Category:Scraping Use Cases
Scraping Naver: Search Results, Images, Products, Ads using Python

Full Stack Developer



Working plug-and-play codes on Github. 🛠
Naver dominates over 60% of Korea’s search market, powers countless Smart Stores (its e-commerce platform), and handles everything from news to payments.
*If you’re scraping Korean web data, you’ll hit Naver FIRST THING.*
And Naver might hit you back with an outrageous CAPTCHA like this that will break your scrapers fast:

In this comprehensive guide, you'll learn, without running into blocks or CAPTCHAs, how to scrape:
- Organic Search Results from Naver's Search Engine
- Paid Ads from Naver Search Ads
- Image Results Exported from Naver's Backend
- E-Commerce Product Pages from smartstore.naver.com and brand.naver.com
We will build absolutely cost-effective, unblockable, and scalable scrapers that will help you get the data you need.
Scraping All Organic Search Results from Naver's Search Engine
Naver’s search engine powers the majority of Korean web traffic so scraping its organic results is often your first step, especially if you have SEO in your crosshairs.
The search results pages use a modern JavaScript-rendered approach, where results are embedded in JavaScript data structures rather than traditional HTML elements.
We'll use Python with requests, BeautifulSoup, and Scrape.do.
Setup
We’ll install the required libraries and define our token and search query.
pip install requests beautifulsoup4Note: As of September 2025, Naver has updated their search results to use JavaScript-rendered content. This guide reflects the modern approach using JavaScript data extraction.
Make sure to insert your Scrape.do token and define the search query you're going for:
token = "<your_token>"
query = "게이밍 헤드셋"Since we're scraping the Korean search results, I'm using the Korean-translation of "gaming headset" as my target search query so that results work as intended.
Scraping First Page of Naver Search Results
Let’s start by scraping just the first page of organic results for a search term, by scraping the second results page.
Unlike what we come across when scraping Google Search, Naver's first page is a mix of everything their Search products have to offer.
And even though the first page contains a few organic results the second and so on pages include only organic results starting from first ranking URL, so we lose nothing if we start from page 2.
This is the URL format Naver uses for its web search results:
https://search.naver.com/search.naver?where=web&query=게이밍+헤드셋&page=2&start=1Here’s what each part means:
where=web: We're asking for regular web search results.query=게이밍+헤드셋: The actual search term (in this case, “gaming headset” in Korean), URL-encoded.page=1: Which page of results we want (first page here).start=1: The index of the first result to display. For page 2, this would be 16; page 3, it’s 31, and so on.
To scrape this page without getting blocked, we’ll route it through the Scrape.do API and use geoCode=kr so the request originates from Korea.
Here's how we construct the request:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import re
import json
# Your Scrape.do token
token = "<your_token>"
# Define the search query
query = "게이밍 헤드셋"
# Build Naver URL for first page of results
naver_url = f"https://search.naver.com/search.naver?where=web&query={urllib.parse.quote(query)}&page=2&start=1"
# Wrap it in Scrape.do API
api_url = f"https://api.scrape.do?token={token}&url={urllib.parse.quote_plus(naver_url)}&geoCode=kr&super=true"
# Send the request
response = requests.get(api_url)
soup = BeautifulSoup(response.text, 'html.parser')Now let's parse the actual search results.
Modern Naver Structure (2025+):
Naver now embeds search results in JavaScript data structures within <script> tags. The results are passed to an entry.bootstrap() function as JSON data.
The structure looks like this:
entry.bootstrap(document.getElementById("..."), {
"body": {
"props": {
"children": [
{
"props": {
"children": [
{
"props": {
"title": "Result Title",
"href": "https://example.com",
"bodyText": "Description text..."
}
}
]
}
}
]
}
}
});We need to extract this JavaScript data and parse the JSON to get our search results.
We'll extract:
- Title from
props.title(with HTML markup cleaned) - URL from
props.href - Description from
props.bodyText(with HTML markup cleaned)
Here's how we do that in code:
results = []
# Extract search results from JavaScript data
script_tags = soup.find_all('script')
for script in script_tags:
if script.string and 'entry.bootstrap' in script.string:
try:
script_content = script.string
# Find the JSON object passed to entry.bootstrap
start_pos = script_content.find('entry.bootstrap(')
if start_pos == -1:
continue
# Find the first opening brace after the function call
brace_start = script_content.find('{', start_pos)
if brace_start == -1:
continue
# Count braces to find the matching closing brace
brace_count = 0
end_pos = brace_start
for i, char in enumerate(script_content[brace_start:], brace_start):
if char == '{':
brace_count += 1
elif char == '}':
brace_count -= 1
if brace_count == 0:
end_pos = i
break
json_str = script_content[brace_start:end_pos + 1]
# Parse the JSON data
data = json.loads(json_str)
# Extract search results from the data structure
if 'body' in data and 'props' in data['body'] and 'children' in data['body']['props']:
children = data['body']['props']['children']
if len(children) > 0 and 'props' in children[0] and 'children' in children[0]['props']:
search_items = children[0]['props']['children']
for item in search_items:
if 'props' in item:
props = item['props']
# Extract title, URL, and description
title = props.get('title', 'No title')
url = props.get('href', '')
body_text = props.get('bodyText', 'No description available')
# Clean up HTML markup from title and description
title = re.sub(r'<[^>]+>', '', title).strip()
body_text = re.sub(r'<[^>]+>', '', body_text).strip()
# Only add if we have a valid URL
if url and url.startswith('http'):
results.append([title, url, body_text])
break # Found the data, no need to check other scripts
except (json.JSONDecodeError, KeyError, IndexError) as e:
print(f"Error parsing JavaScript data: {e}")
continue
for row in results:
print("Title:", row[0])
print("URL:", row[1])
print("Description:", row[2])
print("") # space for readabilityAt this point, results contains all the titles, links, and descriptions from the first page of Naver's web search; clean and ready to export.
