page through Scrape.do and extract the same fields as in the single product scraper.
variant_products = []
for url in variant_urls:
encoded_url = urllib.parse.quote(url)
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}&super=true&geoCode=us&render=true"
response = requests.get(api_url)
if response.status_code != requests.codes.ok:
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# Product name
name_tag = soup.find("h1", {"itemprop": "name"})
name = name_tag.get_text(strip=True) if name_tag else "N/A"
# Brand
brand_tag = soup.find("a", {"class": "prod-brandName"})
if not brand_tag:
brand_tag = soup.find("a", {"data-seo-id": "brand-name"})
brand = brand_tag.get_text(strip=True) if brand_tag else "N/A"
# Price
price_tag = soup.find("span", {"data-seo-id": "hero-price"})
if price_tag:
price = price_tag.get_text(strip=True)
if "Now" in price:
price = "$" + price.split("$")[1]
else:
price = "N/A"
# Stock
stock = soup.find("button", {"data-dca-name": "ItemBuyBoxAddToCartButton"})
stock = "In stock" if stock else "Out of stock"
# Discount
discount = soup.find("div", {"data-testid": "dollar-saving"})
discount = "$" + discount.get_text(strip=True).split("$")[1] if discount else "N/A"
# Additional product details
additional_info = []
for li in soup.select("div#product-smart-summary div.mt0 li"):
additional_info.append(li.get_text(strip=True))
if not len(additional_info):
for li in soup.select("span#product-description-atf li"):
additional_info.append(li.get_text(strip=True))
# Image
img_tag = soup.find("img", {"data-seo-id": "hero-image"})
image = img_tag["src"] if img_tag and img_tag.has_attr("src") else "N/A"
variant_products.append({
"Product Name": name,
"Brand": brand,
"Price": price,
"Stock": stock,
"Discount": discount,
"Additional Info": additional_info,
"Image": image
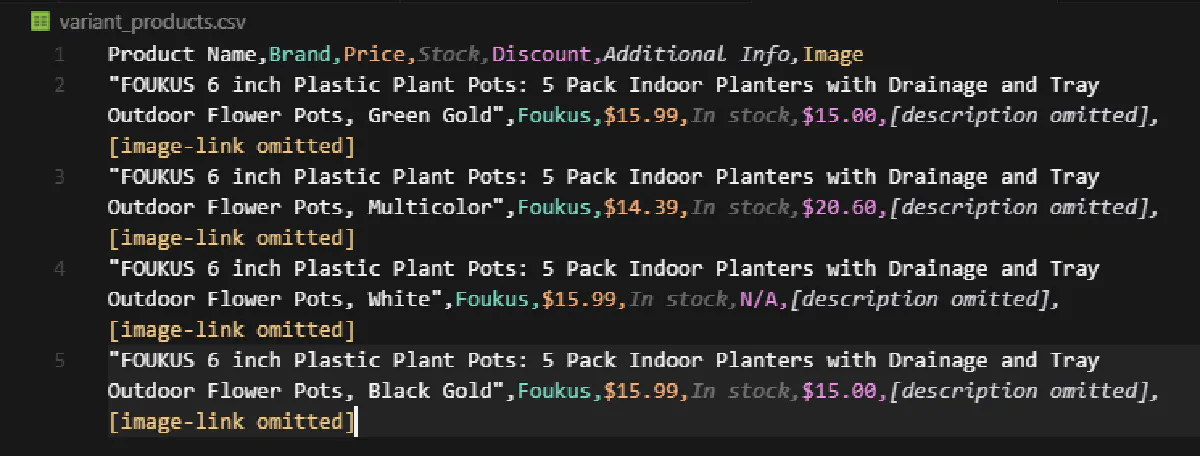
})This gives us a list of dictionaries stored in the variant_products variable, each representing a specific product variation with its full details.
Finalize and Export
Here's the complete script that ties everything together.
💡 For the export step we'll use Python's built-in csv library to write each variant as a row in the output file.
