Category:Scraping Use Cases
Scrape Product and Category Data from Best Buy (Selenium and/or Python Requests)

Founder @ Scrape.do


Best Buy is one of the most important sources of electronics data in North America IF you can scrape it.
From phones and laptops to GPUs and smart TVs, the prices you see on Best Buy today often drive the entire e-commerce pricing chain in the US and Canada.
But getting structured data out of it is a nightmare.
In this article, we’ll use Python to scrape one of the hardest pages on the entire site: Best Buy’s Unlocked Phones category. It’s long, dynamic, fully rendered in JavaScript, and geo-restricted if you’re outside North America.
You’ll learn two methods:
- A small-project approach using Python and Selenium
- A scalable API-based approach using Scrape.do
Both will walk you through how to:
- Bypass the country selection splash screen
- Load and scroll a full category page
- Extract product name, brand, price, rating, SKU, image, and URL
- Save all results into a clean CSV file
- Loop through all the pages of a category
Full code for both scrapers, available on GitHub. ⚙
Let’s start by understanding why scraping Best Buy is (almost) impossible.
Why Is Scraping Best Buy (Almost) Impossible?
Because everything about the site is built to block you, even if it might be unintentional.
It’s one of the most aggressively protected e-commerce platforms combining IP-based geo restrictions, JavaScript-only content, and session-dependent routing.
Let’s look at the two main problems:
Aggressive IP Monitoring
Best Buy doesn’t ship outside the US and Canada and their entire frontend is built around that.
Every time you visit with a fresh IP or no cookies, you're intercepted by a country selection screen asking whether you're shopping from the US or Canada.
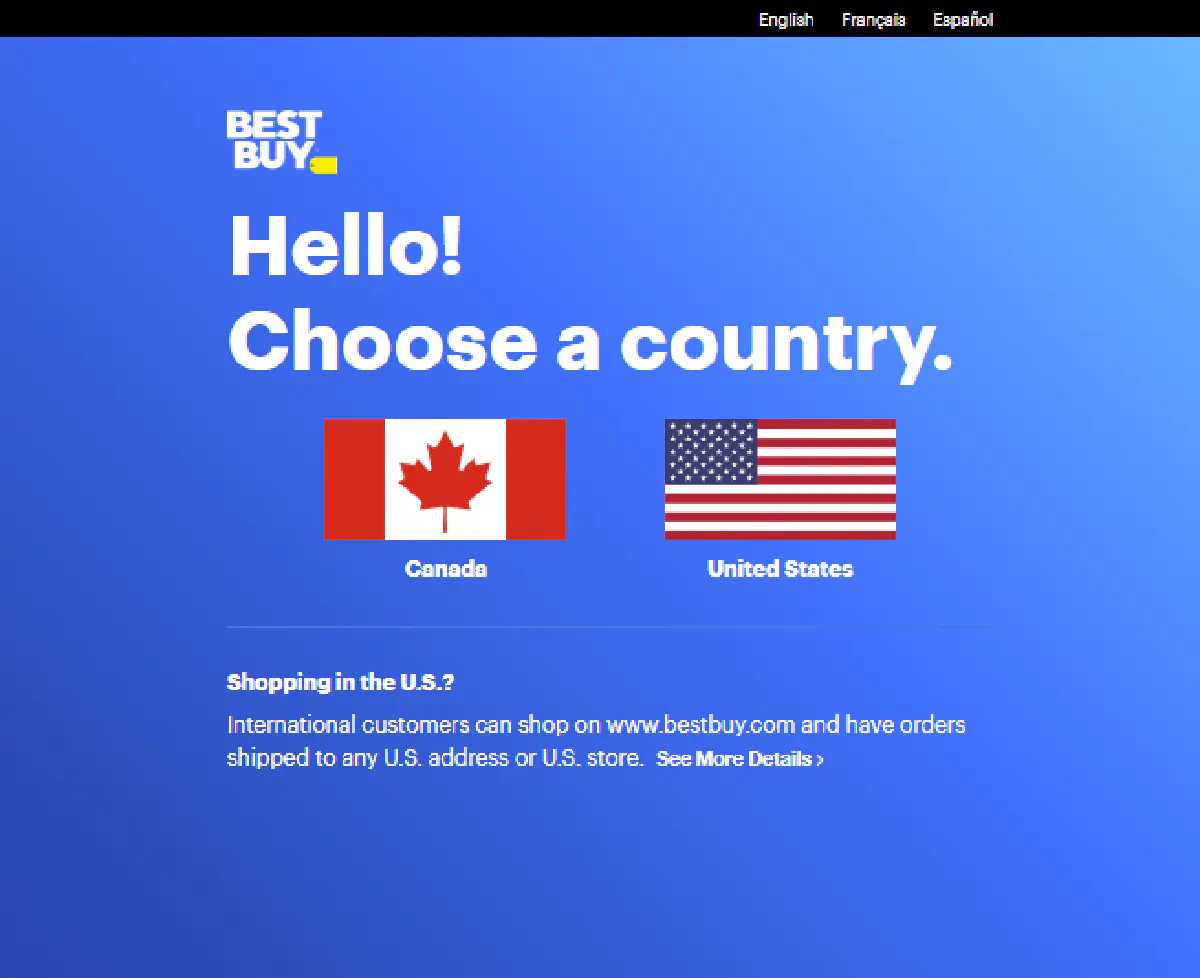
This happens regardless of the page you’re trying to access; product, category, or even the homepage.
If you're scraping with default settings or from an unsupported country, you’ll never reach the actual content.
This means every request must:
- Route through a US or Canadian residential IP
- Include valid cookies that simulate a returning user
- And simulate the action of clicking that country selection button
Otherwise, you’re stuck at the gate.
Heaviest JavaScript Rendering You'll See
Even if you get past the geo wall, requests still won’t help you.
That’s because none of the product data is served in the initial HTML.
Best Buy renders everything including product listings, prices, images, and pagination through JavaScript in the browser.
And that’s just the first layer.
Once the page loads, you still have to scroll to trigger lazy loading, otherwise you'll only see the first product.
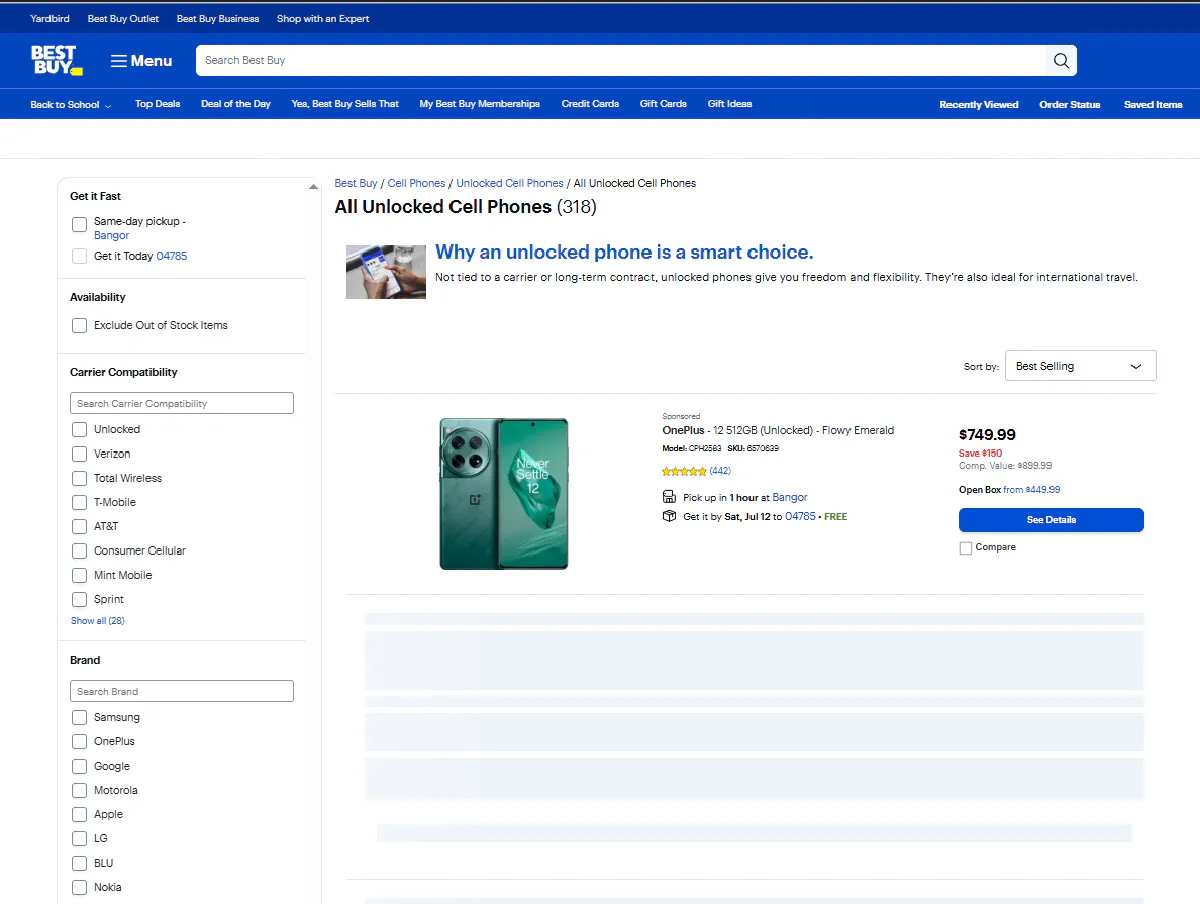
Products are injected in batches as you scroll down, so even if you're using a headless browser, you won’t get the full product list unless you emulate user scrolling behavior.
Scraping JavaScript-rendered pages is not an easy task, so you need a real browser (so scrape with Selenium or with a headless scraping API that supports full rendering and interaction). Otherwise, you're not getting anything.
Option #1: Python and Selenium for Small Projects
If you’re just trying to scrape a few category pages (or you only need to run your scraper once or twice) Selenium is a perfectly valid choice.
It gives you full control over browser behavior, can handle scrolling and country selection, and doesn’t require any paid services to get started.
But there’s a catch.
Selenium scrapers run on your own hardware, which means they’ll eat up CPU and memory.
On top of that, unless you're rotating proxies and spoofing headers manually, your scraper will eventually get blocked either by IP, fingerprint, or behavior pattern.
Yes, you can buy rotating proxy plans and yes, you can rotate headers and user agents yourself.
But you’ll end up paying for infrastructure and maintenance while still fighting blocks and breakage every time Best Buy updates something. So probably not worth it for large-scale projects.
Still, for one-off jobs or local experiments, Selenium gets the job done. ✅
Let’s set it up.
Setup
