Category:Scraping Use Cases
Scrape Restaurant Listings and Menus from HungerStation with Python

Full Stack Developer



HungerStation is Saudi Arabia's #1 food delivery platform, but scraping it is nearly impossible.
From heavy geo-blocking to aggressive Cloudflare defenses, most bots fail before they load a single menu.
In this guide, we’ll show you exactly how to bypass these obstacles using Scrape.do and extract store and menu data reliably even if you’re not located in Saudi Arabia.
Access full code on GitHub repository ⚙
Why Is Scraping HungerStation Difficult?
Scraping HungerStation isn’t like scraping a typical food delivery site.
It’s built for users in Saudi Arabia and it makes that very clear.
Every piece of content you care about (restaurants, menus, prices) is strictly geo-restricted. If you’re outside KSA, you’ll either see a generic homepage or get blocked outright.
And even if you manage to access it from the right region, you’re not in the clear yet, because Cloudflare is on top of everything.
Intense Geo-Restriction
HungerStation’s data is locked behind location-based access.
Unless you're browsing from a Saudi Arabian IP address, you can't view local restaurants or even load their menus.
This is what happens when you try to view restaurants in a specific region or a restaurant page without the right IP:
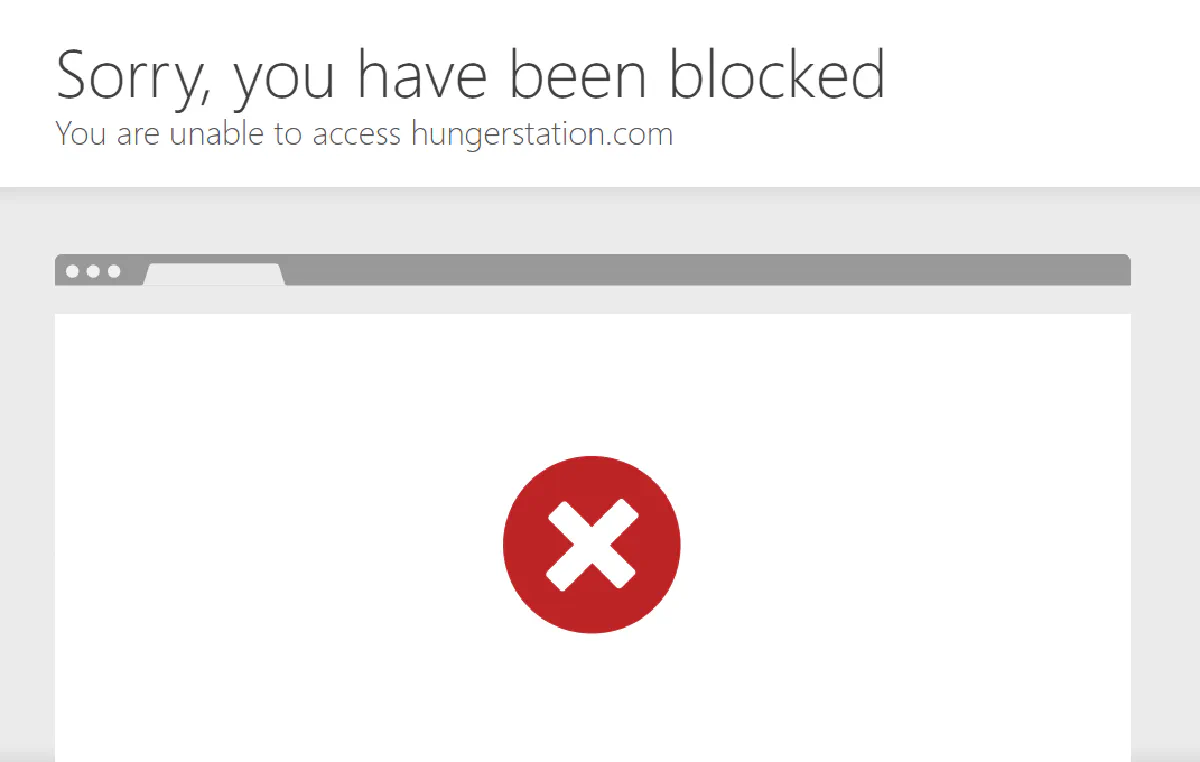
That’s why basic proxy rotation doesn’t work. Without premium Saudi IPs, you're not even accessing the site, let alone scrape it.
