Category:Scraping Use Cases
FastPeopleSearch.com Data Extraction: Scrape Without Getting Blocked

R&D Engineer


⚠ No real data about a real person has been used in this article. Target URLs have been modified by hand to not reveal any personal information of a real person.
FastPeopleSearch.com lets you look up names, phone numbers, addresses, and public records: a completely free people search tool that doesn't require an account.
But scraping it is anything but simple.
The site is protected by Cloudflare, enforces strict anti-bot rules, and often won’t even load if you’re outside the US.
Even visiting the page from outside the US is a challenge, let alone scraping structured data from it.
In this guide, we’ll show you how to bypass those restrictions and extract clean, structured information using Python and Scrape.do.
Find fully functioning code here. ⚙
Why Is Scraping FastPeopleSearch.com Difficult?
FastPeopleSearch is one of the most aggressive websites at blocking automated access.
Whether you’re running a basic Python script or a full-scale web scraping setup, you’ll likely hit a dead end for one of two reasons:
Georestricted to US IPs Only
The first and most immediate problem is geography.
FastPeopleSearch is completely locked down to US-based traffic.
If your IP isn’t coming from within the United States, the site won’t even let you see the homepage. It just drops a generic block page with no explanation.
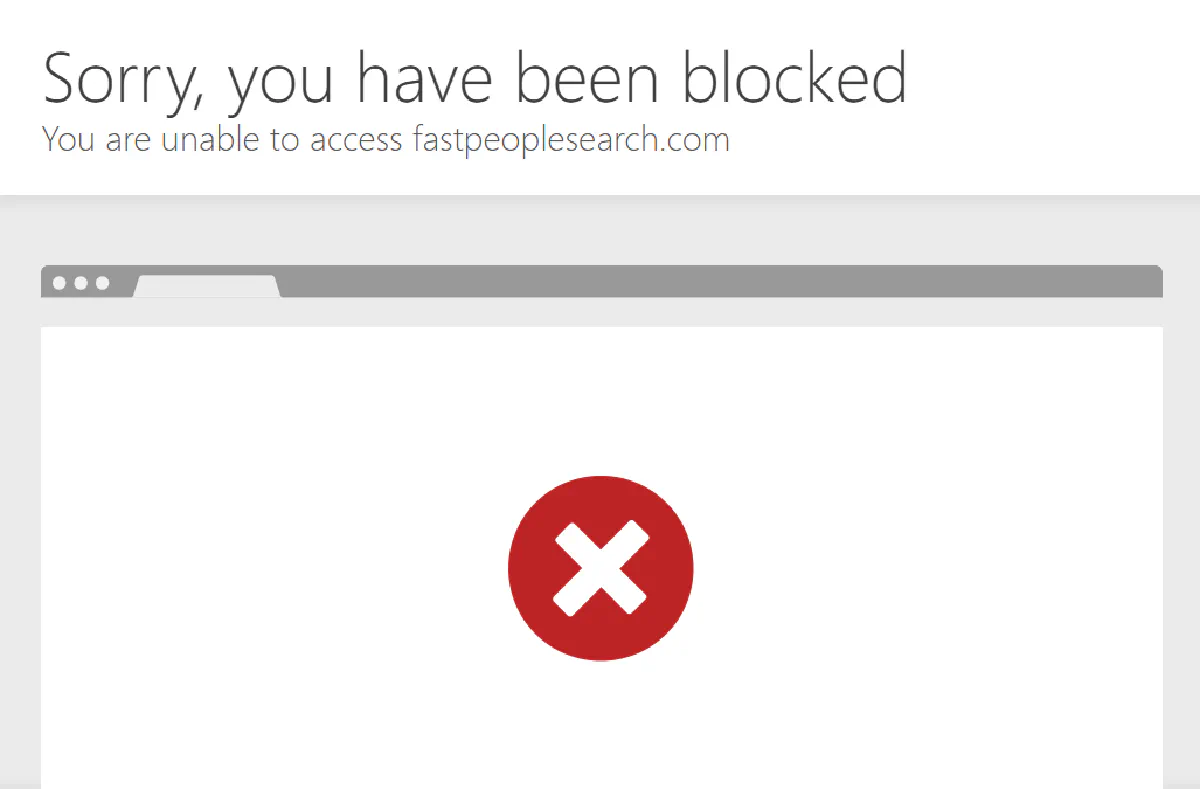
This makes it impossible to scrape the site from overseas without a reliable US proxy. FastPeopleSearch is a US-only service; if you're not coming from the United States, you're not getting in.
