Category:Scraping Use Cases
Scraping Chewy: How to Extract Product Data Without Getting Blocked

R&D Engineer


Chewy is one of the biggest online marketplaces for pet products, offering everything from food to accessories across the United States.
If you're looking to extract product prices, track availability, or analyze trends, you might have already hit a wall since it has strong anti-bot defenses in place, blocking automated traffic and making it difficult to collect data at scale.
But if you’re stuck, don’t worry.
This guide will show you why Chewy is difficult to scrape, what protections it uses, and how you can bypass these challenges to extract the data you need.
You can also find the fully-functioning code in this GitHub folder. ⚙
Why Scraping Chewy Is Difficult
Chewy, like many major e-commerce platforms, actively blocks automated data collection.
It does this through multiple layers of protection, making traditional scraping techniques unreliable.
1. Akamai Bot Protection
Chewy uses Akamai’s bot management system, which is designed to detect and block non-human traffic.
This includes:
- Behavior tracking that monitors mouse movements, scroll patterns, and interaction delays.
- TLS fingerprinting that identifies whether the request is coming from a real browser or an automated tool.
- JavaScript challenges that require scripts to execute in a real browser environment before granting access.
If your scraper doesn’t behave like a real user, it will be blocked almost instantly.
2. Dynamic IP Checks
Chewy tracks IP activity to identify scraping patterns.
If your requests come from an unusual location, lack session persistence, or originate from datacenter proxies, you’ll likely get flagged.
- Requests from datacenter IPs are blocked faster than those from residential or ISP-based proxies.
- High request frequency can trigger rate limiting, even if you use multiple IPs.
- Session-based tracking correlates activity across different IPs, making simple proxy rotation ineffective.
These restrictions make it impossible to scrape Chewy using standard tools like Python’s requests library or even basic proxy rotation.
How Scrape.do Bypasses These Challenges
Scrape.do makes scraping Chewy effortless by handling all the anti-bot defenses for you.
It ensures requests appear natural, avoiding blocks and CAPTCHAs.
- 🌍 Geo-targeted residential and ISP proxies: Chewy is highly sensitive to IP reputation and location. Scrape.do uses real residential and ISP-based IPs from the US, avoiding detection. Sticky sessions allow multiple requests to come from the same identity, preventing tracking issues.
- 🧠 Intelligent request handling: Scrape.do rotates headers and TLS fingerprints to make requests indistinguishable from real browsers. Adaptive request pacing prevents rate limits by simulating human browsing patterns. JavaScript execution solves Akamai’s bot detection challenges automatically.
With Scrape.do, you don’t need to worry about getting blocked.
Just send your request and get clean data.
Extracting Data from Chewy Without Getting Blocked
Now it’s time to put everything into action.
First, we’ll send a request to a product page and verify we’re getting a 200 OK response. Then, we’ll extract important product details.
1. Prerequisites
Before making any requests, install the necessary dependencies if you haven’t already.
We’ll be using requests to send HTTP requests and BeautifulSoup to parse the HTML. Install them using:
pip install requests beautifulsoup4You’ll also need an API key from Scrape.do, which you can get by signing up at Scrape.do, for free.
Next, we need a target page to scrape.