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Scrape.do API token
TOKEN = "<your-token>"
# Walmart product page with variants
target_url = "https://www.walmart.com/ip/17221971947"
encoded_url = urllib.parse.quote(target_url)
# Scrape.do Walmart plugin API endpoint with Secaucus Supercenter
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}&super=true&geoCode=us&render=true"
# Step 1: collect variant URLs
response = requests.get(api_url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
variant_urls = []
for variant in soup.select("div#item-page-variant-group-bg-div a"):
variant_urls.append("https://www.walmart.com/" + variant.get("href"))
variant_urls = list(set(variant_urls))
# Step 2: loop through variants and extract data
variant_products = []
for url in variant_urls:
encoded_url = urllib.parse.quote(url)
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode=07094&storeid=3520&url={encoded_url}&super=true&geoCode=us&render=true"
response = requests.get(api_url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
name_tag = soup.find("h1", {"itemprop": "name"})
name = name_tag.get_text(strip=True) if name_tag else "N/A"
brand_tag = soup.find("a", {"class": "prod-brandName"})
if not brand_tag:
brand_tag = soup.find("a", {"data-seo-id": "brand-name"})
brand = brand_tag.get_text(strip=True) if brand_tag else "N/A"
price_tag = soup.find("span", {"data-seo-id": "hero-price"})
if price_tag:
price = price_tag.get_text(strip=True)
if "Now" in price:
price = "$" + price.split("$")[1]
else:
price = "N/A"
stock = soup.find("button", {"data-dca-name": "ItemBuyBoxAddToCartButton"})
stock = "In stock" if stock else "Out of stock"
discount = soup.find("div", {"data-testid": "dollar-saving"})
discount = "$" + discount.get_text(strip=True).split("$")[1] if discount else "N/A"
additional_info = []
for li in soup.select("div#product-smart-summary div.mt0 li"):
additional_info.append(li.get_text(strip=True))
if not len(additional_info):
for li in soup.select("span#product-description-atf li"):
additional_info.append(li.get_text(strip=True))
img_tag = soup.find("img", {"data-seo-id": "hero-image"})
image = img_tag["src"] if img_tag and img_tag.has_attr("src") else "N/A"
variant_products.append({
"Product Name": name,
"Brand": brand,
"Price": price,
"Stock": stock,
"Discount": discount,
"Additional Info": additional_info,
"Image": image
})
# Step 3: save results to CSV
with open("variant_products.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, variant_products[0].keys())
writer.writeheader()
writer.writerows(variant_products)And here's what our output will look like:
