Category:Scraping Use Cases
How to Scrape Screenings and Ticket Prices from cineworld.co.uk

Software Engineer


Cineworld is the UK’s biggest cinema chain, but if you have ever tried to automate showtime or ticket scraping you know it is far from straightforward.
No worries, though. In this guide, we'll overcome every obstacle together and learn how to scrape Cineworld effortlessly.
We'll bypass Cloudflare protection and break through geo-restrictions to scrape screening times for movies and use them to export ticket price data.
Wanna skip the tutorial? Find fully working code here. ⚙
Why Is Scraping Cineworld Difficult?
Cineworld’s website is not just another HTML page you can curl.
It is designed to reject automated traffic and block visitors outside the UK while keeping pricing data behind complex backend structures.
Heavy Cloudflare Protection
Cineworld sits behind Cloudflare.
Instead of real content at first request, you often get a challenge screen or are forced to solve a CAPTCHA to prove you're not a bot.
This makes it impossible to bypass using basic HTML request libraries like Python Requests.

Tight Geo Restriction
Cineworld only works properly from UK IP addresses.
If you hit their endpoints from abroad, you risk an instant block like below.
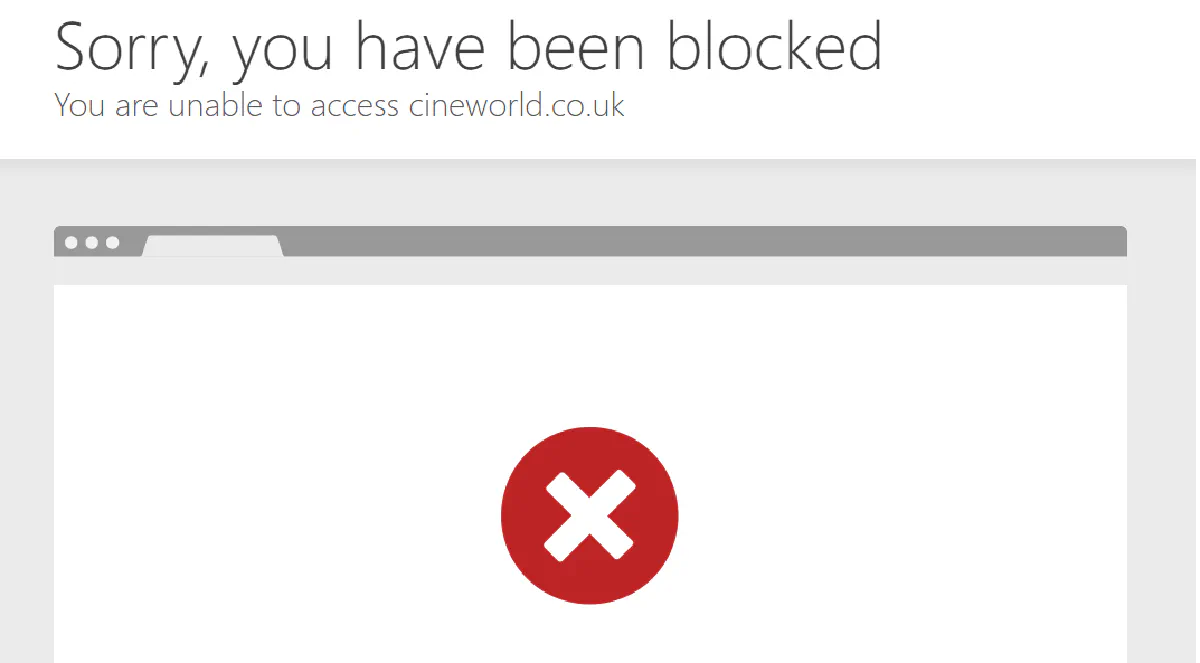
You'll need to get your hands on a premium proxy provider for UK-based residential IPs.
For this guide to gain easy access to Cineworld, we'll use Scrape.do, which bypasses Cloudflare challenges and CAPTCHAs while providing premium proxies to overcome geo-restrictions.
Scrape Screenings from Cineworld
Our very first target will be to scrape all movie and show screenings from a certain cinema for a range of dates.
Each screening is also tied to something called a Vista ID, which we will use later to pull ticket prices.
