Category:Scraping Use Cases
How to Scrape Screenings and Ticket Prices from regmovies.com

Software Engineer


Regal Cinemas is one of the biggest movie theater chains in the US, but scraping showtimes or ticket prices from regmovies.com isn’t straightforward.
You’ll run into Cloudflare blocks, instant geo-restrictions, and backend calls that aren’t obvious at first glance.
In this guide, we’ll walk through how to bypass those obstacles, scrape screenings for any cinema, and extract ticket prices reliably; all with simple Python scripts.
Skip the tutorial and find fully working code here ⚙
Why Is Scraping regmovies.com Difficult?
At first glance, Regal’s website looks simple enough; pick a cinema, select a date, and buy tickets.
But under the hood, it’s built with multiple layers of protection designed to stop scrapers.
You’ll face Cloudflare challenges, region-based access restrictions, and APIs that aren’t obvious from the frontend.
Without accounting for these, your requests will fail long before you can reach the data.
Heavy Cloudflare Protection
The first obstacle is Cloudflare.
Requests are inspected for things like TLS fingerprints, IP reputation, and header consistency.
If anything looks off, Cloudflare triggers a challenge page before serving real content.
Even when browsing normally, you’ll often encounter this screen:
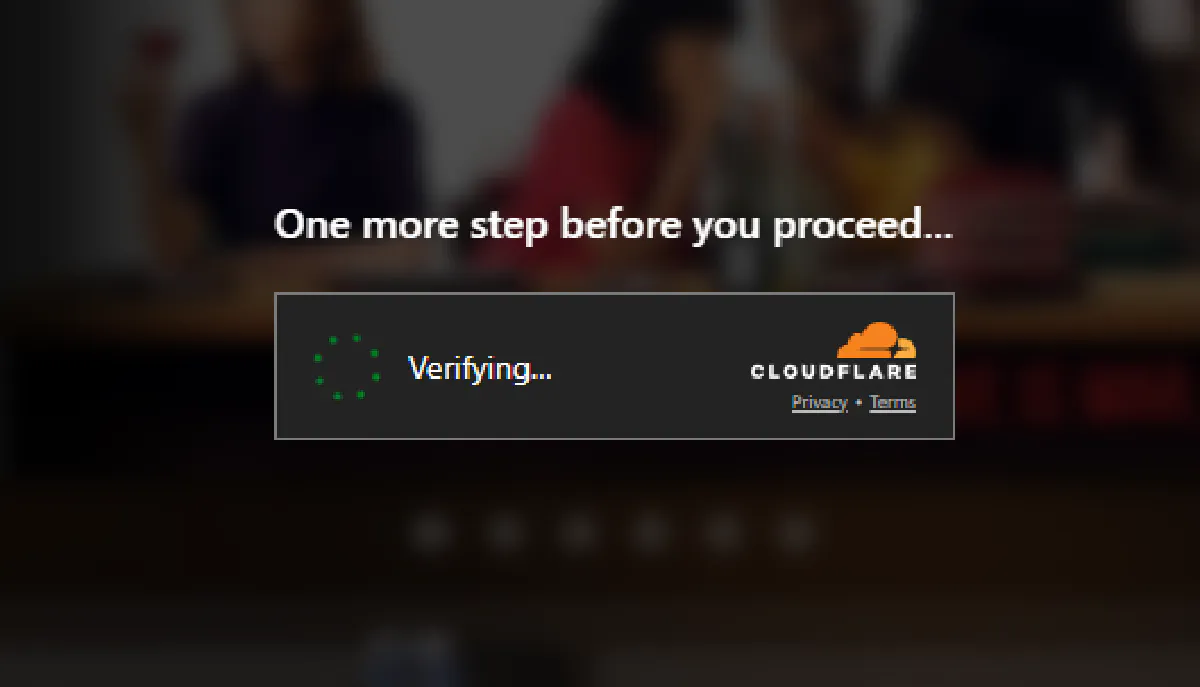
For scraping, that means sending plain requests won’t work.
You need an approach that can mimic a real browser environment and handle automated challenges gracefully.