We’ll be using selenium with Chrome and a few options to reduce detection.
Start by installing the required package:
pip install seleniumThen make sure you have Chrome installed, along with the matching version of chromedriver.
You can either manage this manually or use webdriver-manager, but for this guide, we’ll assume chromedriver is already in your PATH.
Here’s the basic setup code:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--disable-blink-features=AutomationControlled')
# options.add_argument('--headless') # Uncomment if you want headless mode
driver = webdriver.Chrome(options=options)This initializes a Chrome instance with automation features partially hidden. Headless mode is optional but useful for running on servers or CI systems.
Now that the browser is running, we’ll start by selecting the US as our browsing country.
Select US from Country Screen
Every fresh visit to Best Buy starts with the same prompt:
“Are you shopping from the United States or Canada?”
Until you click an option, you won’t see any real content just a splash screen.
This step must be automated, or you’ll be stuck before you even reach the product listings.
Here's how we handle it with Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Set up Chrome options
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--disable-blink-features=AutomationControlled')
# options.add_argument('--headless') # Uncomment for headless mode
# Initialize the driver
driver = webdriver.Chrome(options=options)
try:
# Load the first page in the category
base_url = "https://www.bestbuy.com/site/searchpage.jsp?browsedCategory=pcmcat311200050005&cp=1&id=pcat17071&st=categoryid%24pcmcat311200050005"
driver.get(base_url)
# Wait for the country selection button and click "US"
us_link = WebDriverWait(driver, 15).until(
EC.element_to_be_clickable((By.CLASS_NAME, 'us-link'))
)
us_link.click()
# Wait a few seconds for the actual content to load
time.sleep(6)
finally:
# Close the browser
driver.quit()After this, you’ll be inside the real Best Buy site, ready to visit any page, including full category listings.
