Category:Scraping Use Cases
Scraping Idealista: Extract Region Listings and Property Data with Python

Full Stack Developer



Idealista is one of the most heavily protected websites I’ve seen in my scraping career.
DataDome WAF, geo-restrictions, and relentless CAPTCHA loops at every step make even basic property scraping a serious challenge.
But if you’re working on real estate data for Spain or Portugal, you need Idealista’s listings. There’s no way around it.
In this guide, I’ll show you how to scrape property details and region listings reliably, even if you’ve been blocked at every attempt so far.
Find fully-functioning code on this GitHub repo. ⚙
Why Is Scraping Idealista Difficult?
Idealista’s website isn’t just “protected.” It’s a fortress.
If you try to scrape listings without a solid anti-bot strategy, you’ll hit walls very quickly.
In the next sections, we’ll walk through each of these challenges and how they work under the hood:
Heavy DataDome Protection
DataDome is one of the most aggressive anti-bot solutions you’ll encounter.
It analyzes every single request in real-time, checking your:
- IP reputation and usage patterns
- TLS and SSL fingerprint consistency
- JavaScript behavior and browser quirks
- Request velocity and header authenticity
Even if you rotate IPs and headers, DataDome will catch anomalies in milliseconds.
This is what you’ll see when Idealista detects your scraping attempt:

Once this block appears, your IP is flagged, and you’re locked out.
Switching IPs will only get you a few more requests before the cycle repeats.
Geo-Restrictions
Even if you bypass DataDome’s initial blocks, Idealista still won’t give you full access unless your IP matches the region you’re targeting.
For example:
Trying to scrape Spanish listings with a non-Spanish IP?
Blocked.
Accessing Italian property pages from outside Italy?
Blocked.
Rotating datacenter proxies?
Blocked faster than you can refresh the page.
Idealista cross-checks your IP’s location with the page you’re trying to view. If they don’t align, you’re either shown an empty page or silently redirected.
This is why residential proxies with accurate geo-targeting are non-negotiable when scraping Idealista. You need to look like a local user from the very first request.
Back-to-Back CAPTCHAs and Challenges
Let’s say you’ve bypassed DataDome and passed the geo-restriction filter.
You’re still not safe.
Idealista uses sliding puzzle CAPTCHAs and device fingerprint verification screens that trigger even on normal browsing speeds.
Here’s an example of their device verification loop:
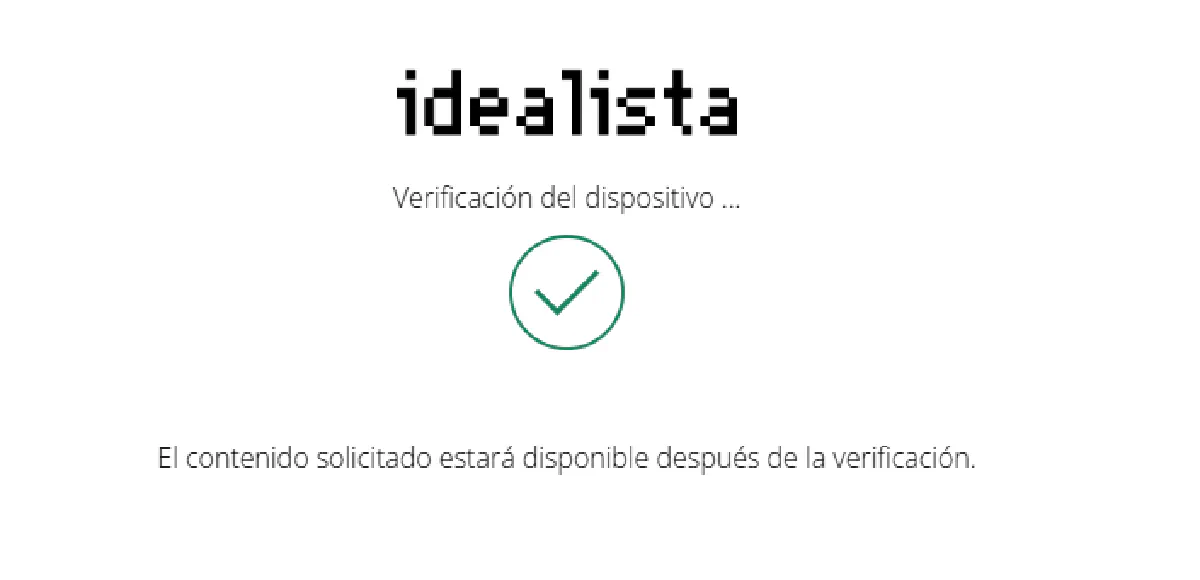
But even if you solve it, Idealista doesn’t trust you yet.