Tight Geo-Restriction
Even if you manage to get past Cloudflare, access to regmovies.com is tightly restricted to US-based visitors.
The site checks your IP location on every request, and if you’re outside the US you’ll often be blocked instantly with a message like this:
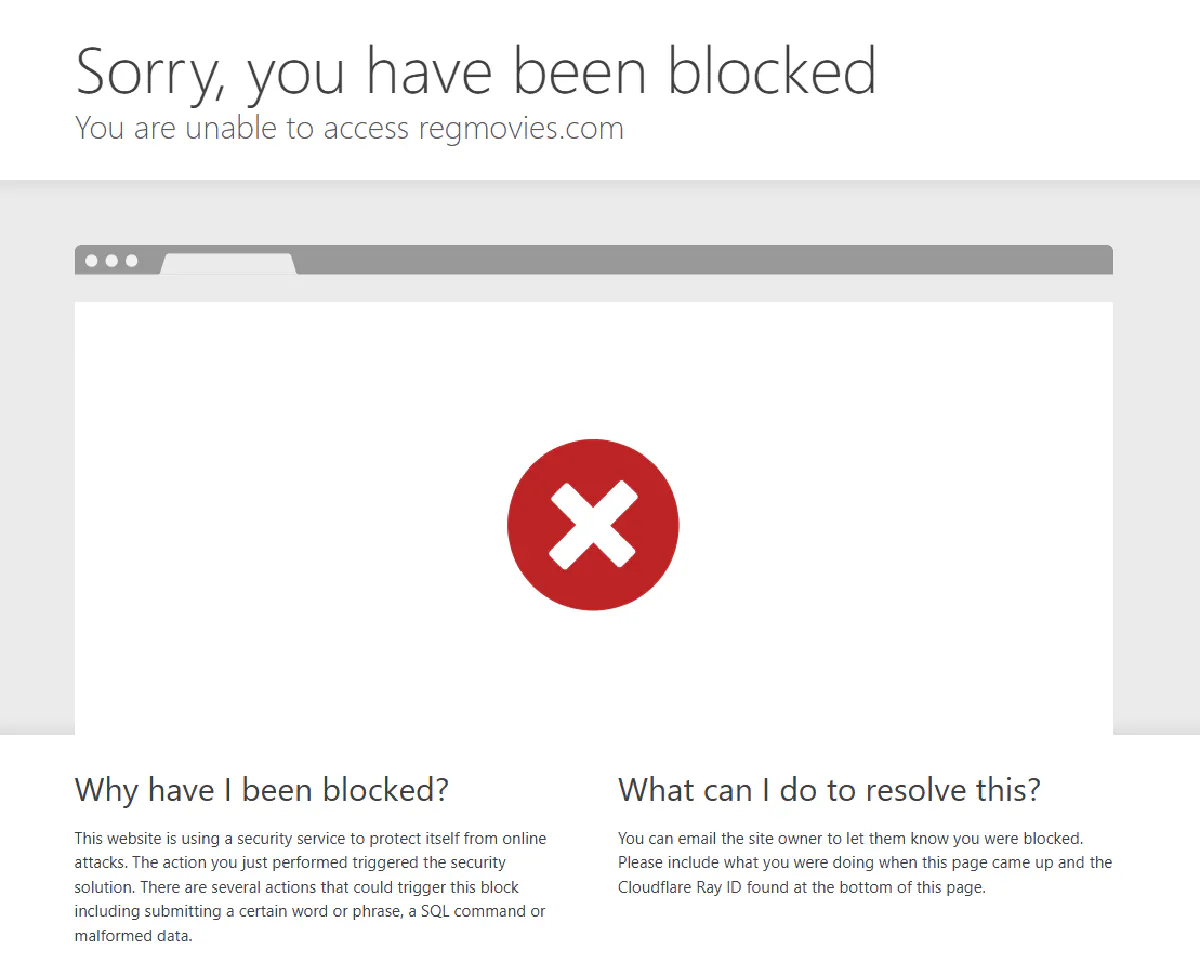
This isn’t a soft restriction; it’s a hard block that prevents you from reaching any cinema pages or API endpoints.
