Category:Scraping Use Cases
Scraping Imovelweb: How to Extract Real Estate Listings

R&D Engineer


👋 Olá!
So, you want to scrape Brazil’s top real estate platform but got stuck?
Don’t worry, we’ll do it together.
Imovelweb hosts thousands of property listings from all over Brazil, making it a goldmine for real estate data in South America. But like many major platforms, it has strong anti-scraping protections that can block automated requests.
With the right approach, though, you can bypass these restrictions and extract property details effortlessly.
Let’s get started.
Why Scraping Imovelweb Is Difficult
Imovelweb, like many real estate platforms, has multiple layers of protection designed to block bot traffic and automated data collection.
DataDome Protection
The site uses DataDome, a bot detection system that analyzes requests in real time.
It blocks scrapers by detecting patterns that don’t match typical human behavior, such as rapid requests or missing browser fingerprints.
If your scraper doesn’t execute JavaScript correctly or comes from an untrusted IP, it will likely get blocked.
Regional Access Controls
Imovelweb restricts access based on geolocation and session tracking.
Requests from non-Brazilian IP addresses may see different content or face access restrictions.
Even with local IPs, frequent requests can trigger rate limits, temporarily blocking further access, which is why you also need to rotate proxies.
How Scrape.do Bypasses These Challenges
Scrape.do ensures seamless access to Imovelweb by handling session management, JavaScript execution, and IP rotation & reputation, so your requests look like they’re coming from real users from different devices.
Instead of worrying about CAPTCHAs, IP bans, or blocked requests, Scrape.do takes care of everything for you:
✅ Brazil-based residential and ISP proxies – Ensures requests originate from trusted locations, avoiding geo-blocks.
✅ Full JavaScript rendering – Bypasses DataDome’s browser challenges automatically.
✅ Smart request rotation – Distributes traffic intelligently to avoid rate limits and bans.
With these protections in place, you can easily bypass Imovelweb. Let's give it a try ourselves:
Extracting Data from Imovelweb Without Getting Blocked
For this guide, we'll keep it simple and extract property name, square meters, and sale price from a real estate listing.
Prerequisites
Before making any requests, install the required dependencies:
pip install requests beautifulsoup4You'll also need an API key from Scrape.do, which you can get by signing up for free.
For this guide, we’ll scrape this luxury villa on Imovelweb, which is very similar to my dream house 🏡
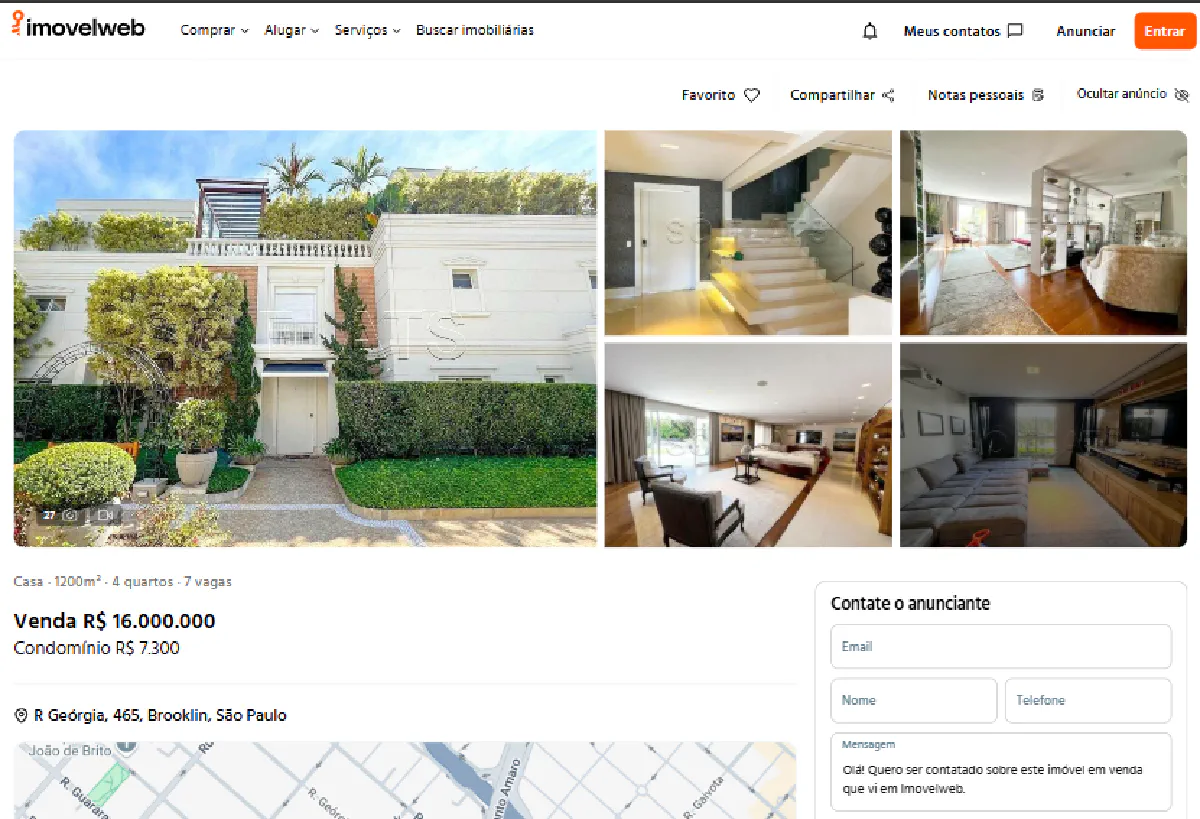
❗ There's a very high chance that when you're reading this, this property will be unlisted because it might get sold. In that case, replace the URL with something that is similar to your dream house :)
Sending a Request and Verifying Access
First, we’ll send a request through Scrape.do to ensure we can access the page without getting blocked.