But even with the right IP address, you're still far from done.
Protected by Cloudflare
FastPeopleSearch sits behind Cloudflare’s anti-bot firewall, which automatically analyzes every request before letting it through.
These protections go far beyond simple rate limits or blacklists.
Even if your request comes from a US IP, Cloudflare steps in.
It challenges your scraper with JavaScript puzzles, fingerprint checks, and most commonly, CAPTCHAs.
If you're not rendering the page like a real browser (with all the required TLS fingerprints, header behavior, and timing), you’ll get stuck in a loop of unsolvable verification prompts.
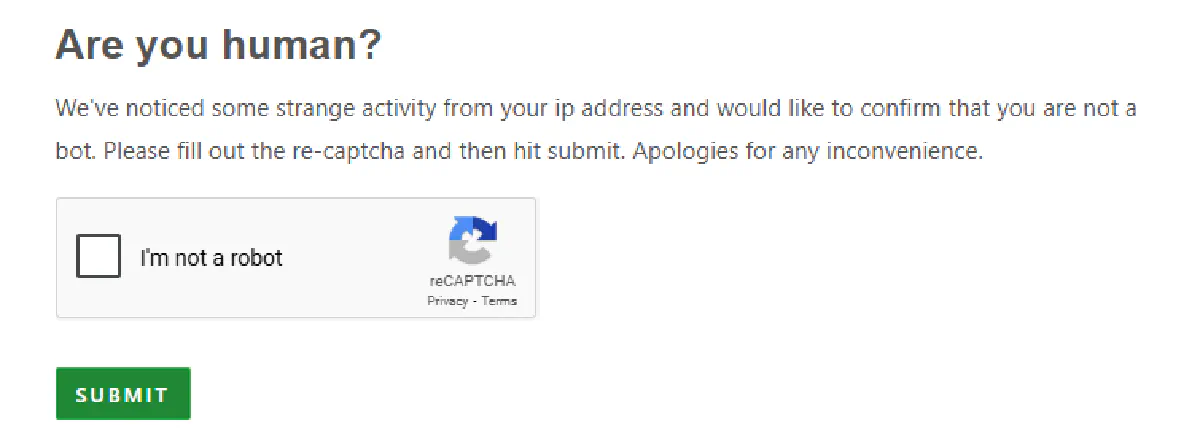
This means standard libraries like requests or basic proxy rotators are instantly flagged. You’ll need much more advanced tools just to get a 200 response let alone parse real data.
So standard libraries like requests or basic proxy rotators get flagged immediately. You need more than that to even get a 200 response.
How Scrape.do Bypasses These Blocks
Scrape.do solves both problems in a single request.
With super=true and geoCode=us, your traffic routes through clean US residential IPs, removing the geoblock instantly. No need to manage proxy pools or IP rotation yourself.
On top of that, the anti-bot engine handles Cloudflare’s JavaScript challenges, bypasses CAPTCHA triggers, and mimics real browser behavior with proper TLS fingerprints and dynamic headers.
You get back a fully rendered HTML page, ready to parse with BeautifulSoup.
FastPeopleSearch has no public API, so this proxy-based scraping approach is the only reliable path to extracting its data at scale.
Creating a Basic FastPeopleSearch.com Scraper
First things first; privacy.