And this geo-layer is just the first line of defense.
Heavy Cloudflare Protection
Even if you're connecting from inside Saudi Arabia, HungerStation still won’t make it easy.
It uses Cloudflare to monitor how fast you’re navigating even when you're just browsing manually.
Open a few pages too quickly and you'll hit a rate limit or get temporarily blocked.
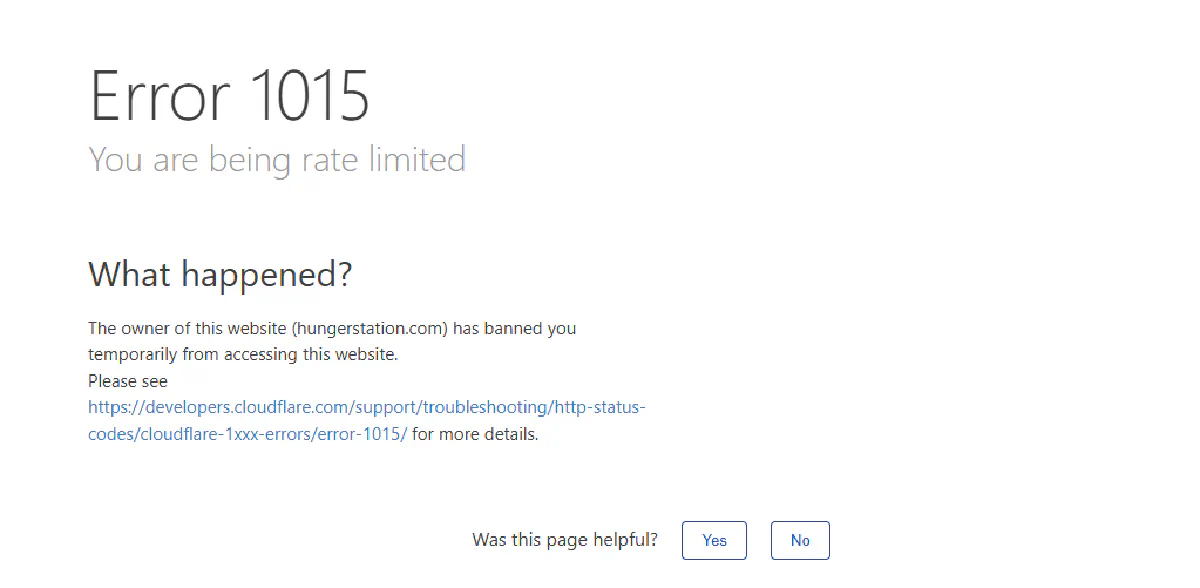
These rate limits reset in a few minutes, but when you're scraping, you’ll trigger them constantly unless you handle sessions, headers, and request pacing just right.
It’s not just about having the right IP; it’s about looking like a real user, every single time.
How Scrape.do Helps
Scrape.do is built for exactly this kind of challenge.
It handles HungerStation’s defenses in two key ways:
- Premium Saudi Residential Proxies: your requests are routed through real residential IPs in Saudi Arabia, not datacenter proxies that get flagged instantly.
- Stealthy Session Management: Scrape.do rotates sessions, user agents, and TLS fingerprints so well that Cloudflare doesn’t even know you’re a bot.
There’s no need to manage headers or retry logic manually.
Just send your request and get clean, unblocked HTML or rendered output back.
Now let’s look at how to scrape stores from a specific city or region.
Scraping All Stores for a Region
Let’s start by scraping all restaurants listed in a specific region. For this example, we’ll focus on Al Jisr, Al Khobar.
We'll extract:
- Restaurant name
- Store link
- Category (e.g., Burgers, Pizza, Shawarma)
- Review rating
Setup
We’ll use three libraries in this scraper:
requeststo send HTTP requests through Scrape.doBeautifulSoupto parse the HTML contentcsvto store the scraped data in a structured format
Install them with:
pip install requests beautifulsoup4You’ll also need your Scrape.do API token.
