Step-by-step guide to integrate Scrape.do with n8n for automated web scraping workflows
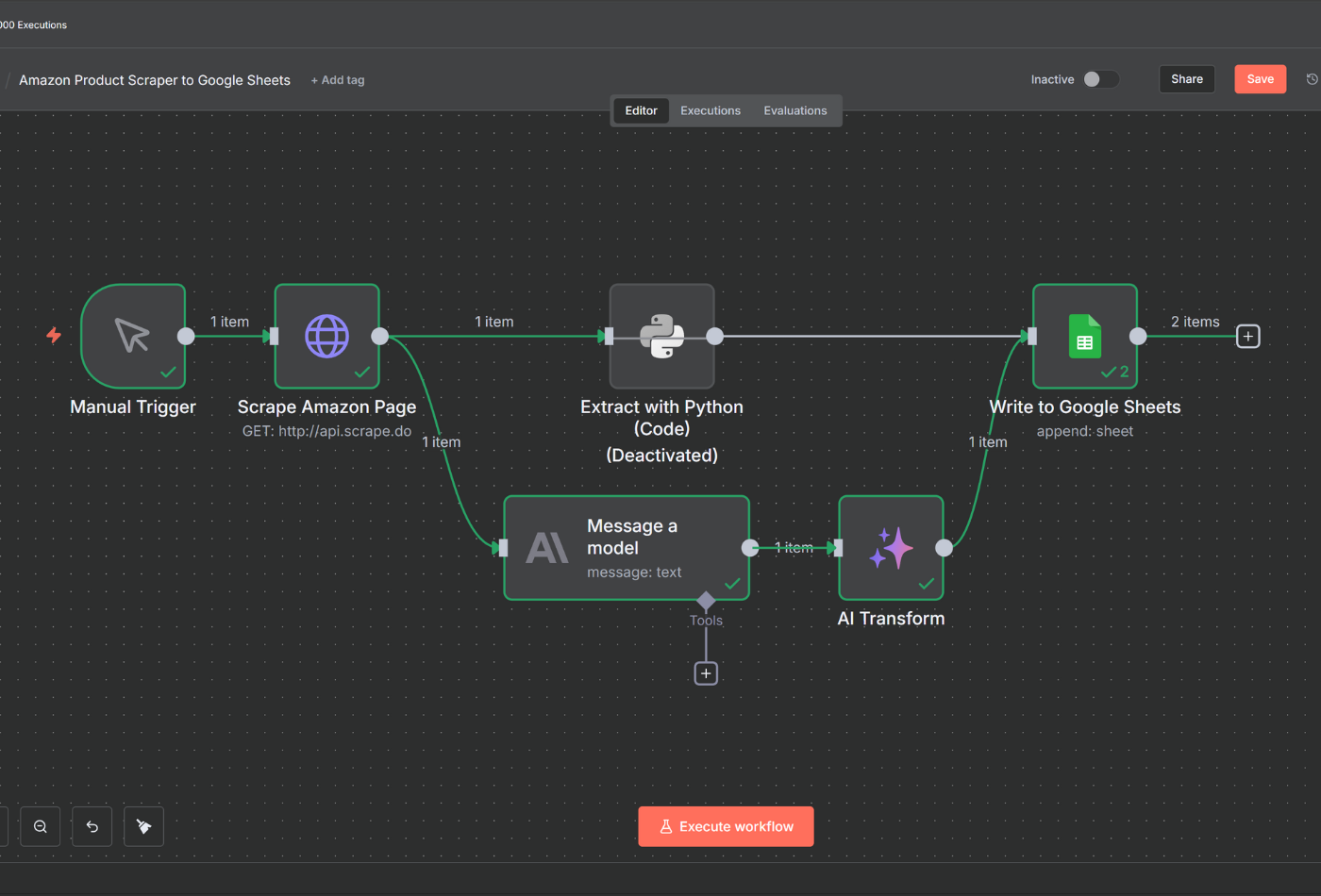
Scrape.do integrates seamlessly with n8n to automate web scraping workflows. Use HTTP requests to scrape websites, parse the response with AI or Python code, and export data to Google Sheets or any of n8n's countless integrations and use cases.