Basic proxy rotation won’t help much either, since low-quality datacenter IPs are quickly flagged and blacklisted.
To scrape successfully, you need requests to appear as if they’re coming from real US users at all times.
For this guide, we'll use Scrape.do to bypass Cloudflare protection of regmovies.com and also send our request through high-quality residential proxies from the US.
Scrape Screenings from regmovies
This will be a bit unusual, but we will skip the frontend completely; the showtime data lives behind a clean backend endpoint that we can call with plain requests.
The flow is simple: pick a cinema, pull its ID, loop a short date range, hit the showtimes API, and collect every performance with its time and internal ID.
We will demonstrate with Regal Village Park as a concrete example (the same method works for any other theater too).
Find Cinema IDs
Pick a theatre page; the last four digits in the URL are the cinema ID.
For example: https://www.regmovies.com/theatres/regal-village-park-0147 will be:
cinema_id = "0147"
cinema_name = "Regal Village Park"Send First Request
Now that we have our cinema ID, let’s confirm that the backend actually gives us useful data.
For now, we’ll just send a single request for one date and dump the raw JSON response to see if we're getting content:
import urllib
import requests
import json
# Scrape.do API token
TOKEN = "<your-token>"
cinema_id = "0147"
date = "10-07-2025"
listing_url = f"https://www.regmovies.com/api/getShowtimes?theatres={cinema_id}&date={date}&hoCode=&ignoreCache=false&moviesOnly=false"
encoded_listing_url = urllib.parse.quote_plus(listing_url)
listing_api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_listing_url}&geoCode=us&super=true&render=true"
response = requests.get(listing_api_url)
listing_json = json.loads(response.text.split("<pre>")[1].split("</pre>")[0])
with open("first_request.json", "w", encoding="utf-8") as f:
json.dump(listing_json, f, ensure_ascii=False, indent=4)
print("Saved first_request.json")This will save the unprocessed JSON to a file (first_request.json) which should look like this:
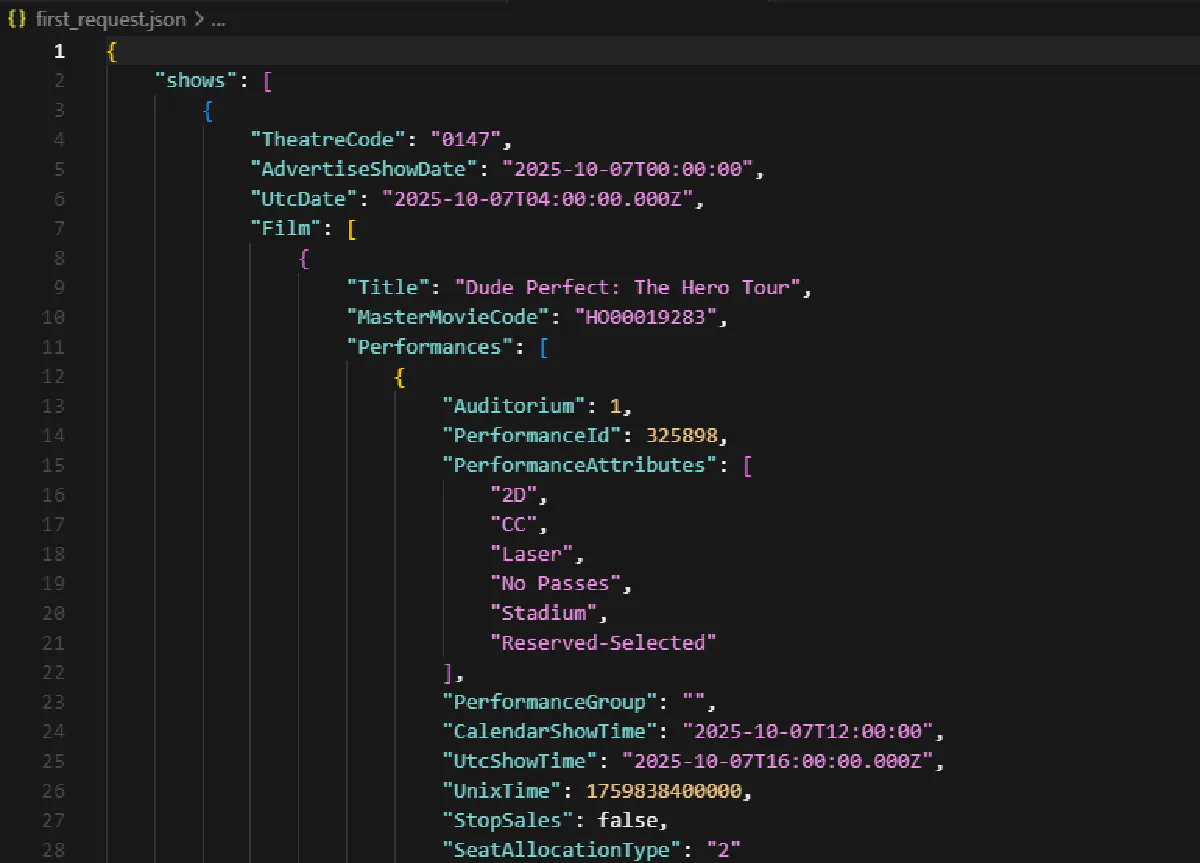
Open it and you’ll see the raw structure of the request. We still need to turn this into a meaningful data structure.
Loop Through a Date Range
We are not scraping just one lucky day; we need to scrape a window. So let's build our working code to scrape multiple days.
First, bring in exactly what we need:
import urllib
import requests
import json