Title,URL,Description
PC헤드셋- 다나와,https://prod.danawa.com/list/?cate=12238749,태블릿/모바일/디카>이어폰/헤드폰>PC헤드셋가격비교 리스트 입니다. 다나와의 가격비교 서비스로 한눈에 비교하고 저렴하게 구매하세요.
게임용 헤드셋|게임용기어,https://www.sony.co.kr/gaming-gear/gaming-headsets,[description omitted]
...
<--- 12 more results --->
...
"가성비 게이밍헤드셋Best 5 ""게임용 헤드셋4만원이면 충분합니다."" 유선, 무선헤드폰, 음질 좋은헤드셋",https://ghlrnjsl13.tistory.com/598,[description omitted]Export to CSV
Now that we’ve successfully extracted the title, URL, and description from each result on the first page, we can export the data to a CSV file.
This allows you to store, analyze, or share the results in a structured format that works well with tools like Excel or Google Sheets.
We’ll use Python’s built-in csv module to do this. Here’s the full export logic:
# add after other imports
import csv
# replace with print section in previous code
# Only export if results exist
if results:
with open("naver_organic_results.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(["Title", "URL", "Description"]) # header row
writer.writerows(results) # all rows of data
print(f"✅ Saved {len(results)} results to naver_organic_results.csv")
else:
print("❗ No results found to export.")❗ utf-8-sig ensures that Korean characters are correctly rendered in Excel.
Now your results will be printed to a CSV in the project folder.
Loop Through All Search Results Pages
So far we’ve only scraped the first page of results. But Naver shows up to 10 pages per query, each containing 15 results. To capture everything, we’ll need to loop through those pages.
Naver’s pagination works by updating two values in the URL:
page=2tells Naver we want the second pagestart=16means “start from result #16” (each page increases by 15)
We’ll use this pattern to scrape all 10 pages automatically, retrying once or twice if we get blocked or receive an empty response before page 10.
Here’s the complete script that scrapes all results and saves them to a CSV file:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
import time
import re
import json
# Your Scrape.do token
token = "<your_token>"
# Search query
query = "게이밍 헤드셋"
def scrape_page(page_num, start_num):
"""Scrape a single page of organic search results"""
# Build URL with pagination, enable super=true on Scrape.do API for better results
target_url = f"https://search.naver.com/search.naver?where=web&query={urllib.parse.quote(query)}&page={page_num}&start={start_num}"
api_url = f"https://api.scrape.do?token={token}&url={urllib.parse.quote_plus(target_url)}&geoCode=kr&super=true"
response = requests.get(api_url)
if response.status_code != 200:
return []
soup = BeautifulSoup(response.text, 'html.parser')
results = []
# Extract search results from JavaScript data
script_tags = soup.find_all('script')
for script in script_tags:
if script.string and 'entry.bootstrap' in script.string:
try:
script_content = script.string
# Find the JSON object passed to entry.bootstrap
start_pos = script_content.find('entry.bootstrap(')
if start_pos == -1:
continue
# Find the first opening brace after the function call
brace_start = script_content.find('{', start_pos)
if brace_start == -1:
continue
# Count braces to find the matching closing brace
brace_count = 0
end_pos = brace_start
for i, char in enumerate(script_content[brace_start:], brace_start):
if char == '{':
brace_count += 1
elif char == '}':
brace_count -= 1
if brace_count == 0:
end_pos = i
break
json_str = script_content[brace_start:end_pos + 1]
# Parse the JSON data
data = json.loads(json_str)
# Extract search results from the data structure
if 'body' in data and 'props' in data['body'] and 'children' in data['body']['props']:
children = data['body']['props']['children']
if len(children) > 0 and 'props' in children[0] and 'children' in children[0]['props']:
search_items = children[0]['props']['children']
for item in search_items:
if 'props' in item:
props = item['props']
# Extract title, URL, and description
title = props.get('title', 'No title')
url = props.get('href', '')
body_text = props.get('bodyText', 'No description available')
# Clean up HTML markup from title and description
title = re.sub(r'<[^>]+>', '', title).strip()
body_text = re.sub(r'<[^>]+>', '', body_text).strip()
# Only add if we have a valid URL
if url and url.startswith('http'):
results.append([title, url, body_text])
break # Found the data, no need to check other scripts
except (json.JSONDecodeError, KeyError, IndexError) as e:
print(f"Error parsing JavaScript data on page {page_num}: {e}")
continue
return results
# Main scraping
all_results = []
page_num = 1
print(f"🔍 Scraping: {query}")
while page_num <= 10:
start_num = (page_num - 1) * 15 + 1
print(f"📄 Page {page_num}...")