Scrape Categories with Multiple Pages
Individual product pages only show you one item at a time.
To collect broader datasets, you need to scrape Walmart's category listings, which can span dozens of paginated result pages.
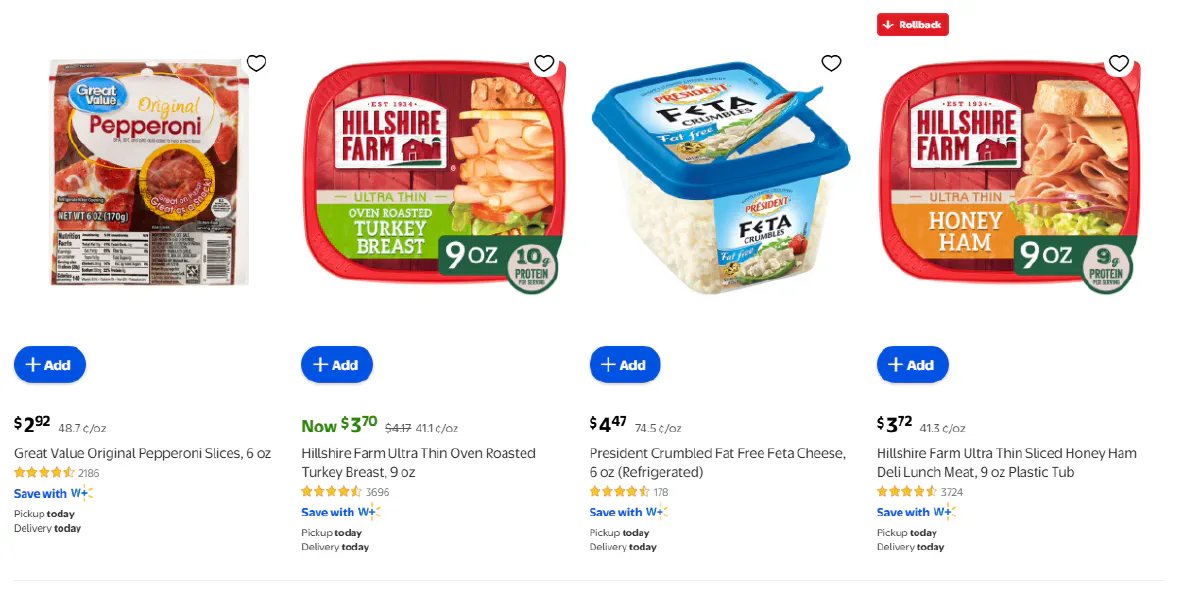
Each page contains tiles with product name, price, image, review data, and a link to the product page.
We need to handle these two challenges:
- Pagination is handled through URL parameters (
?page=2,?page=3, etc.), so we need to loop through them in sequence. - Walmart often reuses the same product tiles across pages, so we'll also track duplicates to avoid cluttering our CSV with repeated items.
We'll use helper functions to fetch pages through Scrape.do, parse products into structured fields, and loop through all pages until we reach the end.
Setup and Prerequisites
When scraping Walmart categories, pagination can trigger bot defenses.
If you try to hit ?page=2 directly without context, Walmart treats it as suspicious traffic. The workaround is to always send a referer header that points to the previous page.
Instead of hardcoding it each time, we'll build helper functions that attach the correct referer for us:
- Page 1 refers to the base URL.
- Page 2 refers to page 1.
- Page 3 refers to page 2, and so on.
Here's the setup section of the code:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
import time
# Scrape.do token
TOKEN = "<your-token>"
# Walmart category page (example: deli meats & cheeses)
target_url = "https://www.walmart.com/browse/food/shop-all-deli-sliced-meats-cheeses/976759_976789_5428795_9084734"
# Store info for Secaucus Supercenter
ZIPCODE = "07094"
STORE_ID = "3520"Building Necessary Helpers
We split the logic into two helpers so the main scraper stays readable.
fetch_page(url, previous_url)
- Sends the request through Scrape.do's Walmart plugin
- Automatically handles store selection with zip code and store ID
- Adds referer header to maintain realistic navigation patterns
- Handles URL encoding and returns raw HTML
def fetch_page(url, previous_url):
headers = {
"sd-User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"sd-Referer": previous_url
}
encoded_url = urllib.parse.quote(url)
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode={ZIPCODE}&storeid={STORE_ID}&url={encoded_url}&super=true&geoCode=us&extraHeaders=true&render=true&customWait=5000&blockResources=false"
response = requests.get(api_url, headers=headers)
response.raise_for_status()
return response.textWe're adding some extra Scrape.do parameters to ensure that all the tile items are loaded correctly.