You’ll immediately be hit with a puzzle CAPTCHA like this:
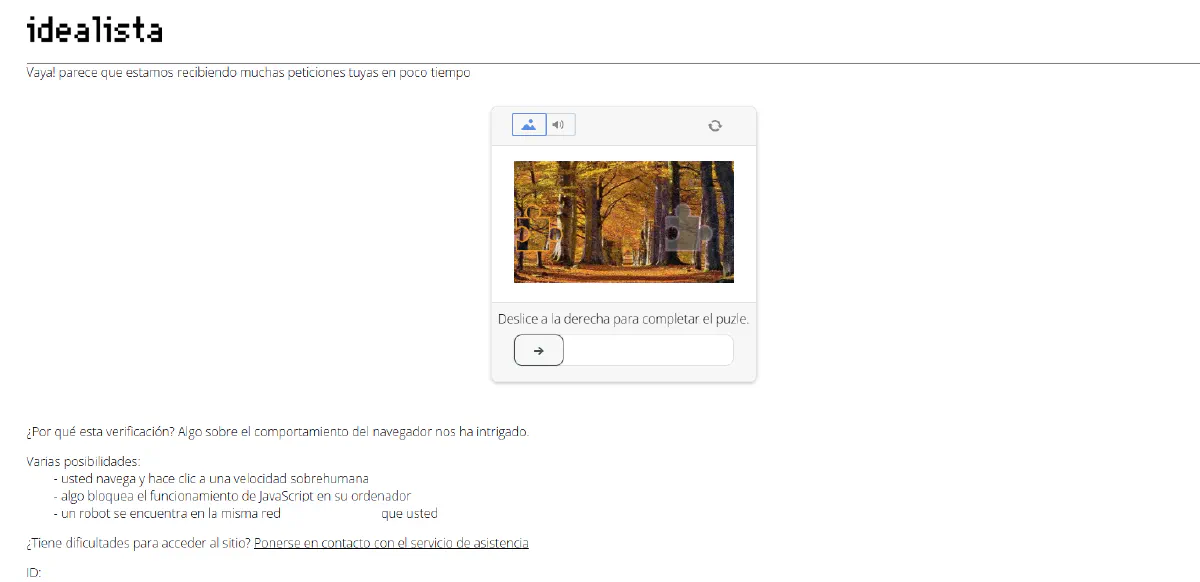
The moment your browsing behavior looks automated (even slightly), you’ll be thrown back into a CAPTCHA or blocked entirely.
This is why scraping Idealista requires real browser simulation (headers, TLS fingerprints, session cookies) and sticky sessions to maintain browser context between requests.
How Scrape.do Solves These Challenges
Scraping Idealista manually is a constant battle.
But with Scrape.do, you bypass these protections automatically without juggling proxies, CAPTCHAs, or browser setups yourself.
Here’s how:
- 🔑 Bypasses DataDome instantly with dynamic TLS fingerprinting and real browser simulation.
- 🌎 Routes requests through geo-targeted residential proxies (Spain, Italy, Portugal) to avoid region blocks.
- 🤖 Handles CAPTCHAs and verification loops by rotating sessions and using premium proxy retries until a clean response is received.
- 💬 Developer-level support to debug and solve scraping issues in real-time.
Scrape.do handles the heavy lifting while you focus on collecting data.
Scrape Property Listing from Idealista
Heart of Idealista lies in individual product listings that have tons of details about the properties, so that's where we'll start.