Scroll Down to Load All Products
We need to scroll slowly and repeatedly update the total height of the page otherwise, we’ll miss items that load in waves.
Here’s the exact scroll logic that is bulletproof:
# Scroll to the bottom to load all products
scroll_pause = 0.5
last_height = driver.execute_script("return window.scrollY")
total_height = driver.execute_script("return document.body.scrollHeight")
step = 400
current_position = 0
while current_position < total_height:
driver.execute_script(f"window.scrollTo(0, {current_position});")
time.sleep(scroll_pause)
current_position += step
total_height = driver.execute_script("return document.body.scrollHeight")
driver.execute_script(f"window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3)This logic gradually scrolls the page in steps of 400 pixels, giving time for each batch of products to render. The total_height is recalculated inside the loop, ensuring we scroll all the way to the dynamically adjusted bottom.
Once this block runs, all product cards will be present in the DOM and ready to be parsed.
Parse All Product Information
We can now start extracting product data.
Each product is contained inside a li.product-list-item. We'll loop through these and extract:
BrandandProduct Titlefromh2.product-titleImagefromdiv.product-image imgPricefromdiv.customer-price.mediumModelandSKUfromdiv.product-attributes
Here’s the exact parsing loop:
# Scrape product details from li.product-list-item
product_items = driver.find_elements(By.CSS_SELECTOR, 'li.product-list-item')
print(f"Found {len(product_items)} product-list-item elements on page {page_num}.")
for idx, item in enumerate(product_items, 1):
# Brand and Product Title
brand = None
product_title = None
try:
h2 = item.find_element(By.CSS_SELECTOR, 'h2.product-title')
try:
brand_span = h2.find_element(By.CSS_SELECTOR, 'span.first-title')
brand = brand_span.text.strip()
except:
brand = None
full_title = h2.text.strip()
if brand and full_title.startswith(brand):
product_title = full_title[len(brand):].strip(' -\n')
else:
product_title = full_title
except:
brand = None
product_title = None
# Image source
img_src = None
try:
img = item.find_element(By.CSS_SELECTOR, 'div.product-image.m-100 img')
img_src = img.get_attribute('src')
except:
img_src = None
# Product price
price = None
try:
price_div = item.find_element(By.CSS_SELECTOR, 'div.customer-price.medium')
price = price_div.text.strip()
except:
price = None
# Model and SKU
model = None
sku = None
try:
attr_divs = item.find_elements(By.CSS_SELECTOR, 'div.product-attributes div.attribute')
if len(attr_divs) > 0:
model_span = attr_divs[0].find_element(By.CSS_SELECTOR, 'span.value')
model = model_span.text.strip()
if len(attr_divs) > 1:
sku_span = attr_divs[1].find_element(By.CSS_SELECTOR, 'span.value')
sku = sku_span.text.strip()
except:
model = None
sku = None
all_products.append({
'Brand': brand,
'Product Title': product_title,
'Image': img_src,
'Price': price,
'Model': model,
'SKU': sku
})This runs for every page in the loop and appends each product to the all_products list.
Export Data to CSV
After collecting all the product details into all_products, we’ll export everything to a CSV file for easier analysis.
The script below saves the file in your system’s Downloads folder and writes all product attributes as columns:
# --- Save to CSV ---
downloads = os.path.join(os.path.expanduser('~'), 'Downloads')
csv_path = os.path.join(downloads, 'bestbuy_products.csv')
print(f"\nSaving product data to {csv_path} ...")
with open(csv_path, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Brand', 'Product Title', 'Image', 'Price', 'Rating', 'SKU', 'URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for product in all_products:
writer.writerow(product)
print(f"Saved {len(all_products)} products to CSV.")This will generate a CSV like:
Brand,Product Title,Image,Price,Rating,SKU,URL
BLU,G35 32GB (Unlocked) - Gray,[image-link],$64.99,Rating 3.7 out of 5 stars with 75 reviews,6645951,https://...