Find Cinema IDs
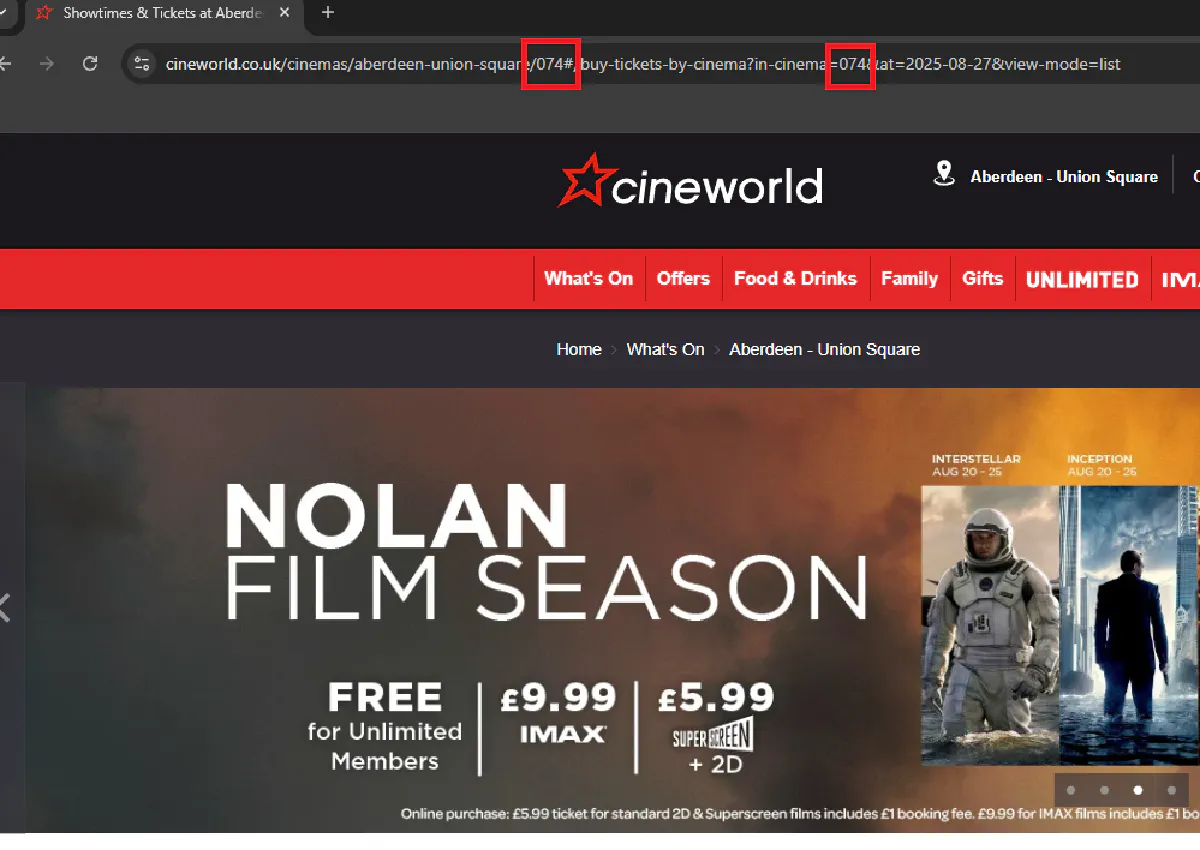
Every cinema has a unique ID that appears directly in the URL.
When you open a cinema page you will see something like this:
https://www.cineworld.co.uk/cinemas/aberdeen-union-square/074That last number, 074, is the cinema ID. We will need both the cinema name and the cinema ID to request listings.
Send First Request
Let’s test with one day of listings.
First we construct the target URL with the cinema ID+name and the chosen date.
Then we encode it and send it through Scrape.do:
import urllib
import requests
from bs4 import BeautifulSoup
TOKEN = "<your-token>"
cinema_name = "aberdeen-union-square"
cinema_id = "074"
target_date = "2025-09-04"
listing_url = f"https://www.cineworld.co.uk/cinemas/{cinema_name}/{cinema_id}#/buy-tickets-by-cinema?in-cinema={cinema_id}&at={target_date}&view-mode=list"
encoded_url = urllib.parse.quote_plus(listing_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geoCode=gb&super=true&render=true"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
movies = soup.select(".movie-row")
print(f"Found {len(movies)} movies")If everything worked, you should see something like:
Found 12 moviesEach showtime button has a data-url attribute with a hidden value called the Vista ID. This is Cineworld’s internal identifier for that specific screening.

Loop Through a Date Range
Scraping just one day is useful for testing, but you usually want to cover a whole week or more.
We can create a helper that generates all dates between a start and end, then loop through them.
Here is a simple function that returns a list of dates in YYYY-MM-DD format:
from datetime import datetime, timedelta
def date_range(start_date, end_date):
start = datetime.strptime(start_date, "%Y-%m-%d")
end = datetime.strptime(end_date, "%Y-%m-%d")
delta = end - start
return [(start + timedelta(days=i)).strftime("%Y-%m-%d") for i in range(delta.days + 1)]Now we can pick a range, for example the first week of September:
start_date = "2025-09-04"
end_date = "2025-09-08"
dates = date_range(start_date, end_date)Add Error Handling and Retries
Sometimes the request might come back empty even though the date has screenings.
To handle that, we retry the request a couple of times with a short pause before skipping the date. This is regular practice in web scraping:
import time
for current_date in dates:
encoded_url = urllib.parse.quote_plus(
f"https://www.cineworld.co.uk/cinemas/{cinema_name}/{cinema_id}#/buy-tickets-by-cinema?in-cinema={cinema_id}&at={current_date}&view-mode=list"
)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geoCode=gb&super=true&render=true"
listings = []
max_retries = 2
attempt = 0
while attempt <= max_retries:
attempt += 1
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
listings = soup.select(".movie-row")
if listings:
print(f"Found {len(listings)} listings on {current_date} (attempt {attempt})")
break
else:
print(f"No listings for {current_date}, retrying...")
time.sleep(2)
if not listings:
print(f"Skipping {current_date}")
continueWith this in place, your scraper will gracefully skip dates that fail after a few retries.
Extract Vista IDs
Scraping showtimes is not about listing movie titles. It is about capturing the exact backend session that sells a ticket.
On Cineworld, only screenings with a decided time expose that session as a Vista ID.
The page can also quietly jump back to today when a date has no shows, which can poison your results if you do not check the visible calendar label first.
In this step we'll:
- Lock down stable selectors for the calendar label, movie rows, titles, and time buttons.
- Detect and skip the “defaulted to today” case by reading the calendar text and normalizing the date.
- Keep only real, decided screenings where the time button does not navigate and carries a
data-url. - Extract the Vista session id from the
idparameter inside thatdata-url.
We will inspect the DOM to confirm selectors, add the fallback guard, walk each movie row to keep only confirmed buttons with href="#", then parse the data-url to pull out the vista_id.