For this guide, we’ll be working with the Purina Pro Plan Shredded Blend Adult Dog Food product page:
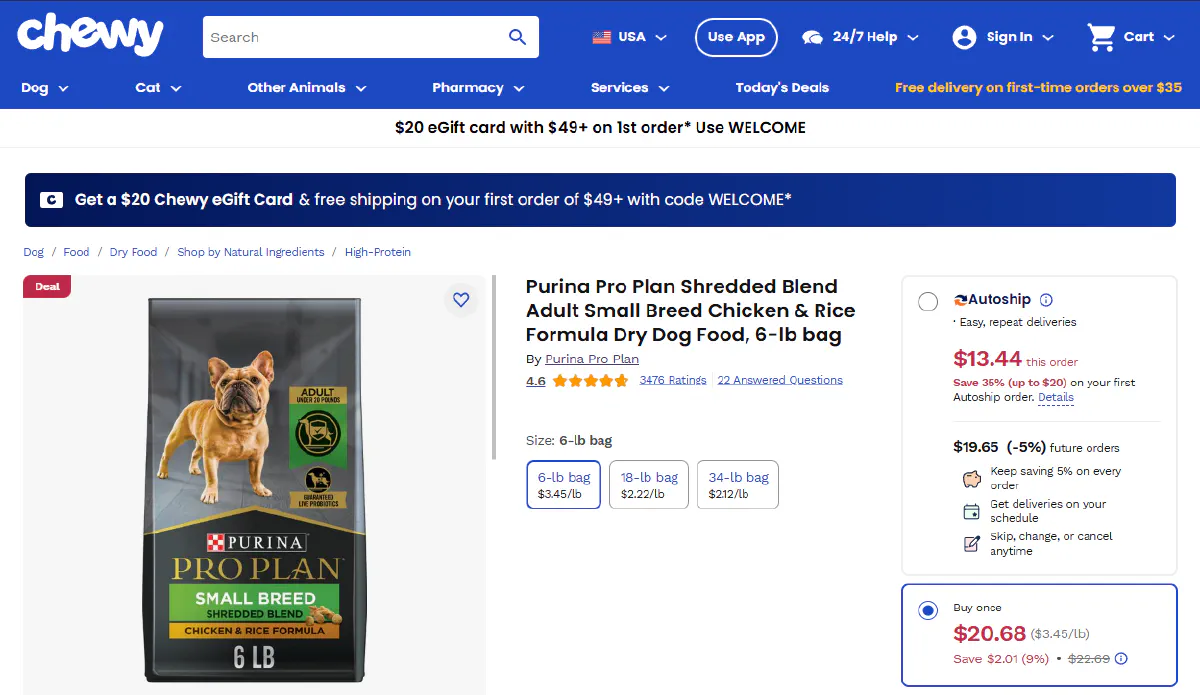
2. Sending a Request and Verifying Access
Now we’ll send a request through Scrape.do to ensure we can access the page without getting blocked.
If successful, we should receive a 200 OK response, confirming that we’ve bypassed Chewy’s protections.
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Chewy product URL
target_url = urllib.parse.quote_plus("https://www.chewy.com/purina-pro-plan-shredded-blend-adult/dp/114030")
# Optional parameters
render = "true"
geo_code = "us"
super = "true"
# Scrape.do API endpoint
url = f"http://api.scrape.do/?token={token}&url={target_url}&render={render}&geoCode={geo_code}&super={super}"
# Send the request
response = requests.request("GET", url)
# Print response status
print(response)If everything is working correctly, you should see this output:
<Response [200]>This confirms that we’ve successfully accessed the page while avoiding blocks and CAPTCHAs.
If you receive a different status code, take a screenshot of the response and inspect the headers to troubleshoot potential issues.
Extracting the Product Title
Now that we have successfully accessed the page, the next step is to extract the product title.
This requires inspecting the HTML structure of the page to find where the title is located.
1. Inspecting the HTML Structure
Open the product page in your browser and press F12 to open the developer tools. Then, use the element selector to hover over the product title.
This will highlight the exact HTML element containing the title:
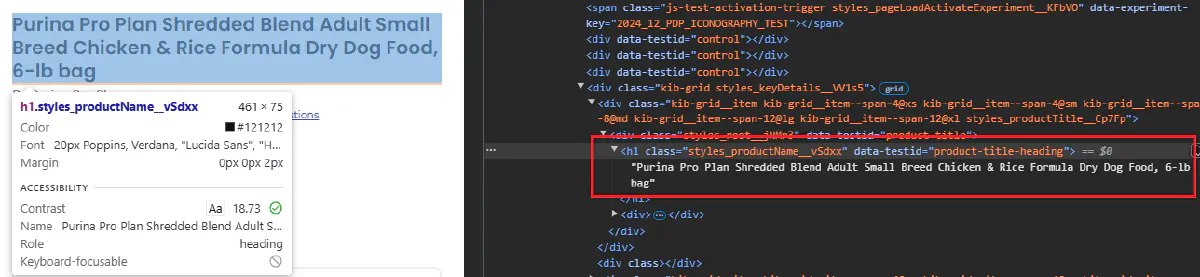
💡 Take a screenshot of the developer tools showing the product title’s HTML structure. This will help verify that we’re targeting the correct element in our scraper.