page_results = scrape_page(page_num, start_num)
retry_count = 0
# Retry logic for pages 1-9
while not page_results and retry_count < 2 and page_num < 10:
retry_count += 1
print(f"🔄 Retrying page {page_num}... ({retry_count}/2)")
time.sleep(5)
page_results = scrape_page(page_num, start_num)
if not page_results:
print(f"📄 No more results on page {page_num}")
break
all_results.extend(page_results)
print(f"✅ {len(page_results)} results")
page_num += 1
time.sleep(2)
# Save results
if all_results:
with open("naver_organic_results.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(["Title", "URL", "Description"])
writer.writerows(all_results)
print(f"✅ Total: {len(all_results)} results across {page_num - 1} pages")
print("✅ Saved to naver_organic_results.csv")
else:
print("❗ No results found")This will output progress like this in your terminal:
🔍 Scraping: 게임용 헤드셋
📄 Page 1...
✅ 15 results
📄 Page 2...
✅ 15 results
...
<--- goes on for pages 3-9 --->
...
📄 Page 10...
✅ 15 results
✅ Total: 150 results across 10 pages
✅ Saved to naver_organic_results.csvAnd all Naver organic results for a search query will be in the same CSV file!
Scraping All Paid Ads from Naver Search Ads
Naver’s paid ads are served from a separate domain: ad.search.naver.com. These results are structured differently than organic listings and are often wrapped in redirect URLs or promotional blocks.
We'll extract the real ad titles, links, and descriptions cleanly, and use Scrape.do to do so without ever getting blocked or fingerprinted.
Setup
The setup is nearly identical to what we’ve done in the organic results section.
We build a Naver search ads URL like this:
https://ad.search.naver.com/search.naver?where=ad&query=<your_query>This domain (ad.search.naver.com) serves the sponsored listings, and we’ll route it through Scrape.do using a Korean IP (geoCode=kr) to ensure ad content is visible.
We'll use the same Korean translation for "gaming headset", so the full request part should look like this:
import requests
import urllib.parse
# importing BeatifulSoup and csv in advance
from bs4 import BeautifulSoup
import csv
# Your Scrape.do token
token = "<your-token>"
# Search query
query = "게이밍 헤드셋"
# Build the Naver search ads URL
target_url = f"https://ad.search.naver.com/search.naver?where=ad&query={urllib.parse.quote(query)}"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint with South Korean IP addresses, enable super=true on Scrape.do API for better results
api_url = f"https://api.scrape.do?token={token}&url={encoded_url}&geoCode=kr"
# Send the request
response = requests.get(api_url)Scraping and Parsing All Results
Each ad is wrapped in an <li> tag that has a data-index attribute, which makes them easy to target.
Let’s walk through how we parse the three key elements: title, URL, and description.
We start by parsing our request and looping through each ad container. The first thing we extract is the title and URL, both found in the a tag with class tit_wrap.
soup = BeautifulSoup(response.text, 'html.parser')
ad_containers = soup.find_all('li', attrs={'data-index': True})
ads_data = []
for container in ad_containers:
try:
tit_wrap = container.find('a', class_='tit_wrap')
if not tit_wrap:
continue
# Get URL from href attribute
url = tit_wrap.get('href', '')
# If it's a relative path, fix it
if url.startswith('/'):
url = f"https://search.naver.com{url}"
# Get title from anchor text
title = tit_wrap.get_text(strip=True)This gives us the headline of the ad and the destination link (cleaned if needed).
Next, we extract the description. This lives inside a div with class desc_area, though not all ads include one.
desc_area = container.find('div', class_='desc_area')
description = desc_area.get_text(strip=True) if desc_area else "No description available"Finally, we combine everything and store it in our ads_data list.
ads_data.append([title, url, description])Save and Export to CSV
Now all that's left is to store the data in a CSV file named naver_ads_data.csv.
This file will include three columns: Title, URL, and Description.
Here’s the final code that includes request, parsing, and export:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Your Scrape.do token
token = "<your_token>"
# Search query
query = "게이밍 헤드셋"
# Build the Naver search ads URL
target_url = f"https://ad.search.naver.com/search.naver?where=ad&query={urllib.parse.quote(query)}"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint with South Korean IP addresses, enable super=true on Scrape.do API for better results
api_url = f"https://api.scrape.do?token={token}&url={encoded_url}&geoCode=kr"
# Send the request
response = requests.get(api_url)
# Check if the request was successful
if response.status_code == 200:
# Parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Find all ad containers (li elements with data-index)
ad_containers = soup.find_all('li', attrs={'data-index': True})
ads_data = []
for container in ad_containers:
try:
# Find the tit_wrap link within this ad container
tit_wrap = container.find('a', class_='tit_wrap')
if not tit_wrap:
continue
# Extract the URL from the tit_wrap link
url = tit_wrap.get('href', '')
# Clean up the URL if it's a relative path
if url.startswith('/'):
url = f"https://search.naver.com{url}"
# Extract the title (all text from tit_wrap)
title = tit_wrap.get_text(strip=True)
# Find the description from the desc_area within this container
desc_area = container.find('div', class_='desc_area')
if desc_area:
description = desc_area.get_text(strip=True)
else:
description = "No description available"
# Add to results
ads_data.append([title, url, description])
except Exception as e:
print(f"Error processing ad container: {e}")
continue
# Export to CSV
with open("naver_ads_data.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(["Title", "URL", "Description"])
writer.writerows(ads_data)
print(f"✅ Found {len(ads_data)} ads")
print("✅ Data saved to naver_ads_data.csv")
else:
print(f"❗ Request failed with status code {response.status_code}")
print("Check if your token is valid and geo-restrictions are handled.")And here's what our CSV file will look like for this search query.