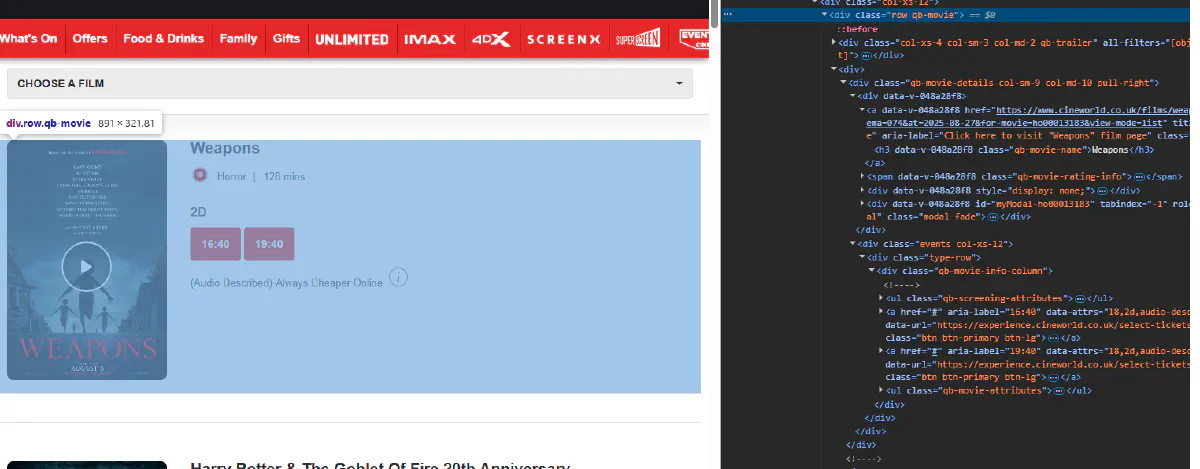
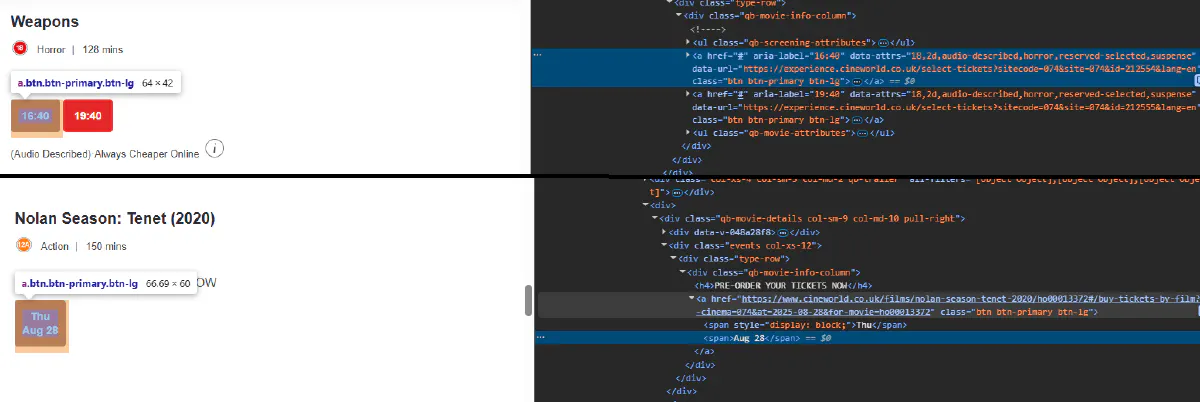
1) Find the selectors in DevTools
Open DevTools, pick elements, and capture these selectors:
- Calendar label
.qb-calendar-widget h5

- Movie container
.movie-row
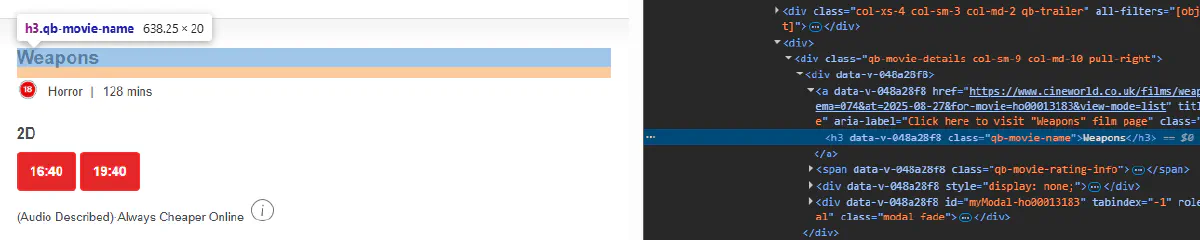
- Movie title
h3.qb-movie-name
- Screening buttons
a.btn-lg,- confirmed example that we keep:
<a class="btn-lg" href="#" data-url="/.../buy?in-cinema=074&id=123456&at=2025-09-04...">13:20</a> - and preorder example that we skip that has a
hrefto coming-soon films.
- confirmed example that we keep:
2) Handle the “defaulted to today” fallback
If the target date we scrape has no screenings or shows, Cineworld may show today instead.
We read the visible label, extract dd/mm/yyyy, and normalize it to yyyy-mm-dd. If the page returned today while we asked for something else, we skip that day.
import re
def parse_calendar_label(label_text: str):
"""
Examples:
'Today Wed 18/09/2025'
'Thu 19/09/2025'
Returns: '2025-09-18' or None
"""
m = re.search(r'(\d{2})/(\d{2})/(\d{4})', label_text)
if not m:
return None
dd, mm, yyyy = m.groups()
return f"{yyyy}-{mm}-{dd}"Guard snippet used later inside our page parser:
# soup = BeautifulSoup(html, "html.parser")
cal = soup.select_one(".qb-calendar-widget h5")
if cal:
returned = parse_calendar_label(cal.get_text(" ", strip=True))
if returned == today_str and current_date != today_str:
print(f"Defaulted to today, no shows for {current_date}")
return []
if returned and returned != current_date:
print(f"Got {returned} instead of {current_date}, skipping")
return []3) Identify confirmed sessions and skip preorder items
Confirmed sessions keep href="#" and include a data-url with the id parameter.