This guide is for demonstration purposes, so we will not use real data from a real FastPeopleSearch result page. Instead, I've modified every detail on the target page below so it does not reveal any real information:
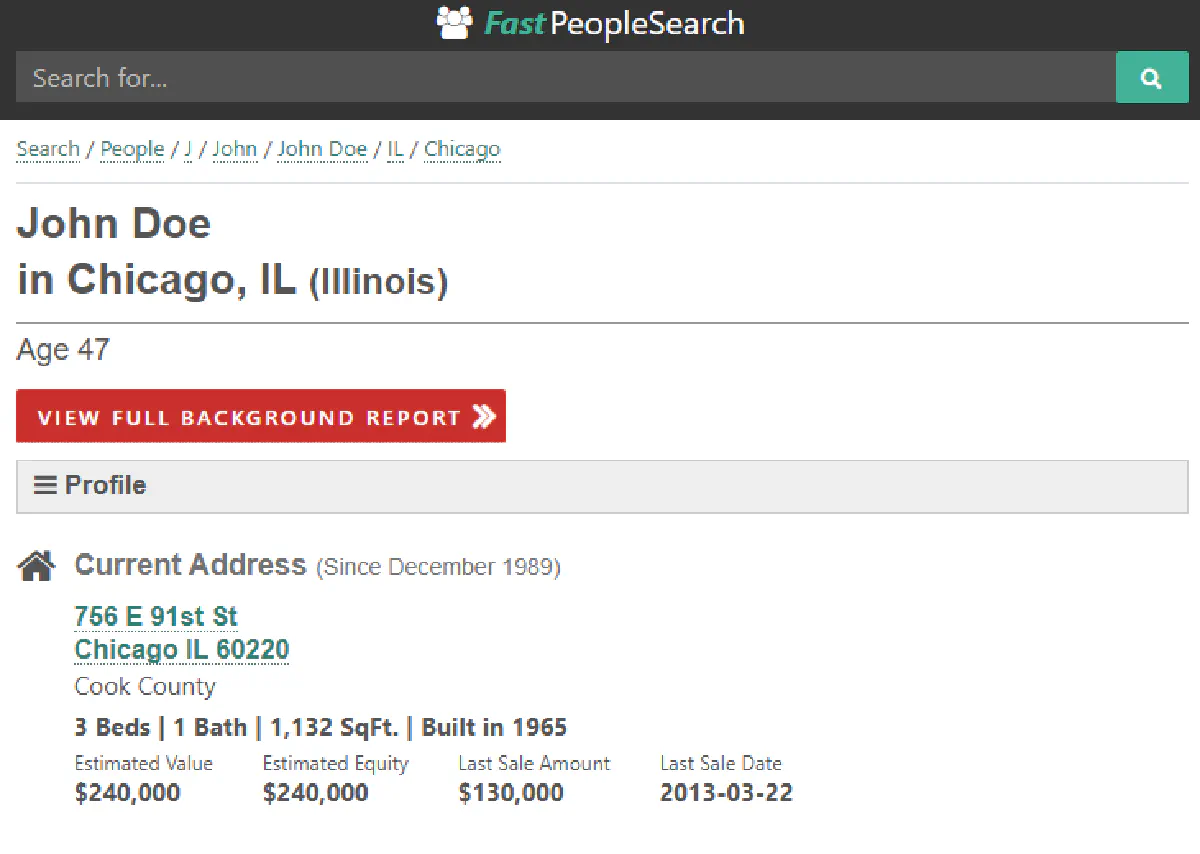
When you're giving it a go, don't forget to do a random search and use the URL of that result page.
Prerequisites
We’ll be using Python for this guide, along with two libraries: requests for sending HTTP requests, and BeautifulSoup for parsing the returned HTML.
If you don’t have them installed yet, run:
pip install requests beautifulsoup4You’ll also need an API key from Scrape.do, which you can get for free by signing up in <1min (no credit card required).
Sending a Request and Verifying Access
Once you have your token, it’s time to send your first request.
We’ll start by targeting a FastPeopleSearch profile page. The goal at this stage is simple: get a 200 OK response and confirm that the page is accessible and fully rendered.
Here’s how we do that using Scrape.do with geoCode=us and super=true:
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Your Scrape.do API token
token = "<your_token>"
# Target URL
target_url = "https://www.fastpeoplesearch.com/john-doe"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint (US-based residential proxies)
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true&geoCode=us"
# Send the request and parse HTML
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
print(response)If everything is working correctly, you should see this in your terminal:
<Response [200]>This confirms we’ve successfully bypassed the location and Cloudflare protections. Now we’re ready to extract structured data from the page.
Extracting Name, City, and State
The profile page header includes the person’s full name followed by their location, usually formatted like this:
John Doe in Chicago, IL (Illinois)This gives us everything we need for the name, city, and state in one string.
We locate this information using the element with id="details-header" and then split the text using " in " as a delimiter.
It’s a simple trick that avoids brittle CSS selectors and works reliably across profiles.
Here’s the code that will parse this section successfully:
# Extract name, city, state
header = soup.find("h1", id="details-header")
name, location = header.get_text(" ").strip().split(" in ", 1)
city, state = [part.strip() for part in location.split(",", 1)]
print("Name:", name)
print("City:", city)
print("State:", state)Extracting Age
Just below the name and location, FastPeopleSearch displays the person’s age in a simple format like this:
Age 47We locate it using the id="age-header" element, then strip the text and remove the "Age " prefix.