from datetime import datetime, timedeltaWe will generate inclusive dates in the format the backend expects:
def date_range_mmddyyyy(start_date, end_date):
start = datetime.strptime(start_date, "%m-%d-%Y")
end = datetime.strptime(end_date, "%m-%d-%Y")
delta = end - start
return [(start + timedelta(days=i)).strftime("%m-%d-%Y") for i in range(delta.days + 1)]Pick a tiny window to verify the flow. Once this works, you can widen it without changing any logic.
start_date = "10-07-2025"
end_date = "10-09-2025"Now you'll need to input key details and your Scrape.do token to send the backend request seamlessly.
# Scrape.do API token
TOKEN = "<your-token>"
cinema_id = "0147"
cinema_name = "Regal Village Park"We're also turning the range of dates we selected above into something that will work with our code better.
Also create a list to store results for the next step.
dates = date_range_mmddyyyy(start_date, end_date)
screening_list = []Now we loop through each day.
Build the first party showtimes URL, encode it safely, and route it through our transport URL so we hit the real JSON.
for date in dates:
print(f"Scraping screenings from {date}")
listing_url = f"https://www.regmovies.com/api/getShowtimes?theatres={cinema_id}&date={date}&hoCode=&ignoreCache=false&moviesOnly=false"
encoded_listing_url = urllib.parse.quote_plus(listing_url)
listing_api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_listing_url}&geoCode=us&super=true&render=true"Finally, we fetch the payload and unwrap it:
listings_response = requests.get(listing_api_url)
listings_json = json.loads(listings_response.text.split("<pre>")[1].split("</pre>")[0])
shows = listings_json.get("shows")
if len(shows):
movies = shows[0].get("Film", [])Extract Necessary Information
Each day we extracted yields a movies array so we just walk it and pull exactly what we need for the next step: the movie title, its internal screening ID, and a clean time string.
We're gonna keep it simple; no transformations beyond extracting fields and shaping rows.
for movie in movies:
movie_name = movie.get('Title')
performances = movie.get('Performances', [])
for performance in performances:
vista_id = performance.get('PerformanceId')
show_time = performance.get('CalendarShowTime').split("T")[1]
screening_list.append({
"Movie Name": movie_name,
"Date": date,
"Cinema": cinema_name,
"Time": show_time,
"id": vista_id
})This will give you a clean list of movies, dates, and vista_id's for the dates we selected for the cinema whose information we inputted.