Title,URL,Description
원두커피,[paid ad link],"전문 로스터가 직접 볶은 원두, 런트커피"
...
<--- 23 more results --->
....
캘리포니아도넛클럽 천안불당점,[paid ad link],항상 좋은 제품을 만들도록 노력하겠습니다💡 Trying a few different search queries, the paid results can vary between 1 and 25-30, so if you're getting lower results than you need you might need to check live page.
Scraping Naver Image Search Results Through Backend API
Scraping image search results from Naver might seem like a JavaScript-heavy task at first.
If you open the standard image search page and try to extract results, nothing useful appears in the HTML, because the actual images load dynamically as you scroll.
You’d need a headless browser, JavaScript rendering, and scroll automation to load everything and even then, you'd burn through time and credits just to grab a few dozen URLs.
So we skip all of that.
Instead, we go straight to the backend API Naver uses to populate image results in the browser.
Setup
We found this API by simply visiting Naver Image Search and opening DevTools (F12). Then we:
- Performed a search (e.g., Korean translation of "gaming headset" ->
게이밍 헤드셋) - Switched to the Network tab
- Scrolled down until more images loaded
- As new images loaded, checked the API calls that were made to see where Naver was pulling the data from
This revealed a backend API call like:
https://s.search.naver.com/p/c/image/search.naver?json_type=6&query=게이밍+헤드셋&_callback=getPhoto&display=30Here’s what this does:
json_type=6returns a more detailed JSON formatquery=...is your search termdisplay=30controls how many image results to fetch (up to 500 max)_callback=getPhotowraps the JSON in a callback (we’ll remove this later)
We’ll send this request through Scrape.do just like before; no need for rendering, scrolling, or browser simulation.
First, install the required libraries (if not already installed):
pip install requestsThen we import them and prepare our token and query:
import requests
import urllib.parse
import json
import csv
# Your Scrape.do token
token = "<your_token>"
# Your search query
query = "게이밍 헤드셋"Extract Image Results from JSON
The backend API returns a long JSON object (wrapped in a getPhoto(...) callback). Inside it, each image result includes dozens of fields, but we only care about three:
"title"— the image’s name or alt text"link"— a redirector URL (used by Naver’s frontend)"originalUrl"— the actual direct link to the image file (JPG, PNG, etc.)
So let's build the request and the parsing logic to get what we want:
# Build the Naver image backend API URL
backend_url = f"https://s.search.naver.com/p/c/image/search.naver?json_type=6&query={urllib.parse.quote(query)}&_callback=getPhoto&display=100"
# Wrap it in Scrape.do
encoded_url = urllib.parse.quote_plus(backend_url)
api_url = f"https://api.scrape.do?token={token}&url={encoded_url}&geoCode=kr"
# Send the request
response = requests.get(api_url)
# Remove the JSONP wrapper ("getPhoto(...)")
raw_text = response.text
json_start = raw_text.find("(") + 1
json_end = raw_text.rfind(")")
json_content = raw_text[json_start:json_end]
# Parse the cleaned JSON
data = json.loads(json_content)
image_items = data.get("data", {}).get("list", [])
# Extract title, link, and originalUrl
image_data = []
for item in image_items:
title = item.get("title", "").strip()
redirect_link = item.get("link", "")
direct_image_url = item.get("originalUrl", "")
image_data.append([title, redirect_link, direct_image_url])Now image_data holds all your image metadata ready to be exported.
Save and Export to CSV
We’ll use built-in csv library to export everything to a CSV file called naver_image_results.csv.
Here’s the full working script from start to finish:
import requests
import urllib.parse
import json
import csv
token = "<your_token>"
query = "게이밍 헤드셋"
# Number of images to display (max 500)
display_count = 30
# Build the Naver image search API URL
# This endpoint returns JSONP data for image search results
url = f"https://s.search.naver.com/p/c/image/search.naver?json_type=6&query={urllib.parse.quote(query)}&_callback=getPhoto&display={display_count}"
# Scrape.do API endpoint with South Korean IP address, enable super=true on Scrape.do API for better results
api_url = f"https://api.scrape.do?token={token}&url={urllib.parse.quote_plus(url)}&geoCode=kr"
# Send the request
resp = requests.get(api_url)
# Check if the request was successful
if resp.status_code == 200:
content = resp.text
# Remove the JSONP callback wrapper: getPhoto(...)
if content.startswith('getPhoto('):
start = 9 # Length of 'getPhoto('
end = content.rfind(')')
json_content = content[start:end] if end > start else content[start:]
else:
json_content = content
try:
# Parse the JSON data
data = json.loads(json_content)
items = data.get('items', [])
# Extract title, link, and original image URL for each result
results = [[item.get('title', ''), item.get('link', ''), item.get('originalUrl', '')] for item in items]
# Export to CSV
with open("naver_images_results.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Link", "Original URL"])
writer.writerows(results)
print(f"✅ Found {len(results)} images\n✅ Data saved to naver_images_results.csv")
except json.JSONDecodeError as e:
print(f"❗ JSON parsing error: {e}\nResponse content: {content[:500]}")
else:
print(f"❗ Request failed with status code {resp.status_code}\nCheck if your token is valid and geo-restrictions are handled.")And once this runs successfully and very quickly, your CSV file will be populated with the results:
Title,Link,Original URL
녹스 게이밍 헤드셋 NX-502 게임용 USB 마이크 7.1 ◎역시 최고로 저렴해요◎,[redirect link],[image url]
제로존 게이밍 헤드셋(레드)/pc게임용 마이크헤드셋 - 예스24,[redirect link],[image url]
...
<--- 27 more results --->
....
피시방헤드셋 리얼7.1 넥스원 게이밍 게임용 LED 고품질 헤드셋 : 한번만 사줘,[redirect link],[image url]Scraping Naver E-Commerce Product Pages
It wouldn't be wrong to say almost everyone in South Korea uses Naver's e-commerce platforms like smartstore.naver.com or brand.naver.com/(brand-name).
So if you're looking to buy from or sell products in South Korea, you need to scrape these pages.
We'll follow two approaches, first one is the traditional web scraping approach that collects data from the product page, and second one is a lot similar to how we collected images, through a backend API call.
But first, setting expectations:
Why Are Product Pages Significantly More Difficult to Scrape?
Scraping Search Results is a walk-in-the-park compared to product pages.
Naver is AGGRESSIVE 👊🏻💥 when it comes to breaking down crawlers, scrapers, and any kind of bot.
The two biggest defenses are:
Datacenter Proxies Are Blocked Instantly
Naver, unlike for Search Pages, actively blocks traffic from known datacenter IP ranges to its e-commerce stores. Be ready to get familiar with this page really quickly:

If you’re sending requests from AWS, GCP, or any commercial proxy provider, you’re almost guaranteed to hit:
403 Forbidden— request denied outright429 Too Many Requests— rate-limited before you even start502 Bad Gateway— fallback error, often shown when WAFs intervene
You won’t even get through the front door.
To avoid this, you’ll need residential or mobile IPs, ideally from Korean ISPs, with session stickiness and rotating headers or you’ll get flagged immediately.
JavaScript Rendering Isn’t Enough
Even with a powerful headless browser, you might still end up with a blank page.
That’s because on product pages Naver uses multi-layered JavaScript challenges; sometimes tied to region, sometimes tied to session behavior.
And if your scraper doesn’t match expected patterns (browser fingerprint, TLS, execution timing), rendering will silently fail or loop endlessly.
Some pages return 200 OK and look like they load (like below), but never actually return real content unless every script executes correctly, in the right sequence.

That’s what makes Naver stores different: *it doesn’t just check if you’re a bot, it tests if you behave like a real user inside a Korean browser session.*
How Scrape.do Bypasses These Challenges
Scraping Naver with your own setup?
You’ll get blocked before the page even loads.
That’s because Naver checks everything; where you're connecting from, how your browser behaves, and whether your session looks natural.
Even well-configured headless browsers fail without the right IP and session setup.
Scrape.do handles all of this under the hood, so you don’t have to.
- KR residential IPs 🇰🇷
- Sticky sessions 📌
- Rotating headers & TLS fingerprints 🔄
- Full JavaScript rendering 🖼️
Without extensive setup and maintenance, you just send the URL and get the real page back, instantly.
Scrape Naver Product Details Directly From Product Page
This is the most common approach: go directly to the product page, extract name, price, and other key details.
It works well if you can get past the initial blocks. For this tutorial, we’ll scrape the a brand.naver.com product page for a SteelSeries headset using Python and Scrape.do.