Apple,iPhone 15 128GB (Unlocked) - Blue,[image-link],$629.99,Rating 4.8 out of 5 stars with 1239 reviews,6418031,https://...
...At this point, your dataset is complete and saved locally, but we're not done yet.
Loop Through All Pages in a Category
Best Buy doesn’t use classic pagination with fixed product counts, you need to visit each page manually using the cp query parameter in the URL.
Our script loops all pages starting with the first one, runs the scroll + parse logic on each, and aggregates the results until it can't find anymore.
This is handled here:
# Aggregate all products from all pages, add after clicking US
all_products = []
start_time = time.time()
page_num = 1
while True:
print(f"\n--- Scraping page {page_num} ---")
page_url = base_url.format(cp=page_num)
driver.get(page_url)
time.sleep(3) # Wait for page to load
# Scroll to the bottom to load all products
<--- Same as before --->
# Add right after "print(f"Found {len(product_items)}..." line
if len(product_items) == 0:
print(f"No products found on page {page_num}. Stopping.")
breakAfter scraping all 15 pages, we calculate and print how long it took:
# Print total elapsed time
elapsed = time.time() - start_time
print(f"\nTotal elapsed time: {elapsed:.2f} seconds ({elapsed/60:.2f} minutes)")And finally, we close the browser:
finally:
driver.quit()
print("Browser closed.")That’s the full flow from launching the browser to exporting every phone listing in the category.
This is what the output will look like:
It takes around 5 minutes to do this for the unlocked phones category, might take less or more depending on the page number in the category.
Not bad for personal projects. But if you're going to up the scale, you might need something more efficient:
Option #2: Python Requests and Scrape.do API for Large-Scale Projects
If you're scraping hundreds of products or running on a schedule, you need a better tool.
Scrape.do makes it possible to handle:
- JavaScript rendering
- Country-based redirects
- Proxy rotation
- Interaction simulation
- Asynchronous scraping
…all in a single API call.
You don’t need to maintain proxies, render browsers locally, or figure out how to click buttons and scroll from your own machine.
Let’s break it down step by step.
Setup
Make sure you have the following installed:
pip install requests beautifulsoup4Then sign up at Scrape.do and get your API key.
We'll be using the Unlocked Phones listing again:
TARGET_URL = "https://www.bestbuy.com/site/searchpage.jsp?browsedCategory=pcmcat311200050005&cp=1&id=pcat17071&st=categoryid%24pcmcat311200050005"Once everything is ready, we can build the API call.
Building API Call to Bypass Country Select Page
First things first, we need to click and pick a country.
Or not.
Instead of simulating this click manually, Scrape.do lets us bypass it entirely using a few smart parameters:
super=trueroutes your request through high-quality residential proxiesgeoCode=usmakes sure the request originates from the United StatessetCookies=locDestZip%3D04785%3B%20locStoreId%3D463tricks Best Buy into thinking you’ve already picked a store and zip coderender=trueuses a headless browser to fully load JavaScript-rendered contentblockResources=falseensures that nothing is skipped during page load (we need everything)customWait=5000waits 5 seconds after rendering starts, enough to get the initial product HTML
Here’s how that looks in code:
import requests
import urllib.parse
from bs4 import BeautifulSoup
TOKEN = "<your-token>"
TARGET_URL = "https://www.bestbuy.com/site/searchpage.jsp?browsedCategory=pcmcat311200050005&cp=1&id=pcat17071&st=categoryid%24pcmcat311200050005"
api_url = (
"https://api.scrape.do/?"
f"url={urllib.parse.quote_plus(TARGET_URL)}"
f"&token={TOKEN}"
f"&super=true"
f"&render=true"
f"&blockResources=false"
f"&setCookies=locDestZip%3D04785%3B%20locStoreId%3D463"
f"&geoCode=us"
f"&customWait=5000"
)
response = requests.get(api_url)
html = response.text
soup = BeautifulSoup(html, "html.parser")This will bypass the splash screen and give us the first wave of rendered content, usually one product card, which we’ll extract next.