We'll scrape this modern penthouse listing:
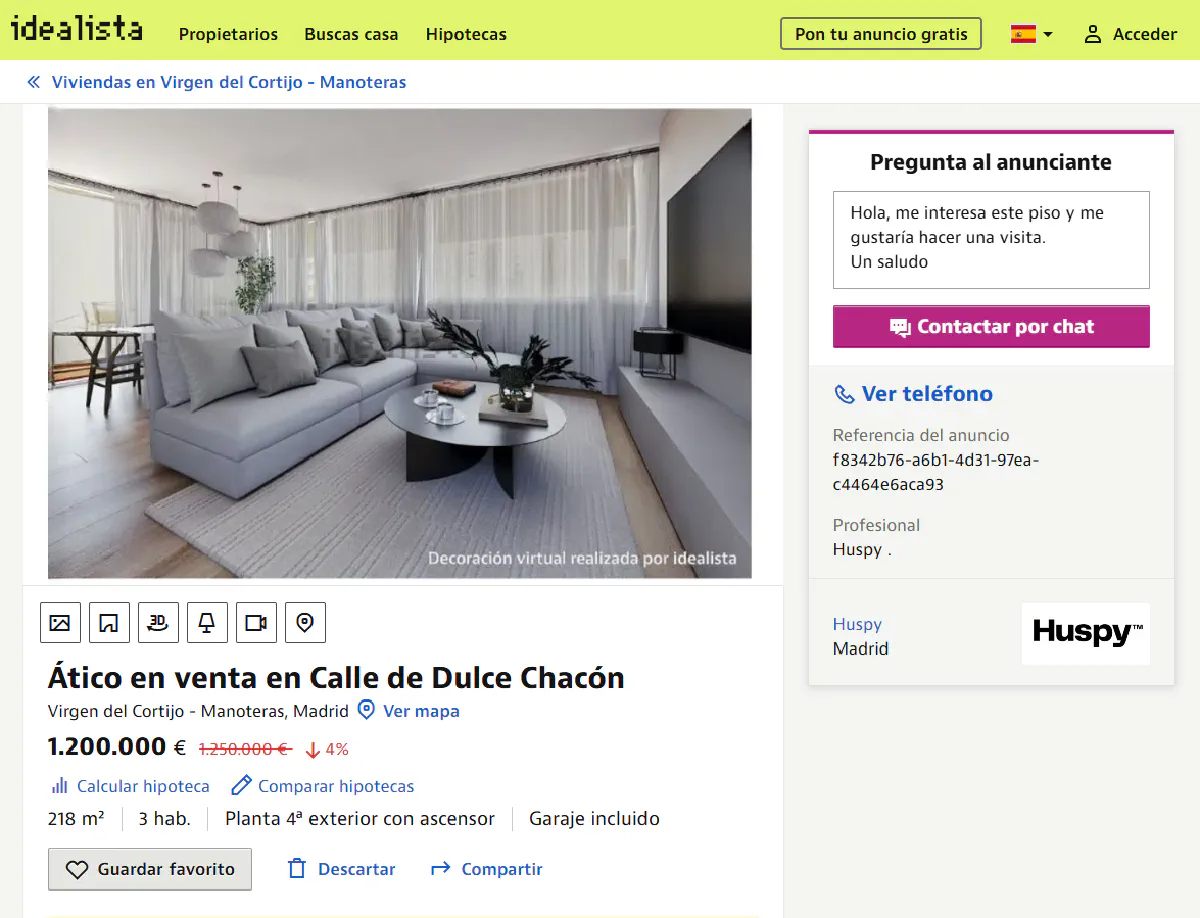
The listing above might have been sold by the time you're reading this article. No worries, pick a new target and keep going 👊🏻
Setup and Sending Request
First, we need to send a request to an Idealista property page, but not directly.
If you try with a normal HTTP request, you’ll get blocked in seconds.
Instead, we’ll route it through Scrape.do’s API, which will handle geo-restrictions, rotate proxies, and return a fully rendered page that’s ready to parse.
Sign up to Scrape.do and get your FREE API token from here:
Replace token placeholder below and we're off to a start:
from bs4 import BeautifulSoup
import requests
import urllib.parse
token = "<your_token>"
target_url = urllib.parse.quote_plus("https://www.idealista.com/inmueble/107795847/")
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode=es&render=true&super=true"
response = requests.request("GET", url)
soup = BeautifulSoup(response.text, "html.parser")We’re using geoCode=es to make sure the request originates from Spain. The super=true flag enables Scrape.do’s advanced anti-bot bypass mode, and render=true ensures the page is rendered in a real browser before we parse it.
Once the request is successful, the entire page is loaded into the soup object, and we’re ready to extract property data.
Extract Title (Property Type, Deal Status, Location)
Once we’ve parsed the HTML with BeautifulSoup, the first thing we need is the property title.
Idealista places the main title inside a span with the class main-info__title-main. This usually holds both the property type and deal status in a single string like “Piso en venta.”
Yes, we're scraping pages in the Native form, Spanish. Getting 404 when sending requests through EN language is pretty common, if you want to convert your data to English, you can edit the code to add a library for property types etc.