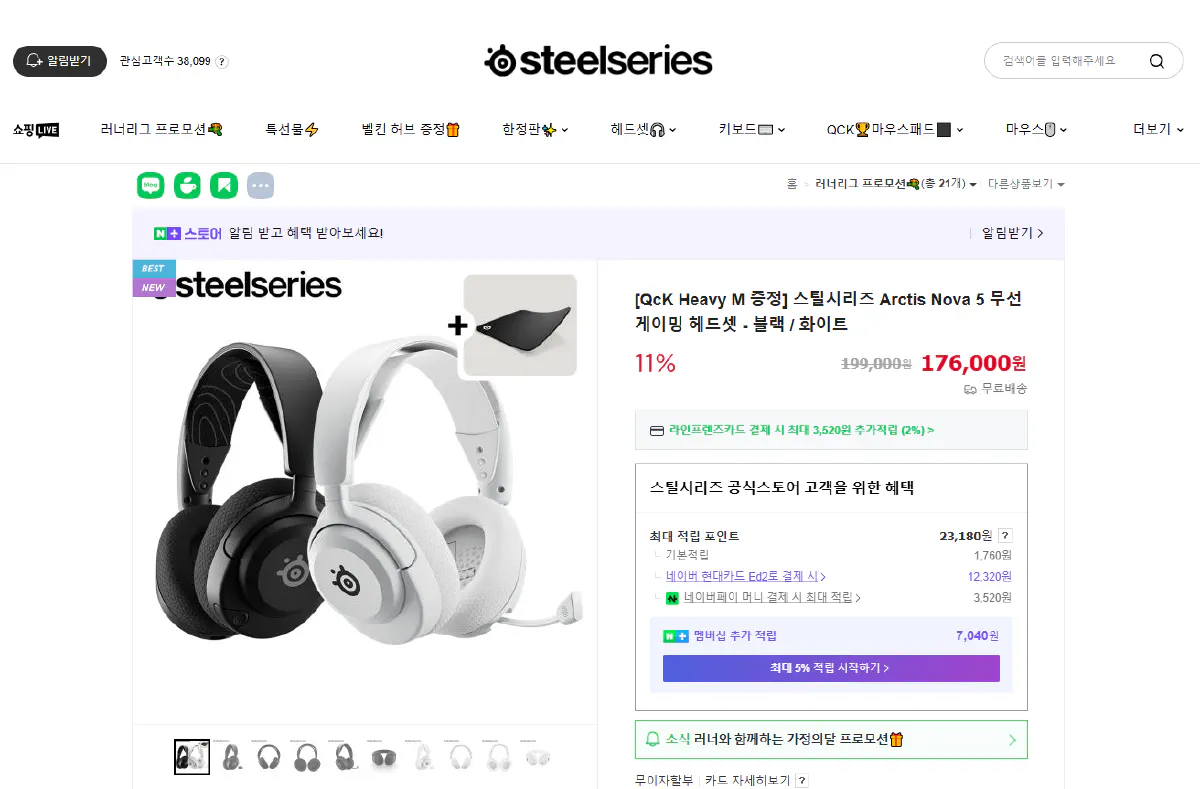
⚠ smartstore.naver.com stores are also successfully scraped using the following methods.
Before we send our first request, let’s make sure we have the tools we need.
Prerequisites
We’ll use Python and a few simple libraries:
requests: To send our HTTP requests.re: To locate desired elements from the returned HTML.- Scrape.do API Token: You’ll need a Scrape.do token to access the page without getting blocked. You can sign up here for free and get 1000 credits to start.
Install requests if you don’t have it:
pip install requestsSending the First Request
Let’s hit the product page and make sure we’re getting a real response.
We’ll use super=true to activate premium proxy routing; this is especially important for Naver, where regular IPs get blocked fast.
Here’s how to send the request:
import requests
import urllib.parse
# Your Scrape.do token
token = "<your_token>"
# Naver product URL
target_url = "https://brand.naver.com/steelseries/products/11800715035"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint with super=true for premium proxy routing
url = f"https://api.scrape.do?token={token}&url={encoded_url}&super=true"
# Send the request
response = requests.get(url)
# Print status code
print(response)If the setup is working, you should see:
<Response [200]>That means Naver let you in and we’re ready to start extracting data.
Extracting Product Name and Price
Now that we’ve confirmed we’re getting a valid response, we can extract the product name and price directly from the page source.
❗ Usually we find on the page the information we're trying to scrape and hit Inspect to get the element we need, but it won't work this time. We need to go to the page source and find information we're looking for there.
If you scroll through the HTML response, you’ll find that Naver injects all product information into a large embedded JSON block.
This is part of their internal state object, and it contains fields like "dispName" for the product title and "dispDiscountedSalePrice" for the final price shown on the page:
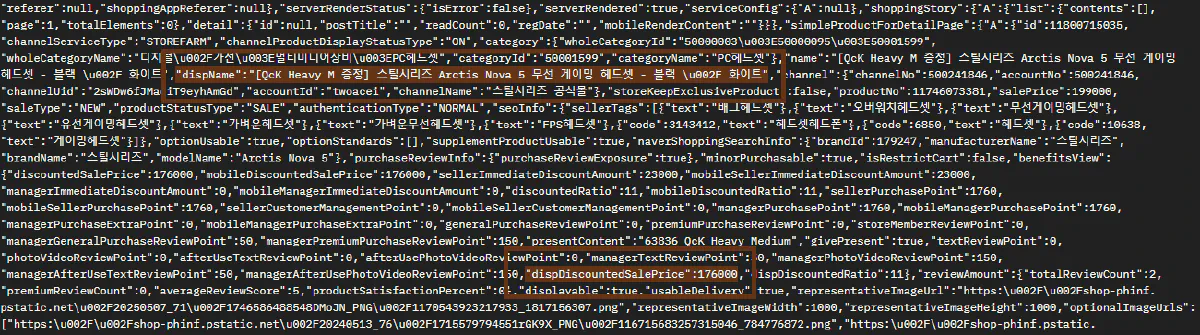
We don’t need to parse the entire JSON. A simple regular expression will do the job.