We use that rule to separate real showtimes from placeholders.
# inside the movie loop
for btn in row.select("a.btn-lg"):
href_val = btn.get("href", "")
is_confirmed = (href_val == "#" and btn.has_attr("data-url"))
if not is_confirmed:
continue # preorder or undecided, skip
# confirmed goes on to id extraction4) Extract vista_id from data-url
We parse the query string with urllib.parse and keep a small regex fallback for odd cases:
import urllib.parse
def extract_vista_id(data_url: str):
parsed = urllib.parse.urlparse(data_url)
qs = urllib.parse.parse_qs(parsed.query)
vid = qs.get("id", [None])[0]
if vid:
return vid
# fallback if attribute is not a standard query string
m = re.search(r'(?:\?|&)id=([^&]+)', data_url)
return m.group(1) if m else None5) Put it together for one day of HTML
This function receives the HTML for a single date and returns clean records for confirmed sessions.
It includes the calendar fallback guard, selector usage, the confirmed button check, id extraction:
from bs4 import BeautifulSoup
def collect_screenings_for_date(html_text, cinema_name, current_date, today_str):
soup = BeautifulSoup(html_text, "html.parser")
# Fallback guard
cal = soup.select_one(".qb-calendar-widget h5")
if cal:
returned = parse_calendar_label(cal.get_text(" ", strip=True))
if returned == today_str and current_date != today_str:
print(f"Defaulted to today, no shows for {current_date}")
return []
if returned and returned != current_date:
print(f"Got {returned} instead of {current_date}, skipping")
return []
results, seen = [], set()
for row in soup.select(".movie-row"):
title_el = row.select_one("h3.qb-movie-name")
movie_name = title_el.get_text(strip=True) if title_el else ""
for btn in row.select("a.btn-lg"):
href_val = btn.get("href", "")
if href_val == "#" and btn.has_attr("data-url"):
vista = extract_vista_id(btn["data-url"])
if not vista:
continue
key = (vista, current_date)
if key in seen:
continue
seen.add(key)
results.append({
"Movie Name": movie_name,
"Date": current_date,
"Cinema": cinema_name,
"Time": btn.get_text(strip=True),
"id": vista
})
return results6) Run it inside your existing loop
We already built date_range earlier, so we will focus feeding the HTML into the collector section:
TODAY = datetime.now().strftime("%Y-%m-%d")
screening_list = []
for current_date in dates: # dates comes from the earlier date_range helper
listing_url = (
f"https://www.cineworld.co.uk/cinemas/{cinema_name}/{cinema_id}"
f"#/buy-tickets-by-cinema?in-cinema={cinema_id}&at={current_date}&view-mode=list"
)
encoded = urllib.parse.quote_plus(listing_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded}&geoCode=gb&super=true&render=true"
html = None
attempt, max_retries = 0, 2
while attempt <= max_retries:
attempt += 1
r = requests.get(api_url)
soup = BeautifulSoup(r.text, "html.parser")
# proceed if listings are present
if soup.select(".movie-row"):
html = r.text
break
print(f"No listings for {current_date} on attempt {attempt}, retrying...")
time.sleep(2)
if not html:
continue
day_rows = collect_screenings_for_date(html, cinema_name, current_date, TODAY)
screening_list.extend(day_rows)
print(f"Collected {len(screening_list)} confirmed screenings")Save and Export
Now that screening_list is populated with confirmed sessions, we will write it to a JSON file.
With that added to the end of our code, here's our full working script:
# Scrape Cineworld screenings and export to screenings.json
import requests
import urllib.parse
import time
import re
import json
from bs4 import BeautifulSoup
from datetime import datetime, timedelta
# Config
TOKEN = "<your-token>"
cinema_name = "aberdeen-union-square"
cinema_id = "074"
start_date = "2025-09-04"
end_date = "2025-09-08"
TODAY = datetime.now().strftime("%Y-%m-%d")
# Helpers
def date_range(start_date, end_date):
s = datetime.strptime(start_date, "%Y-%m-%d")
e = datetime.strptime(end_date, "%Y-%m-%d")
return [(s + timedelta(days=i)).strftime("%Y-%m-%d") for i in range((e - s).days + 1)]
def parse_calendar_label(label_text: str):
"""
Examples:
'Today Wed 18/09/2025'
'Thu 19/09/2025'
Returns: 'YYYY-MM-DD' or None
"""
m = re.search(r'(\d{2})/(\d{2})/(\d{4})', label_text)
if not m:
return None
dd, mm, yyyy = m.groups()
return f"{yyyy}-{mm}-{dd}"
def extract_vista_id(data_url: str):
parsed = urllib.parse.urlparse(data_url)
qs = urllib.parse.parse_qs(parsed.query)
vid = qs.get("id", [None])[0]
if vid:
return vid
# Fallback for non standard strings
m = re.search(r'(?:\?|&)id=([^&]+)', data_url)
return m.group(1) if m else None
def collect_screenings_for_date(html_text, cinema_name, current_date, today_str):
soup = BeautifulSoup(html_text, "html.parser")
# Guard against silent fallback to today
cal = soup.select_one(".qb-calendar-widget h5")
if cal:
returned = parse_calendar_label(cal.get_text(" ", strip=True))
if returned == today_str and current_date != today_str:
print(f"Defaulted to today, no shows for {current_date}")
return []
if returned and returned != current_date:
print(f"Got {returned} instead of {current_date}, skipping")
return []
results, seen = [], set()
# Movie rows
for row in soup.select(".movie-row"):
title_el = row.select_one("h3.qb-movie-name")
movie_name = title_el.get_text(strip=True) if title_el else ""
# Confirmed screening buttons only
for btn in row.select("a.btn-lg"):
href_val = btn.get("href", "")
if href_val == "#" and btn.has_attr("data-url"):
vista = extract_vista_id(btn["data-url"])
if not vista:
continue
key = (vista, current_date)
if key in seen:
continue
seen.add(key)
results.append({
"Movie Name": movie_name,
"Date": current_date,
"Cinema": cinema_name,
"Time": btn.get_text(strip=True),
"id": vista
})
return results
# Main
screening_list = []
for current_date in date_range(start_date, end_date):
listing_url = (
f"https://www.cineworld.co.uk/cinemas/{cinema_name}/{cinema_id}"
f"#/buy-tickets-by-cinema?in-cinema={cinema_id}&at={current_date}&view-mode=list"
)
encoded = urllib.parse.quote_plus(listing_url)
api_url = (
f"https://api.scrape.do/?token={TOKEN}&url={encoded}"
f"&geoCode=gb&super=true&render=true"
)
html = None
attempt, max_retries = 0, 2
while attempt <= max_retries:
attempt += 1
r = requests.get(api_url)
soup = BeautifulSoup(r.text, "html.parser")
# Proceed when listings exist
if soup.select(".movie-row"):
html = r.text
break
print(f"No listings for {current_date} on attempt {attempt}, retrying...")