Let’s locate that element and extract its text:
title = soup.find("span", class_="main-info__title-main").text.strip()The title is a single sentence, but we want to split it into two parts:
- Property Type (e.g., Piso, Chalet, Apartamento)
- Deal Status (e.g., en venta, en alquiler)
We can achieve this by splitting the title string at the “ en ” separator:
title_parts = title.split(" en ")
property_type = title_parts[0].strip()
for_status = "en " + title_parts[1].strip() if len(title_parts) > 1 else ""Next, we’ll grab the location, which Idealista places in a smaller subtitle span with the class main-info__title-minor. This span typically contains both the neighborhood and city, separated by a comma.
Let’s extract and split it:
location = soup.find("span", class_="main-info__title-minor").text.strip()
neighborhood, city = location.split(", ")Not over yet, we need a whole a lot more data to be done:
Extract Price and Apartment Details
We'll fetch the price, square size, and bedroom count.
The price is located inside a span with the class info-data-price. We can extract it like this:
price = soup.find("span", class_="info-data-price").text.strip()Apartment details like square size and bedroom count are found in a container div with the class info-features.
This section contains multiple span elements, each representing a different property attribute.
We’ll first locate the container:
info_features = soup.find("div", class_="info-features")Then, we’ll get all the immediate child span elements inside it:
feature_spans = info_features.find_all("span", recursive=False)Idealista often follows a consistent order:
- First span → Square size (e.g., “85 m²”)
- Second span → Bedroom count (e.g., “2 habitaciones”)
So we can extract them like this:
square_size = feature_spans[0].text.strip() if len(feature_spans) > 0 else ""
bedroom_count = feature_spans[1].text.strip() if len(feature_spans) > 1 else ""Extract Full Address
Idealista provides a more detailed address under the “Ubicación” section on the listing page.
This section is marked by an h2 tag with the text “Ubicación” and is followed by a list (ul) containing several li elements that represent different parts of the address (street, district, city, etc.).
To extract the full address, we first locate the Ubicación header:
ubicacion_h2 = soup.find("h2", class_="ide-box-detail-h2", string="Ubicación")If this section exists, we look for the following ul element, which holds the address details:
if ubicacion_h2:
ul_element = ubicacion_h2.find_next("ul")Within this list, each address component is inside a li with the class header-map-list. We can loop through these items and collect their text:
if ul_element:
address_parts = []
for li in ul_element.find_all("li", class_="header-map-list"):
address_parts.append(li.text.strip())
full_address = ", ".join(address_parts)
else:
full_address = ""
else:
full_address = ""This gives us a clean, comma-separated string containing the complete address; street, district, city, and province.
Last Updated Date and Advertiser
Two more important details to capture from the listing are:
- When was this property last updated?
- Who is the advertiser (agency or individual)?
Let’s start with the last updated date.
Idealista shows a small paragraph with the class date-update-text indicating how many days ago the listing was updated.
We can find it like this:
date_update_text = soup.find("p", class_="date-update-text")If this element exists, we extract its text and use a regular expression to find the number of days:
if date_update_text:
update_text = date_update_text.text.strip()
days_match = re.search(r'hace (\d+) días?', update_text)
last_updated_days = days_match.group(1) if days_match else ""
else:
last_updated_days = ""Next advertiser’s name.
Idealista places the advertiser (usually an agency or property owner) inside an a tag with the class about-advertiser-name:
advertiser_name_element = soup.find("a", class_="about-advertiser-name")
advertiser_name = advertiser_name_element.text.strip() if advertiser_name_element else ""And that was the final field we needed.
Let's put it together:
Full Code & Output
Below is the complete code that prints every field we parsed just now.
It will extract structured property data from an Idealista listing and return it in clean variables you can use.