parse_products(html)
- Parses each product tile in the category grid
- Extracts:
- Name and link
- Image URL
- Price
- Review count and rating
- Returns a list of product dictionaries
def parse_products(html):
soup = BeautifulSoup(html, "html.parser")
products = []
for tile in soup.select("[data-dca-name='ui_product_tile:vertical_index']"):
product = {}
# Name
name_tag = tile.select_one("span", {"data-automation-id": "product-title"}).get_text(strip=True)
product["Name"] = name_tag.split("$")[0] if "$" in name_tag else name_tag
# Link
link_tag = tile.select_one("a", href=True)
if link_tag:
href = link_tag["href"]
if href.startswith("/"):
href = "https://www.walmart.com" + href
product["Link"] = href
else:
product["Link"] = ""
# Image
img_tag = tile.select_one("img", {"data-testid": "productTileImage"})
product["Image"] = img_tag["src"] if img_tag and img_tag.has_attr("src") else ""
# Price
price_tag = tile.find("div", {"data-automation-id": "product-price"})
price_section = price_tag.find("span", {"class": "w_iUH7"}) if price_tag else None
product["Price"] = "$" + price_section.get_text(strip=True).split("$")[1].split(" ")[0] if price_section else ""
# Reviews & rating
review_count_tag = tile.select_one('span[data-testid="product-reviews"]')
product["ReviewCount"] = review_count_tag.get("data-value") if review_count_tag else None
product["Rating"] = ""
if review_count_tag:
next_span = review_count_tag.find_next_sibling("span")
if next_span:
product["Rating"] = next_span.get_text(strip=True).split(" ")[0]
products.append(product)
return productsLooping Through Multiple Pages
While creating our looping logic we'll also add two safeguards:
- Stop early if a page returns no products.
- Track duplicates using product image URLs so the same product isn't stored twice across pages.
def scrape_category(base_url, max_pages=50, delay=1.5):
all_products = []
seen_images = set() # track unique product images across pages
page = 1
while page <= max_pages:
if page == 1:
html = fetch_page(base_url, base_url)
elif page == 2:
html = fetch_page(f"{base_url}?page=2", base_url)
else:
html = fetch_page(f"{base_url}?page={page}", f"{base_url}?page={page-1}")
products = parse_products(html)
if not products:
print(f"No products found on page {page}. Stopping.")
break
new_count = 0
for prod in products:
img = prod.get("Image")
if img and img not in seen_images:
seen_images.add(img)
all_products.append(prod)
new_count += 1
else:
print(f"Duplicate skipped: {prod.get('Name')}")
print(f"Page {page}: extracted {new_count} new products (total {len(all_products)})")
page += 1
time.sleep(delay) # polite delay
return all_productsFull Code and CSV Export
Here's the complete script that brings together our setup, helpers, and pagination loop.
It scrapes every page in the target category, removes duplicate products across pages.
We'll add CSV export at the end using Python's built-in csv library as we did in previous sections:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
import time
# Scrape.do token
TOKEN = "<your-token>"
# Walmart category page (example: deli meats & cheeses)
target_url = "https://www.walmart.com/browse/food/shop-all-deli-sliced-meats-cheeses/976759_976789_5428795_9084734"
# Store info for Secaucus Supercenter
ZIPCODE = "07094"
STORE_ID = "3520"
def fetch_page(url, previous_url):
headers = {
"sd-User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"sd-Referer": previous_url
}
encoded_url = urllib.parse.quote(url)
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode={ZIPCODE}&storeid={STORE_ID}&url={encoded_url}&super=true&geoCode=us&extraHeaders=true&render=true&customWait=5000&blockResources=false"
response = requests.get(api_url, headers=headers)
response.raise_for_status()
return response.text
def parse_products(html):
soup = BeautifulSoup(html, "html.parser")
products = []
for tile in soup.select("[data-dca-name='ui_product_tile:vertical_index']"):
product = {}
# Name
name_tag = tile.select_one("span", {"data-automation-id": "product-title"}).get_text(strip=True)
product["Name"] = name_tag.split("$")[0] if "$" in name_tag else name_tag
# Link
link_tag = tile.select_one("a", href=True)
if link_tag:
href = link_tag["href"]
if href.startswith("/"):
href = "https://www.walmart.com" + href
product["Link"] = href
else:
product["Link"] = ""
# Image
img_tag = tile.select_one("img", {"data-testid": "productTileImage"})
product["Image"] = img_tag["src"] if img_tag and img_tag.has_attr("src") else ""
# Price
price_tag = tile.find("div", {"data-automation-id": "product-price"})
price_section = price_tag.find("span", {"class": "w_iUH7"}) if price_tag else None
product["Price"] = "$" + price_section.get_text(strip=True).split("$")[1].split(" ")[0] if price_section else ""
# Reviews & rating
review_count_tag = tile.select_one('span[data-testid="product-reviews"]')
product["ReviewCount"] = review_count_tag.get("data-value") if review_count_tag else None
product["Rating"] = ""
if review_count_tag:
next_span = review_count_tag.find_next_sibling("span")
if next_span:
product["Rating"] = next_span.get_text(strip=True).split(" ")[0]
products.append(product)
return products
def scrape_category(base_url, max_pages=50, delay=1.5):
all_products = []
seen_images = set() # track unique product images across pages
page = 1
while page <= max_pages:
if page == 1:
html = fetch_page(base_url, base_url)
elif page == 2:
html = fetch_page(f"{base_url}?page=2", base_url)
else:
html = fetch_page(f"{base_url}?page={page}", f"{base_url}?page={page-1}")
products = parse_products(html)
if not products:
print(f"No products found on page {page}. Stopping.")