Look for a tag like <h1> or <span> with a unique class name that identifies the product title. It should look something like this:
<h1 class="styles_productName__vSdxx" data-testid="product-title-heading">
Purina Pro Plan Shredded Blend Adult Small Breed Chicken & Rice Formula
Dry Dog Food, 6-lb bag
</h1>Once we’ve identified the element, we can extract it using BeautifulSoup.
2. Extracting the Product Title with Python
Now that we know the structure, we can write a script to retrieve the title from the response.
from bs4 import BeautifulSoup
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Chewy product URL
target_url = urllib.parse.quote_plus("https://www.chewy.com/purina-pro-plan-shredded-blend-adult/dp/114030")
# Optional parameters
render = "true"
geo_code = "us"
super = "true"
# Scrape.do API endpoint
url = f"http://api.scrape.do/?token={token}&url={target_url}&render={render}&geoCode={geo_code}&super={super}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract the product title
title = soup.find("h1", attrs={"data-testid": "product-title-heading"}).text.strip()
print("Product Title:", title)If the script is working correctly, you should see the product title printed in the terminal:
Product Title: Purina Pro Plan Shredded Blend Adult Small Breed Chicken & Rice Formula Dry Dog Food, 6-lb bagIf the output is empty or incorrect, verify the class name by cross-checking it with your developer tools. If Chewy changes its structure, the class name may be different, so always check before running the script.
Extracting Product Price Alongside Name
Now that we have successfully extracted the product name, we’ll extend our script to include the price as well.
Same process as getting the name, but this time the price is stored inside a <div> tag with data-testid="advertised-price", so we’ll target this element along with the name.
<----- Previous section until the Print command ----->
# Extract product price
price = soup.find("div", attrs={"data-testid": "advertised-price"}).text.strip()
# Print extracted details
print("Product Title:", title)
print("Product Price:", price)This is the output you should get:
Product Title: Purina Pro Plan Shredded Blend Adult Small Breed Chicken & Rice Formula Dry Dog Food, 6-lb bag
Product Price: $20.68Saving Extracted Data to a CSV File
Now that we have successfully extracted the product name and price, we’ll save the data into a CSV file for easier access and further analysis.
Here's the final code:
import csv
from bs4 import BeautifulSoup
import requests
import urllib.parse
# Our token provided by Scrape.do
token = "<your_token>"
# Target Chewy product URL
target_url = urllib.parse.quote_plus("https://www.chewy.com/purina-pro-plan-shredded-blend-adult/dp/114030")
# Optional parameters
render = "true"
geo_code = "us"
super = "true"
# Scrape.do API endpoint
url = f"http://api.scrape.do/?token={token}&url={target_url}&render={render}&geoCode={geo_code}&super={super}"
# Send the request
response = requests.request("GET", url)
# Parse the response using BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Extract product title
title = soup.find("h1", attrs={"data-testid": "product-title-heading"}).text.strip()
# Extract product price
price = soup.find("div", attrs={"data-testid": "advertised-price"}).text.strip()
# Save extracted data to CSV
with open("chewy_product_data.csv", "w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Product Name", "Price"])
writer.writerow([title, price])
print("Data saved to chewy_product_data.csv")Now, the extracted product name and price are stored in chewy_product_data.csv, ready for further use.
Data saved to chewy_product_data.csvConclusion
Scraping Chewy is difficult due to Akamai bot protection and IP tracking, but not impossible with the right tools.
Need to scrape Chewy?
Scrape.do makes it simple.
R&D Engineer