from bs4 import BeautifulSoup
import requests
import urllib.parse
import re
# Our token provided by Scrape.do
token = "<your_token>"
# Target Idealista listing URL
target_url = urllib.parse.quote_plus("https://www.idealista.com/inmueble/107795847/")
# Optional parameters
render = "true"
geo_code = "es"
super_mode = "true"
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={target_url}&geoCode={geo_code}&render={render}&super={super_mode}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract property title
title = soup.find("span", class_="main-info__title-main").text.strip()
# Parse property title to extract type and for status
title_parts = title.split(" en ")
property_type = title_parts[0].strip()
for_status = "en " + title_parts[1].strip() if len(title_parts) > 1 else ""
# Extract location and split into neighborhood and city
location = soup.find("span", class_="main-info__title-minor").text.strip()
neighborhood, city = location.split(", ")
# Extract property price
price = soup.find("span", class_="info-data-price").text.strip()
# Extract square size and bedroom count from info-features
info_features = soup.find("div", class_="info-features")
feature_spans = info_features.find_all("span", recursive=False)
square_size = feature_spans[0].text.strip() if len(feature_spans) > 0 else ""
bedroom_count = feature_spans[1].text.strip() if len(feature_spans) > 1 else ""
# Extract full address from location section
ubicacion_h2 = soup.find("h2", class_="ide-box-detail-h2", string="Ubicación")
if ubicacion_h2:
ul_element = ubicacion_h2.find_next("ul")
if ul_element:
address_parts = []
for li in ul_element.find_all("li", class_="header-map-list"):
address_parts.append(li.text.strip())
full_address = ", ".join(address_parts)
else:
full_address = ""
else:
full_address = ""
# Extract last updated days
date_update_text = soup.find("p", class_="date-update-text")
if date_update_text:
update_text = date_update_text.text.strip()
days_match = re.search(r'hace (\d+) días?', update_text)
last_updated_days = days_match.group(1) if days_match else ""
else:
last_updated_days = ""
# Extract advertiser name
advertiser_name_element = soup.find("a", class_="about-advertiser-name")
advertiser_name = advertiser_name_element.text.strip() if advertiser_name_element else ""
# Print extracted data
print("Property Type:", property_type)
print("For:", for_status)
print("Square Size:", square_size)
print("Bedroom Count:", bedroom_count)
print("Neighborhood:", neighborhood)
print("City:", city)
print("Full Address:", full_address)
print("Last Updated Days:", last_updated_days)
print("Advertiser Name:", advertiser_name)
print("Price:", price)And this is the output we're printing:
Property Type: Ático
For: en venta
Square Size: 218 m²
Bedroom Count: 3 hab.
Neighborhood: Virgen del Cortijo - Manoteras
City: Madrid
Full Address: Calle de Dulce Chacón, Barrio Virgen del Cortijo - Manoteras, Distrito Hortaleza, Madrid, Madrid capital, Madrid
Last Updated Days: 21
Advertiser Name: Huspy
Price: 1.200.000 €From here, you can store the data into a database, export it to CSV, or expand the scraper to loop through multiple listings.
Scrape Phone Numbers from Listings
⚠️ Phone numbers are considered personal data under GDPR, and is strictly prohibited from being used for business usage or public sharing. It can only be allowed for purely personal usage or household activity, so unless you're scraping for a personal non-commercial project, don't extract phone numbers at scale.
This one is a more personal challenge.
After the previous section the only crucial information left on a listing page is the phone number, which is hidden behind a button click.
Although this data can't be used in large-scale scraping projects, I'll use Scrape.do and its playWithBrowser functionality to click and export the phone number.
First let me explain how we're interacting with Idealista to reveal the phone number:
# Import required libraries as usual
import requests
import json
import urllib.parse
from bs4 import BeautifulSoup
# Input token and target URL
TOKEN = "<your-token>"
TARGET_URL = "https://www.idealista.com/inmueble/108889120/"
# playWithBrowser actions, what we're doing is:
# 1. Start at the Idealista homepage
# 2. Click on Cookie agree button to free up our clicking function
# 3. Navigate to the TARGET_URL
# 4. Click the phone number reveal button and wait
play_with_browser = [
{
"action": "WaitSelector",
"timeout": 30000,
"waitSelector": "#didomi-notice-agree-button"
},
{
"action": "Click",
"selector": "#didomi-notice-agree-button"
},
{
"action": "Wait",
"timeout": 2000
},
{
"action": "Execute",
"execute": f"location.href='{TARGET_URL}'"
},
{
"action": "WaitSelector",
"timeout": 30000,
"waitSelector": ".see-phones-btn"
},
{
"action": "Click",
"selector": ".see-phones-btn:not(.show-phone):not(.loading) .hidden-contact-phones_text"
},
{
"Action": "WaitForRequestCompletion",
"UrlPattern": "*example.com/image*",
"Timeout": 10000
},
{
"action": "Wait",
"timeout": 1000
}
]
# Parse playWithBrowser actions, Important!
jsonData = urllib.parse.quote_plus(json.dumps(play_with_browser))Once that's done, we build the API call, we're using a quite few parameters but they're all needed to improve success rates:
api_url = (
"https://api.scrape.do/?"