Now we'll configure the HTTP Request node to send scraping requests to Scrape.do.
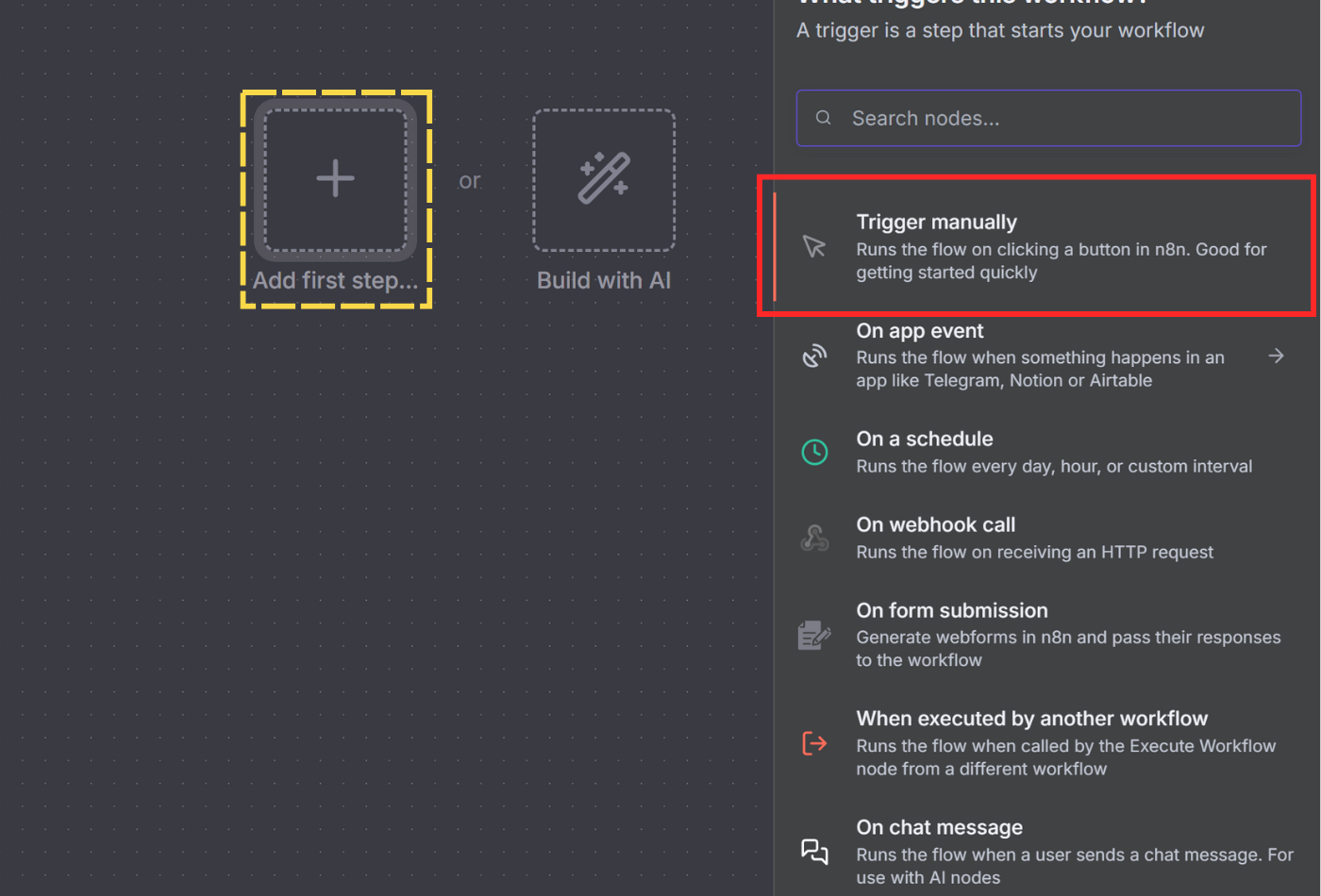