Parsing Product Information
We might have just one product, but we can still test if the setup works by parsing that first product card and handle our parsing logic in the meantime.
Let’s extract the following from product container with class li.product-list-item:
- Brand and Product Title (located inside an h3 element with class
product-title) - Image (located on an img element with
data-testid="product-image") - Price (located inside a div element with
data-testid="price-block-customer-price") - Rating (located inside a p element with class
visually-hiddenwithin the ratings container) - SKU (stored as the
data-testidattribute on theli.product-list-itemelement itself) - URL (located on the a element with class
product-list-item-link)
Here’s the full parsing code, continuing from the previous block:
all_products = []
product_items = soup.select('li.product-list-item')
print(f"Found {len(product_items)} product-list-item elements.")
for idx, item in enumerate(product_items, 1):
# Skip skeleton placeholders (lazy-loaded items that haven't rendered)
if item.select_one('.skeleton-product-grid-view'):
continue
# Brand and Product Title
brand = None
product_title = None
title_tag = item.select_one('.product-title')
if title_tag:
brand_span = title_tag.find('span', class_='first-title')
if brand_span:
brand = brand_span.get_text(strip=True)
full_title = title_tag.get('title') or title_tag.get_text(strip=True)
if brand and full_title.startswith(brand):
product_title = full_title[len(brand):].strip(' -\n')
else:
product_title = full_title
# Image source
img_src = None
img = item.select_one('img[data-testid="product-image"]')
if not img:
img = item.select_one('div.product-image img')
if img:
img_src = img.get('src')
# Product price
price = None
price_el = item.select_one('[data-testid="price-block-customer-price"] span')
if price_el:
price = price_el.get_text(strip=True)
# Rating
rating = None
rating_el = item.select_one('.c-ratings-reviews p.visually-hidden')
if rating_el:
rating = rating_el.get_text(strip=True)
# SKU (stored as data-testid on the li element)
sku = item.get('data-testid')
# Product URL
product_url = None
link = item.select_one('a.product-list-item-link')
if link:
href = link.get('href', '')
if href.startswith('/'):
product_url = 'https://www.bestbuy.com' + href
else:
product_url = href
all_products.append({
'Brand': brand,
'Product Title': product_title,
'Image': img_src,
'Price': price,
'Rating': rating,
'SKU': sku,
'URL': product_url
})
for product in all_products:
print(product)If everything’s working, you’ll see a single product printed to your terminal, proof that your API call, rendering, and parsing logic are solid:
BLU,G35 32GB (Unlocked) - Gray,[image-link],$64.99,Rating 3.7 out of 5 stars with 75 reviews,6645951,https://www.bestbuy.com/product/...But we're here for it all.
Scrolling & Loading All Products in a Results Page
To load every product in a Best Buy category, you can’t just wait, you have to interact.
That’s where playWithBrowser comes in.
It lets you simulate real browser actions like scrolling, executing JavaScript, and waiting inside Scrape.do’s headless browser environment.
It took us a few tries to get this right, but here's how we make sure we load all products with this parameter.
Let’s break down what we do:
# Add after URL and Scrape.do token configuration
play_with_browser = [
{
"action": "WaitSelector", # Wait until a product price element appears
"timeout": 30000,
"waitSelector": "[data-testid='price-block-customer-price']"
},
{
"action": "Execute", # Gradually scroll the page to trigger lazy loading
"execute": "(async()=>{let h=document.body.scrollHeight,step=400,pos=0;while(pos<h){window.scrollTo(0,pos);pos+=step;await new Promise(r=>setTimeout(r,500));h=document.body.scrollHeight;}window.scrollTo(0,h);})();"
},
{
"action": "Wait", # Wait for lazy-loaded products to render
"timeout": 3000
},
{
"action": "Execute", # Wait until all skeleton placeholders are gone
"execute": "(async()=>{for(let i=0;i<20;i++){if(!document.querySelector('.skeleton-product-grid-view'))break;await new Promise(r=>setTimeout(r,500));}})();"
},
{
"action": "Wait", # Final buffer for rendering
"timeout": 1000
}
]Once this sequence is built, we convert it to a URL-safe string and insert it into our API request.