f"url={urllib.parse.quote_plus('https://www.idealista.com/')}"
f"&token={TOKEN}"
f"&super=true"
f"&render=true"
f"&returnJSON=true"
f"&blockResources=false"
f"&playWithBrowser={jsonData}"
f"&geoCode=es"
)
response = requests.get(api_url)After that, let's scrape title and price too, for the phone number to mean something:
# Parse JSON response
json_map = json.loads(response.text)
# Parse HTML content
soup = BeautifulSoup(json_map.get("content", ""), "html.parser")
# Extract property title
title_element = soup.find("span", class_="main-info__title-main")
property_title = title_element.text.strip() if title_element else "Not found"
# Extract price
price_element = soup.find("span", class_="info-data-price")
price = price_element.text.strip() if price_element else "Not found"Phone number can be a bit buggy, so I have a fallback method that will also check a related selector:
# Extract phone number - try tel: links first, then text spans
phone_number = "Not found"
for link in soup.find_all("a", href=True):
href = link.get("href", "")
if href.startswith("tel:+34"):
phone_number = href.replace("tel:", "")
break
if phone_number == "Not found":
for span in soup.find_all("span", class_="hidden-contact-phones_text"):
text = span.text.strip()
if any(char.isdigit() for char in text) and len(text.replace(" ", "")) >= 9:
phone_number = text
breakOnly thing left is to print:
print(f"Property Title: {property_title}")
print(f"Price: {price}")
print(f"Phone Number: {phone_number}")Once your request is successful, here's what your output should look like:
Property Title: Casa o chalet independiente en venta en Carretera de la Costa s/n
Price: 390.000 €
Phone Number: +34[REDACTED]You can also extract multiple phone numbers from a region search, but at that scale you're more likely to fail and certainly breaching GDPR.
Scrape Regional Listings or Search Results from Idealista
Scraping a single property page is great for detailed data.
But if you need hundreds of listings from a search result or region page, you’ll have to deal with pagination, dynamic URLs, and Idealista’s anti-bot traps across multiple pages.
In this section, we’ll build a scraper that loops through every page of a search result and extracts structured data (title, price, location, etc.) for each property, no matter how many pages there are.
I'm picking a region in Santa Cruz De Tenerife as my target listings page.
⚠ WARNING: Some regions, even though you can view them in your browser, might end up returning 404 response to your scrapers. You need to either A) pick a more specific/smaller region and work in chunks or B) draw the region you want in the Idealista website and use the URL of your selection to scrape.
Looping Through All Pages (Until No More Listings)
Unlike a property detail page, Idealista’s search result pages are paginated and dynamically structured.
Each page shows 30 listings, and to scrape them all, we need to build a loop that:
- Starts from page 1.
- Follows Idealista’s pagination URL pattern.
- Stops when no more listings are found.
Here’s how we set it up:
from bs4 import BeautifulSoup
import requests
import urllib.parse
import csv
# Your Scrape.do API token
token = "<your_token>"
# Base URL of the Idealista search results (page 1)
base_url = "https://www.idealista.com/venta-viviendas/santa-cruz-de-tenerife/la-palma/con-chalets/"
# Scrape.do parameters
render = "true"
geo_code = "es"
super_mode = "true"
# Initialize data storage
all_properties = []
page = 1We’ll now loop through each page until we reach a page with no listings:
while True:
# Build the URL for the current page.
# Idealista uses "pagina-2.htm", "pagina-3.htm", etc. for pagination.
if page == 1:
current_url = base_url
else:
current_url = base_url + f"pagina-{page}.htm"
print(f"Scraping page {page}...")
# Encode the URL and send the request via Scrape.do
url = f"https://api.scrape.do/?token={token}&url={urllib.parse.quote_plus(current_url)}&geoCode={geo_code}&render={render}&super={super_mode}"
response = requests.request("GET", url)
# Parse the returned HTML
soup = BeautifulSoup(response.text, "html.parser")
# Find all listings on the current page
listings = soup.find_all("article", class_="item")
# If no listings are found, we've reached the end of pagination
if not listings:
print(f"No more listings found on page {page}. Stopping.")
break
# Otherwise, we’ll process these listings in the next step
print(f"Found {len(listings)} listings on page {page}")
page += 1We’re constructing each paginated URL based on Idealista’s pattern and every request goes through Scrape.do with full rendering and anti-bot protections until there are no more listings.