break
new_count = 0
for prod in products:
img = prod.get("Image")
if img and img not in seen_images:
seen_images.add(img)
all_products.append(prod)
new_count += 1
else:
print(f"Duplicate skipped: {prod.get('Name')}")
print(f"Page {page}: extracted {new_count} new products (total {len(all_products)})")
page += 1
time.sleep(delay) # polite delay
return all_products
# Run scraper and save output
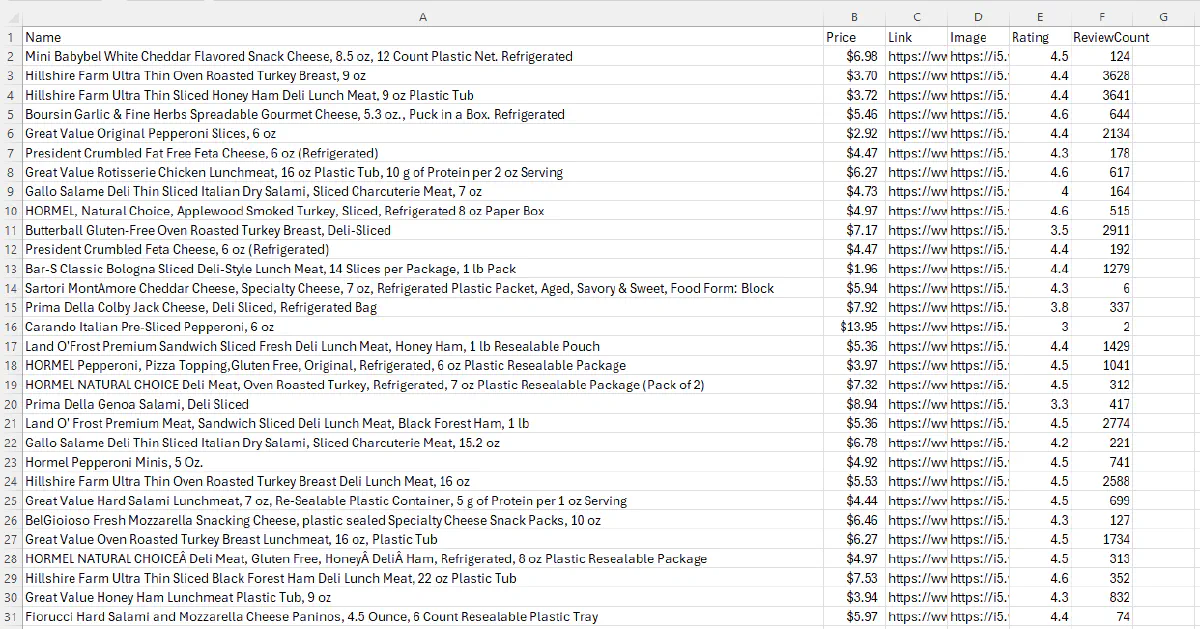
rows = scrape_category(target_url, max_pages=20)
with open("walmart_category.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["Name", "Price", "Link", "Image", "Rating", "ReviewCount"])
writer.writeheader()
writer.writerows(rows)
print(f"Extracted {len(rows)} products to walmart_category.csv")This will take a while but successfully extract all items from the category without duplicates:
Use Case: Track Stock and Price Changes on Walmart
Scraping single products and categories is useful, but the real power comes from tracking changes over time.