Just head over to your Scrape.do Dashboard, and you’ll find it right at the top:
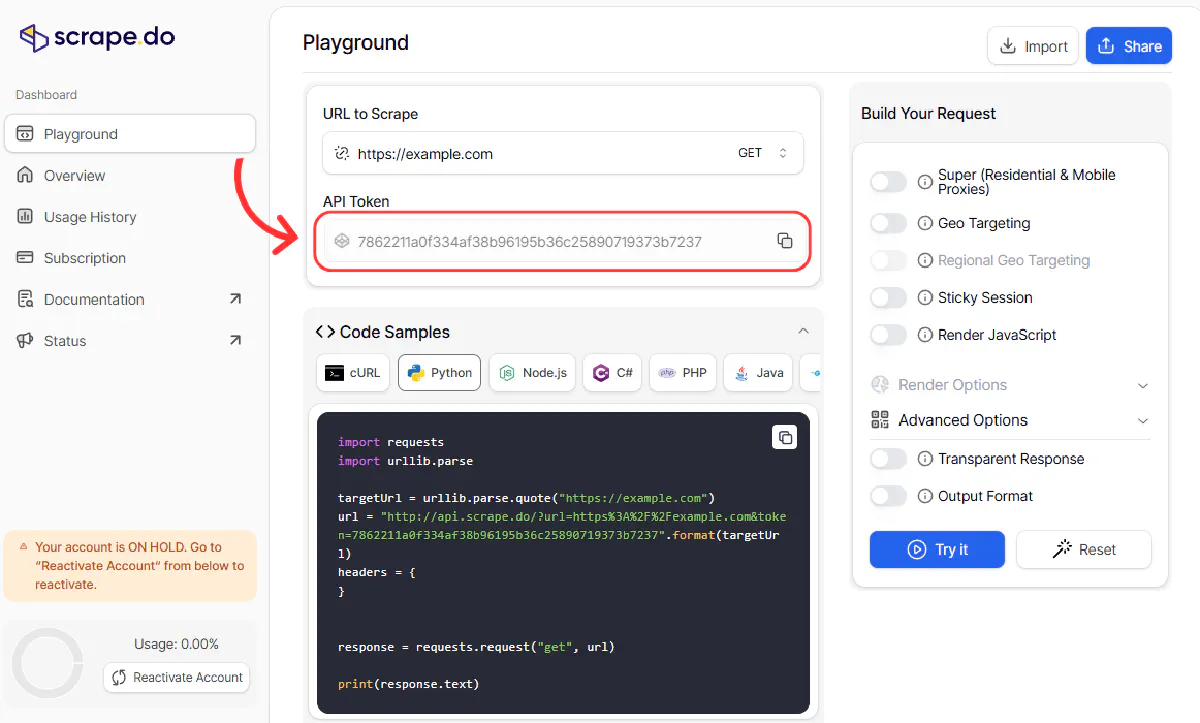
We’ll use this token in every request to route our scraping through Scrape.do’s Saudi Arabia proxies, bypassing both geo-restrictions and Cloudflare protection.
Building Your Request
Before we start scraping restaurant data, we need to make sure our request goes through and doesn’t get blocked or redirectad.
We’ll send our first request using Scrape.do, which handles proxy routing, session headers, and geo-targeting for us. All we care about is whether we get a clean 200 OK response.
import requests
import urllib.parse
# Your Scrape.do token
TOKEN = "<your-token>"
# Target URL (first page of Al Jisr, Al Khobar restaurants)
target_url = "https://hungerstation.com/sa-en/restaurants/al-khobar/al-jisr"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geoCode=sa&super=true"
response = requests.get(api_url)
print(response)If everything is working correctly, you should see:
<Response [200]>This means the request reached the real content, geo-restrictions and Cloudflare both bypassed.
If you see anything else (like <Response [403]> or a redirect page), double-check:
geoCode=sais present (to force a Saudi IP)super=trueis used (for premium proxy and header rotation)- Your token is valid and active
Now that we’ve confirmed access, we can start extracting restaurant data.
Parse Restaurant Information
If you inspect the page structure, each restaurant is listed inside an <li> element. Inside that, you’ll find:
h1.text-base→ store namea[href]→ link to the storep→ category (e.g., Pizza, Burger)span→ review rating
Here’s how we parse those details using BeautifulSoup:
from bs4 import BeautifulSoup
# ... same request code from previous step ...
soup = BeautifulSoup(response.text, "html.parser")
restaurants = []
for li in soup.select("ul > li"):
name_tag = li.find("h1", class_="text-base text-typography font-medium")
if not name_tag:
continue # skip non-restaurant items
store_name = name_tag.get_text(strip=True)
a = li.find("a", href=True)
store_link = "https://hungerstation.com" + a["href"] if a else ""
category_tag = li.find("p")
category = category_tag.get_text(strip=True) if category_tag else ""
rating_tag = li.find("span")
review_rating = rating_tag.get_text(strip=True) if rating_tag else ""
restaurants.append({
"store_link": store_link,
"store_name": store_name,
"category": category,
"review_rating": review_rating
})
print(restaurants)You should get a list of dictionaries with the 12 restaurants listed on the first page, but we need all of it.