Now to parse all the information:
Extracting Property Type, Price, Area, Location, and More
Each listing on Idealista results pages is structured inside an <article> element with the class item.
Within that element, you’ll find the property’s price, title, bedrooms, square meters, and link.
Let’s parse these details, we're manipulating the property title like we did in previous section:
for listing in listings:
# Extract property price
price_element = listing.find("span", class_="item-price")
price = price_element.text.strip() if price_element else ""
# Extract the property title
title_element = listing.find("a", class_="item-link")
if title_element:
title = title_element.text.strip()
# Parse title into property type and location (e.g., "Chalet en venta")
title_parts = title.split(" en ")
property_type = title_parts[0].strip()
location = title_parts[1].strip() if len(title_parts) > 1 else ""
# Build the full listing URL
listing_url = "https://www.idealista.com" + title_element.get("href", "")
else:
title = property_type = location = listing_url = ""Let's also extract bedroom count and square meters from the listing’s detail spans:
details = listing.find_all("span", class_="item-detail")
bedroom_count = ""
square_meters = ""
for detail in details:
text = detail.text.strip()
if "hab." in text:
bedroom_count = text
elif "m²" in text:
square_meters = textOnce we have all these fields, we can store them into our data list for later export:
all_properties.append({
"Price": price,
"Property Type": property_type,
"Location": location,
"Bedrooms": bedroom_count,
"Square Meters": square_meters,
"URL": listing_url
})This loop will run for every listing on every page, building a clean dataset as it goes.
Save and Export to CSV
After scraping all listings and compiling their details into all_properties, the final step is to save everything into a structured CSV file.
We’ll use Python’s built-in csv module to write the data.
Here's the full-working code with the CSV writing section added:
from bs4 import BeautifulSoup
import requests
import urllib.parse
import csv
# Our token provided by Scrape.do
token = "<your_token>"
# Target Idealista search URL
base_url = "https://www.idealista.com/venta-viviendas/santa-cruz-de-tenerife/la-palma/con-chalets/"
# Optional parameters
render = "true"
geo_code = "es"
super_mode = "true"
# Initialize data storage
all_properties = []
page = 1
while True:
# Construct URL for current page
if page == 1:
current_url = base_url
else:
current_url = base_url + f"pagina-{page}.htm"
print(f"Scraping page {page}...")
# Scrape.do API endpoint
url = f"https://api.scrape.do/?token={token}&url={urllib.parse.quote_plus(current_url)}&geoCode={geo_code}&render={render}&super={super_mode}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Find all property listings
listings = soup.find_all("article", class_="item")
# If no listings found, we've reached the end
if not listings:
print(f"No more listings found on page {page}. Stopping.")
break
for listing in listings:
# Extract property price
price_element = listing.find("span", class_="item-price")
price = price_element.text.strip() if price_element else ""
# Extract property title and parse type + location
title_element = listing.find("a", class_="item-link")
if title_element:
title = title_element.text.strip()
title_parts = title.split(" en ")
property_type = title_parts[0].strip()
location = title_parts[1].strip() if len(title_parts) > 1 else ""
# Extract listing URL
listing_url = "https://www.idealista.com" + title_element.get("href", "")
else:
title = property_type = location = listing_url = ""
# Extract bedroom count and square meters
details = listing.find_all("span", class_="item-detail")
bedroom_count = ""
square_meters = ""
for detail in details:
text = detail.text.strip()
if "hab." in text:
bedroom_count = text
elif "m²" in text:
square_meters = text
# Store property data
all_properties.append({
"Price": price,
"Property Type": property_type,
"Location": location,
"Bedrooms": bedroom_count,
"Square Meters": square_meters,
"URL": listing_url
})
print(f"Found {len(listings)} listings on page {page}")
page += 1
# Save extracted data to CSV
with open("idealista_properties.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["Price", "Property Type", "Location", "Bedrooms", "Square Meters", "URL"])
writer.writeheader()
writer.writerows(all_properties)
print(f"\nScraping complete! Found {len(all_properties)} total properties.")
print("Data saved to idealista_properties.csv")You'll see this in your terminal:
Scraping page 1...
Found 30 listings on page 1
Scraping page 2...
Found 30 listings on page 2
Scraping page 3...
<--- omitted --->
Scraping page 10...
No more listings found on page 10. Stopping.
Scraping complete! Found 270 total properties.