Here’s the full request code using playWithBrowser and proper waitUntil=load and timeout:
# We need json library for this so import that
import json
# Add right after URL and token configuration
play_with_browser = [ ... ] # Use the exact list above
# We need to parse the playWithBrowser actions to add it to our API call safely
jsonData = urllib.parse.quote_plus(json.dumps(play_with_browser))
# We're using Scrape.do to its full extent, updating our parameters
api_url = (
"https://api.scrape.do/?"
f"url={urllib.parse.quote_plus(TARGET_URL)}"
f"&token={TOKEN}"
f"&super=true"
f"&render=true"
f"&playWithBrowser={jsonData}" # our browser interactions
f"&blockResources=false"
f"&setCookies=locDestZip%3D04785%3B%20locStoreId%3D463"
f"&geoCode=us"
f"&waitUntil=load" # wait until everything's loaded to parse
f"&timeout=120000" # if we're stuck, fail after 120 seconds
)
...⚠ Since we're using multiple actions and parameters, your request might have decreased success rate. We'll add retries in the next sessions.
If all actions are executed successfully, the entire category page will be loaded with all visible products, and we can now parse the result just like before.
However, since we'll have hundreds of results, it's a terrible practice to print output to terminal.
So we make a small adjustment:
Exporting Product Results to CSV
Once all products are loaded and parsed into all_products, we can write them to a CSV file just like we did with the Selenium version.
This makes it easy to filter, analyze, or import the data elsewhere.
Add the following to the bottom of your script:
import csv
with open('bestbuy_products.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Brand', 'Product Title', 'Image', 'Price', 'Rating', 'SKU', 'URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for product in all_products:
writer.writerow(product)
print("Products saved to bestbuy_products.csv")This saves your results into a file in the same directory, with one row per product:
Brand,Product Title,Image,Price,Rating,SKU,URL
BLU,G35 32GB (Unlocked) - Gray,[image-link],$64.99,Rating 3.7 out of 5 stars with 75 reviews,6645951,https://www.bestbuy.com/product/...
Apple,iPhone 15 128GB (Unlocked) - Blue,[image-link],$629.99,Rating 4.8 out of 5 stars with 1239 reviews,6418031,https://www.bestbuy.com/product/...
... more products ...
Samsung,Galaxy A16 5G 128GB (Unlocked) - Blue Black,[image-link],$154.99,Rating 4.4 out of 5 stars with 1486 reviews,6607858,https://www.bestbuy.com/product/...Looping Through All Category Pages and Including Retries
Best Buy’s category pages are split across multiple cp= query parameters (cp=1, cp=2, cp=3…). To finalize our code and start collecting all the data we need, we have to loop through all pages of a category.
But we also need to add some precaution for fails.
Because the page is so heavy and interaction-sensitive, some requests might fail or return incomplete data even with a browser renderer.
To solve this, we:
- Loop through all pages starting from
cp=1 - If printed results are higher than 18 products, move to next page ✅
- When a page returns 0 or fewer than 18 products, retry 3 more times ❌
- If no products are returned after all 4 tries, looping is done
- Save everything to a CSV at the end
Here’s the complete script:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import json
import time
import csv
TOKEN = "<your-token>"
BASE_URL = "https://www.bestbuy.com/site/searchpage.jsp?browsedCategory=pcmcat311200050005&cp={cp}&id=pcat17071&st=categoryid%24pcmcat311200050005"
play_with_browser = [
{
"action": "WaitSelector",
"timeout": 30000,
"waitSelector": "[data-testid='price-block-customer-price']"
},
{
"action": "Execute",
"execute": "(async()=>{let h=document.body.scrollHeight,step=400,pos=0;while(pos<h){window.scrollTo(0,pos);pos+=step;await new Promise(r=>setTimeout(r,500));h=document.body.scrollHeight;}window.scrollTo(0,h);})();"
},
{
"action": "Wait",
"timeout": 3000
},
{
"action": "Execute",
"execute": "(async()=>{for(let i=0;i<20;i++){if(!document.querySelector('.skeleton-product-grid-view'))break;await new Promise(r=>setTimeout(r,500));}})();"
},
{
"action": "Wait",
"timeout": 1000
}
]
def get_products_from_page(cp):
url = BASE_URL.format(cp=cp)
jsonData = urllib.parse.quote_plus(json.dumps(play_with_browser))
api_url = (
"https://api.scrape.do/?"