time.sleep(2)
if not html:
continue
day_rows = collect_screenings_for_date(html, cinema_name, current_date, TODAY)
screening_list.extend(day_rows)
# Export
with open("screenings.json", "w", encoding="utf-8") as f:
json.dump(screening_list, f, ensure_ascii=False, indent=2)
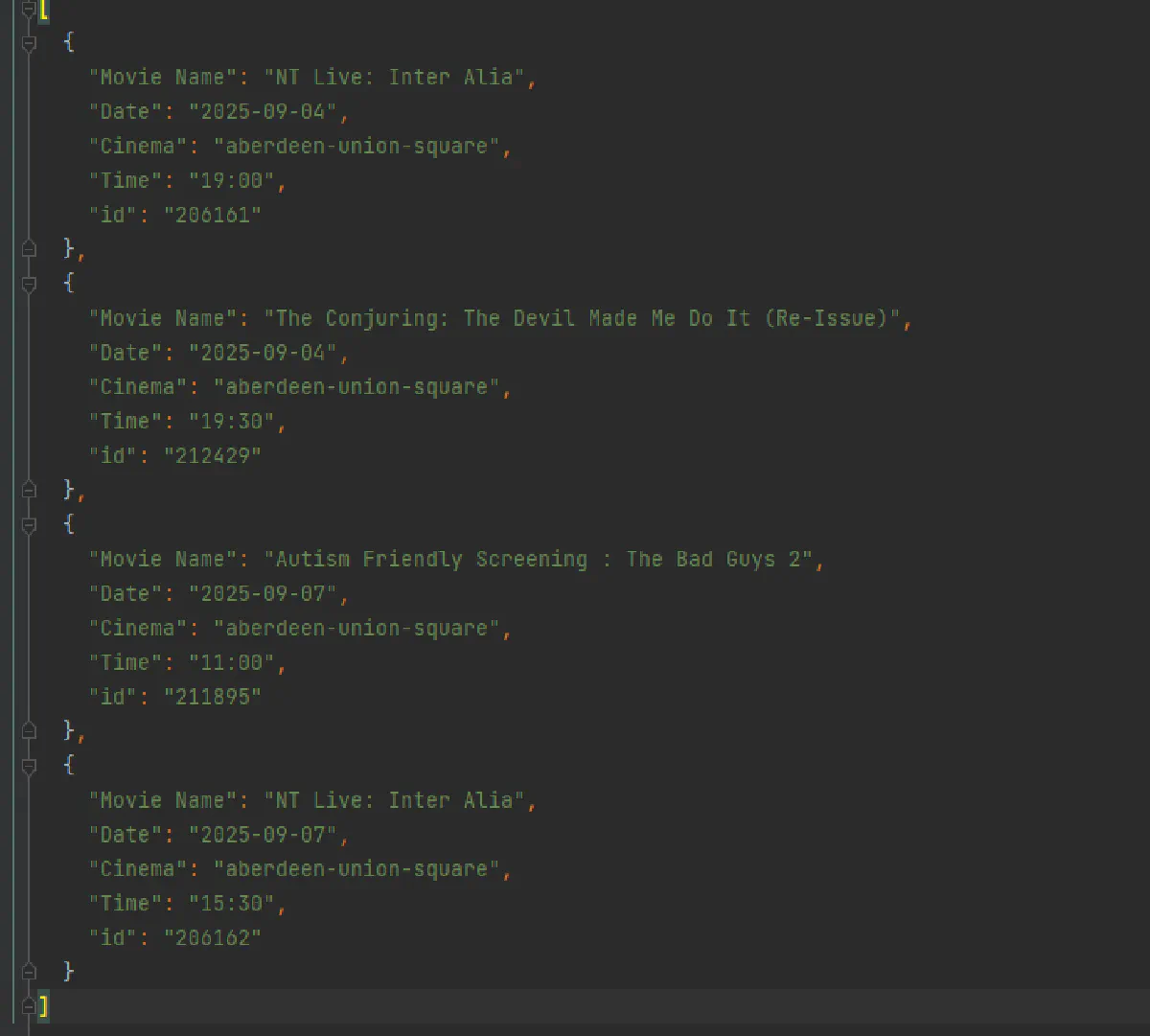
print(f"Saved {len(screening_list)} screenings to screenings.json")Our output file will look like this:
Scrape Ticket Prices for Multiple Screenings
Next up, we'll use the file we created in the previous step to extract ticket prices for all screenings in a theater, through the Cineworld backend.
