Scraping RealEstate.com.au - extract property data and prices
RealEstate.com.au is Australia’s biggest real estate platform, listing thousands of properties every day.
Maybe you want to track property prices, analyze trends, or collect property details but if you’ve tried scraping the site, you’ve probably run into blocks.
Like many big platforms, RealEstate.com.au uses Cloudflare and advanced bot detection to stop automated access.
But don’t worry, we’ll get through it together.
In this guide, we’ll break down why scraping RealEstate.com.au is difficult and how to bypass it using Scrape.do, so you can extract property data without headaches.
Why Scraping RealEstate.com.au is Challenging
Scraping a real estate platform sounds simple—just send a request, get the data, and move on. But the moment you try it, you hit a wall.
RealEstate.com.au doesn’t just let scrapers walk in. It actively detects and blocks bots with Cloudflare Enterprise, rate limits, and JavaScript-based content loading. Here’s why it’s difficult:
1. Cloudflare Enterprise Protection
Cloudflare’s job is to separate humans from bots, and it’s very good at it. Which makes it the #1 enemy of a web scraper.
- Every request gets checked to see if it’s coming from a real browser or a script.
- If your request doesn’t execute JavaScript like a normal user, you’ll get blocked.
- It even monitors mouse movements and scrolling behavior to detect automation.
2. IP Tracking and Rate Limits
If you think rotating proxies will help, think again.
RealEstate.com.au has an aggressive IP monitoring which renders datacenter proxies useless. You’ll need quality residential or mobile proxies to get the job done.
3. JavaScript-Rendered Content
Not all the data loads when the page first opens.
Some parts of the page—like price history and dynamic filters—only appear after JavaScript runs.
A simple requests.get() won’t see the full page, leaving you with missing or incomplete data.
So, what’s the solution?
You need a way to bypass Cloudflare, handle session tracking, and load JavaScript properly; without getting blocked.
How Scrape.do Bypasses These Blocks
Instead of fighting against Cloudflare, Scrape.do does all the heavy lifting for you.
With Scrape.do, your scraper doesn’t look like a bot. It looks like a real person browsing the site.
✅ Cloudflare Bypass – Handles JavaScript challenges and bot detection automatically.
✅ Real Residential IPs – Routes requests through Australia-based IPs so you aren’t flagged as a bot.
✅ Session Handling – Manages cookies and headers just like a real browser.
✅ Dynamic Request Optimization – Mimics real user behavior to avoid detection.
With these, you can scrape RealEstate.com.au without getting blocked, no complicated workarounds needed.
Now, let’s send our first request and see if we get access.
Extracting Data from RealEstate.com.au Without Getting Blocked
We’ll extract the property name, price, and square meters from a real estate listing for this tutorial.
Prerequisites
Before making any requests, install the required dependencies:
pip install requests beautifulsoup4
You’ll also need an API key from Scrape.do, which you can get by signing up for free.
For this guide, we’ll scrape this RealEstate.com.au listing for a beautiful home in New South Wales.
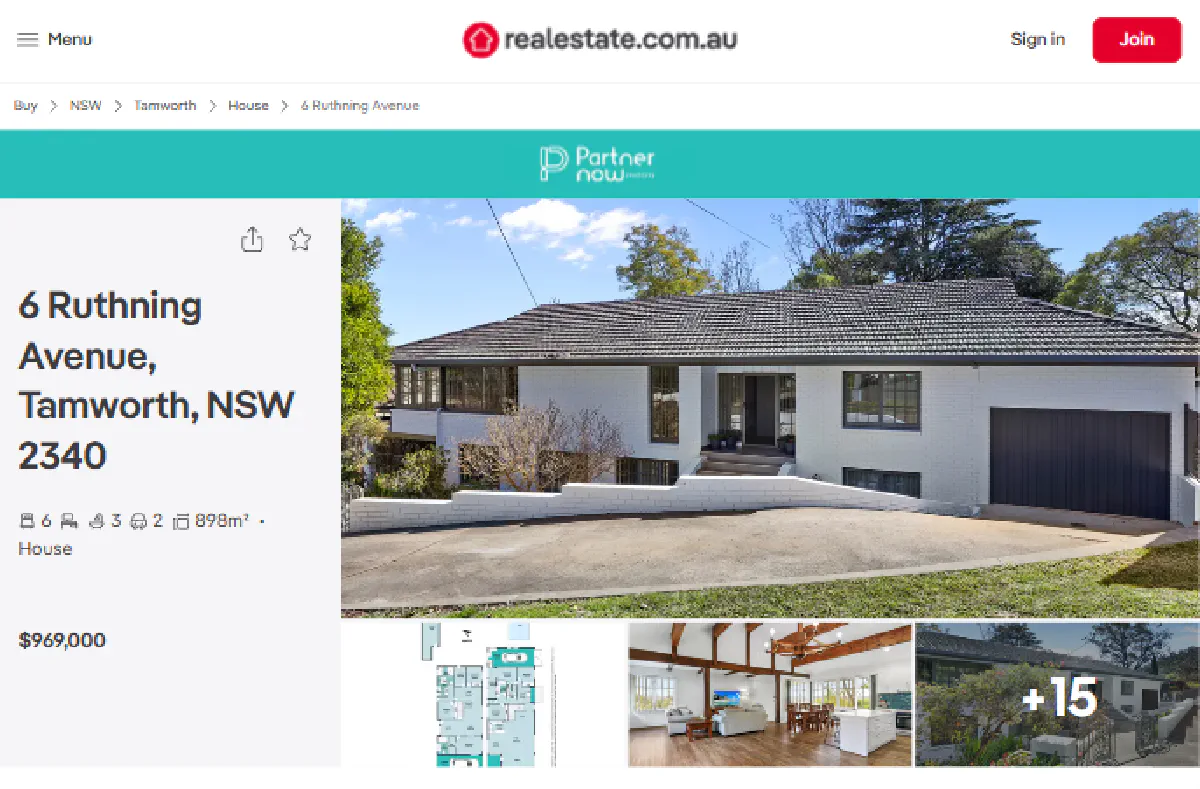
🏊🏻♂️ That pool is huge.