Save and Export
Full script below stitched together, exactly as we built it; including the export to screenings.json using the existing function from the json library:
import urllib
import requests
import json
from datetime import datetime, timedelta
def date_range_mmddyyyy(start_date, end_date):
start = datetime.strptime(start_date, "%m-%d-%Y")
end = datetime.strptime(end_date, "%m-%d-%Y")
delta = end - start
return [(start + timedelta(days=i)).strftime("%m-%d-%Y") for i in range(delta.days + 1)]
start_date = "10-07-2025"
end_date = "10-09-2025"
# Scrape.do API token
TOKEN = "<your-token>"
cinema_id = "0147"
cinema_name = "Regal Village Park"
dates = date_range_mmddyyyy(start_date, end_date)
screening_list = []
for date in dates:
print(f"Scraping screenings from {date}")
listing_url = f"https://www.regmovies.com/api/getShowtimes?theatres={cinema_id}&date={date}&hoCode=&ignoreCache=false&moviesOnly=false"
encoded_listing_url = urllib.parse.quote_plus(listing_url)
listing_api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_listing_url}&geoCode=us&super=true&render=true"
listings_response = requests.get(listing_api_url)
listings_json = json.loads(listings_response.text.split("<pre>")[1].split("</pre>")[0])
shows = listings_json.get("shows")
if len(shows):
movies = shows[0].get("Film", [])
for movie in movies:
movie_name = movie.get('Title')
performances = movie.get('Performances', [])
for performance in performances:
vista_id = performance.get('PerformanceId')
show_time = performance.get('CalendarShowTime').split("T")[1]
screening_list.append({
"Movie Name": movie_name,
"Date": date,
"Cinema": cinema_name,
"Time": show_time,
"id": vista_id
})
with open("screenings.json", "w", encoding="utf-8") as f:
json.dump(screening_list, f, ensure_ascii=False, indent=4)
print(f"Extracted {len(screening_list)} screenings from {len(dates)} days")This code will go through each date one-by-one, printing a log to the terminal like this:
Scraping screenings from 10-07-2025
Scraping screenings from 10-08-2025
Scraping screenings from 10-09-2025
Extracted 16 screenings from 3 daysAnd the JSON file that it exports will look like this, all organized:
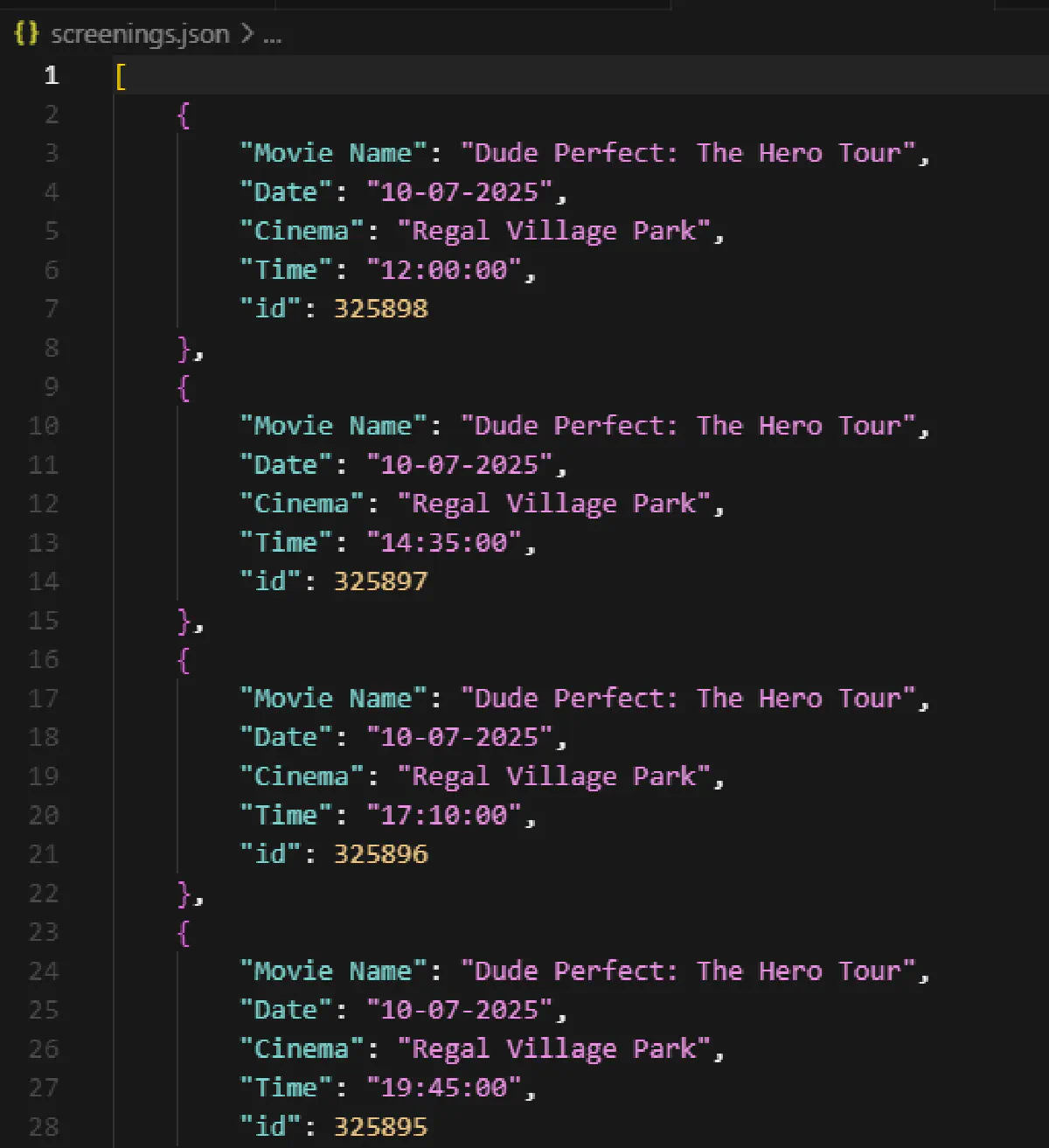