Import and Use Vista IDs from JSON
We will read screenings.json from the first script and load it into memory.
Each row already has everything we need for pricing:
Movie NameDateinYYYY-MM-DDCinemaTimeidas the Vista session id
import json
from pathlib import Path
cinema_id = "074"
INPUT_FILE = Path("screenings.json")
with INPUT_FILE.open("r", encoding="utf-8") as f:
sessions = json.load(f)
print(f"Loaded {len(sessions)} sessions from {INPUT_FILE.name}")

Next, we will loop over sessions and request prices using cinema_id, Date, and id.
Understanding Pricing JSON Endpoint
Before writing the loop, we need to do a little research on where the ticket prices come from using our browser.
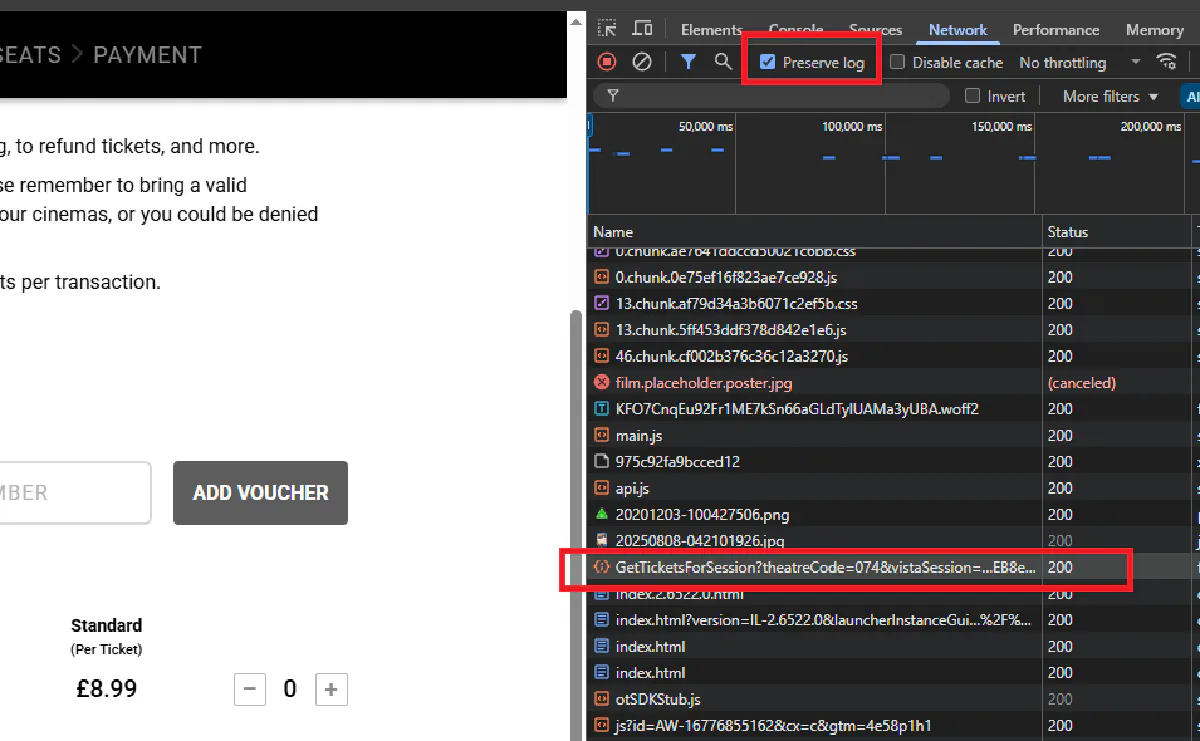
1. Open the cinema page and pick any decided session
Click a real showtime button that you know has a fixed time.
2. Open DevTools and preserve logs
Press F12, go to the Network tab, enable Preserve log.
3. Trigger the request
Click the time button again so the page fires all related requests.
4. Filter and locate the call
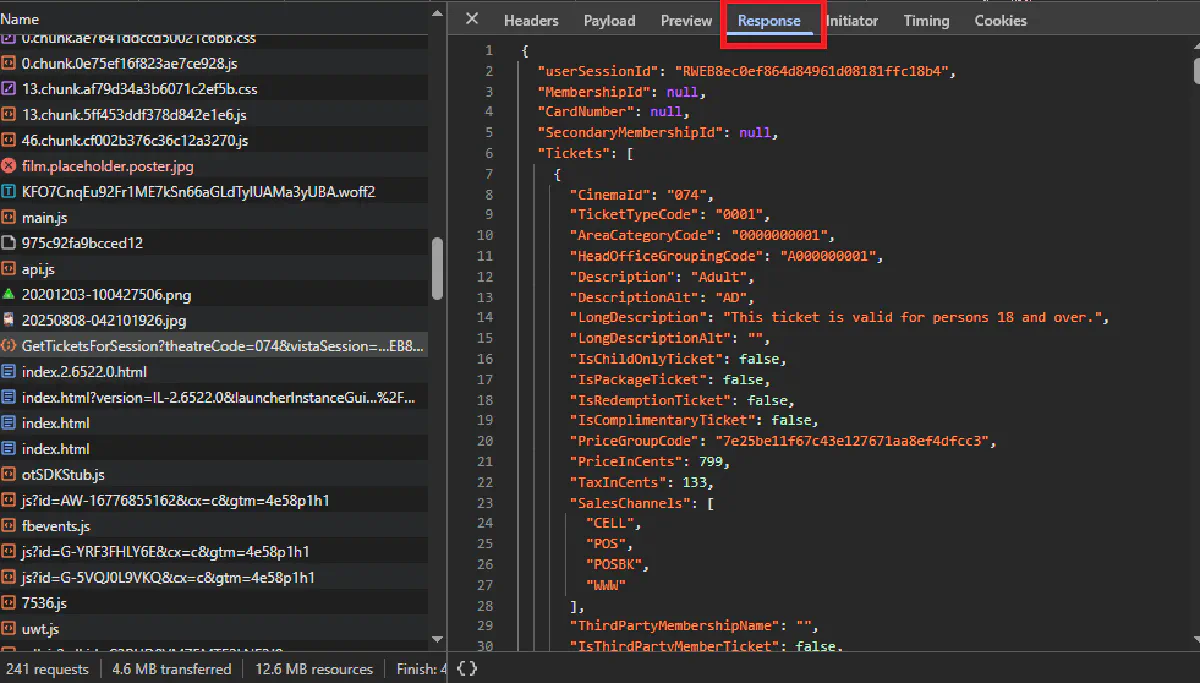
Type tickets or GetTicketsForSession in the filter box. You should see a request like: https://experience.cineworld.co.uk/api/GetTicketsForSession?...
