Category:Scraping Basics
Before You Scrape: How to Check If a Website Allows Scraping

Full Stack Developer



Is all public data up for grabs for scrapers?
Not exactly.
There are rules, subtle signals, and legal nuances you need to decipher before you start.
In this guide, we'll break down how to read robots.txt, inspect ToS, and spot anti-bot measures with clear, no-nonsense steps.
Welcome to the world of smart, safe, and on-the-good-side-of-the-law web scraping.
Do You Really Need to Check If a Website Allows Scraping?
If the data is public, why bother checking?
Can’t you just start scraping?
Here’s the thing; just because data is visible doesn’t mean a website wants you collecting it automatically.
Some websites explicitly state in their robots.txt or Terms of Service (ToS) that scraping isn’t allowed. Others don’t say a word but silently monitor traffic, using IP tracking, fingerprinting, or rate limits to block scrapers without warning.
Skipping the check might not get you in legal trouble as legality of web scraping is disputed, but it can get you blocked, blacklisted, or even hit with a cease-and-desist if the website decides to take action.
Major platforms like Facebook, LinkedIn, and Instagram have taken legal steps against scrapers, often relying on their ToS as a basis for lawsuits.
In the hiQ Labs v. LinkedIn case, a U.S. court ruled that scraping publicly available data isn’t a violation of the Computer Fraud and Abuse Act (CFAA)—but that didn’t stop LinkedIn from continuing to fight in court using contract-based claims from its ToS.
And that’s just one example. In the EU, scraping personal data—even if it’s public—could violate GDPR regulations if the data is used improperly. In 2022, Clearview AI was fined millions for scraping images from social media without consent. Other regions, like Brazil (LGPD) and Canada (PIPEDA), have similar privacy laws that affect web scraping practices.
So what does this mean for you?
- Be extra careful when scraping personal data. A lot of countries will surely follow EU on the GDPR regulations so personal data can turn into a minefield.
- Checking permissions isn’t just about legal risks, it’s about efficiency. A quick review can save you from getting blocked, wasting time on a site that’s aggressively anti-scraping, or missing out on an official API that provides the same data without restrictions.
- Technical barriers can be unpredictable. Some sites allow scraping but implement stealthy anti-bot systems. Others may restrict only certain pages or data types.
- A simple check keeps your scraper running longer. Avoiding IP bans, fingerprinting, or honeypot traps can mean the difference between an efficient project and a constant game of cat and mouse.
Bottom line?
A few minutes of checking saves you from wasted effort, unexpected blocks, and unnecessary risks. Let’s go over exactly how to do it.
Why Checking Scraping Permissions Matters (and What Can Happen If You Don’t)
Scraping is easy until you hit a roadblock. 🛑
Maybe the site suddenly blocks your IP.
Maybe your scraper stops returning data because key content is hidden behind JavaScript.
Or maybe, worst case, you get an email from the website’s legal team telling you to stop immediately.
That’s why checking permissions upfront matters.
It’s not just about ethics. It’s about avoiding wasted effort, unnecessary risks, and legal headaches.
1. Scraping Without Checking Can Get You Blocked Instantly
Websites don’t always explicitly say “no scraping,” but that doesn’t mean they allow it.
Many use automated detection systems to monitor traffic and block anything that looks like a bot. Some common defenses include:
- Rate Limiting: If your scraper makes too many requests too fast, you’ll hit an HTTP 429 (Too Many Requests) error.
- IP Blacklisting: Some sites detect scrapers by tracking requests from data center IPs and banning them permanently.
- JavaScript Rendering Traps: Pages that look static may load key data dynamically, forcing scrapers to use headless browsers or API workarounds.
- CAPTCHAs & Fingerprinting: Even if your scraper gets through, aggressive anti-bot measures like Cloudflare’s Turnstile or fingerprint tracking might cut you off.
A simple robots.txt check or a few manual requests can save you from running a scraper that will get blocked after just a few attempts.
2. Some Websites Will Take Legal Action Against Scrapers
Think legal threats are rare?
Big platforms have gone after scrapers before and won.
- Facebook & LinkedIn have aggressively pursued web scrapers, often citing their Terms of Service as the legal foundation for takedowns.
- In the hiQ Labs v. LinkedIn case, the court ruled that scraping public data wasn’t a CFAA violation, but LinkedIn kept fighting the case using breach-of-contract claims from their ToS.
- In Europe, scraping personal data (even if public) without user consent can violate GDPR. Companies like Clearview AI have been fined for mass data collection.
- Many websites now include anti-scraping clauses in their ToS, which means even if you don’t break a law, you could be violating a contract—potentially leading to a lawsuit.
While most scrapers won’t get sued, companies can and do send cease-and-desist letters, request takedowns, or even pursue legal action in extreme cases.