Loop Through All Pages
HungerStation paginates its restaurant listings, so to get the full dataset, we’ll need to crawl through all pages until there are no more results.
Each page URL follows the same pattern:
https://hungerstation.com/sa-en/restaurants/al-khobar/al-jisr?page=2We’ll modify our code to:
- Add
?page=to the base URL - Keep requesting pages until we stop finding valid restaurant entries
Here’s how we do that:
restaurants = []
page = 1
while True:
url = f"https://hungerstation.com/sa-en/restaurants/al-khobar/al-jisr?page={page}"
encoded_url = urllib.parse.quote_plus(url)
api_url = f"https://api.scrape.do/?token={TOKEN}&url={encoded_url}&geoCode=sa&super=true"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
found = False
for li in soup.select("ul > li"):
name_tag = li.find("h1", class_="text-base text-typography font-medium")
if not name_tag:
continue
found = True
a = li.find("a", href=True)
store_link = "https://hungerstation.com" + a["href"] if a else ""
store_name = name_tag.get_text(strip=True)
category_tag = li.find("p")
category = category_tag.get_text(strip=True) if category_tag else ""
rating_tag = li.find("span")
review_rating = rating_tag.get_text(strip=True) if rating_tag else ""
restaurants.append({
"store_link": store_link,
"store_name": store_name,
"category": category,
"review_rating": review_rating
})
if not found:
break
print(f"Extracted page {page}")
page += 1This loop will automatically stop when it hits an empty page. You’ll see the progress printed for each page scraped.
Export to CSV
We’ll use Python’s built-in csv module to write the data to a file so we can use it for any purpose.
Here's the complete code with everything we've built so far:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import csv
# Your Scrape.do token
TOKEN = "<your-token>"
BASE_URL = "https://hungerstation.com/sa-en/restaurants/al-khobar/al-jisr"
API_URL_BASE = f"https://api.scrape.do/?token={TOKEN}&geoCode=sa&super=true&url="
restaurants = []
page = 1
while True:
url = f"{BASE_URL}?page={page}"
encoded_url = urllib.parse.quote_plus(url)
api_url = API_URL_BASE + encoded_url
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
found = False
for li in soup.select("ul > li"):
name_tag = li.find("h1", class_="text-base text-typography font-medium")
if not name_tag:
continue
found = True
a = li.find("a", href=True)
store_link = "https://hungerstation.com" + a["href"] if a else ""
store_name = name_tag.get_text(strip=True)
category_tag = li.find("p")
category = category_tag.get_text(strip=True) if category_tag else ""
rating_tag = li.find("span")
review_rating = rating_tag.get_text(strip=True) if rating_tag else ""
restaurants.append({
"store_link": store_link,
"store_name": store_name,
"category": category,
"review_rating": review_rating
})
if not found:
break
print(f"Extracted page {page}")
page += 1
# Write to CSV
with open("hungerstation_restaurants.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["store_link", "store_name", "category", "review_rating"])
writer.writeheader()
writer.writerows(restaurants)
print(f"Extracted {len(restaurants)} restaurants to hungerstation_restaurants.csv")This will output a file named hungerstation_restaurants.csv containing all scraped listings.