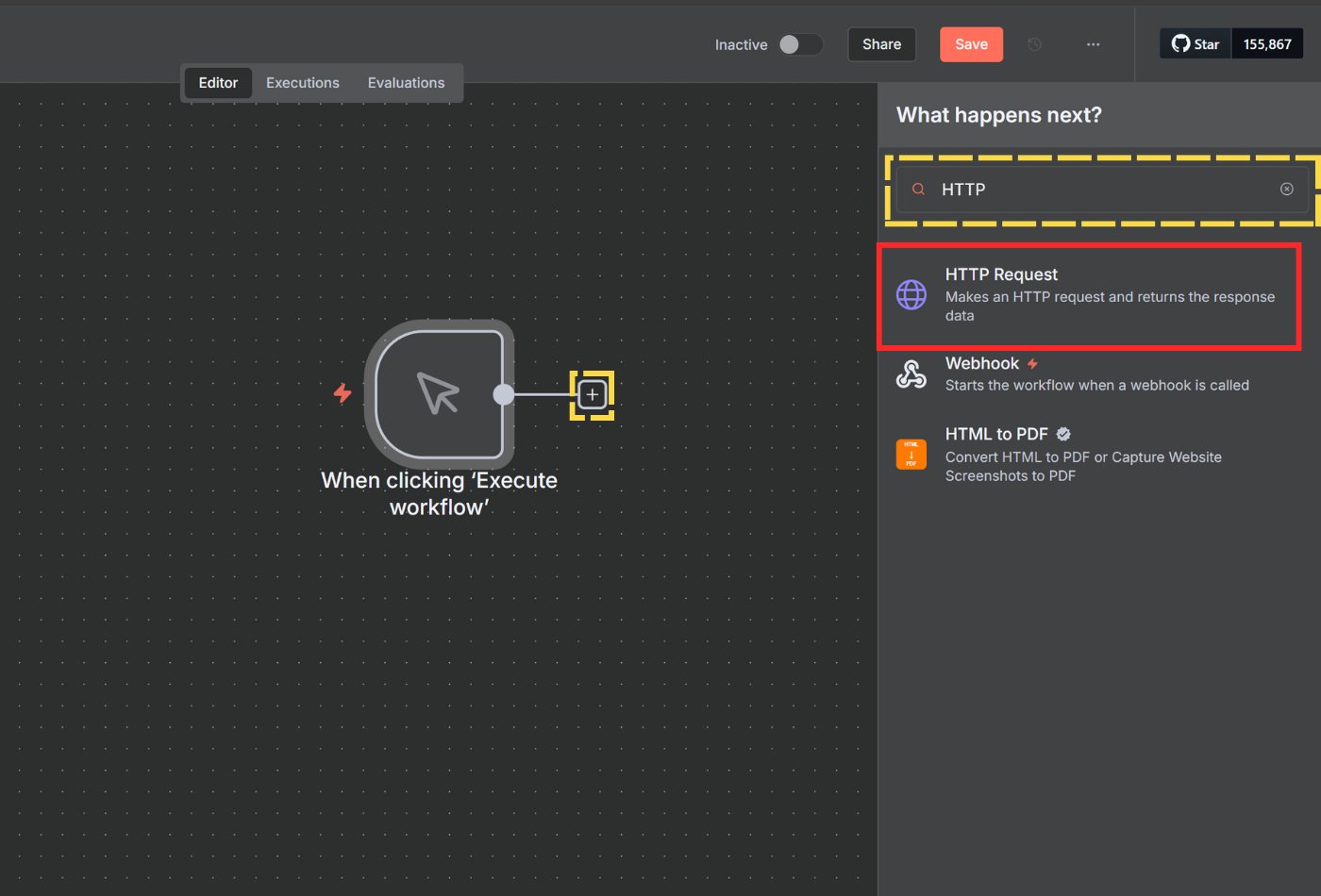
Click the + button to add a new node and search for HTTP. Select HTTP Request from the list.