f"url={urllib.parse.quote_plus(url)}"
f"&token={TOKEN}"
f"&super=true"
f"&render=true"
f"&playWithBrowser={jsonData}"
f"&blockResources=false"
f"&setCookies=locDestZip%3D04785%3B%20locStoreId%3D463"
f"&geoCode=us"
f"&waitUntil=load"
f"&timeout=120000"
)
response = requests.get(api_url)
if response.status_code != 200:
print(f" HTTP error: {response.status_code}")
return []
html = response.text
soup = BeautifulSoup(html, "html.parser")
product_items = soup.select('li.product-list-item')
products = []
for item in product_items:
if item.select_one('.skeleton-product-grid-view'):
continue
brand = None
product_title = None
title_tag = item.select_one('.product-title')
if title_tag:
brand_span = title_tag.find('span', class_='first-title')
if brand_span:
brand = brand_span.get_text(strip=True)
full_title = title_tag.get('title') or title_tag.get_text(strip=True)
if brand and full_title.startswith(brand):
product_title = full_title[len(brand):].strip(' -\n')
else:
product_title = full_title
img_src = None
img = item.select_one('img[data-testid="product-image"]')
if not img:
img = item.select_one('div.product-image img')
if img:
img_src = img.get('src')
price = None
price_el = item.select_one('[data-testid="price-block-customer-price"] span')
if price_el:
price = price_el.get_text(strip=True)
rating = None
rating_el = item.select_one('.c-ratings-reviews p.visually-hidden')
if rating_el:
rating = rating_el.get_text(strip=True)
sku = item.get('data-testid')
product_url = None
link = item.select_one('a.product-list-item-link')
if link:
href = link.get('href', '')
if href.startswith('/'):
product_url = 'https://www.bestbuy.com' + href
else:
product_url = href
products.append({
'Brand': brand,
'Product Title': product_title,
'Image': img_src,
'Price': price,
'Rating': rating,
'SKU': sku,
'URL': product_url
})
return products
def main():
all_products = []
cp = 1
while True:
print(f"Scraping page {cp}...")
attempts = 0
products = []
while attempts < 4:
products = get_products_from_page(cp)
valid = any(p.get('Product Title') and p.get('Price') for p in products)
print(f" Attempt {attempts+1}: Found {len(products)} products, data valid: {valid}")
if len(products) >= 18 and valid:
break
attempts += 1
if attempts < 4:
time.sleep(2)
if not products or len(products) < 1:
print(f"No products found on page {cp}. Stopping.")
break
all_products.extend(products)
cp += 1
time.sleep(1)
print(f"Total products scraped: {len(all_products)}")
# Write to CSV
with open('bestbuy_products_scrapedo.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Brand', 'Product Title', 'Image', 'Price', 'Rating', 'SKU', 'URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for product in all_products:
writer.writerow(product)
print("Products written to bestbuy_products_scrapedo.csv")
if __name__ == "__main__":
main()This version is production-ready. It handles Best Buy’s dynamic loading, simulates interaction, retries failed pages, and saves everything to disk.
Here's what the CSV file will look like:
Conclusion
Scraping Best Buy is one of the toughest challenges you’ll face in web scraping.
Between aggressive IP filtering, country gating, and dynamic rendering, it throws every kind of obstacle your way.
But once you understand how to control a headless browser, simulate real user behavior, and retry intelligently when things go wrong; you’ve basically unlocked the playbook for scraping any complex site on the web.
With Scrape.do, you don’t need to manage proxies, handle browser execution, or build retry logic from scratch.
Just send a request, and get clean, rendered data back.
- ✅ Unblocked access with geo-targeted residential IPs
- 🧠 Smart browser automation with
playWithBrowser - 💨 Fast, stable infrastructure built for scale
Get 1000 free credits and start scraping Best Buy with Scrape.do.
Founder @ Scrape.do