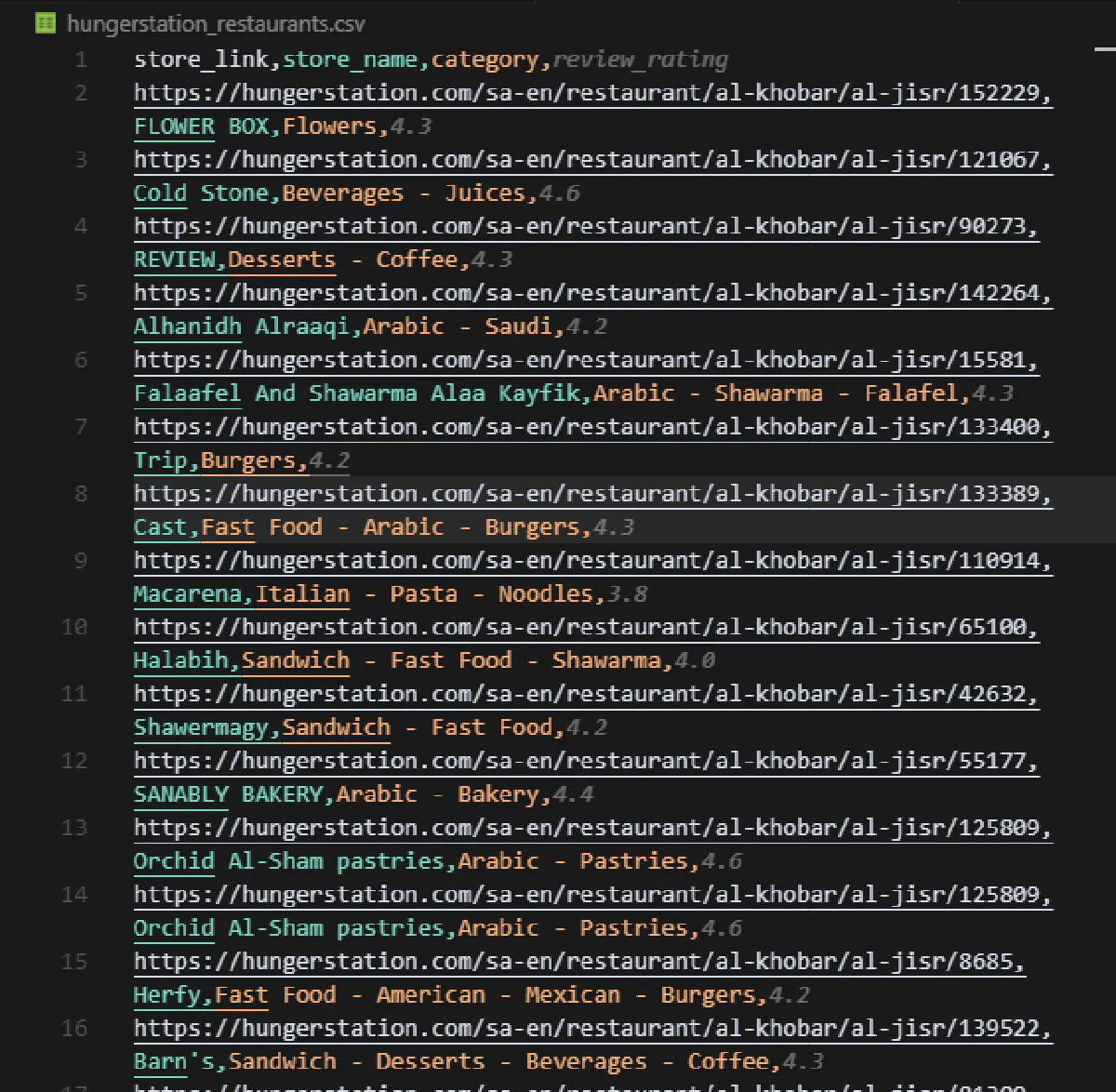
We have the restaurants, let's now scrape what they have in their menus:
Scraping All Items on Store Menus
Scraping a specific restaurant’s menu page is a bit more simple.
We'll target a Domino's in Al Jisr, because who doesn't like pizza:
https://hungerstation.com/sa-en/restaurant/al-khobar/al-jisr/13699We’ll send the request through Scrape.do, parse menu sections, extract item details, and save everything into a CSV.
We start by importing the libraries and defining our request:
import requests
from bs4 import BeautifulSoup
import csv
TOKEN = "<your-token>"
STORE_URL = "https://hungerstation.com/sa-en/restaurant/al-khobar/al-jisr/13699"
API_URL = f"https://api.scrape.do/?token={TOKEN}&url={STORE_URL}&geoCode=sa&super=true"Then we send our request and parse the page:
response = requests.get(API_URL)
soup = BeautifulSoup(response.text, "html.parser")Once we have the HTML content, we’ll create an empty list to store the menu items:
menu_items = []Now we’ll loop through all the category sections on the page.