In the node settings, either click Import cURL and paste a working request from your playground, or configure the following:
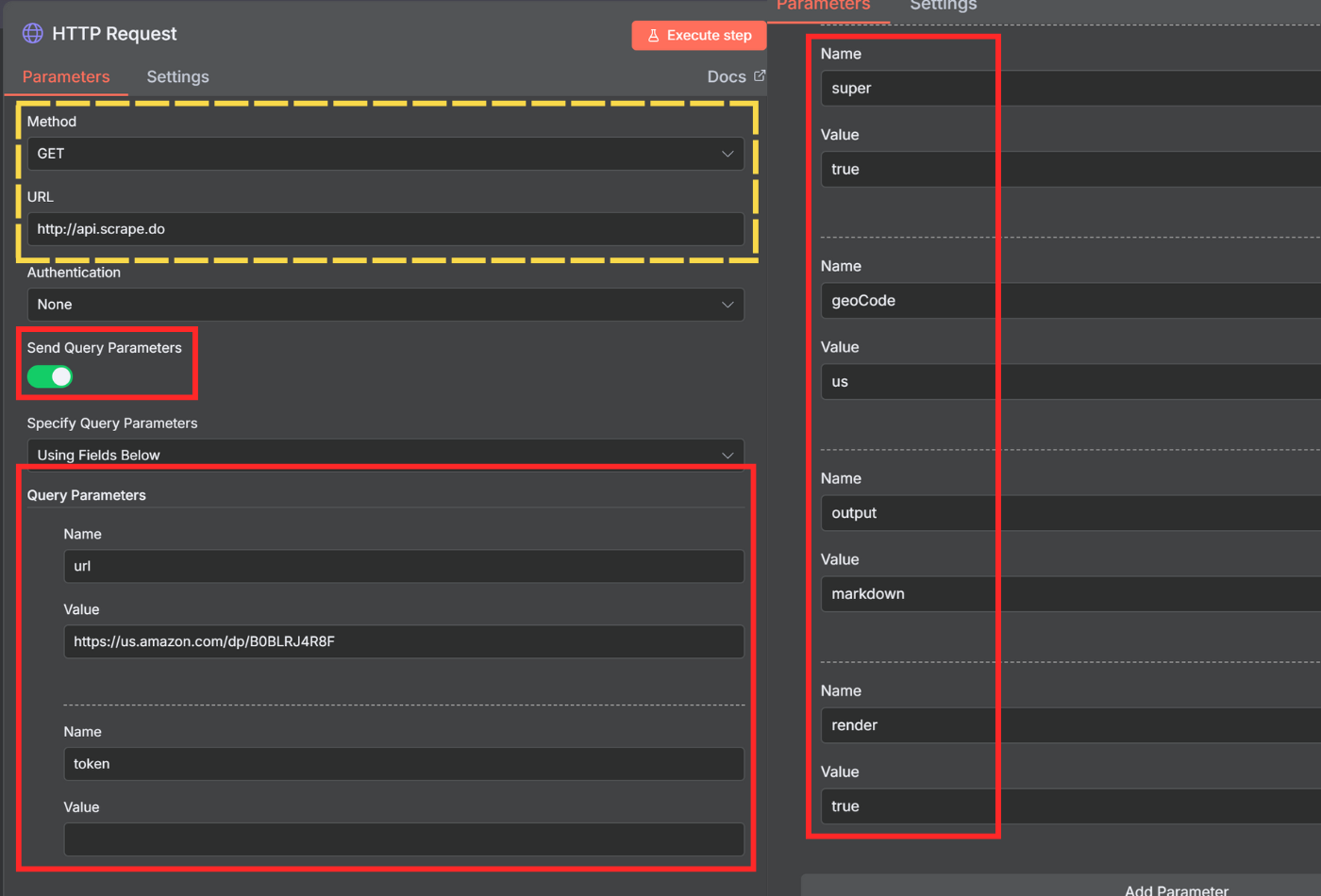
Method - Select GET
URL - Enter http://api.scrape.do
Send Query Parameters - Toggle this ON
Click Add Parameter and add these query parameters one by one:
url - The URL of the web page you want to scrape (e.g., https://us.amazon.com/dp/B0BLRJ4R8F)
token - Your Scrape.do API token from your dashboard
super - Set to true to use residential and mobile proxies for better success rates, or false for datacenter proxies
geoCode - Country code for proxy location (e.g., us, uk, de). View available locations here
render - Set to false by default. Change to true for JavaScript-heavy websites that need browser rendering
output - Set to raw for manual parsing with code, or markdown for AI-based extraction (reduces token usage)
Click Test step to verify you're getting a successful response.