Here’s the code:
# Extract age
age = soup.find("h2", id="age-header").text.strip().replace("Age ", "")
print("Age:", age)Simple enough, and it gives us a clean numeric string.
Extracting Address and Final Code
This one's a bit more difficult:
The current address on FastPeopleSearch isn’t presented in a single clean line. It’s split across multiple tags inside a clickable <a> element, nested within the section identified by id="current_address_section".
If you try to extract it with .text.strip() or by targeting a specific tag, you’ll often get either missing parts or unwanted formatting.
That’s why we use stripped_strings which collects all visible text across nested elements and strips out any empty lines, whitespace, or junk markup.
By calling next() on it, we grab just the first meaningful line: the street address.
And with that, here’s the final version of the code that puts everything together:
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Your Scrape.do API token
token = "<your_token>"
# Target URL
target_url = "https://www.fastpeoplesearch.com/john-doe"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint - enabling "super=true" and "geoCode=us" for US-based residential proxies
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true&geoCode=us"
# Send the request and parse HTML
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract name, city, state
header = soup.find("h1", id="details-header")
name, location = header.get_text(" ").strip().split(" in ", 1)
city, state = [part.strip() for part in location.split(",", 1)]
# Extract age
age = soup.find("h2", id="age-header").text.strip().replace("Age ", "")
# Extract address
addr = soup.find("div", id="current_address_section").find("a")
address = next(line for line in addr.stripped_strings)
# Print output
print("Name:", name)
print("Age:", age)
print("City:", city)
print("State:", state)
print("Address:", address)And here's all the data we've parsed in clean format:
Name: John Doe
Age: 47
City: Chicago
State: IL (Illinois)
Address: 756 E 91st StExtract Phone Numbers, Emails, and Relatives
The scraper above covers the basics, but FastPeopleSearch profiles contain far more data: phone numbers, email addresses, aliases, and family connections. All of it is accessible through JSON-LD structured data embedded in the page.
Extract Phone Numbers and ZIP from JSON-LD
FastPeopleSearch doesn't expose phone numbers in a simple HTML selector (they're behind affiliate CTAs in the visible page). But the page embeds a Person JSON-LD schema in a <script type="application/ld+json"> tag that contains every phone number and the full address with ZIP code in clean JSON.
import json
person_data = None
for script in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(script.string)
if isinstance(data, dict) and data.get("@type") == "Person":
person_data = data
break
except (json.JSONDecodeError, TypeError):
pass
phones = person_data.get("telephone", [])
home_addr = person_data.get("homeLocation", {}).get("address", {})
zipcode = home_addr.get("postalCode", "")
print(f"ZIP: {zipcode}")
print(f"Phones ({len(phones)}): {phones[0]}")ZIP: 60601
Phones (23): (312) 555-0199The telephone field is an array; some profiles list over 20 numbers including current, previous, and associated phones. The first entry is typically the primary number.
Extract Email Addresses
Email addresses on FastPeopleSearch are Cloudflare XOR-obfuscated in the HTML. The DOM shows [email protected] placeholders with encoded data-cfemail attributes that require JavaScript decryption.
But there's a shortcut: the page also includes a FAQPage JSON-LD block where emails appear in plaintext inside the FAQ answer text. We extract them with a regex:
import re
emails = []
for script in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(script.string)
if isinstance(data, dict) and data.get("@type") == "FAQPage":
for q in data.get("mainEntity", []):
if "email" in q.get("name", "").lower():
answer = q.get("acceptedAnswer", {}).get("text", "")
emails.extend(re.findall(r"[\w.+-]+@[\w-]+\.[\w.-]+", answer))
except (json.JSONDecodeError, TypeError):
pass
emails = list(dict.fromkeys(emails))
print(f"Emails ({len(emails)}): {emails[0]}")Emails (9): [email protected]This completely bypasses Cloudflare's email obfuscation without needing to decode the XOR cipher. SearchPeopleFree uses the same XOR obfuscation but stores plaintext emails in its Person JSON-LD instead of the FAQ block, a different extraction path for the same bypass.
Extract Relatives and Aliases
The same Person JSON-LD includes relatedTo (relatives) and additionalName (aliases) arrays:
aliases = person_data.get("additionalName", [])
relatives = [rel.get("name", "") for rel in person_data.get("relatedTo", [])]
print(f"Aliases: {', '.join(aliases[:3])}")
print(f"Relatives ({len(relatives)}): {', '.join(relatives[:5])}")Aliases: John A Doe, John Anthony Doe, Johnny Doe
Relatives (41): Mary Doe, Robert Smith, Emily Doe, Thomas Doe, Sarah JohnsonThe JSON-LD version includes full middle names that the visible HTML may abbreviate or omit entirely.