Here’s how:
import requests
import urllib.parse
import re
# Your Scrape.do token
token = "<your_token>"
# Target URL
target_url = urllib.parse.quote_plus("https://brand.naver.com/steelseries/products/11800715035")
# Scrape.do API endpoint with premium proxy routing
url = f"https://api.scrape.do?token={token}&url={target_url}&super=true"
# Send the request
response = requests.get(url)
# Extract the values via regex
html = response.text
product_name = re.search(r'"dispName":"([^"]+)"', html).group(1)
discounted_price = int(re.search(r'"dispDiscountedSalePrice":([0-9]+)', html).group(1))
# Print product name and price
print("Product Name:", product_name)
print("Price:", f"{discounted_price:,}₩")You output should look like this:
Product Name: [QcK Heavy M 증정] 스틸시리즈 Arctis Nova 5 무선 게이밍 헤드셋 - 블랙 / 화이트
Price: 176,000₩And voila! You've scraped a product from Naver.
However, my experience using this method has been inconsistent.
The security at Naver is TIGHT!
So, I've found a slightly different approach that uses their API endpoint:
Scrape Naver API Endpoint for Product Details
If you want something faster, more stable, and easier to parse, Naver’s own API is the better option. It returns clean JSON, loads faster, and is more consistent across products.
The only catch?
You need to build the API request yourself.
But the good news is: it’s easier than it sounds.
You only need two things:
channelUid: the store identifier (like a brand or seller)productNo: the product ID (already in the URL)
And chances are, if you’re scraping Naver, you're targeting specific stores anyway, which means you can reuse the channelUid across dozens or hundreds of products.
Let me show you how to find it:
Find channelUid
The easiest way to find channelUid is by inspecting the page source.
Right-click anywhere on the product page and hit Inspect, or press F12.
Once DevTools opens, press Ctrl + F and search for:
channelUidYou’ll see it in plain text, should look like this:
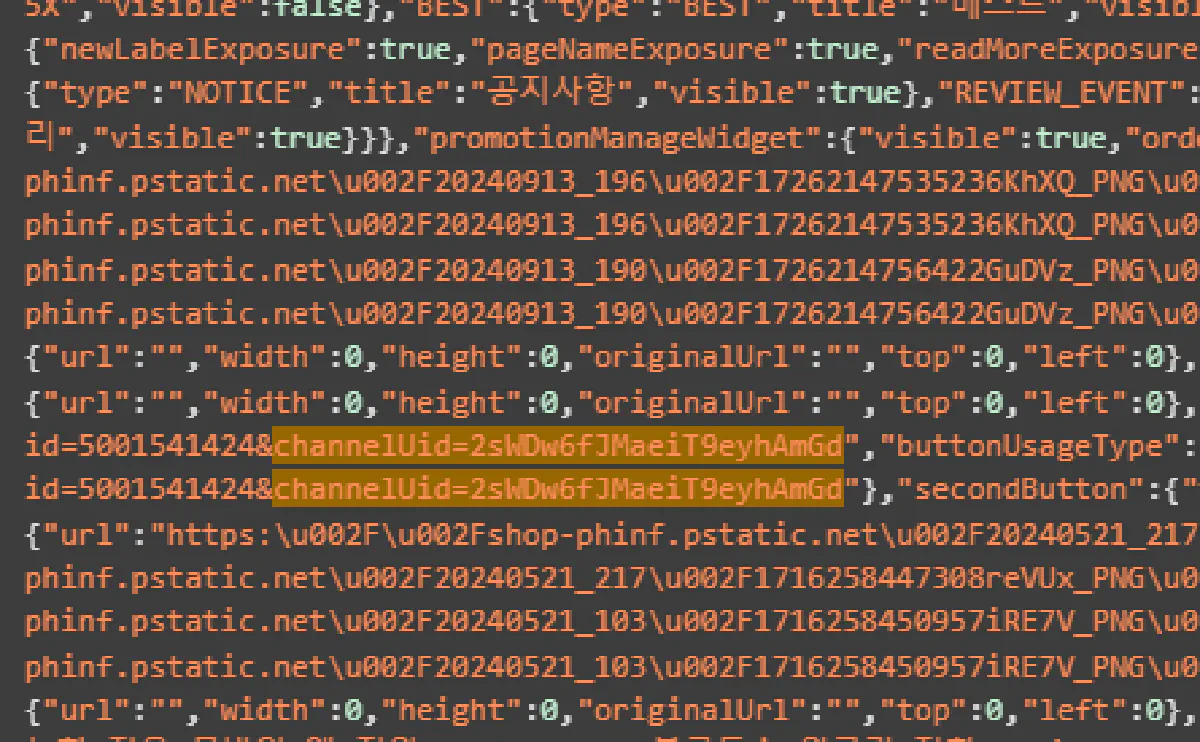
That’s the value you need.
This ID is unique to the store (in this case, SteelSeries), and it’ll stay the same across all their product pages so once you grab it, you can reuse it for as many products as you want from that seller.
Find Product ID
This one’s even easier.
Just look at the URL:
https: //brand.naver.com/steelseries/products/11800715035;11800715035 is the product ID, also referred to as productNo in Naver’s API.
No need to inspect anything. If you have the product URL, you already have the ID.
Now that we’ve got both the channelUid and productNo, let’s build the API request.