3. Checking Can Save You Time (and Show You a Better Alternative)
Not every website is anti-scraping.
Some offer official APIs that provide the same data in a structured format, with fewer risks and faster access.
- Twitter (X), Reddit, and Instagram have all limited scraping but offer API access (even if some require payment).
- E-commerce sites like Amazon or eBay provide API access to product data, eliminating the need for direct HTML scraping.
- Some sites actively welcome scrapers as long as they follow rate limits and request rules outlined in their robots.txt.
Checking before you scrape isn’t just about avoiding blocks, it’s about finding the most efficient, risk-free way to get the data you need.
How to Check If a Website Allows Scraping
Some websites make it clear whether they allow scraping. Others? Not so much.
You won’t always get a straight answer, but there are ways to find out. Some methods give you clear evidence—like robots.txt, Terms of Service (ToS), and API availability—that directly tell you if scraping is allowed. Others require detecting hidden anti-bot measures, which we’ll get into later.
Let’s start with the definitive signals that reveal whether a website welcomes, tolerates, or outright forbids scrapers.
A. Methods That Provide Clear Evidence
A.1. Checking the Robots.txt File
The first stop for any scraper should be robots.txt. It’s a simple text file that tells search engines and bots which parts of a website they’re allowed to access. While it’s not legally binding, it’s a strong indicator of the website’s scraping policy.
To check, visit https://www.amazon.com/robots.txt. You’ll see a list of rules that look something like this:
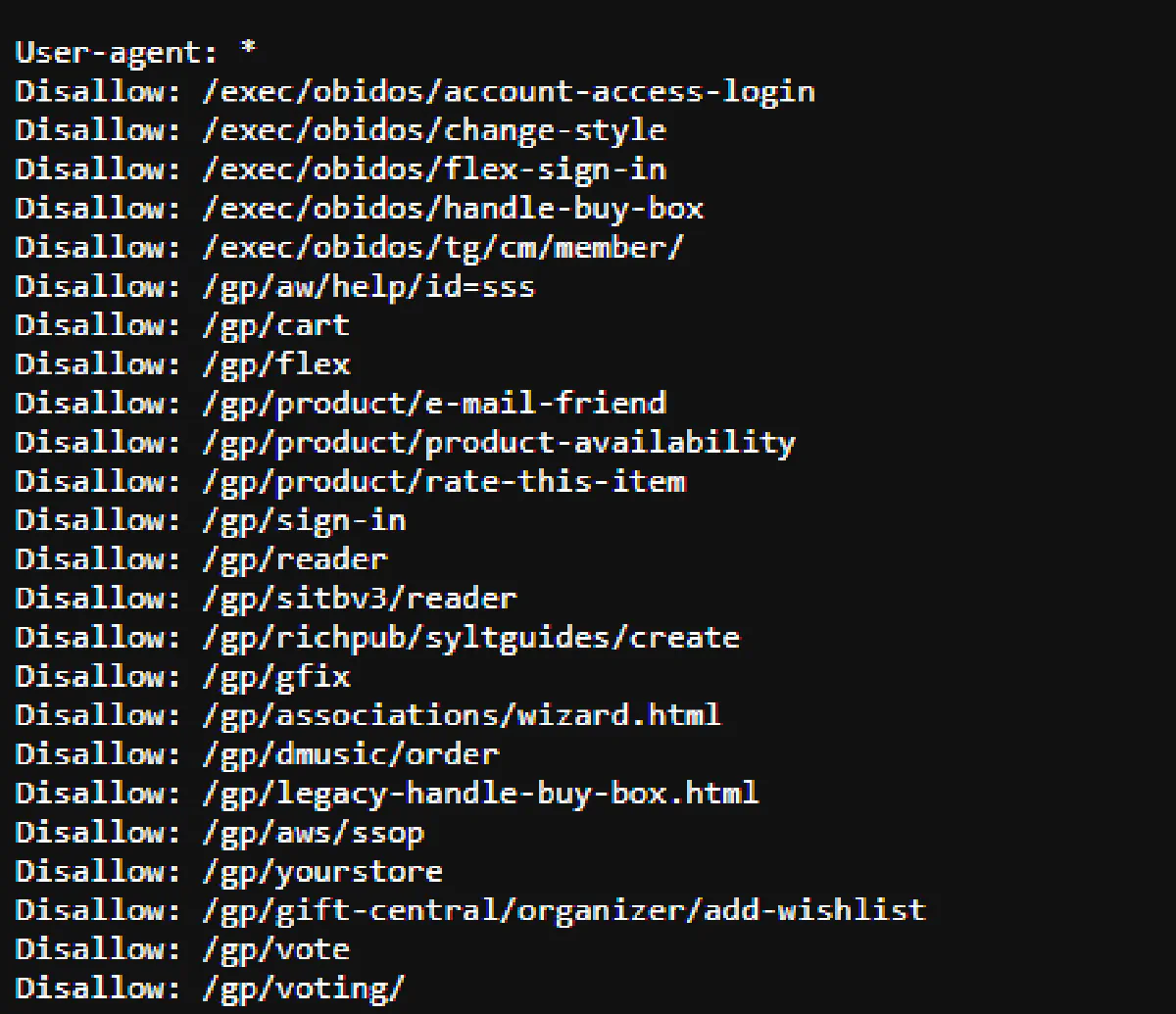
This means that all bots (including scrapers) are disallowed from accessing pages under URL structures that say disallow, which happen to include product pages, carts, and checkout flows.