Price drops, stock outages, and restocks are all events worth detecting automatically.
Imagine getting an alert when a product's price is reduced, when stock suddenly disappears, or when an item comes back in stock. For larger projects, multiple category scrapers can also feed into a central dataset to build a long-term history of Walmart's inventory.
We'll extend our approach into a tracker script that:
- Collects category results into a structured dataset
- Saves them into a snapshot file
- Compares today's results with the previous run
- Prints alerts when stock or price changes occur
Building Necessary Helpers
We'll define three helpers to keep the tracking logic modular.
fetch_page(url, previous_url)
- Sends requests through Scrape.do's Walmart plugin
- Automatically handles store selection and session management
- Adds referer header so pagination looks natural
- Returns raw HTML for parsing
def fetch_page(url, previous_url):
headers = {
"sd-User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"sd-Referer": previous_url
}
encoded_url = urllib.parse.quote(url)
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode={ZIPCODE}&storeid={STORE_ID}&url={encoded_url}&super=true&geoCode=us&extraHeaders=true&render=true&customWait=5000&blockResources=false"
response = requests.get(api_url, headers=headers)
response.raise_for_status()
return response.textparse_products(html)
- Parses each product tile in the category grid
- Extracts name, link, image, price, rating, and review count
- Marks stock availability based on the presence of a button with
data-automation-id="add-to-cart"
def parse_products(html):
soup = BeautifulSoup(html, "html.parser")
products = []
for tile in soup.select("[data-dca-name='ui_product_tile:vertical_index']"):
product = {}
# Name
name_tag = tile.select_one("span", {"data-automation-id": "product-title"})
product["Name"] = name_tag.get_text(strip=True) if name_tag else "N/A"
# Link
link_tag = tile.select_one("a", href=True)
if link_tag:
href = link_tag["href"]
if href.startswith("/"):
href = "https://www.walmart.com" + href
product["Link"] = href
else:
product["Link"] = ""
# Image
img_tag = tile.select_one("img", {"data-testid": "productTileImage"})
product["Image"] = img_tag["src"] if img_tag and img_tag.has_attr("src") else ""
# Price
price_tag = tile.find("div", {"data-automation-id": "product-price"})
price_section = price_tag.find("span", {"class": "w_iUH7"}) if price_tag else None
product["Price"] = price_section.get_text(strip=True) if price_section else "N/A"
# Reviews & Rating
review_count_tag = tile.select_one('span[data-testid="product-reviews"]')
product["ReviewCount"] = review_count_tag.get("data-value") if review_count_tag else None
product["Rating"] = ""
if review_count_tag:
next_span = review_count_tag.find_next_sibling("span")
if next_span:
product["Rating"] = next_span.get_text(strip=True).split(" ")[0]
# Stock availability
add_to_cart = tile.find("button", {"data-automation-id": "add-to-cart"})
product["Stock"] = "In stock" if add_to_cart else "Out of stock"
products.append(product)
return productsSnapshot Helpers
save_snapshot(filename, rows)writes current run results to a JSON file.load_snapshot(filename)loads the last run for comparison, returns empty list if none exists.
def save_snapshot(filename, rows):
with open(filename, "w", encoding="utf-8") as f:
json.dump(rows, f, ensure_ascii=False, indent=2)
def load_snapshot(filename):
if os.path.exists(filename):
with open(filename, "r", encoding="utf-8") as f:
return json.load(f)
return []Looping Through Categories and Comparing Results
We'll store each snapshot as a JSON file named after the category.
