Category:Scraping Use Cases
How to Scrape Autodoc.de Product & Parts Listings with Python

Full Stack Developer



Autodoc.de is a leading online retailer for car parts and accessories in Europe.
With a vast catalog of products, it presents a valuable target for data extraction.
However, like many e-commerce sites, scraping Autodoc.de can be challenging due to various anti-bot measures and dynamic content loading.
In this guide, we'll show you how to extract key product data from Autodoc.de using Python and Scrape.do, focusing on product name, price, and main image URL.
Why Is Scraping Autodoc.de Difficult?
Autodoc.de, like many modern e-commerce platforms, employs various techniques to prevent automated scraping.
These measures are designed to protect their data and ensure fair usage of their website. Understanding these challenges is crucial for building a robust and reliable scraper.
Most scrapers encounter difficulties for several reasons:
Anti-Bot Mechanisms
Autodoc.de likely utilizes anti-bot solutions to detect and block non-human traffic.
These systems analyze various parameters, including IP address reputation, request patterns, browser fingerprints, and even mouse movements.
If your scraper exhibits behavior that deviates from a typical human user, it risks being flagged and blocked. This can result in CAPTCHAs, IP bans, or misleading content being served.
Dynamic Content and Complex HTML Structure
Many e-commerce websites, including Autodoc.de, rely heavily on JavaScript to load content dynamically. This means that much of the product information, prices, and images might not be present in the initial HTML response.
Traditional scrapers that only fetch static HTML will miss this dynamically loaded data.
Furthermore, the HTML structure of such sites can be complex and frequently updated. Elements might not have consistent class names or IDs, making it challenging to reliably locate and extract specific data points. Relying on static CSS selectors can lead to broken scrapers with even minor website updates.
To overcome these challenges, we'll leverage Scrape.do, a service designed to bypass anti-bot measures and render JavaScript-heavy pages, providing us with a clean HTML response.
Extract Product Information from Autodoc.de with Python
For this guide, we’ll target a specific product listing on Autodoc.de. The principles, however, can be applied to other product pages with minor adjustments.
We’ll pull out:
- MPU and SKU codes
- Brand name
- Product name
- Product description
- Price
- Image URLs
- Product availability
- Seller name
Let’s start with the setup:
Prerequisites
We’ll be using requests to make the API call and BeautifulSoup to parse the HTML and extract values from raw text.
If you haven’t already, install the dependencies:
pip install requests beautifulsoup4🔑 We will also be using Scrape.do to bypass anti-bot mechanisms and ensure reliable data extraction.
Sending the First Request
To begin, we send a request to the target Autodoc.de product page using Scrape.do. Scrape.do handles the complexities of bypassing anti-bot measures, allowing us to receive a clean, rendered HTML page.
Here’s how to send the request and verify that it works:
import requests
import urllib.parse
from bs4 import BeautifulSoup
# Your Scrape.do API token
token = "<your-token>" # Replace with your actual Scrape.do API token
# Target URL
target_url = "https://www.autodoc.de/reifen/hankook-8808563543369-1029031"