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Imovelweb listing URL
target_url = urllib.parse.quote_plus("https://www.imovelweb.com.br/propriedades/casa-no-condominio-east-village-disponivel-para-venda-2986272608.html")
# Optional parameters
render = "true"
geo_code = "br"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Print response status
print(response)Here's what the output should look like:
<Response [200]>If the request is successful, we can proceed with customizing our request so that it extracts data we need.
💡 If at this point you're getting any response other than 200 OK, check your Scrape.do token to see if it's inputted correctly.
If it all looks good, the website might've added an additional layer of security. Add &super=true to the end of your API request to enable Residential and Mobile proxies which are way less likely to get blocked.
Extracting the Property Name
With a successful request, we can now extract the property name from the listing page.
The name is stored inside an <h1> tag, making it easy to locate using BeautifulSoup.
from bs4 import BeautifulSoup
import requests
import urllib.parse
import re
# Our token provided by Scrape.do
token = "<your_token>"
# Target Imovelweb listing URL
target_url = urllib.parse.quote_plus("https://www.imovelweb.com.br/propriedades/casa-no-condominio-east-village-disponivel-para-venda-2986272608.html")
# Optional parameters
render = "true"
geo_code = "br"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract listing name
listing_name = soup.find("h1").text.strip()
print("Listing Name:", listing_name)This should print out:
Listing Name: Casa no Condominio East Village disponível para vendaExtracting the Square Meters
Now that we’ve successfully extracted the property name, the next piece of information we need is the square meters of the listing.
Unlike the name, which is stored inside an <h1> tag making our job easy, the square meter value is embedded inside an <h2> with the class "title-type-sup-property".
The challenge here is that this text contains more than just the number. It includes extra words and symbols, meaning we can’t simply extract the full content. Instead, we need to isolate just the numeric value before "m²".
This is where regular expressions (re) come in. Instead of extracting everything, we’ll use a pattern that looks for:
- A number (
\d+) - That appears right before "m²"
This allows us to grab the exact value we need without any extra text.
<----- Previous section until the Print command ----->
# Extract square meters from title-type-sup-property
title_content = soup.find("h2", class_="title-type-sup-property").text.strip()
square_meters = re.search(r"(\d+)\s*m²", title_content).group(1)
print("Listing Name:", listing_name)
print("Square Meters:", square_meters)With this, we’ve filtered out unnecessary words and kept only the number before "m²" so it looks clean.
The output should look like this:
Listing Name: Casa no Condominio East Village disponível para venda
Square Meters: 1200Extracting the Sale Price
The price is inside a <div> tag with the class "price-value", but it sometimes contains extra words like "venda", which we don’t need.
Instead of extracting everything, we'll make use of regular expressions (re) again to grab only the currency symbol (R$) followed by numbers, ensuring we capture the price without unnecessary text.
After adding the price extraction code, here's what the final code should look like:
from bs4 import BeautifulSoup
import requests
import urllib.parse
import re
# Our token provided by Scrape.do
token = "<your_token>"
# Target Imovelweb listing URL
target_url = urllib.parse.quote_plus("https://www.imovelweb.com.br/propriedades/casa-no-condominio-east-village-disponivel-para-venda-2986272608.html")
# Optional parameters
render = "true"
geo_code = "br"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract listing name
listing_name = soup.find("h1").text.strip()
# Extract square meters from title-type-sup-property
title_content = soup.find("h2", class_="title-type-sup-property").text.strip()
square_meters = re.search(r"(\d+)\s*m²", title_content).group(1)
# Extract sale price and remove unwanted words
price_text = " ".join(soup.find("div", class_="price-value").stripped_strings)
price = re.search(r"R\$\s*[\d.,]+", price_text).group(0)
print("Listing Name:", listing_name)
print("Square Meters:", square_meters)
print("Sale Price:", price)And the output should look like this:
Listing Name: Casa no Condominio East Village disponível para venda
Square Meters: 1200
Sale Price: R$ 16.000.000That’s it. You've successfully scraped Imovelweb!
Conclusion
Scraping Imovelweb comes with challenges like DataDome protection and regional access controls, but with Scrape.do, these obstacles are bypassed automatically.
We successfully extracted the property name, square meters, and sale price without getting blocked by using geo-targeted IPs, session management, and JavaScript rendering.
Need to scrape Imovelweb?
Scrape.do makes it effortless.
R&D Engineer