Data saved to idealista_properties.csvAnd this is what your output CSV will look like:
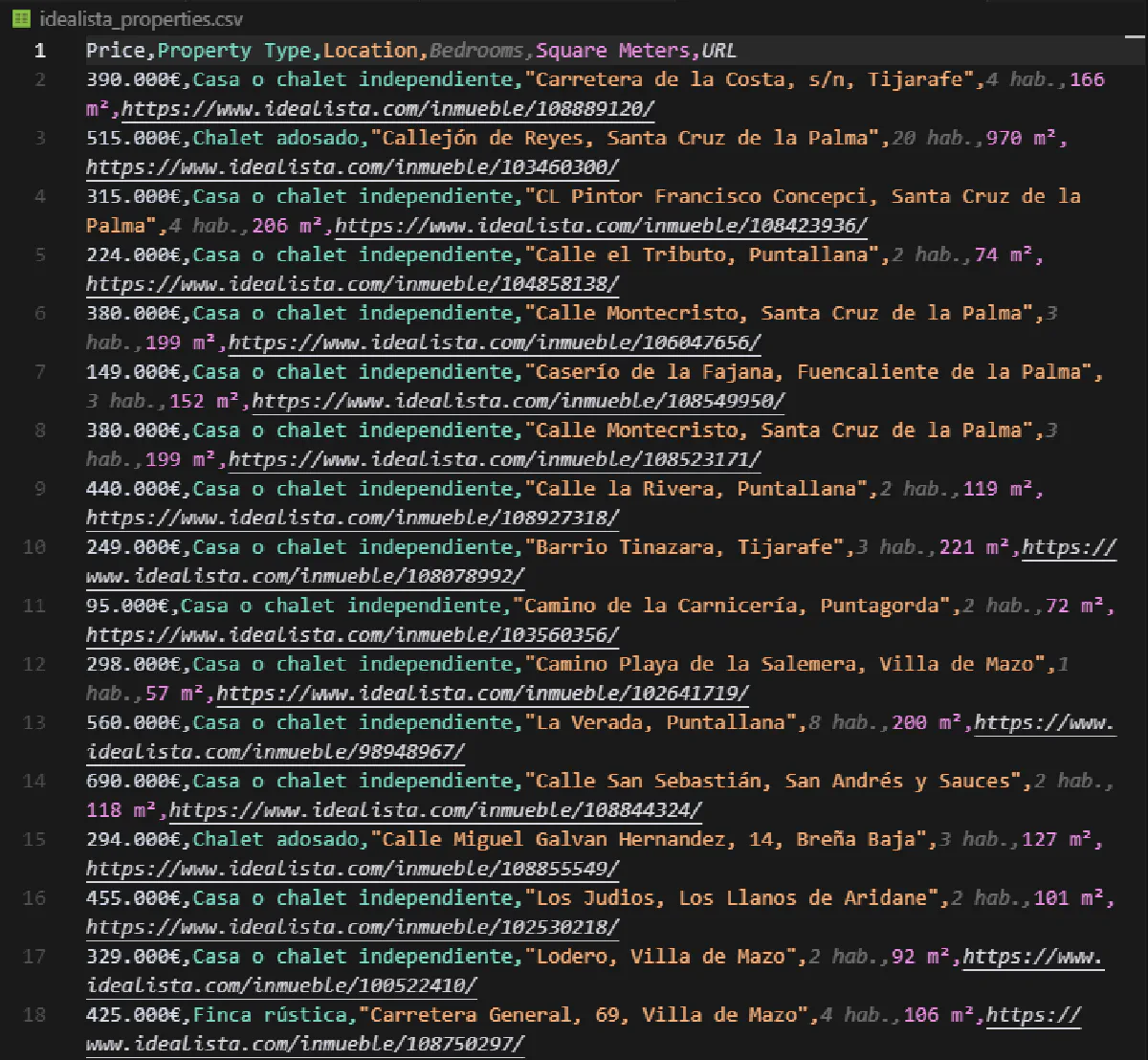
You're now able to scrape all data from Idealista!
Conclusion
Scraping Idealista is tough; CAPTCHAs, WAFs, geo-blocks, you name it.
But with the right approach, and Scrape.do handling the heavy lifting, you can extract property data at scale without getting blocked.
- Bypass DataDome and CAPTCHA loops
- Use real residential IPs for any region
- Only pay for successful requests
Full Stack Developer