On each run, we'll load previous run's snapshot, scrape the current one, then print any differences.
def scrape_category(base_url, max_pages=5, delay=1.5):
all_products = []
page = 1
while page <= max_pages:
if page == 1:
html = fetch_page(base_url, base_url)
elif page == 2:
html = fetch_page(f"{base_url}?page=2", base_url)
else:
html = fetch_page(f"{base_url}?page={page}", f"{base_url}?page={page-1}")
products = parse_products(html)
if not products:
break
all_products.extend(products)
page += 1
time.sleep(delay)
return all_products
def compare_snapshots(old_data, new_data):
alerts = []
# Build quick lookup by product link
old_map = {p["Link"]: p for p in old_data}
for prod in new_data:
link = prod["Link"]
old_prod = old_map.get(link)
if old_prod:
# Check price change
if prod["Price"] != old_prod.get("Price"):
alerts.append(f"Price change for {prod['Name']}: {old_prod.get('Price')} -> {prod['Price']}")
# Check stock change
if prod["Stock"] != old_prod.get("Stock"):
alerts.append(f"Stock change for {prod['Name']}: {old_prod.get('Stock')} -> {prod['Stock']}")
return alertsFull Code for Tracking Stock and Price Changes
This script scrapes multiple categories, saves each run as a JSON snapshot, compares it with the last run, and exports the latest data into CSV.
Alerts are printed in the console when a product's price or stock state changes.
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
import time
import json
import os
# Scrape.do token
TOKEN = "<your-token>"
# Walmart categories to track
CATEGORY_URLS = [
"https://www.walmart.com/browse/food/shop-all-deli-sliced-meats-cheeses/976759_976789_5428795_9084734",
"https://www.walmart.com/browse/food/snacks/976759_976787"
]
# Store info for Secaucus Supercenter
ZIPCODE = "07094"
STORE_ID = "3520"
def fetch_page(url, previous_url):
headers = {
"sd-User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"sd-Referer": previous_url
}
encoded_url = urllib.parse.quote(url)
api_url = f"https://api.scrape.do/plugin/walmart/store?token={TOKEN}&zipcode={ZIPCODE}&storeid={STORE_ID}&url={encoded_url}&super=true&geoCode=us&extraHeaders=true&render=true&customWait=5000&blockResources=false"
response = requests.get(api_url, headers=headers)
response.raise_for_status()
return response.text
def parse_products(html):
soup = BeautifulSoup(html, "html.parser")
products = []
for tile in soup.select("[data-dca-name='ui_product_tile:vertical_index']"):
product = {}
# Name
name_tag = tile.select_one("span[data-automation-id='product-title']")
product["Name"] = name_tag.get_text(strip=True) if name_tag else "N/A"
# Link
link_tag = tile.select_one("a[href]")
href = link_tag["href"] if link_tag else ""
href = "https://www.walmart.com" + href if href.startswith("/") else href
product["Link"] = href
# Image
img_tag = tile.select_one("img[data-testid='productTileImage']")
product["Image"] = img_tag["src"] if img_tag and img_tag.has_attr("src") else ""
# Price
price_tag = tile.find("div", {"data-automation-id": "product-price"})
price_section = price_tag.find("span", {"class": "w_iUH7"}) if price_tag else None
product["Price"] = price_section.get_text(strip=True) if price_section else "N/A"
# Reviews & Rating
review_count_tag = tile.select_one('span[data-testid="product-reviews"]')
product["ReviewCount"] = review_count_tag.get("data-value") if review_count_tag else None
product["Rating"] = ""
next_span = review_count_tag.find_next_sibling("span") if review_count_tag else None
product["Rating"] = next_span.get_text(strip=True).split(" ")[0] if next_span else ""
# Stock availability
add_to_cart = tile.find("button", {"data-automation-id": "add-to-cart"})
product["Stock"] = "In stock" if add_to_cart else "Out of stock"
products.append(product)
return products
def scrape_category(base_url, max_pages=5, delay=1.5):
all_products = []
page = 1
while page <= max_pages:
url = base_url if page == 1 else f"{base_url}?page={page}"