Scrape Ticket Prices for Multiple Screenings
We have a clean list of screenings with their internal IDs, but to make that list useful, we also need to attach real ticket prices.
This means creating a temporary cart session in the backend, then querying the ticketing endpoint for each performance.
Don’t worry, we’ll keep it simple and structure everything into a CSV by the end.
Import and Use CSV
We already have screenings.json from the previous section; now we will load it, set up a tiny helper to format prices as dollars, and prepare a container to collect ticket rows so we can export a clean CSV at the end.
import urllib
import requests
import json
import csv
def cents_to_usd(cents):
try:
return f"${int(cents) / 100:.2f}"
except (ValueError, TypeError):
return None
# Scrape.do API token
TOKEN = "<your-token>"
# Regal cinema we are pricing
cinema_id = "0147"
# Load screenings produced in the previous section
with open("screenings.json", "r", encoding="utf-8") as f:
screening_list = json.load(f)
print(f"Loaded {len(screening_list)} screenings from screenings.json")
# We will append one dict per ticket type here, then write a single CSV
all_tickets = []Loop Through All Screenings
We'll walk through each screening and fetch the ticket information tied to their unique id.
The flow has two moving parts:
- First, we need to create an order session on the backend; this gives us a temporary
cart_idto work with. - Then, we combine that
cart_idwith the screening’sidto reach the ticketing endpoint.
Let’s start by iterating over the list:
for i, session in enumerate(screening_list, 1):
print(f"Processing {i}/{len(screening_list)}: {session['Movie Name']}")
order_url = f"https://www.regmovies.com/api/createOrder"
encoded_order_url = urllib.parse.quote_plus(order_url)
order_api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_order_url}&geoCode=us&super=true"
order_response = requests.post(order_api_url, json={"cinemaId": "0147"})
cart_id = json.loads(order_response.text).get("order").get("userSessionId")
session_id = session["id"]At this point, for each session, we’ve created an order and captured the cart_id along with the session’s own internal id.