If you're unable to get a response, visit the playground and experiment with parameters like Super, Render JavaScript, and Block Resources until you get a successful response.
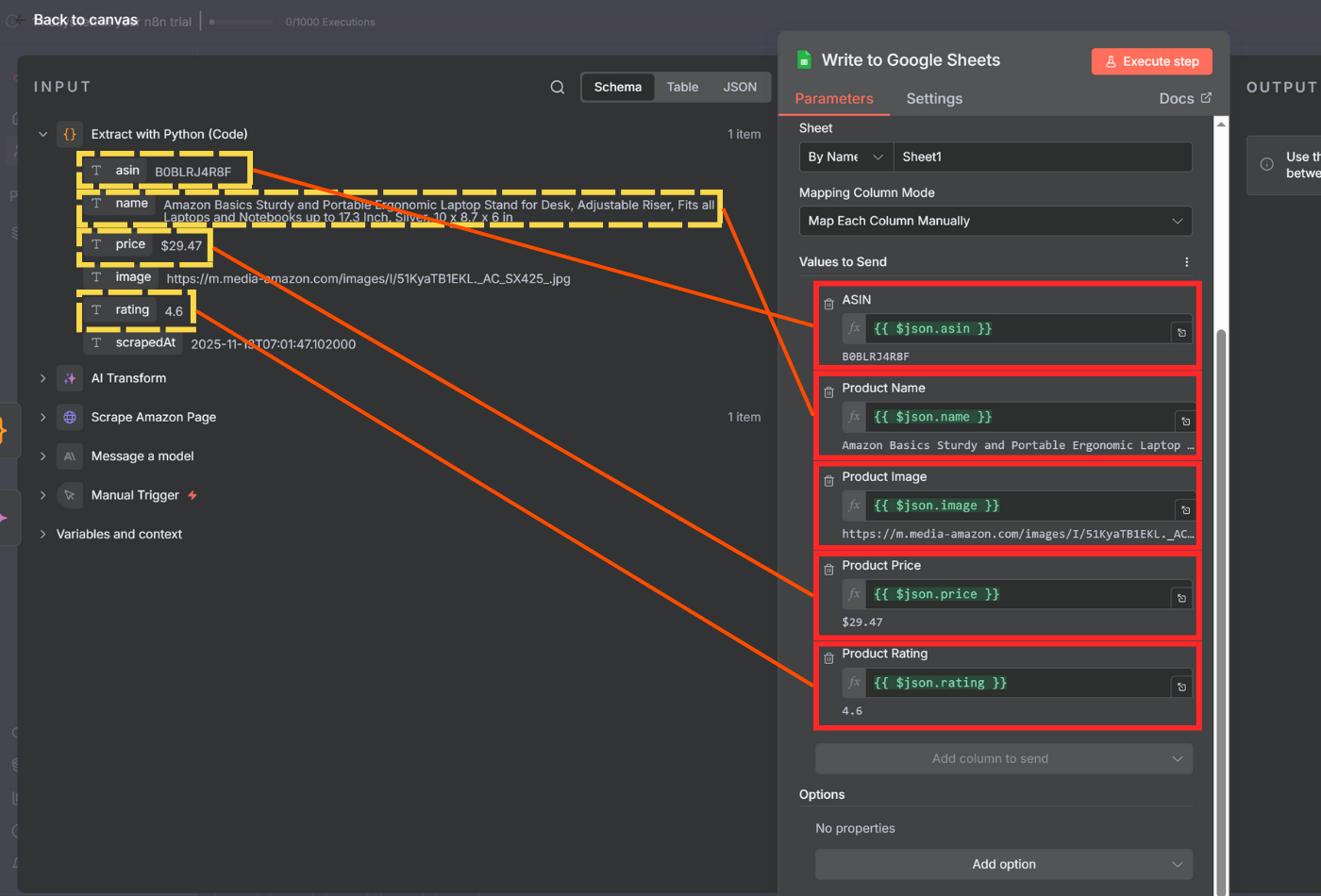
Once you have the raw HTML or markdown response, you need to parse it into structured data. You have two options for extracting data from your Scrape.do response.
Best for scraping different websites with varying structures. AI can extract data into a consistent format regardless of the source website's layout.
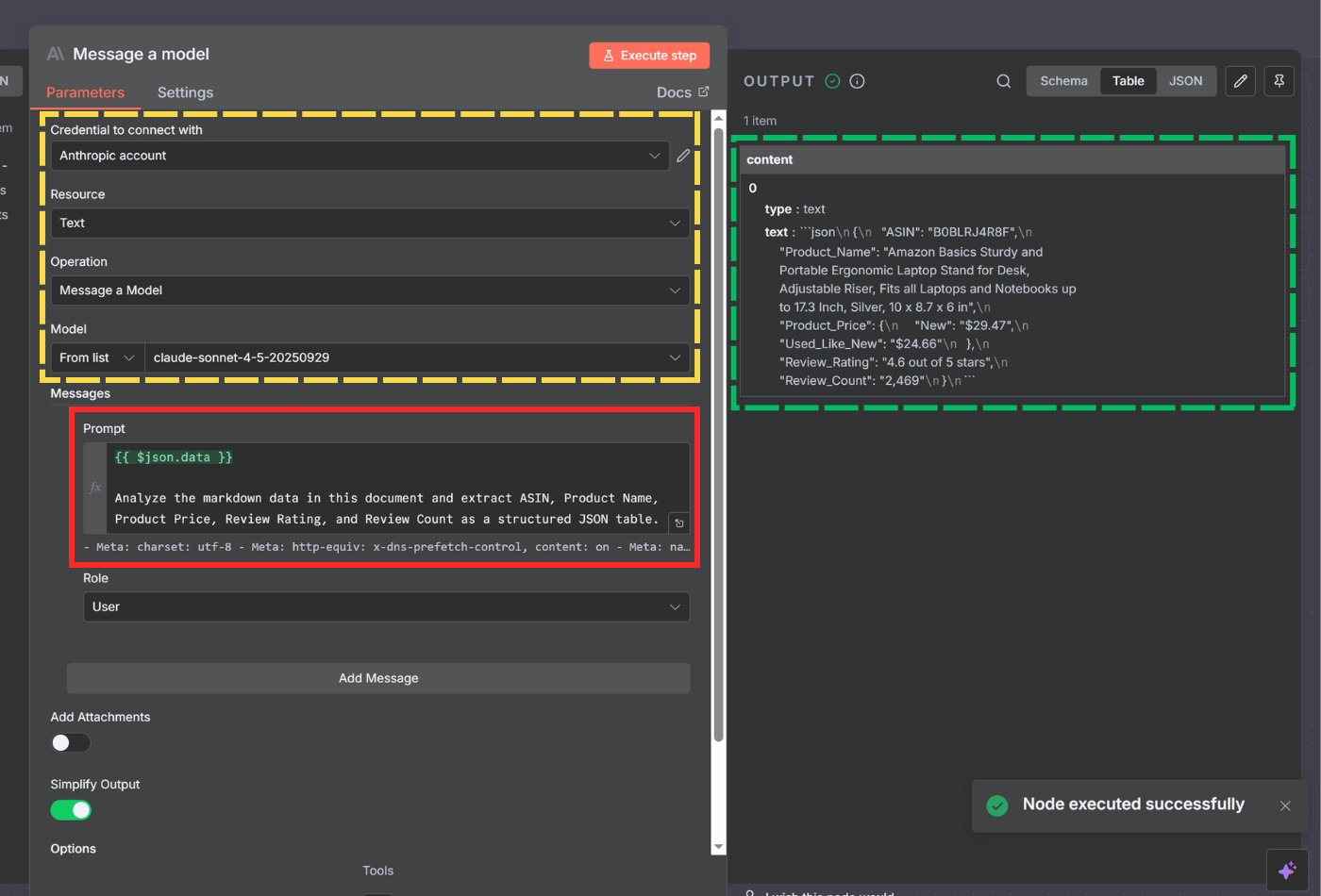
Click the + button after the HTTP Request node and search for Anthropic or OpenAI.
Select Message a model (for Anthropic Claude) or the equivalent AI chat node.
Connect your Anthropic/OpenAI API credentials if you haven't already.
Configure the AI node:
Model - Select a model like claude-sonnet-4-5-20250929 or gpt-4
Message - Add a user message with this structure:
{{ $json.data }}Analyze the markdown data in this document and extract ASIN, Product Name, Product Price, Review Rating, and Review Count as a structured JSON table.
The {{ $json.data }} will insert the scraped content from the previous node. If not, you can drag and drop the {{ $json.data }} from the INPUT section on the left to your prompt input field.
If you're scraping a single website with a consistent layout, Python code is faster and doesn't consume AI credits. This is also useful when the response is too large for AI models.
Click the + button after the HTTP Request node and search for Code.
Select Code node and configure:
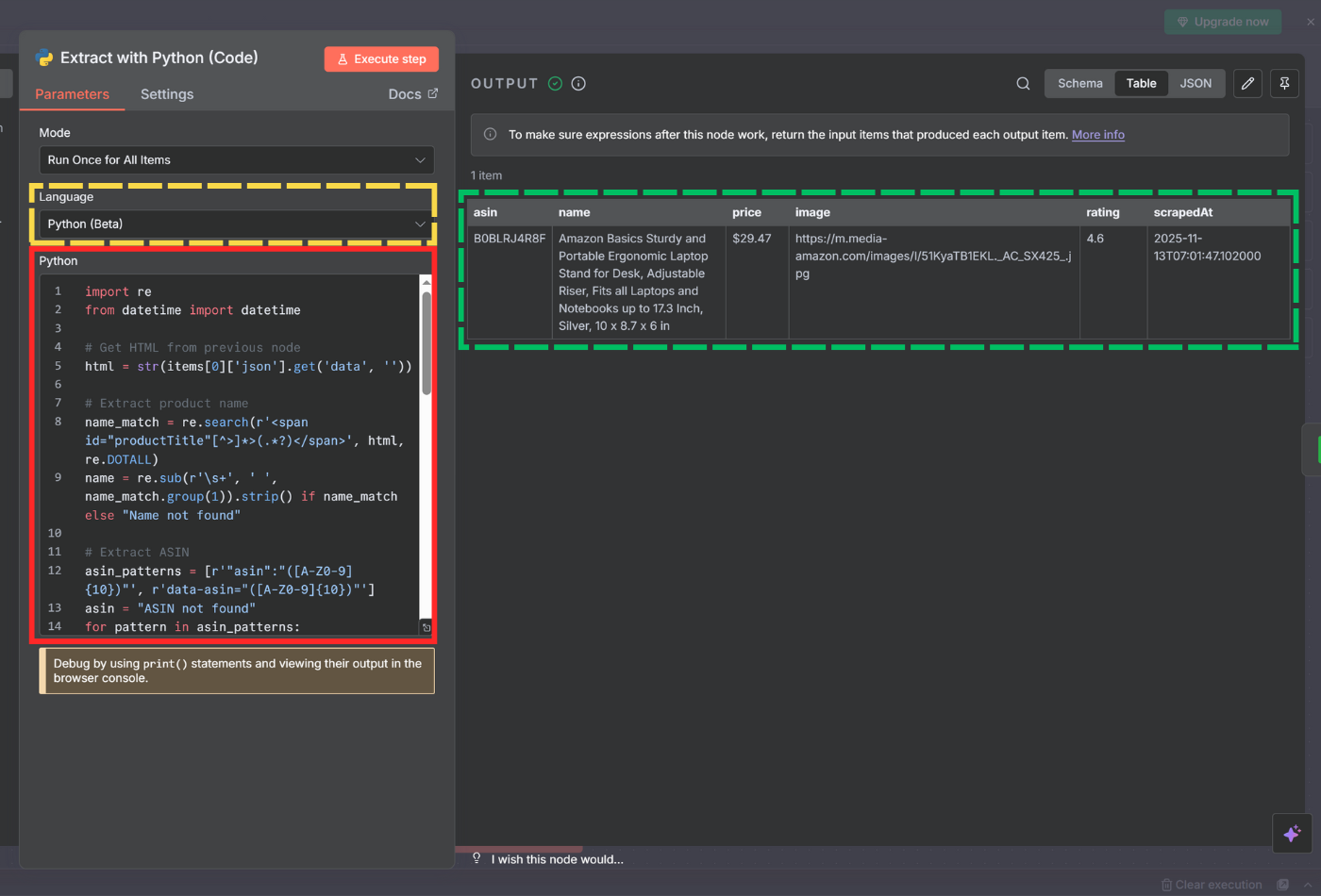