Sending a Request and Verifying Access
First, we’ll send a request through Scrape.do to ensure we can access the page without getting blocked.
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target RealEstate listing URL
target_url = urllib.parse.quote_plus("https://www.realestate.com.au/property-house-nsw-tamworth-145889224")
# Optional parameters
geo_code = "au"
superproxy = "true"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&super={superproxy}"
# Send the request
response = requests.request("GET", url)
# Print response status
print("Response Status:", response.status_code)
This request routes through Scrape.do’s Australian proxies, ensuring it looks like a normal user browsing the site. If everything works, you should see:
Response Status: 200
If you see 403 Forbidden or a Cloudflare error, RealEstate.com.au is blocking your request. In that case, add JavaScript rendering by tweaking the URL:
url = f"https://api.scrape.do/?token={token}&url={target_url}&super={superproxy}&render=true"
Extracting the Property Name
RealEstate.com.au stores the listing title inside an <h1> tag, making it one of the easiest elements to extract.
from bs4 import BeautifulSoup
<----- Previous section until the Print command ----->
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract listing name
listing_name = soup.find("h1").text.strip()
print("Listing Name:", listing_name)
BeautifulSoup finds the <h1> tag, extracts its text, and removes extra spaces. The output should look like this:
Listing Name: House with 898m² land size and 6 bedrooms
Extracting the Sale Price
The property price is stored inside a <span> tag with the class "property-price property-info__price". Instead of pulling all the text, we’ll extract only the price value.
<----- Previous section until the Print command ----->
# Extract sale price
price = soup.find("span", class_="property-price property-info__price").text.strip()
print("Listing Name:", listing_name)
print("Sale Price:", price)
This ensures we grab only the price and clean up any unnecessary spaces.
The output should look like this:
Listing Name: House with 898m² land size and 6 bedrooms
Sale Price: $969,000
Extracting the Square Meters
The square meter value is not in a simple tag—it’s inside a <li> element within "property-info__header", along with other property details. To ensure we extract only the land size, we:
- Find the correct
<li>tag using itsaria-label. - Use regex (
re.search) to extract only the number before"m²".
With the code for the square meter section added, the final code should look like this:
from bs4 import BeautifulSoup
import requests
import urllib.parse
import re
# Our token provided by Scrape.do
token = "<your-token>"
# Target RealEstate listing URL
target_url = urllib.parse.quote_plus("https://www.realestate.com.au/property-house-nsw-tamworth-145889224")
# Optional parameters
geo_code = "au"
superproxy = "true"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&super={superproxy}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract listing name
listing_name = soup.find("h1").text.strip()
# Extract sale price
price = soup.find("span", class_="property-price property-info__price").text.strip()
# Extract square meters
# First locate the correct <li> tag inside property-info__header
square_meters_element = soup.find("li", attrs={"aria-label": re.compile(r"\d+\s*m²")})
# Then extract text and filter out only the number before "m²"
square_meters = re.search(r"(\d+)\s*m²", square_meters_element.text).group(1)
# Print extracted data
print("Listing Name:", listing_name)
print("Sale Price:", price)
print("Square Meters:", square_meters)
Instead of pulling everything inside "property-info__header", this approach finds the specific square meter value and removes any extra text.
And here’s the output you’ll get:
Listing Name: House with 898m² land size and 6 bedrooms
Sale Price: $969,000
Square Meters: 898
Good job, you just scraped realestate.com.au!
Conclusion
Scraping RealEstate.com.au is tough due to Cloudflare protection, session tracking, and JavaScript-rendered content, but with the right tools we’ve scraped everything we need.
If you need to scrape RealEstate.com.au without blocks, Scrape.do makes it easy.
Also You May Interest


Full Stack Developer



Hey, there! As a true data-geek working in the software department, getting real-time data for the companies I work for is really important: It created valuable insight. Using IP rotation, I recreate the competitive power for the brands and companies and get super results. I’m here to share my experiences!