Amazon doesn’t want bots crawling these sections.
If you ignore this and start scraping, you’re breaking the site’s rules, even if there’s no direct legal consequence.
But here’s the catch: robots.txt isn’t a wall, it’s a suggestion. The website can’t enforce it, but it might have other defenses in place that automatically block scrapers that ignore it.
If you see “Disallow” rules for key pages, expect the site to have additional anti-bot mechanisms in play.
A.2. Reading the Terms of Service (And What It Actually Means for Scraping)
Most sites bury their scraping policies in their Terms of Service (ToS). You can search for terms like “scraping,” “crawler,” “automated access,” or “bot.”
Amazon's ToS makes it clear:
"You may not use any data mining, robots, or similar data gathering and extraction tools in connection with the Amazon Services."
Seems like a hard no, right? Not exactly.
Here’s what you need to know about ToS and scraping:
- Simply visiting a website does not mean you legally agree to its ToS. Courts have ruled that browsing a public page isn’t the same as entering into a contract. This means if a website bans scraping in its ToS, it doesn’t automatically make scraping illegal—unless they can prove you knowingly agreed to the terms.
- Logging in changes everything. If you sign in before scraping, you are bound by the ToS. That makes scraping against their rules a contract violation, which can lead to legal trouble.
This is where Amazon has made a huge move—product reviews are now behind a login wall. 🔒
If you scrape reviews today, you must log in, which means you’re knowingly violating their ToS. That puts you on the wrong side of the law.
Product listings? Still public. Scraping them is against Amazon’s ToS, but it’s not a contract violation unless they can prove you agreed to the terms.
A.3. Checking for an Official API
If a website provides an official API, that’s usually a sign they prefer you use it instead of scraping. It’s also a strong clue that scraping might be restricted (either in ToS or through technical defenses.)
Amazon, for example, offers several APIs, including Product Advertising API and Selling Partner API.
At first glance, these APIs seem like a goldmine, but there’s a catch: they require approval, and access is limited.
If you don’t qualify, you’re left with scraping as your only option. But knowing the API exists tells you that Amazon is monitoring data access closely.
So, what does this mean for you?
- If an API exists and is open to you, it’s the safest way to get data.
- If an API exists but has strict access requirements, the website is likely anti-scraping and may have extra defenses.
- If no API exists, scraping is probably the only option, but you should still check for hidden defenses.
Amazon’s API is locked behind verification, which means if you’re scraping their product pages, expect challenges.
B. Methods That Detect Anti-Bot Measures
Some websites don’t explicitly say “no scraping” in robots.txt or ToS, but that doesn’t mean they’re scraper-friendly. Instead of stating their stance outright, they silently set up traps and systems designed to detect and block automated traffic in real time.
Amazon is a perfect example. There’s no law stopping you from scraping publicly visible product pages, but if your bot isn’t configured properly, it won’t get very far.
You’ll start hitting CAPTCHAs, missing content, or worse; getting permanently blocked.
So, how do you tell if a site has anti-scraping defenses before running a full scraper? Let’s go step by step.
B.1. Checking for JavaScript-Rendered Content
Some sites don’t load key data until JavaScript runs, making it impossible to extract with a simple HTTP request. The easiest way to check is by viewing the raw HTML source (CTRL + U in most browsers) and searching for essential elements like prices, product names, or reviews. If they’re missing but appear in DevTools (F12 → Elements tab), the site is dynamically injecting data after the page loads.
A scraper using requests or BeautifulSoup won’t retrieve that content.
Instead, you’ll need a headless browser like Selenium or Puppeteer, or you can intercept API calls in the network tab and replicate them.
If the site relies on heavy JavaScript frameworks like React or Angular, assume that traditional scraping methods won’t work out of the box.
B.2. Detecting Rate Limiting and IP Blocking
Websites monitor how often and how fast requests come from the same IP. If you refresh a page too quickly or scrape multiple URLs in succession, you’ll start running into HTTP 429 (Too Many Requests) errors, CAPTCHAs, or outright blocks. 🔒
Testing for rate limiting is simple: manually refresh a page multiple times in quick succession and see if a CAPTCHA appears. Then, do the same with a script making back-to-back requests. If the site starts blocking after a certain threshold, it’s tracking access patterns and limiting repeated requests.