Language - Select Python
In the code editor, paste your extraction logic:
Example code (extract product details from Amazon):
import refrom datetime import datetime# Get HTML from previous nodehtml = str(items[0]['json'].get('data', ''))# Extract product namename_match = re.search(r'<span id="productTitle"[^>]*>(.*?)</span>', html, re.DOTALL)name = re.sub(r'\s+', ' ', name_match.group(1)).strip() if name_match else "Name not found"# Extract ASINasin_patterns = [r'"asin":"([A-Z0-9]{10})"', r'data-asin="([A-Z0-9]{10})"']asin = "ASIN not found"for pattern in asin_patterns: m = re.search(pattern, html) if m: asin = m.group(1) break# Extract priceprice_match = re.search(r'<span class="a-offscreen">\$([0-9.,]+)</span>', html)if price_match: price = f"${price_match.group(1)}"else: whole = re.search(r'<span class="a-price-whole">([0-9,]+)', html) fraction = re.search(r'<span class="a-price-fraction">([0-9]+)</span>', html) price = f"${whole.group(1)}.{fraction.group(1)}" if whole and fraction else "Price not found"# Extract imageimage_match = re.search(r'id="landingImage"[^>]*data-a-dynamic-image="[^"]*"(https://[^&]+?)"', html)if not image_match: image_match = re.search(r'<img[^>]*id="landingImage"[^>]*src="([^"]+)"', html)image = image_match.group(1) if image_match else "No image"# Extract ratingrating_match = re.search(r'(\d+\.?\d*)\s*out of', html)rating = rating_match.group(1) if rating_match else "No rating"# Return outputreturn [{'json': {'asin': asin, 'name': name, 'price': price, 'image': image, 'rating': rating, 'scrapedAt': datetime.now().isoformat()}}]
Click Test step to verify the extraction works correctly.