Extended Code and Output
Here's the complete scraper with all fields: basic HTML extraction plus JSON-LD data:
import requests
import urllib.parse
from bs4 import BeautifulSoup
import json
import re
token = "<your_token>"
target_url = "<target_person_url>"
encoded_url = urllib.parse.quote_plus(target_url)
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}&super=true&geoCode=us"
response = requests.get(api_url)
soup = BeautifulSoup(response.text, "html.parser")
# Name, city, state from header
header = soup.find("h1", id="details-header")
name, location = header.get_text(" ").strip().split(" in ", 1)
city, state = [part.strip() for part in location.split(",", 1)]
# Age from header
age = soup.find("h2", id="age-header").text.strip().replace("Age ", "")
# Address from HTML
addr = soup.find("div", id="current_address_section").find("a")
address = next(line for line in addr.stripped_strings)
# JSON-LD Person data
person_data = None
for script in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(script.string)
if isinstance(data, dict) and data.get("@type") == "Person":
person_data = data
break
except (json.JSONDecodeError, TypeError):
pass
zipcode = person_data.get("homeLocation", {}).get("address", {}).get("postalCode", "")
phones = person_data.get("telephone", [])
aliases = person_data.get("additionalName", [])
relatives = [rel.get("name", "") for rel in person_data.get("relatedTo", [])]
# Emails from FAQ JSON-LD
emails = []
for script in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(script.string)
if isinstance(data, dict) and data.get("@type") == "FAQPage":
for q in data.get("mainEntity", []):
if "email" in q.get("name", "").lower():
answer = q.get("acceptedAnswer", {}).get("text", "")
emails.extend(re.findall(r"[\w.+-]+@[\w-]+\.[\w.-]+", answer))
except (json.JSONDecodeError, TypeError):
pass
emails = list(dict.fromkeys(emails))
print(f"Name: {name}")
print(f"Age: {age}")
print(f"Address: {address}")
print(f"City: {city}")
print(f"State: {state}")
print(f"ZIP: {zipcode}")
print(f"Phone: {phones[0] if phones else ''}")
print(f"Email: {emails[0] if emails else ''}")
print(f"Aliases: {', '.join(aliases[:5])}")
print(f"Relatives: {', '.join(relatives[:5])}")Name: John Doe
Age: 47
Address: 756 E 91st St
City: Chicago
State: IL (Illinois)
ZIP: 60601
Phone: (312) 555-0199
Email: [email protected]
Aliases: John A Doe, John Anthony Doe, Johnny Doe
Relatives: Mary Doe, Robert Smith, Emily Doe, Thomas Doe, Sarah JohnsonTen data fields from one API call, a major step up from the basic 5-field extraction.
FAQs
Is FastPeopleSearch.com Free?
Yes. FastPeopleSearch.com is a free people search engine. You can look up names, ages, addresses, and public records without paying or creating an account. The challenge isn't access to the data itself; it's getting past the Cloudflare protection that blocks automated requests.
Does FastPeopleSearch Have an API?
No. FastPeopleSearch doesn't provide a public API for data access. The only way to pull data programmatically is by scraping the website through a proxy service like Scrape.do that can handle Cloudflare bypass and US geo-targeting.
Why Is FastPeopleSearch Blocked?
FastPeopleSearch gets blocked for two reasons: you're either outside the US (the site is georestricted to US traffic only) or Cloudflare's bot detection has flagged your connection as automated. Even US-based users see block pages if they're running scripts without proper browser emulation. Scrape.do's super=true and geoCode=us parameters solve both issues.
Can I Access FastPeopleSearch from Outside the USA?
Not directly. FastPeopleSearch enforces strict US-only geoblocking at the network level. To access it from outside the US, you need to route requests through US-based residential proxies. Scrape.do handles this with the geoCode=us parameter, giving you unblocked access to any people search profile regardless of your actual location.
Conclusion
FastPeopleSearch throws aggressive anti-bot defenses at you, from strict georestrictions to Cloudflare protection, but Scrape.do cuts through all of it.
Here's what you get:
- Premium residential and mobile proxies with US geo-targeting
- Full browser rendering with automatic CAPTCHA bypass
- Pay only for successful requests
R&D Engineer