🔑 To avoid detection, slow down requests and rotate IP addresses. Proxies (especially residential proxies) help distribute traffic, making scrapers appear as real users from different locations. Adding random delays between requests and mimicking natural browsing behavior also reduces the risk of detection.
B.3. Identifying Honeypot Traps
Some sites plant invisible elements that exist only to catch scrapers. 🍯🕸
These honeypots can be hidden form fields, fake links, or CSS elements with display: none.
If your bot interacts with them, the site instantly flags it as automated and blocks access.
To check for honeypots, inspect the page source (CTRL + U) and look for elements that don’t appear on the page but exist in the HTML. Hidden input fields (<input type="hidden">) and links styled to be invisible (opacity: 0, visibility: hidden) are common traps.
A real user would never click them, but a poorly designed scraper that extracts all links or inputs might.
To avoid this, scrape only visible elements by ensuring your parser checks for display: none or hidden attributes. Advanced sites may also use JavaScript to dynamically insert honeypots after page load, so testing with both static HTML and rendered content helps catch them before they catch you.
B.4. Checking for Browser Fingerprinting
Even with a headless browser, websites can track visitors based on unique browser fingerprints.
They detect scrapers by analyzing User-Agent strings, screen resolution, installed fonts, WebGL configurations, and even how the mouse moves. If your scraper lacks natural browser characteristics, it stands out and gets flagged.
You can check how unique your browser fingerprint is by visiting https://amiunique.org/ in both a normal browser and a headless one. If the fingerprints are different, websites can tell them apart too.
To bypass fingerprinting, use real User-Agent headers, enable JavaScript, and modify WebGL settings to mimic real users. Puppeteer and Selenium offer stealth plugins that help make automated browsers look more human. Enabling cookies, allowing minor page interactions, and matching real user behavior also improve stealth.
Best Practices
Checking a website’s scraping permissions is just the first step. If you decide to move forward, scraping smart is what keeps your project running efficiently without unnecessary risks.
⏳ Respect Rate Limits – Don’t flood the site with requests. Space them out, randomize timing, and stay under detection thresholds. See our rate limiting guide for details.
🚀 Use A Web Scraping API - A web scraping API like Scrape.do can help your bots access protected domains that will block your attempts to scrape using rotating proxies, header rotation, TLS fingerprint manipulation, and more; with a single API call.
1000 FREE monthly web scraping credits - start with Scrape.do.
🔄 Use Rotating Proxies – A single IP making repeated requests gets flagged fast. Rotate between residential or mobile proxies to stay under the radar.
👤 Mimic Real User Behavior – Bots get caught when they behave unnaturally. Randomize request patterns, use real browser headers, and allow time for pages to load.
🔐 Avoid Scraping Behind Logins – If you need to log in, you’re bound by the site’s Terms of Service, and scraping could become a legal issue. Stick to public data whenever possible.
⚙️ Check for an API First – If an API exists, it’s often the safest and most efficient way to access data. Scraping when an API is available is riskier, especially if the site enforces its ToS.
🔍 Monitor for Site Changes – Websites update structures and defenses constantly. Build scrapers that can adapt, and don’t rely on hardcoded selectors that break easily.
⚖️ Stay Informed on Legal and Ethical Issues – Laws and enforcement around scraping are evolving. Keep up with cases like hiQ Labs v. LinkedIn, GDPR regulations, and platform policy updates.
Scraping responsibly means balancing efficiency, stealth, and compliance. If you follow these best practices, you’ll reduce blocks, avoid legal trouble, and keep your data pipeline running smoothly.
To Sum Up
A good web scraper is like the Batman: takes prep. time seriously, understands the risks, and tries to stay on the good side of the law.
The best scrapers take a moment to check permissions, spot potential blocks, and adjust their strategy before running their code.
If you’re serious about data extraction, build scrapers that work long-term by considering every aspect.
Frequently Asked Questions
Are you allowed to scrape any website?
No, not all websites allow scraping. Public data is generally fair game, but if a site’s robots.txt, Terms of Service, or legal regulations restrict scraping, you could face IP bans or legal action if you proceed.
Do websites block web scraping?
Yes, many websites use anti-bot measures like rate limiting, CAPTCHAs, JavaScript obfuscation, and IP tracking to detect and block scrapers. Some explicitly forbid scraping in their robots.txt or ToS, while others silently monitor traffic and block suspicious activity.
Is web scraping unethical?
Not necessarily. Scraping publicly available data for research, market analysis, or personal projects is generally ethical. However, scraping behind logins, personal data, or content protected by ToS without permission can cross ethical and legal lines.
Full Stack Developer