Each section represents a category like “Burgers” or “Drinks.” These are marked with data-role="item-category":
for section in soup.find_all("section", attrs={"data-role": "item-category"}):
category = section.get("id") or ""Inside each section, each item is a button with class card p-6 menu-item.
We’ll loop through each and extract the name, description, price, and calorie info:
for item in section.find_all("button", class_="card p-6 menu-item"):
name_tag = item.find("h2", class_="menu-item-title")
name = name_tag.get_text(strip=True) if name_tag else ""
desc_tag = item.find("p", class_="menu-item-description")
description = desc_tag.get_text(strip=True) if desc_tag else ""
price_tag = item.find("p", class_="text-greenBadge text-base mx-2")
price = price_tag.get_text(strip=True) if price_tag else ""
cal_tag = item.find("p", class_="text-secondary text-base mx-2")
calories = cal_tag.get_text(strip=True) if cal_tag else ""Finally, we append the item to our list (but only if it has a valid name for product title):
if name:
menu_items.append({
"Category": category,
"Name": name,
"Description": description,
"Price": price,
"Calories": calories
})Once all the items are collected, we export them to a CSV:
with open("hungerstation_menu_items.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["Category", "Name", "Description", "Price", "Calories"])
writer.writeheader()
writer.writerows(menu_items)
print(f"Extracted {len(menu_items)} menu items to hungerstation_menu_items.csv")And when we run the full code, all the menu items will be written to a CSV, waiting for us:
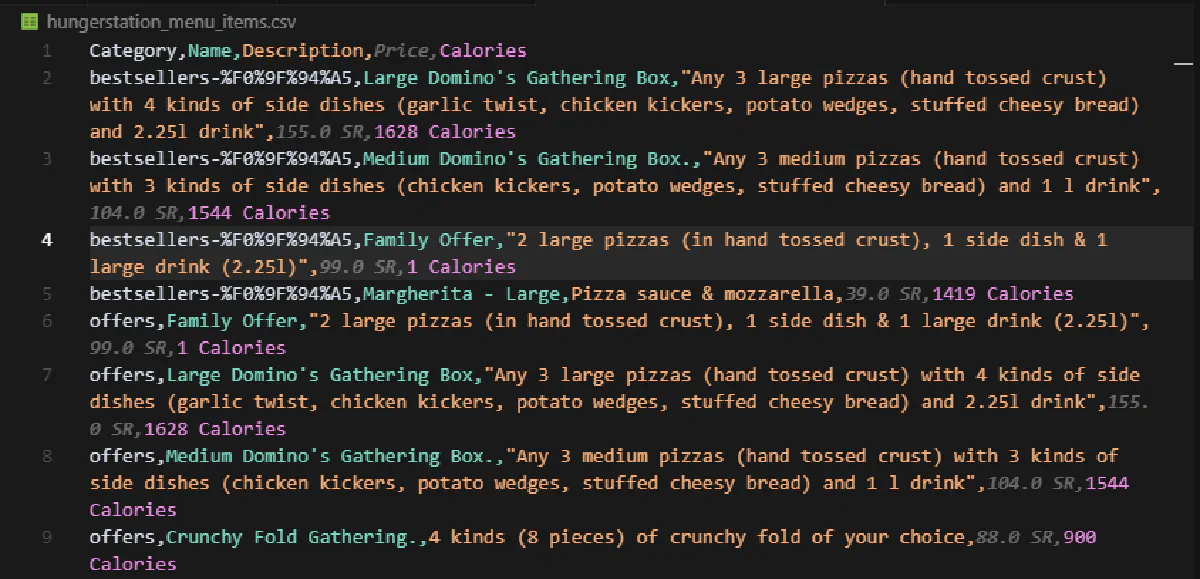
Congrats! You're now able to scrape HungerStation.
Conclusion
Scraping HungerStation isn't easy with strict geo-blocking and aggressive bot defenses, most scrapers fail before reaching the data.
But with Scrape.do, you can bypass those blocks effortlessly:
- Premium Saudi IPs 🇸🇦
- Smart session and header rotation 🔄
- Built-in Cloudflare and WAF bypass 🔑
Whether you're focused on HungerStation or building a complete system for scraping food delivery data across multiple platforms, the same core principles apply.
Full Stack Developer