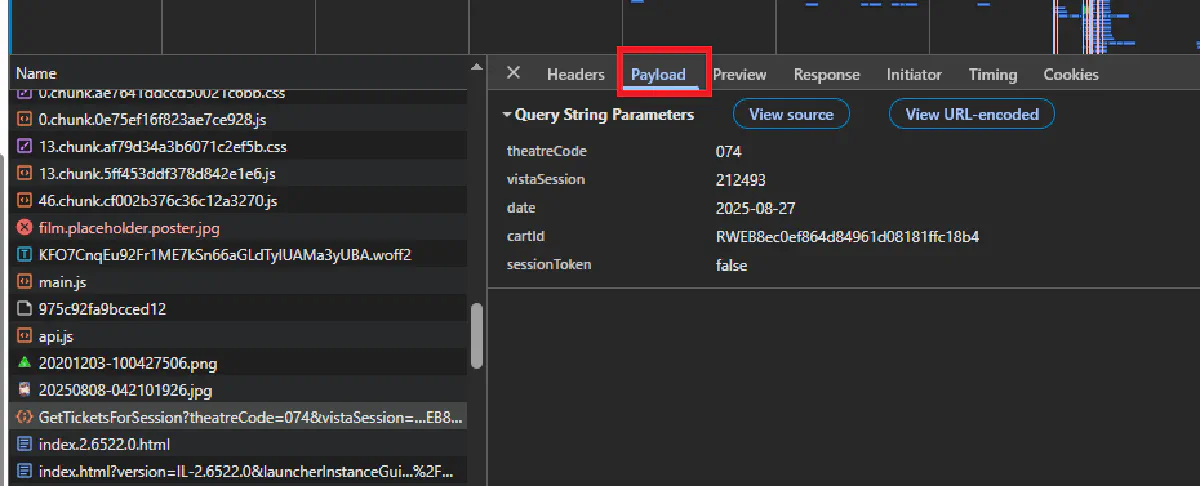
5. Inspect the request URL
On the right pane, look at the full URL and query string. You will see:
theatreCodewhich is the same as your cinema idvistaSessionwhich matches the id from screenings.jsondateinYYYY-MM-DDcartIdset to a random identifiersessionTokenoftenfalse
6. Inspect the response
Open the Response tab. You will see a JSON document with a top level Tickets array. Each ticket object contains fields like TicketTypeCode, LongDescription, and PriceInCents.
Now that the endpoint and its parameters are clear, we can implement the script that pulls ticket data for each session.
import urllib
import requests
import json
import secrets # for a random cart id
TOKEN = "<your-token>" # Scrape.do API token
cinema_id = "074" # theatreCode for Cineworld
CART_ID = "RWEB" + secrets.token_hex(8) # one cart id per run
# 'sessions' is loaded in the previous step:
all_tickets = []
for s in sessions:
session_id = s["id"]
date_str = s["Date"]
target_url = (
"https://experience.cineworld.co.uk/api/GetTicketsForSession"
f"?theatreCode={cinema_id}"
f"&vistaSession={session_id}"
f"&date={date_str}"
f"&cartId={CART_ID}"
"&sessionToken=false"
)
encoded = urllib.parse.quote_plus(target_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded}&geoCode=gb&super=true"
r = requests.get(api_url)
try:
data = json.loads(r.text)
except json.JSONDecodeError:
print(f"Invalid JSON for session {session_id}")
continue
# Collect raw ticket entries for later formatting
for t in data.get("Tickets", []):
all_tickets.append({
"Movie Name": s["Movie Name"],
"Date": s["Date"],
"Cinema": s["Cinema"],
"Time": s["Time"],
"TicketTypeCode": t.get("TicketTypeCode"),
"LongDescription": t.get("LongDescription"),
"PriceInCents": t.get("PriceInCents")
})
print(f"Collected {len(all_tickets)} ticket rows across {len(sessions)} sessions")Extract Price and Export
We now have one more step, we need to convert PriceInCents into readable pounds and write one row per ticket type to a CSV. This gives you a structured table for analysis.