Sending the Request
We now have both pieces we need:
channelUid:2sWE13PU92zxrIFi44IbYproductNo:11800715035
These two values are all you need to hit Naver’s internal API. We’ll also append withWindow=false to skip extra UI data and get a lighter, cleaner JSON response.
Here’s how to build and send the request using Scrape.do:
import requests
import urllib.parse
# Your Scrape.do token
token = "<your_token>"
# Product identifiers
channel_uid = "2sWDw6fJMaeiT9eyhAmGd"
product_id = "11800715035"
# Naver API target - if you're scraping smartstores, change URL to smartstore.naver.com/i/...
target_url = f"https://brand.naver.com/n/v2/channels/{channel_uid}/products/{product_id}?withWindow=false"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint
api_url = f"https://api.scrape.do?token={token}&url={encoded_url}&super=true"
# Send the request
response = requests.get(api_url)
# Print response status
print(response)If everything works, you’ll see:
<Response [200]>That means Naver responded with the full product data; no HTML, no noise, just clean JSON we can work with next.
Parse and Export
Once we get a successful 200 response from Naver’s API, you'll see that the rest is easy.
Here are the 5 key fields we’ll extract:
- Product Name →
dispName - Discounted Price →
discountedSalePrice - Discount Ratio →
benefitsView.discountedRatio - Image URL →
representImage.url - Stock Quantity →
stockQuantity
Let’s print them first:
import requests
import urllib.parse
# Your Scrape.do token
token = "<your_token>"
# Product identifiers
channel_uid = "2sWDw6fJMaeiT9eyhAmGd"
product_id = "11800715035"
# Build the Naver API URL
target_url = f"https://brand.naver.com/n/v2/channels/{channel_uid}/products/{product_id}?withWindow=false"
encoded_url = urllib.parse.quote_plus(target_url)
api_url = f"https://api.scrape.do?token={token}&url={encoded_url}&super=true"
# Send the request
response = requests.get(api_url)
data = response.json()
# Extract fields
name = data["dispName"]
price = data["discountedSalePrice"]
discount = data["benefitsView"]["discountedRatio"]
image = data["representImage"]["url"]
stock = data["stockQuantity"]
# Print the results
print("Product Name:", name)
print("Price:", f"{price:,}₩")
print("Discount:", f"{discount}%")
print("Image URL:", image)
print("Stock Quantity:", stock)Here's what will print out:
Product Name: [QcK Heavy M 증정] 스틸시리즈 Arctis Nova 5 무선 게이밍 헤드셋 - 블랙 / 화이트
Price: 176,000₩
Discount: 11%
Image URL: https://shop-phinf.pstatic.net/20250507_71/1746586488548DMoJN_PNG/1170543923217933_1817156307.png
Stock Quantity: 968Now that we’ve confirmed the values are correct, let’s export them to a .csv file so we can reuse the data later or analyze it at scale.
Here’s the final version with export:
import requests
import urllib.parse
import csv
# Your Scrape.do token
token = "<your_token>"
# Product identifiers
channel_uid = "2sWDw6fJMaeiT9eyhAmGd"
product_id = "11800715035"
# Build request
target_url = f"https://brand.naver.com/n/v2/channels/{channel_uid}/products/{product_id}?withWindow=false"
encoded_url = urllib.parse.quote_plus(target_url)
api_url = f"https://api.scrape.do?token={token}&url={encoded_url}&super=true"
# Request and parse
response = requests.get(api_url)
data = response.json()
# Extract details
name = data["dispName"]
price = data["discountedSalePrice"]
discount = data["benefitsView"]["discountedRatio"]
image = data["representImage"]["url"]
stock = data["stockQuantity"]
# Export to CSV
with open("naver_product_data.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(["Product Name", "Price", "Discount", "Image URL", "Stock Quantity"])
writer.writerow([name, price, f"{discount}%", image, stock])
print("Data saved to naver_product_data.csv")You should see:
Data saved to naver_product_data.csvAnd that’s clean, reliable product data straight from Naver’s internal API.
If API Endpoint Doesn't Work
Naver doesn’t officially document their internal API and they do change it from time to time.
If your API request suddenly stops working, you’ll need to reconfirm the endpoint:
- Open the product page in Chrome
- Press
F12to open DevTools - Go to the Network tab
- Refresh the page
- In the "Filter" input, type the product ID plus
?withWindow=false
(e.g.11800715035?withWindow=false) - Click the matching request that appears
- The full Request URL will be the internal API endpoint
That’s the real URL you need to use and it may change depending on Naver’s current architecture.
If you're ever unsure, fall back to this method and rebuild your API request accordingly.
Conclusion
Naver is a tough target for search and e-commerce scraping; between geo-blocking, headless rendering traps, and a constantly shifting internal structure, most scrapers fail before they even get a 200 response.
But once you know how to get behind the front-end, literally, use the internal API, and route your requests through the right proxies, it becomes simple and repeatable.
And with Scrape.do, you don’t need to worry about:
- Proxy rotation or fingerprinting
- Session headers or TLS configs
- JavaScript rendering or CAPTCHA solving
Just send the request and get clean, fast, and unblocked access to important data.
Full Stack Developer