Using those two values, we can now build the request for the tickets endpoint and send it through Scrape.do:
tickets_url = f"https://www.regmovies.com/api/getTicketsForSession?theatreCode={cinema_id}&vistaSession={session_id}&cartId={cart_id}&sessionToken=false"
encoded_tickets_url = urllib.parse.quote_plus(tickets_url)
tickets_api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_tickets_url}&geoCode=us&super=true"
tickets_response = requests.get(tickets_api_url)
try:
data = json.loads(tickets_response.text)
except json.JSONDecodeError:
print(f"Invalid JSON for session {session_id}")
continueFinally, if the JSON is valid, we capture the raw ticket objects.
💡 We don’t polish the values yet; that will happen in the next step when we shape them into readable entries with proper price formatting.
tickets = data.get("Tickets", [])
for ticket in tickets:
all_tickets.append({
"Movie Name": session["Movie Name"],
"Date": session["Date"],
"Cinema": session["Cinema"],
"Time": session["Time"],
"TicketTypeCode": ticket.get("TicketTypeCode"),
"LongDescription": ticket.get("LongDescription"),
"Price": cents_to_usd(ticket.get("PriceInCents"))
})Extract Price and Export
At this point, every ticket entry we collected is sitting in all_tickets. Each row already contains the movie title, date, cinema, showtime, ticket type, description, and a price formatted with our cents_to_usd() helper.
Here’s the full working code with the added export logic from the existing csv library of Python:
import urllib
import requests
import json
import csv
def cents_to_usd(cents):
try:
return f"${int(cents) / 100:.2f}"
except (ValueError, TypeError):
return None
# Scrape.do API token
TOKEN = "<your-token>"
cinema_id = "0147"
# Load screenings.json
with open("screenings.json", "r", encoding="utf-8") as f:
screening_list = json.load(f)
all_tickets = []
for i, session in enumerate(screening_list, 1):
print(f"Processing {i}/{len(screening_list)}: {session['Movie Name']}")
order_url = f"https://www.regmovies.com/api/createOrder"
encoded_order_url = urllib.parse.quote_plus(order_url)
order_api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_order_url}&geoCode=us&super=true"
order_response = requests.post(order_api_url, json={"cinemaId": "0147"})
cart_id = json.loads(order_response.text).get("order").get("userSessionId")
session_id = session["id"]
tickets_url = f"https://www.regmovies.com/api/getTicketsForSession?theatreCode={cinema_id}&vistaSession={session_id}&cartId={cart_id}&sessionToken=false"
encoded_tickets_url = urllib.parse.quote_plus(tickets_url)
tickets_api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_tickets_url}&geoCode=us&super=true"
tickets_response = requests.get(tickets_api_url)
try:
data = json.loads(tickets_response.text)
except json.JSONDecodeError:
print(f"Invalid JSON for session {session_id}")
continue
tickets = data.get("Tickets", [])
for ticket in tickets:
all_tickets.append({
"Movie Name": session["Movie Name"],
"Date": session["Date"],
"Cinema": session["Cinema"],
"Time": session["Time"],
"TicketTypeCode": ticket.get("TicketTypeCode"),
"LongDescription": ticket.get("LongDescription"),
"Price": cents_to_usd(ticket.get("PriceInCents"))
})
# Write CSV once
with open("ticket_prices.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["Movie Name", "Date", "Cinema", "Time", "TicketTypeCode", "LongDescription", "Price"])
writer.writeheader()
writer.writerows(all_tickets)
print(f"Saved {len(all_tickets)} ticket entries to ticket_prices.csv")This step takes the entire all_tickets list and dumps it in one clean CSV file, which will look like this:
Conclusion
Scraping showtimes and ticket prices from regmovies.com isn’t easy, but with the right approach it becomes completely manageable.
We bypassed Cloudflare, handled geo-restrictions, skipped the frontend, and pulled structured data straight from Regal’s backend APIs.
With Scrape.do, you don’t have to worry about proxies, headers, CAPTCHAs, or TLS fingerprints; all the heavy lifting is taken care of so you can focus on the data.
Software Engineer