import csv
def cents_to_pounds(cents):
try:
return f"£{int(cents) / 100:.2f}"
except Exception:
return None
# 'all_tickets' is produced in the previous step
with open("ticket_prices.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(
f,
fieldnames=[
"Movie Name", "Date", "Cinema", "Time",
"TicketTypeCode", "LongDescription", "Price"
]
)
writer.writeheader()
for t in all_tickets:
writer.writerow({
"Movie Name": t["Movie Name"],
"Date": t["Date"],
"Cinema": t["Cinema"],
"Time": t["Time"],
"TicketTypeCode": t.get("TicketTypeCode"),
"LongDescription": t.get("LongDescription"),
"Price": cents_to_pounds(t.get("PriceInCents"))
})
print(f"Wrote {len(all_tickets)} rows to ticket_prices.csv")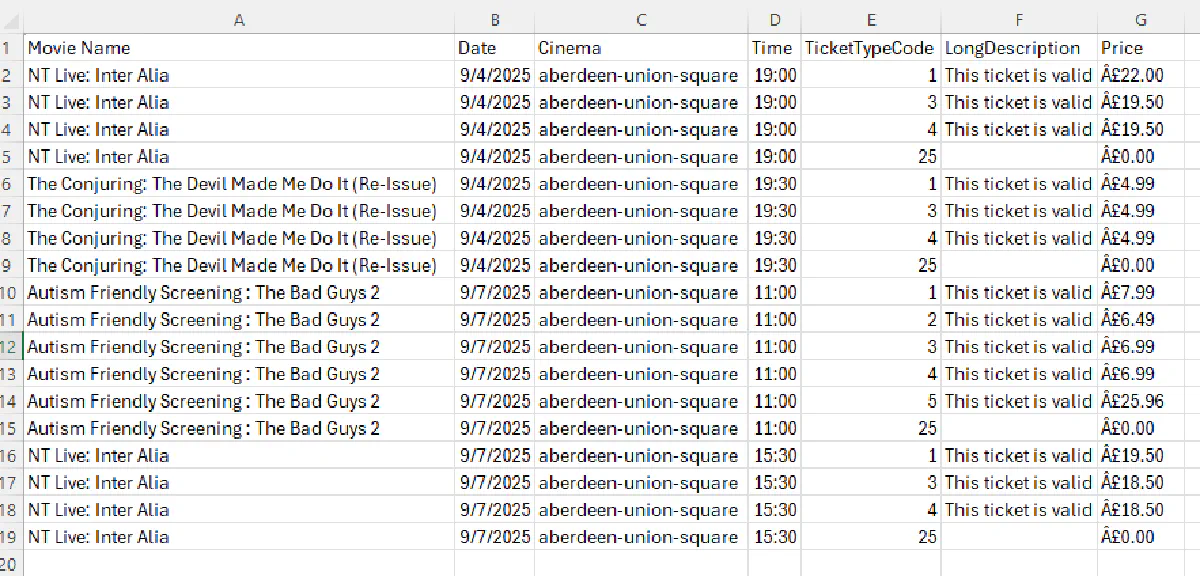
Full Code
Here is the complete second script that loads screenings.json, fetches prices for each session through Scrape.do, converts cents, and exports ticket_prices.csv.
# cineworld_prices.py
import json
import csv
import urllib.parse
import requests
import secrets
# Config
TOKEN = "<your-token>"
cinema_id = "074"
INPUT_FILE = "screenings.json"
CART_ID = "RWEB" + secrets.token_hex(8)
# 1) Load sessions
with open(INPUT_FILE, "r", encoding="utf-8") as f:
sessions = json.load(f)
print(f"Loaded {len(sessions)} sessions from {INPUT_FILE}")
# 2) Request prices
all_tickets = []
for s in sessions:
session_id = s["id"]
date_str = s["Date"]
target_url = (
"https://experience.cineworld.co.uk/api/GetTicketsForSession"
f"?theatreCode={cinema_id}"
f"&vistaSession={session_id}"
f"&date={date_str}"
f"&cartId={CART_ID}"
"&sessionToken=false"
)
encoded = urllib.parse.quote_plus(target_url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded}&geoCode=gb&super=true"
r = requests.get(api_url)
try:
data = json.loads(r.text)
except json.JSONDecodeError:
print(f"Invalid JSON for session {session_id}")
continue
for t in data.get("Tickets", []):
all_tickets.append({
"Movie Name": s["Movie Name"],
"Date": s["Date"],
"Cinema": s["Cinema"],
"Time": s["Time"],
"TicketTypeCode": t.get("TicketTypeCode"),
"LongDescription": t.get("LongDescription"),
"PriceInCents": t.get("PriceInCents")
})
print(f"Collected {len(all_tickets)} ticket rows")
# 3) Convert and export
def cents_to_pounds(cents):
try:
return f"£{int(cents) / 100:.2f}"
except Exception:
return None
with open("ticket_prices.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(
f,
fieldnames=[
"Movie Name", "Date", "Cinema", "Time",
"TicketTypeCode", "LongDescription", "Price"
]
)
writer.writeheader()
for t in all_tickets:
writer.writerow({
"Movie Name": t["Movie Name"],
"Date": t["Date"],
"Cinema": t["Cinema"],
"Time": t["Time"],
"TicketTypeCode": t.get("TicketTypeCode"),
"LongDescription": t.get("LongDescription"),
"Price": cents_to_pounds(t.get("PriceInCents"))
})
print(f"Wrote {len(all_tickets)} rows to ticket_prices.csv")Conclusion
We've created a dependable two step pipeline: first script collects confirmed screenings with Vista IDs while guarding against the silent today fallback, second script fetches ticket prices per session and exports a clean CSV you can analyze or feed into a dashboard.
While the code we built handles how to extract and store information, Scrape.do works behind the scenes to bypass Cineworld's WAF and geo-blocks.
Bypass any WAF, geo-block, or CAPTCHA with Scrape.do, start completely FREE ->
Software Engineer