previous_url = base_url if page <= 2 else f"{base_url}?page={page-1}"
html = fetch_page(url, previous_url)
products = parse_products(html)
break if not products else None
all_products.extend(products)
page += 1
time.sleep(delay)
return all_products
def save_snapshot(filename, rows):
with open(filename, "w", encoding="utf-8") as f:
json.dump(rows, f, ensure_ascii=False, indent=2)
def load_snapshot(filename):
return json.load(open(filename, "r", encoding="utf-8")) if os.path.exists(filename) else []
def compare_snapshots(old_data, new_data):
alerts = []
old_map = {p["Link"]: p for p in old_data}
for prod in new_data:
link = prod["Link"]
old_prod = old_map.get(link)
alerts.append(f"Price change for {prod['Name']}: {old_prod.get('Price')} -> {prod['Price']}") if old_prod and prod["Price"] != old_prod.get("Price") else None
alerts.append(f"Stock change for {prod['Name']}: {old_prod.get('Stock')} -> {prod['Stock']}") if old_prod and prod["Stock"] != old_prod.get("Stock") else None
return alerts
# Main tracking logic
for url in CATEGORY_URLS:
category_name = url.split("/")[5] # crude way to name file
snapshot_file = f"{category_name}_snapshot.json"
old_snapshot = load_snapshot(snapshot_file)
new_snapshot = scrape_category(url, max_pages=20)
save_snapshot(snapshot_file, new_snapshot)
# Export latest data to CSV
csv_file = f"{category_name}_latest.csv"
with open(csv_file, "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["Name", "Price", "Link", "Image", "Rating", "ReviewCount", "Stock"])
writer.writeheader()
writer.writerows(new_snapshot)
# Print alerts
alerts = compare_snapshots(old_snapshot, new_snapshot)
print(f"--- Alerts for {category_name} ---") if alerts else print(f"No changes detected for {category_name}")
[print(alert) for alert in alerts]When run periodically, this script will produce:
- A CSV file with the most recent product data per category.
- A JSON snapshot for historical comparison.
- Console alerts when products change stock or price.
Using this workflow, you can turn the one-off scrapers we built into a real monitoring system for Walmart data.
Some Improvements You Can Do
The tracker we built stores snapshots in JSON and CSV, then prints alerts to the console.
That's enough for testing, but in production you'll want more robust workflows:
- Database Merge: instead of keeping separate JSON snapshots, feed each run into a central database (SQLite, PostgreSQL, MongoDB). Use a unique product identifier like the product link or SKU as the primary key. Each new run updates the record if it exists or inserts a new row, building a complete history of stock and price changes.
- Email Alerts: console logs are fine for debugging, but not practical for monitoring. Integrate an email service (SMTP, SendGrid, Amazon SES) so whenever the
compare_snapshotsfunction finds changes, you get an alert. Each email can include product name, old vs. new price, and stock transitions. - Scheduling: running the tracker once is only a proof of concept. To make it useful, schedule it to run automatically. On Linux you can use cron jobs, on Windows use Task Scheduler, or in the cloud rely on AWS Lambda, Google Cloud Scheduler, or GitHub Actions.
Conclusion
Scraping Walmart in 2026 isn't simple.
Akamai firewalls, HUMAN CAPTCHAs, and store-specific cookies block basic scrapers fast.
But with the right setup that has valid cookies, referer-aware pagination, Scrape.do handling TLS and rendering, you can reliably extract:
- Single products (stock, price, discounts, details, images)
- Variants (sizes, packs, colors)
- Categories with pagination and duplicate filtering
- Price and stock changes over time
The same techniques apply whether you're focused on scraping grocery delivery data from Walmart or expanding to other platforms for comprehensive food delivery data scraping.
Full Stack Developer