encoded_url = urllib.parse.quote_plus(target_url)
# Scrape.do API endpoint - enabling super=true for premium proxies
api_url = f"https://api.scrape.do/?token={token}&url={encoded_url}"
# Get and parse HTML
response = requests.get(api_url)
# Print response status
print(response)If everything goes right, you’ll see:
<Response [200]>Which means we’ve successfully bypassed any blocking mechanisms and received a clean, rendered page.
Scraping Product Details
Parsing product information from Autodoc product pages is extremely simple because all product information is located inside a JSON script in a structured way.
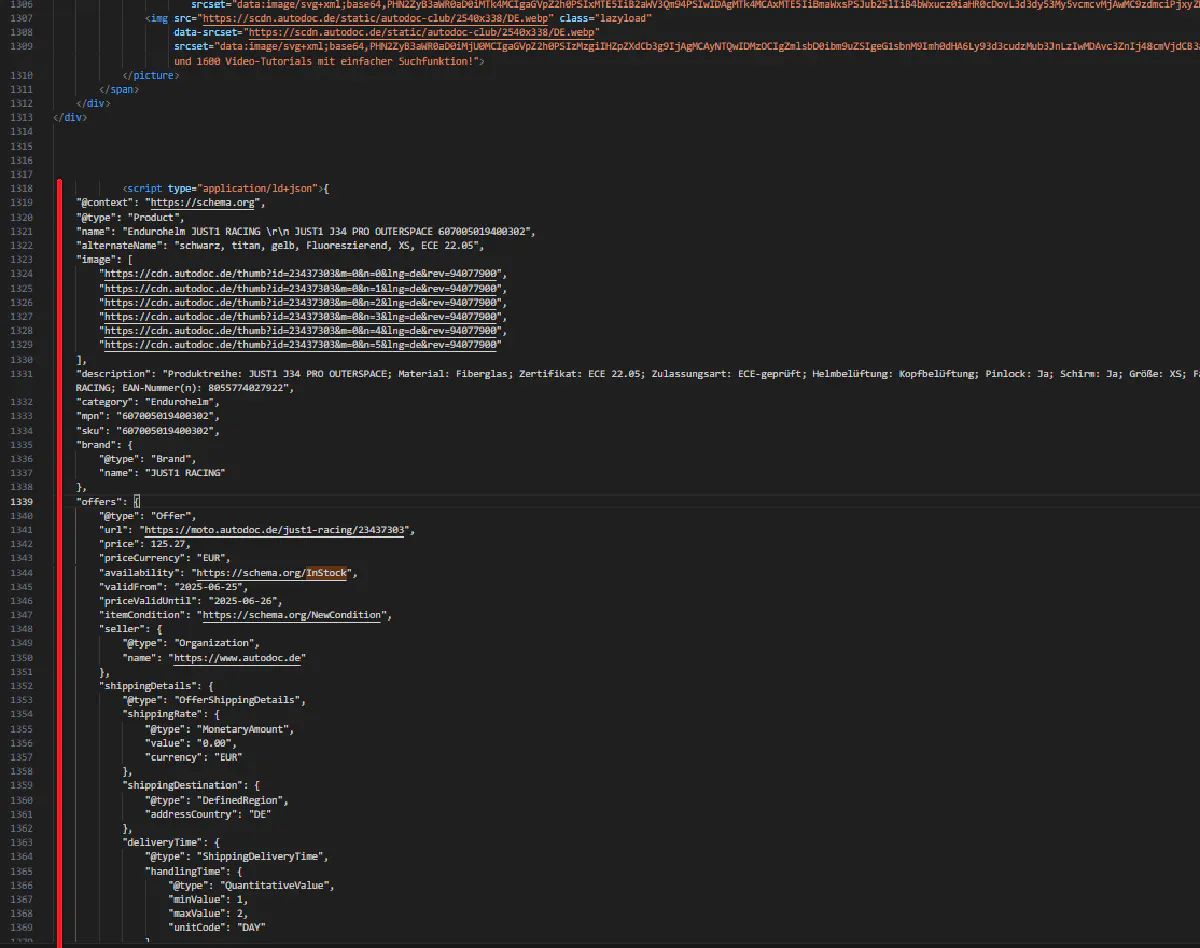
We can write a simple code that gathers all the information we need from this structure:
import requests
import urllib.parse
import json
from bs4 import BeautifulSoup
token = "<your-token>"
target_url = "https://www.autodoc.de/reifen/hankook-8808563543369-1029031"
api_url = f"https://api.scrape.do/?token={token}&url={urllib.parse.quote_plus(target_url)}"
resp = requests.get(api_url); resp.raise_for_status()
soup = BeautifulSoup(resp.text, "html.parser")
data = next(
(
json.loads(tag.string)
for tag in soup.select('script[type="application/ld+json"]')
if (tag.string or "").strip().startswith('{') and json.loads(tag.string).get("@type") == "Product"
),
{}
)
offers = data.get("offers", {})
availability = {"https://schema.org/InStock": "In stock"}.get(offers.get("availability"), "not in stock")
print("MPN: ", data.get("mpn"))
print("SKU: ", data.get("sku"))
print("Product Name: ", data.get("name"))
print("Brand Name: ", data.get("brand", {}).get("name"))
print("Product Name: ", data.get("name"))
print("Product Description:", data.get("description"))
print("Price: ", offers.get("price"))
print("Image URLs: ", data.get("image", []))
print("Availability: ", availability)
print("Seller Name: ", offers.get("seller", {}).get("name"))This will give you an output like:
MPN: 1029031
SKU: 1029031
Product Name: Hankook K127EEVAO 235/55 R19 101T Sommerreifen
Brand Name: Hankook
Product Name: Hankook K127EEVAO 235/55 R19 101T Sommerreifen
Product Description: Reifenart: Sommerreifen; Reifengröße: 235 55 R19 101T; M+S: Nein; Breite: 235; Höhe: 55; Typ: R; Zoll: 19; Lastindex: 101 = bis 825 kg; Speed-Index: T = bis 190 km/h; Typ: PKW; Felgenschutz: Nein; Runflatreifen: Nein; Verstärkt / reinforced / XL: Nein; C-Reifen: Nein
Price: 87.85
Image URLs: ['https://cdn.autodoc.de/thumb?id=18734086&m=0&n=0&lng=de&rev=94077900', 'https://cdn.autodoc.de/thumb?id=18734086&m=0&n=1&lng=de&rev=94077900', 'https://cdn.autodoc.de/thumb?id=18734086&m=0&n=2&lng=de&rev=94077900', 'https://cdn.autodoc.de/thumb?id=18734086&m=0&n=3&lng=de&rev=94077900', 'https://cdn.autodoc.de/thumb?id=18734086&m=0&n=4&lng=de&rev=94077900']
Availability: In stock
Seller Name: https://www.autodoc.deAnd that's it, you now have access to tens of thousands of car and motorbike parts and supplies with a simple bypass.
💡 Trouble getting access? Enable &super=true and &geoCode=de paramaters in the Scrape.do API call to enable Germany-located residential proxies.
Conclusion
Scraping e-commerce websites like Autodoc.de can be a powerful way to gather valuable product data for market analysis, competitive intelligence, or personal projects.
While challenges like anti-bot measures and dynamic content exist, tools like Scrape.do, combined with Python libraries such as requests and BeautifulSoup, provide effective solutions.
Full Stack Developer








